本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
架構
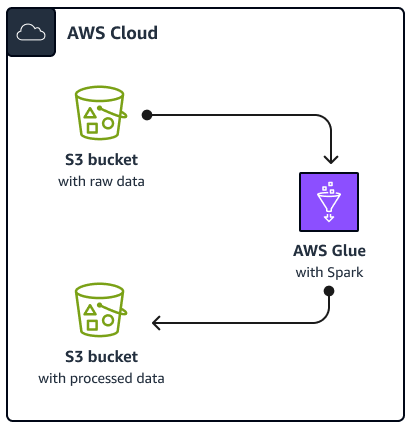
下圖說明本指南中所述解決方案的架構。 AWS Glue 任務會從 Amazon Simple Storage Service (Amazon S3) 儲存貯體讀取資料,這是雲端型物件儲存服務,可協助您儲存、保護和擷取資料。您可以透過 AWS Management Console、 AWS Command Line Interface (AWS CLI) 或 AWS Glue API 啟動任務 AWS Glue Spark SQL。任務 AWS Glue Spark SQL會在 Amazon S3 儲存貯體中處理原始資料,然後將處理的資料存放在不同的儲存貯體中。
舉例來說,本指南說明以 Python和 Spark SQL() 撰寫的基本AWS GlueSpark SQL任務PySpark。此 AWS Glue 任務用於示範Spark SQL調校的最佳實務。雖然本指南著重於 AWS Glue,但本指南中的最佳實務也適用於 Amazon EMR Spark SQL任務。
下圖說明Spark SQL查詢的生命週期。Spark SQL Catalyst Optimizer 會產生查詢計畫。查詢計畫是一系列步驟,如指示,用於存取 SQL 關聯式資料庫系統中的資料。若要開發效能最佳化Spark SQL的查詢計劃,第一步是檢視EXPLAIN計劃、解譯計劃,然後調整計劃。您可以使用Spark SQL使用者介面 (UI) 或Spark SQL歷史記錄伺服器來視覺化計劃。
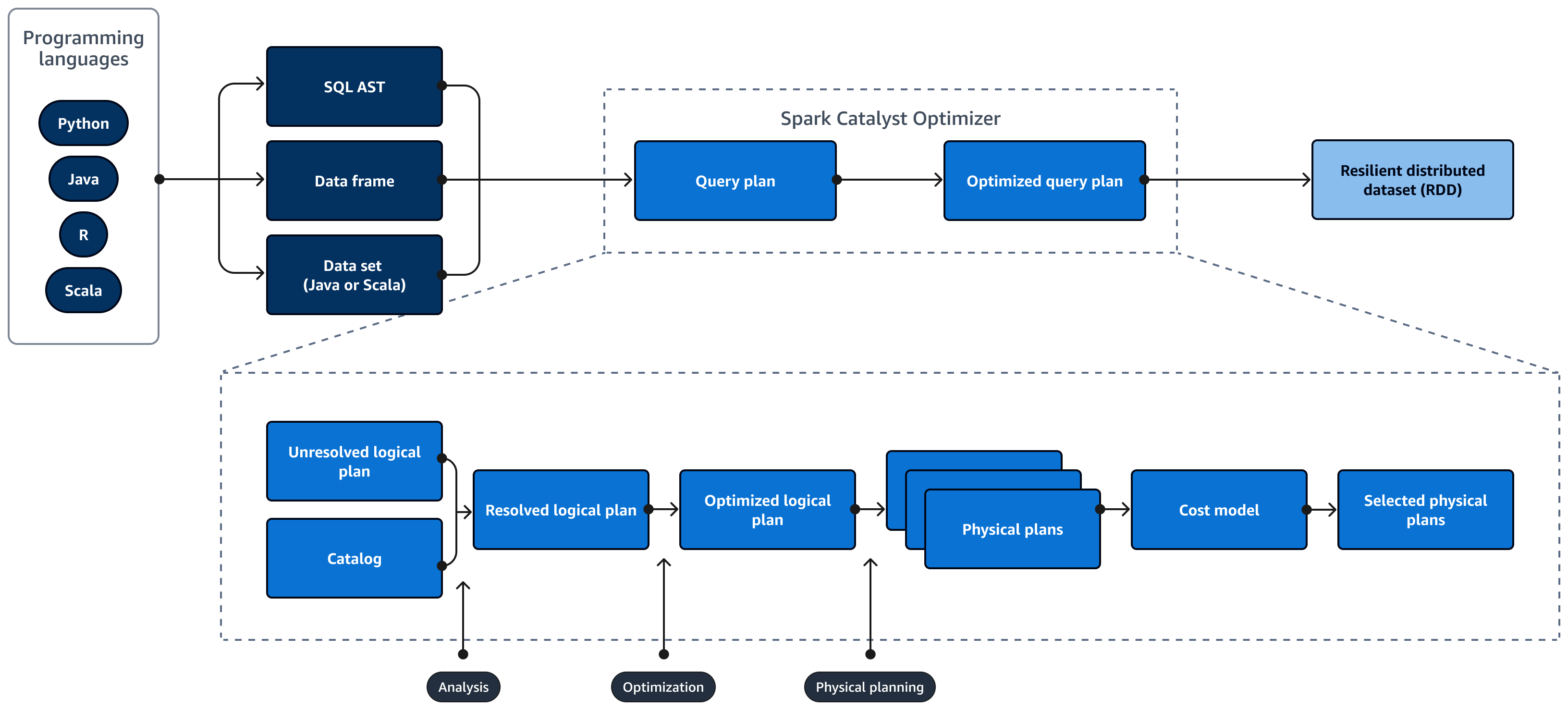
Spark Catalyst Optimizer 會將初始查詢計畫轉換為最佳化的查詢計畫,如下所示:
-
分析和宣告式 APIs – 分析階段是第一步。未解決的邏輯計畫,其中在 SQL 查詢中參考的物件不明或不符合輸入資料表,會產生未繫結屬性和資料類型。Spark SQL Catalyst Optimizer 接著會套用一組規則來建置邏輯計畫。SQL 剖析器可以產生 SQL 抽象語法樹 (AST),並提供此做為邏輯計畫的輸入。輸入也可能是使用 API 建構的資料框架或資料集物件。下表顯示何時應使用 SQL、資料框架或資料集。
SQL 資料框架 資料集 語法錯誤 執行期 編譯時間 編譯時間 分析錯誤 執行期 執行期 編譯時間 如需輸入類型的詳細資訊,請檢閱以下內容:
-
資料集 API 提供類型版本。這會因為高度依賴使用者定義的 lambda 函數而降低效能。RDD 或資料集會以靜態方式輸入。例如,當您定義 RDD 時,您需要明確提供結構描述定義。
-
資料框架 API 提供未輸入的關聯式操作。動態輸入資料影格。類似於 RDD,當您定義資料影格時,結構描述會保持不變。資料仍然是結構化的。不過,此資訊僅在執行時間提供。這可讓編譯器即時撰寫類似 SQL 的陳述式並定義新的資料欄。例如,它可以將資料欄附加到現有的資料框架,而不需要為每個操作定義新的類別。
-
Spark SQL 查詢會在執行時間評估語法和分析錯誤,以提供更快的執行時間。
-
-
目錄 – Spark SQL 使用 Apache Hive Metastore (HMS)管理持久性關聯式實體的中繼資料,例如資料庫、資料表、資料欄和分割區。
-
最佳化 – 最佳化工具會使用啟發式和成本來重寫查詢計劃。它會執行下列動作來產生最佳化的邏輯計畫:
-
刪除資料欄
-
下推述詞
-
重新排序聯結
-
-
實體計畫和規劃器 – Spark SQL Catalyst Optimizer 會將邏輯計畫轉換為一組實體計畫。這表示它會將內容轉換為方法。
-
選取的實體計畫 – Spark SQL Catalyst Optimizer 會選取最具成本效益的實體計畫。
-
最佳化查詢計畫 – Spark SQL執行效能最佳化和成本最佳化的查詢計畫。 Spark SQL記憶體管理會追蹤記憶體用量,並在任務和運算子之間分配記憶體。Spark SQL 鎢引擎可大幅改善Spark SQL應用程式的記憶體和 CPU 效率。它也會實作二進位資料模型處理,並直接在二進位資料上運作。這可避免還原序列化的需求,並大幅降低與資料轉換和還原序列化相關的額外負荷。
