本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
在 上建立生產就緒的 ML 管道 AWS
Josiah Davis、Verdi March、Yin Song、Baichuan Sun、Chen Wu 和 Wei Yih Yap、Amazon Web Services (AWS)
2021 年 1 月 (文件歷史記錄)
機器學習 (ML) 專案需要重要的多階段工作,包括建模、實作和生產,以提供商業價值並解決實際問題。每個步驟都提供許多替代方案和自訂選項,這些選項使得在資源和預算限制範圍內準備生產 ML 模型變得越來越困難。在過去幾年,在 Amazon Web Services (AWS),我們的資料科學團隊已與不同的產業部門合作進行 ML 計畫。我們發現許多 AWS 客戶共用的痛點,這源自組織問題和技術挑戰,而且我們開發了交付生產就緒 ML 解決方案的最佳方法。
本指南適用於參與 ML 管道實作的資料科學家和 ML 工程師。它說明了我們交付可立即生產 ML 管道的方法。本指南討論如何從以互動方式執行 ML 模型 (在開發期間) 轉換到部署它們,做為 ML 使用案例管道 (在生產期間) 的一部分。為此,我們也開發了一組範例範本 (請參閱 ML Max 專案
概觀
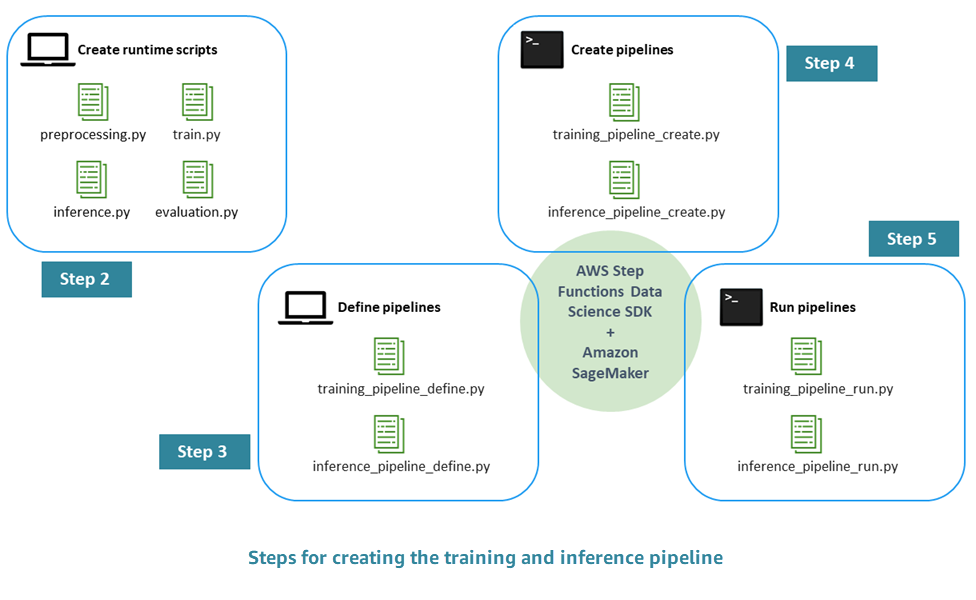
建立生產就緒 ML 管道的程序包含下列步驟:
-
步驟 1。執行 EDA 並開發初始模型 – 資料科學家在 Amazon Simple Storage Service (Amazon S3) 中提供原始資料、執行探索性資料分析 (EDA)、開發初始 ML 模型,以及評估其推論效能。您可以透過 Jupyter 筆記本以互動方式執行這些活動。
-
步驟 2。建立執行階段指令碼 – 您可以將模型與執行階段 Python 指令碼整合,以便由 ML 架構 (在我們的案例中為 Amazon SageMaker AI) 管理和佈建。這是從獨立模型的互動開發轉向生產的第一步。具體而言,您可以分別定義預先處理、評估、訓練和推論的邏輯。
-
步驟 3。定義管道 – 您可以定義管道每個步驟的輸入和輸出預留位置。這些的具體值將在稍後的執行時間提供 (步驟 5)。您會專注於訓練、推論、交叉驗證和回溯測試的管道。
-
步驟 4。建立管道 – 您可以使用 建立基礎基礎設施,包括以自動化 (幾乎一鍵式) 方式使用 AWS Step Functions 的狀態機器執行個體 AWS CloudFormation。
-
步驟 5。執行管道 – 執行步驟 4 中定義的管道。您也可以準備中繼資料和資料或資料位置,為您在步驟 3 中定義的輸入/輸出預留位置填入具體值。這包括步驟 2 中定義的執行階段指令碼,以及模型超參數。
-
步驟 6。擴展管道 – 您可以實作持續整合和持續部署 (CI/CD) 程序、自動化重新訓練、排程推論,以及管道的類似延伸。
下圖說明此程序的主要步驟。