自 2025 年 11 月 1 日起,Amazon Redshift 將不再支援建立新的 Python UDFs。如果您想要使用 Python UDFs,請在該日期之前建立 UDFs。現有的 Python UDFs將繼續如常運作。如需詳細資訊,請參閱部落格文章
本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
將清空時間降至最低
Amazon Redshift 會自動排序資料並在背景中執行 VACUUM DELETE。這可以減少執行 VACUUM 命令的需求。清空可能是耗時的程序。根據您的資料性質,我們建議您採取下列實務,將清空時間降至最低。
決定是否重新索引
您通常可以使用交錯的排序樣式大幅改善查詢效能,但如果排序索引鍵資料欄中值的配送變更,效能可能隨著時間降級。
當您一開始使用 COPY 或 CREATE TABLE AS 載入空白的交錯資料表時,Amazon Redshift 會自動建立交錯的索引。如果您最初使用 INSERT 載入交錯的資料表,您之後必須執行 VACUUM REINDEX,才能初始化交錯的索引。
隨著時間,在您新增具有新排序索引鍵值的資料列時,如果排序索引鍵資料欄中值的配送變更,效能可能降級。如果您的新資料列主要在現有排序索引鍵值的範圍內,則不需要重建索引。執行 VACUUM SORT ONLY 或 VACUUM FULL 來還原排序順序。
查詢引擎可以使用排序順序來有效地選取處理查詢需要掃描的資料區塊。針對交錯的排序,Amazon Redshift 會分析排序索引鍵資料欄值,以判斷最佳排序順序。如果隨著資料列新增,索引鍵值的配送變更或偏移,排序策略將不再最佳,而排序的效能優勢將會降級。若要重新分析排序索引鍵配送您可以執行 VACUUM REINDEX。重建索引操作相當耗時,因此,若要決定資料表是否將可從重建索引獲益,請查詢 SVV_INTERLEAVED_COLUMNS 檢視。
例如,下列查詢顯示使用交錯排序索引鍵的資料表的詳細資訊。
select tbl as tbl_id, stv_tbl_perm.name as table_name, col, interleaved_skew, last_reindex from svv_interleaved_columns, stv_tbl_perm where svv_interleaved_columns.tbl = stv_tbl_perm.id and interleaved_skew is not null;tbl_id | table_name | col | interleaved_skew | last_reindex --------+------------+-----+------------------+-------------------- 100048 | customer | 0 | 3.65 | 2015-04-22 22:05:45 100068 | lineorder | 1 | 2.65 | 2015-04-22 22:05:45 100072 | part | 0 | 1.65 | 2015-04-22 22:05:45 100077 | supplier | 1 | 1.00 | 2015-04-22 22:05:45 (4 rows)
interleaved_skew 的值為比率,指出偏移量。值為 1 表示沒有偏移。如果偏移大於 1.4,VACUUM REINDEX 一般將會改善效能,除非偏移本來就在基礎設定中。
您可以使用 last_reindex 中的日期值來判斷自上次重建索引後經過的時間。
減少未排序區域的大小
載入大量新資料至已包含資料的資料表,或當您不隨著例行維護操作清空資料表時,未排序的區域會成長。若要避免長時間執行清空操作,請使用下列做法:
-
根據定期排程執行清空操作。
如果您以小型增量載入您的資料表 (例如代表資料表中資料列總數的每日更新),定期執行 VACUUM 將有助於確保個別清空操作快速進行。
-
先執行最大型的載入。
如果您需要使用多個 COPY 操作載入新資料表,請先執行最大的載入。執行初始載入至新的或截斷的資料表時,所有資料會直接載入至排序的區域,因此不需要清空。
-
截斷資料表,而非刪除所有資料列。
從資料表刪除資料列不會回收該資料列佔用的空間,直到您執行清空操作為止;不過,截斷資料表會清空資料表和回收磁碟空間,因此不需要清空。或者,捨棄資料表和重新建立它。
-
截斷或捨棄測試資料表。
如果您因測試目的載入少量的資料列至資料表,在完成之前請勿刪除資料列。而是截斷資料表,並在後續生產載入操作中重新載入這些資料列。
-
執行深層複製。
如果使用複合排序索引鍵資料表的資料表有大型未排序的區域,深層複製較清空的速度快得多。深層複製會使用會自動重新排序資料表的大量插入來重新建立和重新填入資料表。如果資料表有大型未排序的區域,深層複製較清空的速度快得多。取捨是您不可以在深層複製操作期間進行並行更新,但清空期間卻可以。如需詳細資訊,請參閱設計查詢的 Amazon Redshift 最佳實務。
減少合併資料列的磁碟區
如果清空操作必須將新資料列合併至資料表的排序區域,清空所需的時間將隨著資料表變大而增加。您可以透過減少必須合併的資料列數量來改善清空效能。
在清空之前,資料表在資料表的標頭中包含排序的區域,接著是未排序的區域,它會在資料列新增或更新時成長。透過 COPY 操作新增一組資料列時,在新增至資料表尾端的未排序區域時,新的一組資料列會依排序索引鍵排序。新資料列會在其自己的集合內排序,但不會在未排序的區域內排序。
下圖說明兩個後續的 COPY 操作之後的未排序區域,其中的排序索引鍵為 CUSTID。為求簡化,此範例顯示複合排序索引鍵,但相同的原則適用於交錯的排序索引鍵,除了未排序區域的影響大於交錯的資料表。
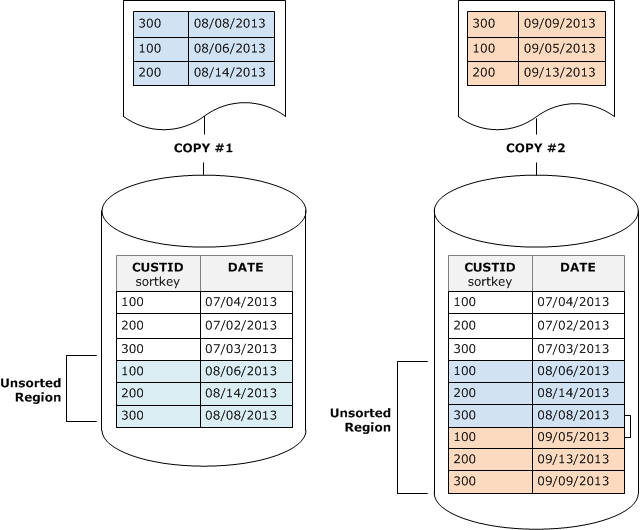
清空會以兩個階段還原資料表的排序順序:
-
將未排序的區域排序為新排序的區域。
第一個階段相當經濟實惠,因為只會重新寫入未排序的區域。如果新排序區域的排序索引鍵值的範圍高於現有範圍,則只需要重新寫入新資料列,清空即完成。例如,如果排序的區域包含 ID 值 1 到 500,而和後續的複製操作會新增大於 500 的索引鍵值,那麼只必須重新寫入未排序的區域。
-
將新排序的區域與先前排序的區域合併。
如果新排序區域中的索引鍵與排序的區域中的索引鍵重疊,那麼 VACUUM 必須合併資料列。從新排序區域 (最下方的排序索引鍵) 的開頭開始,清空會從將合併的資料列從先前排序的區域和新排序的區域寫入至新的一組區塊。
新排序索引鍵範圍與現有排序索引鍵重疊的程度,決定需要重新寫入先前排序區域的程度。如果未排序的索引鍵分散在現有排序範圍中,清空可能需要重新寫入資料表的現有部分。
下表顯示清空如何排序和合併新增至 CUSTID 為排序索引鍵的資料表的資料列。因為每個複製操作會新增一組新資料列,其具有的索引鍵值與現有索引鍵重疊,幾乎必須重新寫入整個資料表。此表顯示單一的排序和合併,但在實務上,大型的清空包含一系列的遞增排序和合併步驟。

如果一組新資料列中排序索引鍵的範圍與現有索引鍵的範圍重疊,合併階段的成本會隨著資料表成長,繼續按比例成長至資料表大小,同時排序階段的成本會維持與未排序區域的大小成比例。在這類情況下,合併階段的成本會使得排序階段的成本相形見絀,如下表所示。

若要判斷資料表重新合併的比例,請在清空操作完成之後查詢 SVV_VACUUM_SUMMARY。下列查詢顯示在 CUSTSALES 隨著時間變大時,六個後續清空的效果。
select * from svv_vacuum_summary where table_name = 'custsales';table_name | xid | sort_ | merge_ | elapsed_ | row_ | sortedrow_ | block_ | max_merge_ | | partitions | increments | time | delta | delta | delta | partitions -----------+------+------------+------------+------------+-------+------------+---------+--------------- custsales | 7072 | 3 | 2 | 143918314 | 0 | 88297472 | 1524 | 47 custsales | 7122 | 3 | 3 | 164157882 | 0 | 88297472 | 772 | 47 custsales | 7212 | 3 | 4 | 187433171 | 0 | 88297472 | 767 | 47 custsales | 7289 | 3 | 4 | 255482945 | 0 | 88297472 | 770 | 47 custsales | 7420 | 3 | 5 | 316583833 | 0 | 88297472 | 769 | 47 custsales | 9007 | 3 | 6 | 306685472 | 0 | 88297472 | 772 | 47 (6 rows)
merge_increments 資料欄提供針對每個清空操作所合併資料量的指示。如果合併增量的數目超過資料表大小成長比例後續清空的增加,即表示因為現有和新排序的區域重疊,每個清空操作會重新合併資料表中增加數量的資料列。
依排序索引鍵順序載入您的資料
如果使用 COPY 命令以排序索引鍵順序載入您的資料,您可能會降低或甚至免除清空的需求。
當以下各項成立時,COPY 會自動新增新資料列至資料表的排序區域:
-
資料表使用複合排序索引鍵搭配僅一個排序資料欄。
-
排序資料欄為 NOT NULL。
-
資料表完全經過排序或為空白。
-
所有新資料列的排序順序高於現有資料列,包括標記進行刪除的資料列。在此執行個體中,Amazon Redshift 會使用排序索引鍵的前八個位元組來判斷排序順序。
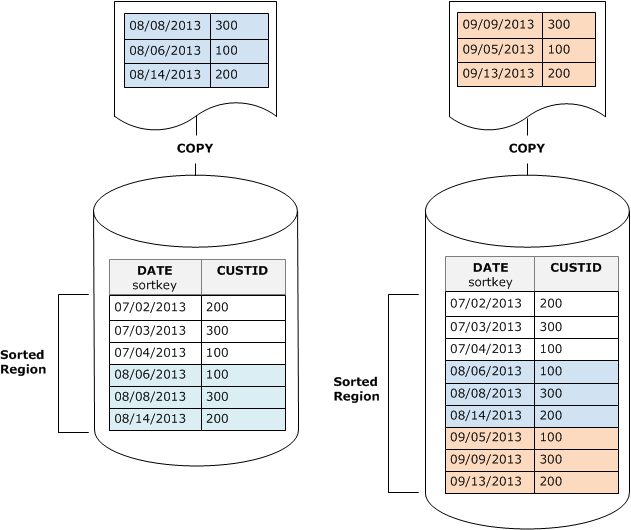
例如,假設您有一個使用客戶 ID 和時間記錄客戶事件的資料表。如果您依客戶 ID 排序,遞增載入新增的新資料列的排序索引鍵範圍很可能會與現有範圍重疊,如先前的範例所示,導致代價高昂的清空操作。
如果您將您的排序索引鍵設為時間戳記資料欄,您的新資料列將以排序順序附加在資料表結尾,如下表所示,降低或甚至消除清空的需求。
使用時間序列資料表來減少儲存的資料
如果您維護資料一段時間,使用一系列資料表,如下圖所述。
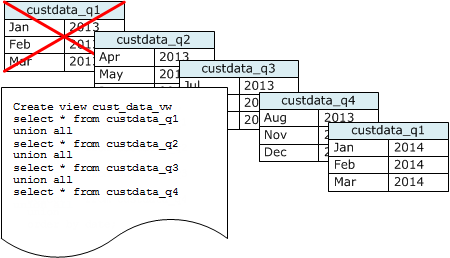
每次您新增一組資料即建立新的資料表,然後刪除系列中最舊的資料表。您會獲得雙重優勢:
-
避免刪除資料列的增加成本,因為 DROP TABLE 操作較大量 DELETE 來的更有效。
-
如果資料表是依時間戳記排序,則不需要清空。如果每個資料表包含一個月的資料,清空將至少必須重新寫入一個月的資料量,即使資料表未依時間戳記排序。
您可以建立 UNION ALL 檢視,供隱藏資料儲存在多個資料表事實的報告查詢使用。如果查詢會依排序索引鍵篩選,查詢規劃器可以有效地略過所有未使用的資料表。UNION ALL 對於其他類型的查詢可能效率較低,因此您應該評估使用該資料表的所有查詢內容中的查詢效能。
