本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
使用案例:管理和提升您的醫療保健人員技能
實作人才轉型和提升技能策略,有助於員工繼續熟悉在醫療和醫療保健服務中使用新技術和實務。主動提升技能計畫可確保醫療專業人員可以提供高品質的病患護理、最佳化營運效率,以及符合法規標準。此外,人才轉型促進持續學習的文化。這對於適應不斷變化的醫療保健環境和解決新興的公共健康挑戰至關重要。傳統的訓練方法,例如課堂式訓練和靜態學習模組,可為廣泛的受眾提供統一的內容。他們通常缺乏個人化的學習路徑,這對於解決個別從業人員的特定需求和熟練程度至關重要。這個one-size-fits-all策略可能會導致分離和次佳的知識保留。
因此,醫療保健組織必須採用創新、可擴展且技術驅動的解決方案,這些解決方案可以判斷每位員工在其目前狀態和潛在未來狀態中的差距。這些解決方案應該建議超個人化學習途徑和正確的一組學習內容。這可以有效地為人力資源做好未來醫療保健的準備。
在醫療保健產業中,您可以套用生成式 AI,以協助您了解和提升人力資源。透過大型語言模型 (LLMs) 和進階擷取器的連線,組織可以了解他們目前擁有的技能,並識別未來可能需要的關鍵技能。此資訊可協助您透過招聘新工作者和提升目前人力的技能來彌補差距。使用 Amazon Bedrock 和知識圖表,醫療保健組織可以開發領域特定的應用程式,以促進持續學習和技能開發。
此解決方案所提供的知識可協助您有效管理人才、最佳化人力資源績效、推動組織成功、識別現有技能,以及制定人才策略。此解決方案可協助您在幾週內執行這些任務,而不是幾個月。
解決方案概觀
此解決方案是一種醫療保健人才轉型架構,包含下列元件:
-
智慧型繼續剖析器 – 此元件可以讀取候選者的繼續,並精確擷取候選資訊,包括技能。在專屬訓練資料集上使用 Amazon Bedrock 中微調 Llama 2 模型建置的智慧型資訊擷取解決方案,涵蓋來自超過 19 個產業的履歷和人才設定檔。此 LLM 型程序透過自動化恢復的手動檢閱程序,並將最佳候選項目配對至開放角色,節省數百小時。
-
知識圖表 – 建立在 Amazon Neptune 上的知識圖表,這是人才資訊的統一儲存庫,包括組織和產業的角色和技能分類,使用技能定義、角色及其屬性、關係和邏輯限制來擷取醫療保健人才的語意。
-
技能本質 – 候選技能與理想目前狀態或未來狀態技能 (使用知識圖表擷取) 之間的技能鄰近性探索是透過衡量候選技能和目標狀態技能之間語意相似性的本質演算法達成。
-
學習途徑和內容 – 此元件是一種學習建議引擎,可根據識別的技能差距,從任何供應商的學習材料目錄中建議正確的學習內容。透過分析技能差距並建議優先學習內容來識別每個候選者的最佳提升技能途徑,以便在轉換到新角色期間為每個候選者實現無縫且持續的專業發展。
此雲端型自動化解決方案採用機器學習服務、LLMs、知識圖表和擷取增強生成 (RAG) 技術。它可以在最短時間內擴展以處理數十或數千個恢復、建立即時候選設定檔、識別其目前或潛在未來狀態的差距,然後有效地建議正確的學習內容來填補這些差距。
下圖顯示架構的end-to-end流程。解決方案是以 Amazon Bedrock 中經過微調LLMs 為基礎。這些 LLMs會從 Amazon Neptune 中的醫療保健人才知識庫擷取資料。資料驅動演算法針對每個候選項目的最佳學習途徑提出建議。
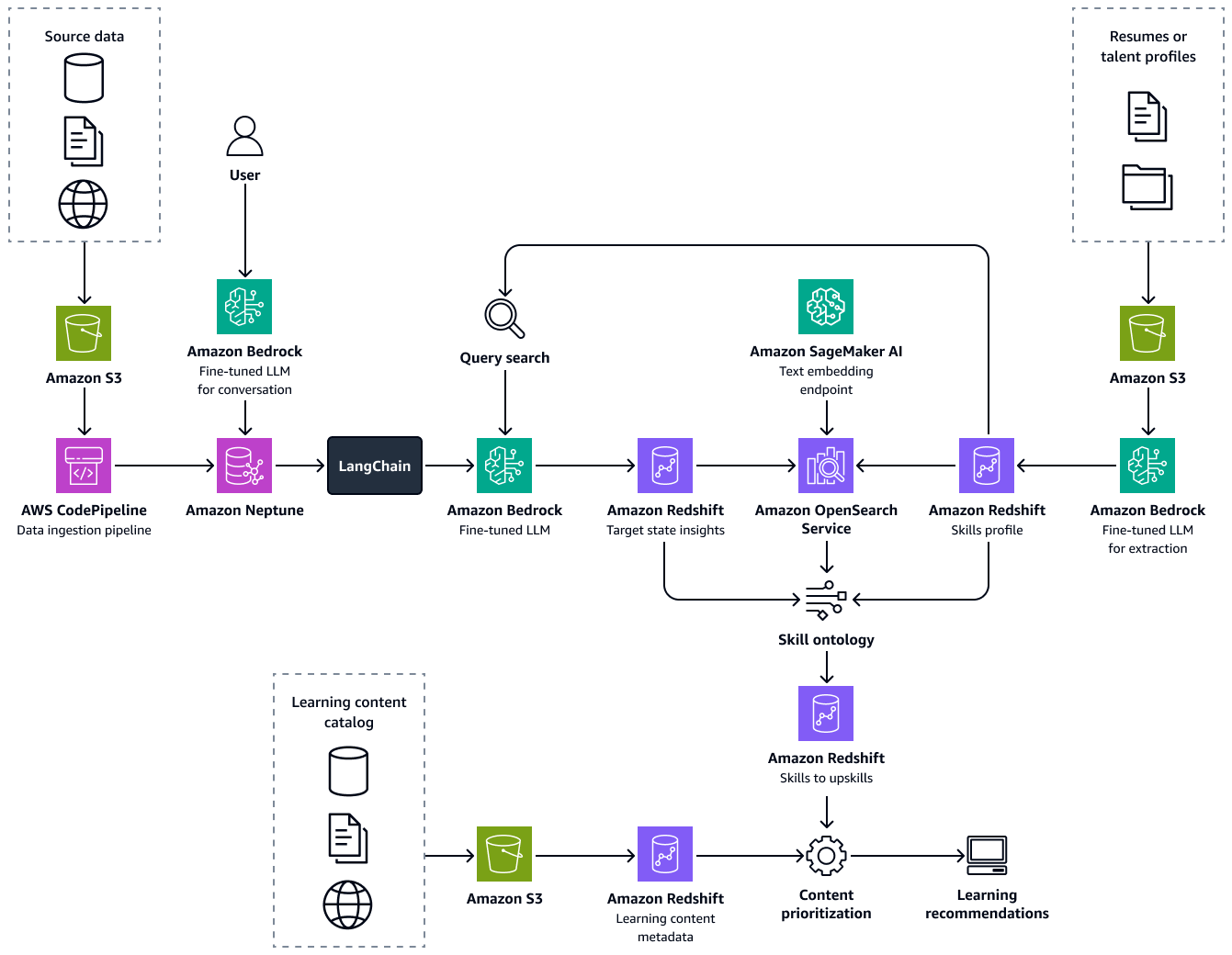
建置此解決方案包含下列步驟:
步驟 1:擷取人才資訊和建立技能描述檔
首先,使用自訂資料集微調 Amazon Bedrock 中的大型語言模型,例如 Llama 2。這會針對使用案例調整 LLM。在訓練期間,您準確且一致地從候選履歷或類似人才設定檔中擷取關鍵人才屬性。這些人才屬性包括技能、目前角色標題、具有日期範圍的體驗標題、教育和認證。如需詳細資訊,請參閱《Amazon Bedrock 文件》中的自訂模型,以改善其使用案例的效能。
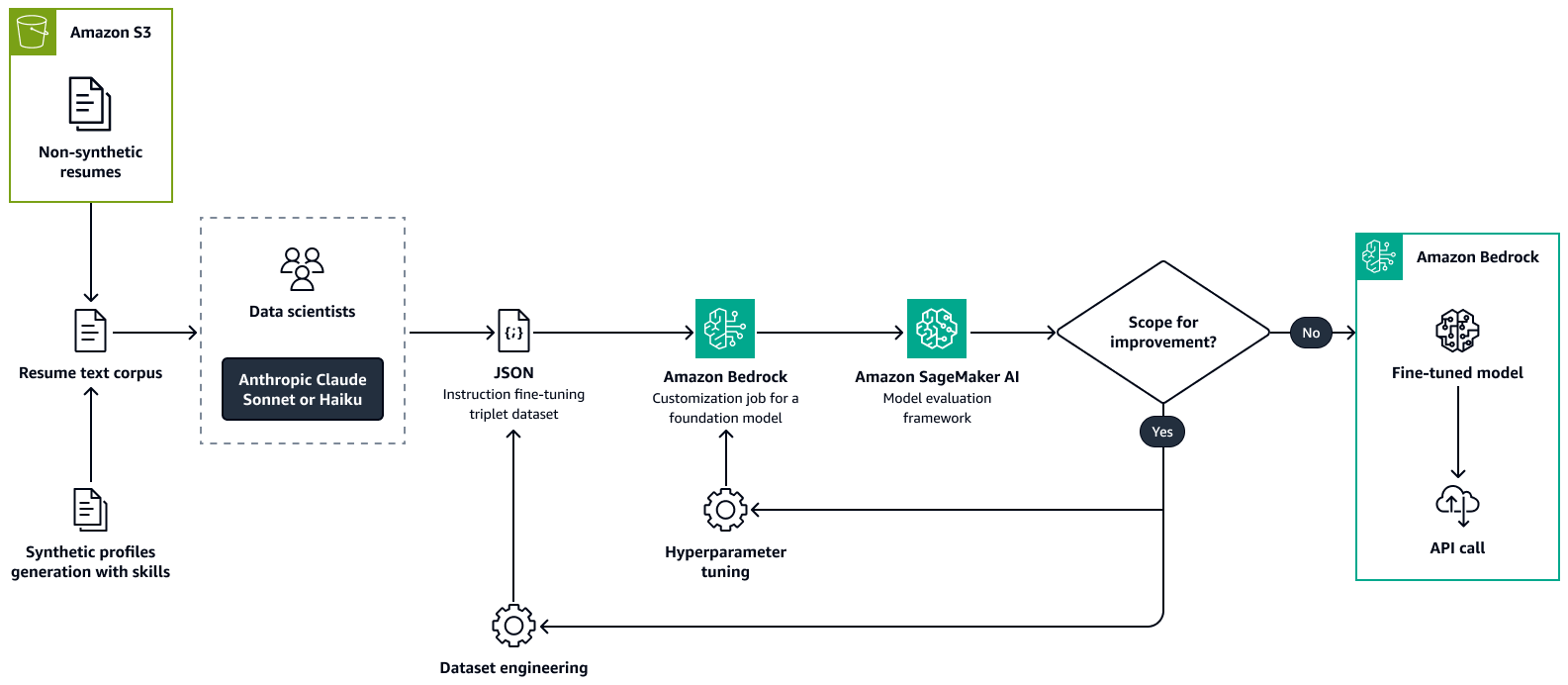
下圖顯示使用 Amazon Bedrock 微調恢復剖析模型的程序。實際和合成建立的恢復都會傳遞至 LLM,以擷取金鑰資訊。一組資料科學家會根據原始原始原始文字驗證擷取的資訊。擷取的資訊接著會使用chain-of-thought
步驟 2:從知識圖表探索role-to-skill的相關性
接下來,您將建立知識圖表,其中封裝組織和醫療保健產業中其他組織的技能和角色分類。這個豐富的知識庫來自 Amazon Redshift 中的彙總人才和組織資料。您可以從各種人力市場資料提供者以及組織特定的結構化和非結構化資料來源收集人才資料,例如企業資源規劃 (ERP) 系統、人力資源資訊系統 (HRIS)、員工恢復、任務描述和人才架構文件。
在 Amazon Neptune 上建置知識圖表。節點代表技能和角色,邊緣代表它們之間的關係。將此圖形填入中繼資料,以包含組織名稱、產業、工作系列、技能類型、角色類型和產業標籤等詳細資訊。
接下來,您將開發圖形擷取增強生成 (Graph RAG) 應用程式。圖形 RAG 是一種從圖形資料庫擷取資料的 RAG 方法。以下是 Graph RAG 應用程式的元件:
-
與 Amazon Bedrock 中的 LLM 整合 – 應用程式使用 Amazon Bedrock 中的 LLM 進行自然語言理解和查詢產生。使用者可以使用自然語言與系統互動。這可讓非技術利益相關者存取。
-
協調和資訊擷取 – 使用 LlamaIndex
LangChain 或協調器來促進 LLM 和 Neptune 知識圖表之間的整合。他們會管理將自然語言查詢轉換為 openCypher 查詢的程序。然後,他們會在知識圖表上執行查詢。使用提示詞工程來指示 LLM 建構 openCypher 查詢的最佳實務。這有助於最佳化查詢以擷取相關子圖,其中包含有關查詢角色和技能的所有相關實體和關係。 -
洞見產生 – Amazon Bedrock 中的 LLM 會處理擷取的圖形資料。它會針對查詢的角色和相關技能,產生有關目前狀態和專案未來狀態的詳細洞見。
下圖顯示從來源資料建置知識圖表的步驟。您可以將結構化和非結構化來源資料傳遞至資料擷取管道。管道會擷取資訊並將其轉換為與 Amazon Neptune 相容的 CSV 大量負載形式。大量載入器 API 會將存放在 Amazon S3 儲存貯體中的 CSV 檔案上傳至 Neptune 知識圖表。對於與人才未來狀態、相關角色或技能相關的使用者查詢,Amazon Bedrock 中的微調 LLM 會透過LangChain協調器與知識圖表互動。協調器會從知識圖表擷取相關內容,並將回應推送至 Amazon Redshift 中的洞察資料表。LangChain 協調器,例如 GraphQAChain

步驟 3:識別技能差距並建議訓練
在此步驟中,您可以準確計算醫療保健專業人員目前狀態與潛在未來狀態角色之間的鄰近性。若要這樣做,您可以透過比較個人的技能集與任務角色來執行技能親和性分析。在 Amazon OpenSearch Service 向量資料庫中,您會儲存技能分類資訊和技能中繼資料,例如技能描述、技能類型和技能叢集。使用 Amazon Bedrock 內嵌模型,例如 Amazon Titan Text Embeddings 模型,將已識別的關鍵技能內嵌至向量。透過向量搜尋,您可以擷取目前狀態技能和目標狀態技能的描述,並執行本體分析。此分析提供目前和目標狀態技能對之間的接近分數。對於每對,您可以使用計算的內科分數來識別技能親和性中的差距。然後,您會建議提升技能的最佳路徑,候選者可以在角色轉換期間考慮這些路徑。
對於每個角色,建議用於提升技能或重新技能的正確學習內容涉及一種系統化方法,從建立完整的學習內容目錄開始。此目錄存放在 Amazon Redshift 資料庫中,會彙總來自各種提供者的內容,並包含中繼資料,例如內容持續時間、難度等級和學習模式。下一個步驟是擷取每個內容提供的關鍵技能,然後將其對應至目標角色所需的個別技能。您可以透過技能鄰近性分析來分析內容所提供的涵蓋範圍,藉此達成此映射。此分析會評估內容所教導的技能與角色所需技能的一致性。中繼資料在為每個技能選擇最適當的內容時扮演關鍵角色,確保學習者收到符合其學習需求的量身打造建議。在 LLMs 從內容中繼資料中擷取技能、執行功能工程,以及驗證內容建議。這可改善提升技能或重新技能程序中的準確性和相關性。
符合 AWS Well-Architected 架構
解決方案符合 AWS Well-Architected Framework
-
卓越營運 – 模組化的自動化管道可增強卓越營運。管道的關鍵元件會解耦和自動化,讓模型更新更快速且更容易監控。此外,自動化訓練管道支援更快速的微調模型版本。
-
安全性 – 此解決方案會處理敏感和個人身分識別資訊 (PII),例如履歷中的資料和人才設定檔。在 AWS Identity and Access Management (IAM) 中,實作精細存取控制政策,並確保只有獲得授權的人員才能存取此資料。
-
可靠性 – 解決方案使用 AWS 服務,例如 Neptune、Amazon Bedrock 和 OpenSearch Service,即使在高需求期間也能提供容錯能力、高可用性和不間斷的洞見存取。
-
效能效率 – Amazon Bedrock 和 OpenSearch Service 向量資料庫中的微調 LLMs 旨在快速準確地處理大型資料集,以提供及時、個人化的學習建議。
-
成本最佳化 – 此解決方案使用 RAG 方法,可減少持續預先訓練模型的需求。系統只會微調特定程序,例如從恢復和結構輸出擷取資訊,而不是重複微調整個模型。這可大幅節省成本。透過將資源密集型模型訓練的頻率和規模降至最低,以及使用pay-per-use的雲端服務,醫療保健組織可以最佳化其營運成本,同時維持高效能。
-
永續性 – 此解決方案使用可擴展的雲端原生服務,以動態方式配置運算資源。這可減少能源消耗和環境影響,同時仍支援大規模、資料密集的人才轉型計畫。
