本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用案例:預測患者結果和重新入院率
AI 驅動的預測分析透過預測患者結果並啟用個人化治療計劃,提供進一步的好處。這可以改善患者滿意度和健康結果。透過將這些 AI 功能與 Amazon Bedrock 和其他技術整合,醫療保健供應商可以實現顯著的生產力提高、降低成本並提高患者護理的整體品質。
您可以在知識圖表
此解決方案可協助您預測重新入學的可能性。這些預測可以改善患者結果並降低醫療保健成本。此解決方案也可以協助醫院臨床醫生和管理員將注意力集中在具有較高重新入院風險的患者。它還有助於他們透過提醒、自助服務和資料驅動的動作,向這些患者啟動主動介入。
解決方案概觀
此解決方案使用多擷取器擷取增強生成 (RAG) 架構來分析患者資料。它預測個別患者重新入院的可能性,並協助您計算醫院層級的重新入院傾向分數。此解決方案整合了下列功能:
-
知識圖表 – 存放結構化、按時間排序的患者資料,例如醫院事件、先前的重新入院、症狀、實驗室結果、規定的處理方式,以及藥物依從性歷史記錄
-
向量資料庫 – 存放非結構化臨床資料,例如出院摘要、醫生備註,以及錯過預約或報告藥物副作用的記錄
-
微調 LLM – 使用知識圖表中的結構化資料和向量資料庫中的非結構化資料,以產生有關患者行為、治療遵循和重新入院可能性的推論
風險評分模型會將 LLM 的推論量化為數值分數。您可以將分數彙總為醫院層級的重新入學傾向分數。此分數會定義每位病患的風險暴露,您可以定期或視需要進行計算。所有推論和風險分數都會編製索引並存放在 Amazon OpenSearch Service 中,以便照護管理員和臨床醫生可以擷取它。透過將對話式 AI 代理程式與此向量資料庫整合,臨床醫生和護理經理可以順暢地擷取個別患者層級、全設施層級或醫療專科的洞見。您也可以根據風險分數設定自動提醒,以鼓勵主動介入。
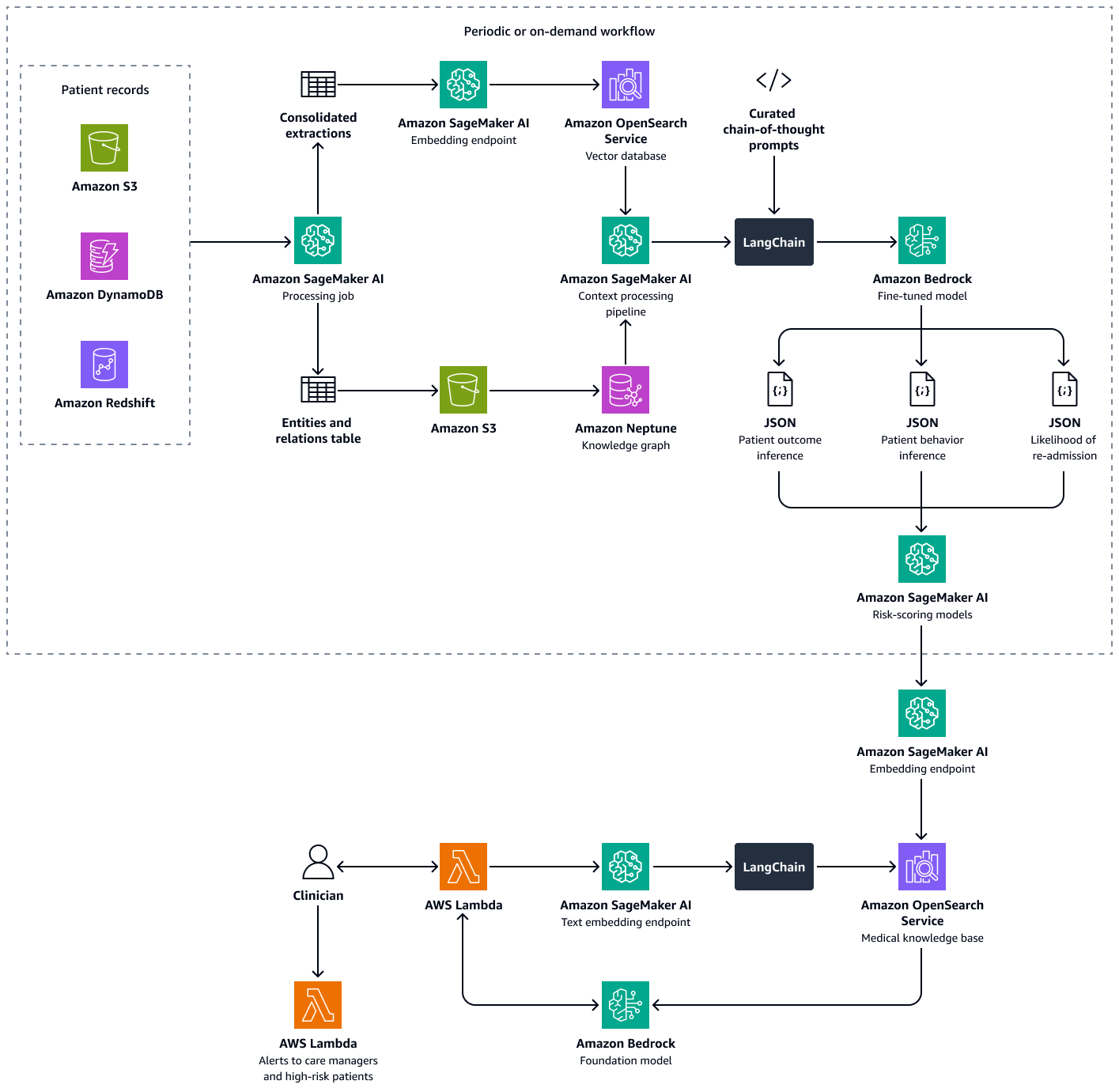
建置此解決方案包含下列步驟:
步驟 1:使用醫學知識圖表預測病患結果
在 Amazon Neptune 中,您可以使用知識圖表來儲存一段時間內有關患者就診和結果的臨時知識。建置和存放知識圖形最有效的方法是使用圖形模型和圖形資料庫。圖形資料庫專為存放和導覽關係而建置。圖形資料庫可讓您更輕鬆地建立和管理高度連線的資料,並具有靈活的結構描述。
知識圖表可協助您執行時間序列分析。以下是圖形資料庫的關鍵元素,用於暫時預測患者結果:
-
歷史資料 – 先前診斷、繼續藥物、先前使用藥物,以及病患的實驗室結果
-
患者門診 (時間) – 門診日期、症狀、觀察到的敏感、臨床備註、診斷、程序、治療、處方藥和實驗室結果
-
症狀和臨床參數 – 臨床和以症狀為基礎的資訊,包括嚴重性、進展模式,以及患者對藥物的反應
您可以使用醫學知識圖表中的洞見來微調 Amazon Bedrock 中的 LLM,例如 Llama 3。您可以使用有關患者對一組藥物或治療隨時間回應的循序患者資料來微調 LLM。使用標記的資料集,將 中的一組藥物或治療和患者-臨床互動資料分類為預先定義的類別,以指示患者的運作狀態。這些類別的範例包括運作狀態惡化、改善或穩定的進度。當臨床醫生輸入有關患者及其症狀的新內容時,微調後的 LLM 可以使用訓練資料集的模式來預測潛在的患者結果。
下圖顯示使用醫療保健特定的訓練資料集,在 Amazon Bedrock 中微調 LLM 所涉及的循序步驟。此資料可能包括患者醫療情況,以及隨著時間的推移對治療的反應。此訓練資料集有助於模型對患者結果進行一般性預測。
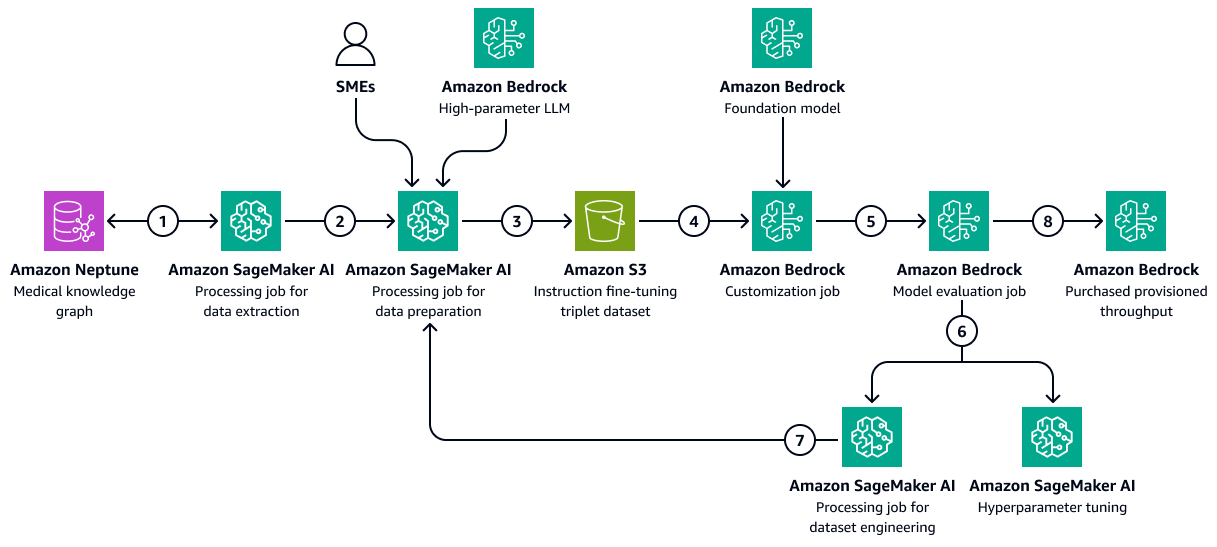
該圖顯示以下工作流程:
-
Amazon SageMaker AI 資料擷取任務會查詢知識圖表,以擷取不同患者隨著時間對一組藥物或處理方式回應的時間資料。
-
SageMaker AI 資料準備任務整合了 Amazon Bedrock LLM 和主題專家 (SMEs的輸入。任務會將從知識圖表擷取的資料分類為預先定義的類別 (例如,運作狀態惡化、改善或穩定的進度),以指出每個病患的運作狀態。
-
任務會建立微調資料集,其中包含從知識圖表擷取的資訊、chain-of-thought提示和病患結果類別。它會將此訓練資料集上傳至 Amazon S3 儲存貯體。
-
Amazon Bedrock 自訂任務會使用此訓練資料集來微調 LLM。
-
Amazon Bedrock 自訂任務整合了訓練環境中選擇的 Amazon Bedrock 基礎模型。它會啟動微調任務,並使用訓練資料集和您設定的訓練超參數。
-
Amazon Bedrock 評估任務會使用預先設計的模型評估架構來評估微調後的模型。
-
如果模型需要改善,在仔細考慮訓練資料集之後,訓練任務會使用更多資料再次執行。如果模型未顯示增量效能改善,也請考慮修改訓練超參數。
-
模型評估符合業務利益相關者定義的標準後,您會將微調後的模型託管至 Amazon Bedrock 佈建的輸送量。
步驟 2:預測患者對處方藥或治療的行為
微調 LLMs可以處理臨時醫學知識圖表中的臨床備註、放電摘要和其他患者特定文件。他們可以評估患者是否可能遵循處方藥或治療。
此步驟使用在 中建立的知識圖表步驟 1:使用醫學知識圖表預測病患結果。知識圖表包含來自病患設定檔的資料,包括病患作為節點的歷史遵循。它還包括不遵守藥物或處理方式的執行個體、藥物的副作用、缺乏藥物的存取或成本障礙,或複雜用量方案作為此類節點的屬性。
微調LLMs 可以使用來自醫學知識圖表的過去處方履行資料,以及來自 Amazon OpenSearch Service 向量資料庫的臨床備註描述性摘要。這些臨床備註可能會提及經常錯過的預約或不遵守治療。LLM 可以使用這些備註來預測未來不遵守的可能性。
-
準備輸入資料,如下所示:
-
結構化資料 – 從醫學知識圖表中擷取最近的患者資料,例如過去三次的就診和實驗室結果。
-
非結構化資料 – 從 Amazon OpenSearch Service 向量資料庫中擷取最新的臨床備註。
-
-
建構包含病患歷史記錄和目前內容的輸入提示。以下是提示範例:
You are a highly specialized AI model trained in healthcare predictive analytics. Your task is to analyze a patient's historical medical records, adherence patterns, and clinical context to predict the **likelihood of future non-adherence** to prescribed medications or treatments. ### **Patient Details** - **Patient ID:** {patient_id} - **Age:** {age} - **Gender:** {gender} - **Medical Conditions:** {medical_conditions} - **Current Medications:** {current_medications} - **Prescribed Treatments:** {prescribed_treatments} ### **Chronological Medical History** - **Visit Dates & Symptoms:** {visit_dates_symptoms} - **Diagnoses & Procedures:** {diagnoses_procedures} - **Prescribed Medications & Treatments:** {medications_treatments} - **Past Adherence Patterns:** {historical_adherence} - **Instances of Non-Adherence:** {past_non_adherence} - **Side Effects Experienced:** {side_effects} - **Barriers to Adherence (e.g., Cost, Access, Dosing Complexity):** {barriers} ### **Patient-Specific Insights** - **Clinical Notes & Discharge Summaries:** {clinical_notes} - **Missed Appointments & Non-Compliance Patterns:** {missed_appointments} ### **Let's think Step-by-Step to predict the patient behaviour** 1. You should first analyze past adherence trends and patterns of non-adherence. 2. Identify potential barriers, such as financial constraints, medication side effects, or complex dosing regimens. 3. Thoroughly examine clinical notes and documented patient behaviors that may hint at non-adherence. 4. Correlate adherence history with prescribed treatments and patient conditions. 5. Finally predict the likelihood of non-adherence based on these contextual insights. ### **Output Format (JSON)** Return the prediction in the following structured format: ```json { "patient_id": "{patient_id}", "likelihood_of_non_adherence": "{low | moderate | high}", "reasoning": "{detailed_explanation_based_on_patient_history}" } -
將提示傳遞至微調的 LLM。LLM 會處理提示並預測結果。以下是來自 LLM 的範例回應:
{ "patient_id": "P12345", "likelihood_of_non_adherence": "high", "reasoning": "The patient has a history of missed appointments, has reported side effects to previous medications. Additionally, clinical notes indicate difficulty following complex dosing schedules." } -
剖析模型的回應,以擷取預測的結果類別。例如,上一個步驟中範例回應的類別可能是不遵守的可能性很高。
-
(選用) 使用模型日誌或其他方法來指派可信度分數。日誌是屬於特定類別的項目的非標準化機率。
步驟 3:預測患者重新入院的可能性
由於醫療保健管理的高成本,以及其對患者良好狀態的影響,重新入院是主要的考量。運算醫院重新入院率是衡量醫療保健供應商患者照護品質和效能的一種方式。
若要計算重新加入率,您定義了一個指標,例如 7 天的重新加入率。此指標是在出院後七天內返回醫院進行非計劃就診的已入院患者百分比。為了預測患者重新入院的機會,微調後的 LLM 可能會耗用您在 中建立的醫學知識圖表中的暫時資料步驟 1:使用醫學知識圖表預測病患結果。此知識圖表會維護病患事件、程序、藥物和症狀的時間記錄。這些資料記錄包含下列項目:
-
自病患上次出院以來的持續時間
-
病患對過去治療和藥物的反應
-
隨著時間的推移,症狀或條件的進展
您可以處理這些時間序列事件,透過策劃的系統提示來預測患者重新入院的可能性。提示會將預測邏輯提供給微調的 LLM。
-
準備輸入資料,如下所示:
-
依從性歷史記錄 – 從醫學知識圖表中擷取藥物收件日期、藥物補充頻率、診斷和藥物詳細資訊、時間性醫療史,以及其他資訊。
-
行為指標 – 擷取並包含有關錯過預約和患者報告副作用的臨床備註。
-
-
建構輸入提示,其中包含遵循歷史記錄和行為指標。以下是提示範例:
You are a highly specialized AI model trained in healthcare predictive analytics. Your task is to analyze a patient's historical medical records, clinical events, and adherence patterns to predict the **likelihood of hospital readmission** within the next few days. ### **Patient Details** - **Patient ID:** {patient_id} - **Age:** {age} - **Gender:** {gender} - **Primary Diagnoses:** {diagnoses} - **Current Medications:** {current_medications} - **Prescribed Treatments:** {prescribed_treatments} ### **Chronological Medical History** - **Recent Hospital Encounters:** {encounters} - **Time Since Last Discharge:** {time_since_last_discharge} - **Previous Readmissions:** {past_readmissions} - **Recent Lab Results & Vital Signs:** {recent_lab_results} - **Procedures Performed:** {procedures_performed} - **Prescribed Medications & Treatments:** {medications_treatments} - **Past Adherence Patterns:** {historical_adherence} - **Instances of Non-Adherence:** {past_non_adherence} ### **Patient-Specific Insights** - **Clinical Notes & Discharge Summaries:** {clinical_notes} - **Missed Appointments & Non-Compliance Patterns:** {missed_appointments} - **Patient-Reported Side Effects & Complications:** {side_effects} ### **Reasoning Process – You have to analyze this use case step-by-step.** 1. First assess **time since last discharge** and whether recent hospital encounters suggest a pattern of frequent readmissions. 2. Second examine **recent lab results, vital signs, and procedures performed** to identify clinical deterioration. 3. Third analyze **adherence history**, checking if past non-adherence to medications or treatments correlates with readmissions. 4. Then identify **missed appointments, self-reported side effects, or symptoms worsening** from clinical notes. 5. Finally predict the **likelihood of readmission** based on these contextual insights. ### **Output Format (JSON)** Return the prediction in the following structured format: ```json { "patient_id": "{patient_id}", "likelihood_of_readmission": "{low | moderate | high}", "reasoning": "{detailed_explanation_based_on_patient_history}" } -
將提示傳遞至微調的 LLM。LLM 會處理提示,並預測重新入院的可能性和原因。以下是來自 LLM 的範例回應:
{ "patient_id": "P67890", "likelihood_of_readmission": "high", "reasoning": "The patient was discharged only 5 days ago, has a history of more than two readmissions to hospitals where the patient received treatment. Recent lab results indicate abnormal kidney function and high liver enzymes. These factors suggest a medium risk of readmission." } -
將預測分類為標準化規模,例如低、中或高。
-
檢閱 LLM 提供的推理,並識別有助於預測的關鍵因素。
-
將定性輸出映射至量化分數。例如,非常高可能等於 0.9 的機率。
-
使用驗證資料集,根據實際重新入學率校正模型輸出。
步驟 4:計算醫院重新入院傾向分數
接下來,您可以計算每位病患的醫院重新入院傾向分數。此分數反映在先前步驟中執行的三個分析的淨影響:潛在的患者結果、患者對藥物和治療的行為,以及患者重新入院的可能性。透過將患者層級重新入院傾向分數彙總至專科層級,然後在醫院層級,您可以獲得臨床醫生、護理經理和管理員的洞察。醫院重新入院傾向分數可協助您依設施、專科或條件評估整體效能。然後,您可以使用此分數來實作主動介入。
-
將權重指派給每個不同的因素 (結果預測、遵循可能性、重新加入)。以下是範例權重:
-
結果預測權重:0.4
-
依從性預測權重:0.3
-
重新加入可能性權重:0.3
-
-
使用下列計算來計算複合分數:
ReadadmissionPropensityScore= (OutcomeScore×OutcomeWeight) + (AdherenceScore×AdherenceWeight) + (ReadmissionLikelihoodScore×ReadmissionLikelihoodWeight) -
確保所有個別分數都位於相同的規模,例如 0 到 1。
-
定義動作的閾值。例如,高於 0.7 的分數會啟動提醒。
根據上述分析和患者重新入學傾向分數,臨床醫生或護理經理可以設定提醒,根據計算的分數來監控其個別患者。如果超過預先定義的閾值,則會在達到該閾值時收到通知。這有助於護理管理員在為其患者建立出院護理計劃時保持主動而不是被動。在 Amazon OpenSearch Service 向量資料庫中以索引形式儲存病患結果、行為和重新入院傾向分數,以便照護管理員可以使用對話式 AI 代理程式無縫擷取。
下圖顯示對話式 AI 代理器的工作流程,臨床醫生或照護管理員可用來擷取有關患者結果、預期行為和重新入院傾向的洞察。使用者可以擷取患者層級、部門層級或醫院層級的洞見。AI 代理器會擷取這些洞見,這些洞見以索引形式存放在 Amazon OpenSearch Service 向量資料庫中。代理程式使用查詢來擷取相關資料並提供量身打造的回應,包括為具有高重新入院風險的患者建議的動作。根據風險等級,代理程式也可以為患者和護理提供者設定提醒。
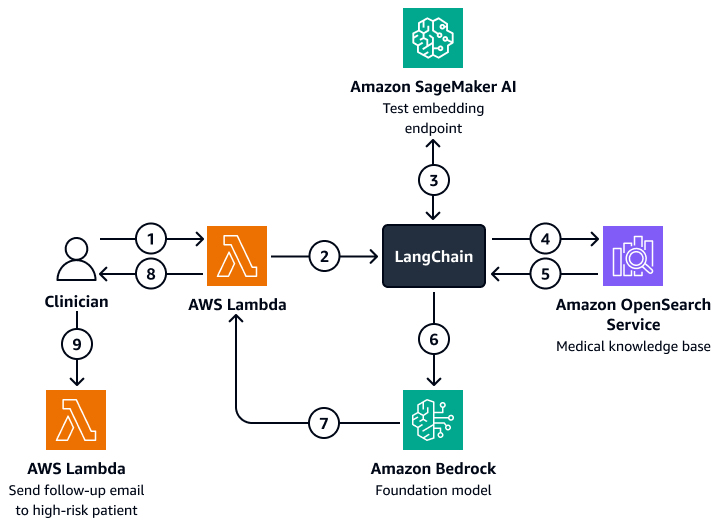
該圖顯示以下工作流程:
-
臨床醫生向對話式 AI 代理器提出問題,該代理程式包含 AWS Lambda 函數。
-
Lambda 函數會啟動LangChain代理程式。
-
LangChain 代理程式會將使用者的問題傳送至 Amazon SageMaker AI 文字內嵌端點。端點內嵌問題。
-
LangChain 代理程式會將內嵌問題傳遞給 Amazon OpenSearch Service 中的醫學知識庫。
-
Amazon OpenSearch Service 會將與使用者查詢最相關的特定洞見傳回給LangChain客服人員。
-
LangChain 代理程式會將查詢和擷取的內容從知識庫傳送至 Amazon Bedrock 基礎模型。
-
Amazon Bedrock 基礎模型會產生回應,並將其傳送至 Lambda 函數。
-
Lambda 函數會將回應傳回給臨床醫生。
-
臨床醫生會啟動 Lambda 函數,將追蹤電子郵件傳送給具有重新入院高風險的患者。
符合 AWS Well-Architected 架構
追蹤患者行為和預測醫院重新入院率的架構整合 AWS 服務了醫學知識圖表和 LLMs,可改善醫療成果,同時符合 AWS Well-Architected Framework
-
卓越營運 – 解決方案是解耦的自動化系統,使用 Amazon Bedrock 和 AWS Lambda 進行即時提醒。
-
安全性 – 此解決方案的設計符合醫療保健法規,例如 HIPAA。您也可以實作加密、精細存取控制和 Amazon Bedrock 護欄,以協助保護病患資料。
-
可靠性 – 架構使用容錯、無伺服器 AWS 服務。
-
效能效率 – Amazon OpenSearch Service 和微調的 LLMs 可以提供快速準確的預測。
-
成本最佳化 – 無伺服器技術和pay-per-inference模型有助於將成本降至最低。雖然使用微調 LLM 的 可能會產生額外費用,但模型會使用 RAG 方法來減少微調程序所需的資料和運算時間。
-
永續性 – 架構透過使用無伺服器基礎設施將資源消耗降至最低。它還支援有效率、可擴展的醫療保健操作。
