本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
指標與驗證
本指南顯示可用於測量機器學習模型效能的指標和驗證技術。Amazon SageMaker Autopilot 會產生指標,以測量機器學習模型候選項的預測品質。針對候選項計算的指標,是使用指標 MetricDatum 類型的陣列來指定。
Autopilot 指標
下列清單包含目前可用來測量 Autopilot 模型效能的指標名稱。
注意
Autopilot 支援樣本權重。若要進一步了解樣本權重和可用物件指標,請參閱Autopilot 加權指標。
下列是可用的指標。
Accuracy-
正確分類項目的數量與 (正確和不正確) 的分類項目總數的比率。它用於二進位和多類別分類。準確性衡量預測的類別值與實際值的接近程度。準確性指標的值在零 (0) 和一 (1) 之間變化。值 1 表示完美的準確性,0 表示完美的不準確性。
AUC-
曲線下面積 (AUC) 指標用於比較和評估二元分類,適用於傳回機率的演算法,例如邏輯迴歸。若要將機率對應至分類,會將這些機率與閾值進行比較。
相關曲線是接收者的操作特性曲線。該曲線繪製了預測 (或召回) 的真陽性率 (TPR) 與假陽性率 (FPR) 作為閾值的函式,這個閾值以上的預測會被認為是正值。增加閾值結果會導致較少的誤報,但漏報率會增加。
AUC 是此接收者操作特性曲線下的區域。因此,AUC 會針對所有可能的分類閾值,提供模型效能的彙總度量。AUC 評分在 0 和 1 之間變化。評分為 1 表示完美的準確性,評分為一半 (0.5) 表示預測結果不比隨機分類器更好。
BalancedAccuracy-
BalancedAccuracy是衡量準確預測與所有預測比率的指標。這個比率是把真陽性 (TP) 和真陰性 (TN),按照陽性 (P) 和陰性 (N) 的總數標準化之後計算出來的。其用於二元和多類別分類,定義如下:0.5*((TP/P)+(TN/N)),其值範圍從 0 到 1。在不平衡資料集之中,當陽性或陰性相互差異很大時,例如只有 1% 的電子郵件是垃圾郵件時,BalancedAccuracy可以更準確地衡量準確性。 F1-
F1分數是精確度和召回率的諧波平均值,定義如下:F1 = 2*(精確度 * 召回率)/(精確度 + 召回率)。它用於二元分類成類別,傳統上被稱為陽性和陰性。當他們配對到實際 (正確) 類別時,我們可以說預測為真,如果它們配對失敗,則預測為假。精確度是真正的陽性預測之於所有陽性預測的比率,它包括資料集中的誤報。精確度是用來測量當預測出陽性類別的時候,其預測成果的品質。
召回率 (或敏感度) 是真正陽性預測佔所有實際陽性執行個體的比率。召回率衡量模型在資料集中,預測實際類別成員的完整程度。
F1 評分在 0 和 1 之間變化。評分 1 表示效能已達可能性的上限,0 表示最差。
F1macro-
F1macro分數會將 F1 評分套用至多類別分類問題。它透過計算精確度和召回率來做到這一點,然後取他們的諧波平均值來計算每個類別的 F1 分數。最後,F1macro將個別分數做平均,以獲得F1macro分數。F1macro分數在 0 和 1 之間變化。評分 1 表示效能已達可能性的上限,0 表示最差。 InferenceLatency-
推論延遲是指提出模型預測請求後,到從部署模型的即時端點接收模型預測之間的大約時間。此指標以秒為單位測量,且僅適用於集成模式。
LogLoss-
對數損失,也稱為跨熵損失,是一種用於評估機率輸出品質的指標,而不是輸出本身。它用於二元和多類別分類以及神經網路。它也是邏輯迴歸的成本函式。對數損失是一項重要指標,能指出模型何時有高機率發生錯誤預測。其數值介於 0 到無限大之間。如數值為 0,代表完美預測資料的模型。
MAE-
平均絕對誤差 (MAE) 是衡量預測值和實際值的不同程度,將它們與所有值進行平均。MAE 通常用於迴歸分析,以了解模型預測誤差。如為線性迴歸,MAE 表示從預測線到實際值的平均距離。MAE 被定義為絕對值誤差的總和,除以觀測值的數量。其數值範圍從 0 到無限大,數字越小,表示模型越適合資料。
MSE-
均方錯誤 (MSE) 是預測值和實際值之間的平方差異之平均值。它用於迴歸。MSE 值始終為正值。MSE 值越小,模型預測實際值的能力越好。
Precision-
精確度衡量演算法在所有找到的陽性結果中,預測出真陽性 (TP) 的成效。它的定義如下:精確度 = TP/(TP+FP),其數值範圍從零 (0) 到一 (1),並在二元分類中使用。當假陽性的成本高時,精確度是一個重要的指標。舉例來說,一個飛機安全系統被錯誤地判定為可安全飛行,這個假陽性的成本就非常高。假陽性 (FP) 反映了資料中實際上是陰性的陽性預測。
PrecisionMacro-
精確度巨集會計算多類別分類問題的精確度。它透過計算每個類別的精確度,平均這些分數以獲得多個類別的精確度來達成此目的。
PrecisionMacro分數範圍是從零 (0) 到一 (1)。分數高表示這個模型在所有找到的陽性結果中,預測出真陽性 (TP) 的成效顯著,而且是在好幾個類別裡平均算出來的。 R2-
R2,也稱為決定係數,在迴歸分析中,它被用來量化模型能解釋因變數變異程度的多少。數值的範圍從一 (1) 到負一 (-1)。數字越大,表示解釋的變異性越大。
R2值接近零 (0) 的話,就表示這模型對因變數的解釋能力很小。負值表示與資料契合度不佳,且常數函式的效能優於模型。如為線性迴歸,這是一條水平線。 Recall-
召回率衡量演算法在資料集內,正確預測所有的真陽性 (TP) 的表現。真陽性代表其為一個陽性預測,同時也是資料中的實際陽性。召回率定義如下:召回率 = TP/(TP+FN),數值範圍從 0 到 1。分數越高,代表模型在資料中預測出真陽性 (TP) 的能力越好。它是在二元分類中使用。
召回率在檢測癌症時很重要,因為它會用來找到所有的真陽性。假陽性 (FP) 反映了資料中實際上是陰性的陽性預測。通常只測量召回率是不夠的, 因為只要預測每個輸出都是真陽性,就能獲得完美的召回率分數。
RecallMacro-
在多類別分類問題中,
RecallMacro透過為每個類別計算召回率並將得分平均,以計算出多個類別的召回率。RecallMacro數值範圍從 0 到 1。分數越高,就表示這模型預測出資料集裡的真陽性 (TP) 能力越強。真陽性指的是其預測是陽性,而在資料裡實際上也是陽性。通常只測量召回率是不夠的, 因為只要預測每個輸出都是真陽性,就能獲得完美的召回率分數。 RMSE-
均方根誤差 (RMSE) 測量預測值和實際值之間,平方差異值的平方根,並對所有值進行平均。其用於迴歸分析,以了解模型預測誤差。這是能指出存在大型模型錯誤和極端值的重要指標。其數值範圍從零 (0) 到無限大,數字越小,表示模型越適合資料。RMSE 依賴於規模,因此不應該用來比較大小不同的資料集。
對模型候選項自動計算的指標,是由要解決的問題類型決定。
如需 Autopilot 支援的可用指標清單,請參閱 Amazon SageMaker API 參考文件。
Autopilot 加權指標
注意
除了 Balanced Accuracy 和 InferenceLatency 以外,Autopilot 僅在集成模式下支援所有可用指標的樣本權重。BalanceAccuracy 具備專屬的權重方案,用於不需要進行樣本權重的不平衡資料集。 InferenceLatency 不支援樣本權重。在訓練和評估模型時,目標 Balanced Accuracy 和 InferenceLatency 指標都會忽略任何現有的樣本權重。
使用者可以在自己的資料裡加上一列樣本權重,如此一來,就能確保訓練機器學習模型時,每個觀察到的資料都根據它對模型的重要性進行加權。這在一些情況下特別實用,比如說資料集裡的觀察結果重要性不一時,或者資料集裡某一類別的樣本數量跟其他的比起來特別多的時候。根據每個觀察結果的重要性,或是對少數類別的更大重要性進行加權,可以幫助提高模型的整體表現,或確保模型不會偏向多數類別。
如需有關如何在 Studio Classic UI 中建立實驗時傳遞範例權重的資訊,請參閱使用 Studio Classic 建立 Autopilot 實驗中的步驟 7。
有關如何在使用 API 建立自動執行實驗時以程式設計方式傳遞樣本權重的詳細資訊,請參閱以程式設計方式建立一個 Autopilot 實驗中的如何將樣本權重新增至 AutoML 任務。
Autopilot 的交叉驗證
交叉驗證被用來減少模型選取中的過度契合和偏差。如果驗證資料集是從同一個群體中抽出,它也能用來評估模型對未知驗證資料集內數值的預測能力。對訓練執行個體數量有限的資料集進行訓練時,此方法尤其重要。
Autopilot 使用交叉驗證,以超參數最佳化 (HPO) 和整體訓練模式建立模型。Autopilot 交叉驗證程序的第一步,是將資料分割成 k 折疊。
K-折疊分割
K 折分割是一種將輸入訓練資料集分成多個訓練和驗證資料集的方法。該資料集被分成k個大小相同的子樣本,並稱為折疊。接下來,在k-1折疊上訓練模型,並針對剩餘的 k 個折疊 (即驗證資料集) 進行測試。該過程使用不同的資料集重複k次以進行驗證。
下列影像描述當 k = 4 折疊的 K 折分割。每個折疊表示為一列。深色調方塊代表訓練中使用的資料部分。剩餘的淺色方塊表示驗證資料集。

Autopilot 在超參數最佳化 (HPO) 模式和集成模式皆使用 k 折交叉驗證。
您可以部署使用交叉驗證建置的 Autopilot 模型,就像使用任何其他 Autopilot 或 SageMaker AI 模型一樣。
HPO 模式
K 折交叉驗證使用 k 折分割法進行交叉驗證。在 HPO 模式下,Autopilot 會針對具有 50,000 個或更少訓練執行個體的小型資料集,自動套用 K 折交叉驗證。在訓練小型資料集時,執行交叉驗證尤其重要,因為它可以防止過度契合和選取偏差。
HPO 模式對每個用來對資料集建模的候選項演算法,都設定了k值為 5。多個模型在不同的分割上進行訓練,並且模型分開儲存。訓練完成後,會平均每個模型的驗證指標,以產生單一的估計指標。最後,Autopilot 將試用中的模型與最佳驗證指標結合成一個整體模型。Autopilot 使用此整體模型進行預測。
Autopilot 訓練模型的驗證指標,會顯示為模型排行榜中的目標指標。除非您另有指定,否則 Autopilot 會針對其處理的每種問題類型使用預設驗證指標。有關 Autopilot 使用的所有指標清單,請參閱Autopilot 指標。
舉例來說,波士頓住房資料集
交叉驗證平均會增加 20% 的訓練時間。如果資料集複雜,訓練時間也可能會大幅增加。
注意
您可以查看每個折疊的訓練和驗證指標,請參閱/aws/sagemaker/TrainingJobsCloudWatch Logs。如需 CloudWatch Logs 的詳細資訊,請參閱Amazon SageMaker AI 的 CloudWatch Logs。
集成模式
注意
Autopilot 可在集成模式下支援樣本權重。如需支援樣本權重的可用指標的清單,請參閱Autopilot 指標。
在集成模式下,無論資料集大小為何,都會執行交叉驗證。客戶可以提供自己的驗證資料集和自訂資料分割比例,或讓 Autopilot 自動將資料集分割成 80-20% 比例。然後,訓練資料會分割成 k 折以交叉驗證,其中的 k 值由 AutoGluon 引擎決定。集成由多個機器學習模型組成,其中每個模型稱為基礎模型。在 (k-1) 折疊上訓練單一基礎模型,並在剩餘折疊上進行折疊預測。這個過程會在所有 k 折疊上重複進行,而折外 (OF) 預測會被連接起來,形成單一組預測。集成中的所有基本模型,都遵循產生 OF 預測的相同過程。
下列影像描述當 k = 4 折疊的 K 折驗證。每個折疊表示為一列。深色調方塊代表訓練中使用的資料部分。剩餘的淺色方塊表示驗證資料集。
在映像的上半部分的每個折疊中,第一個基礎模型會在訓練資料集上進行訓練後,對驗證資料集進行預測。在每個後續折疊中,資料集都會變更角色。先前用於訓練的資料集現在用於驗證,反之亦然。在k折疊結束時,所有預測都會連接串連形成一組稱為折疊式 (OOF) 預測的預測。每個 n 基礎模型都會重複此程序。
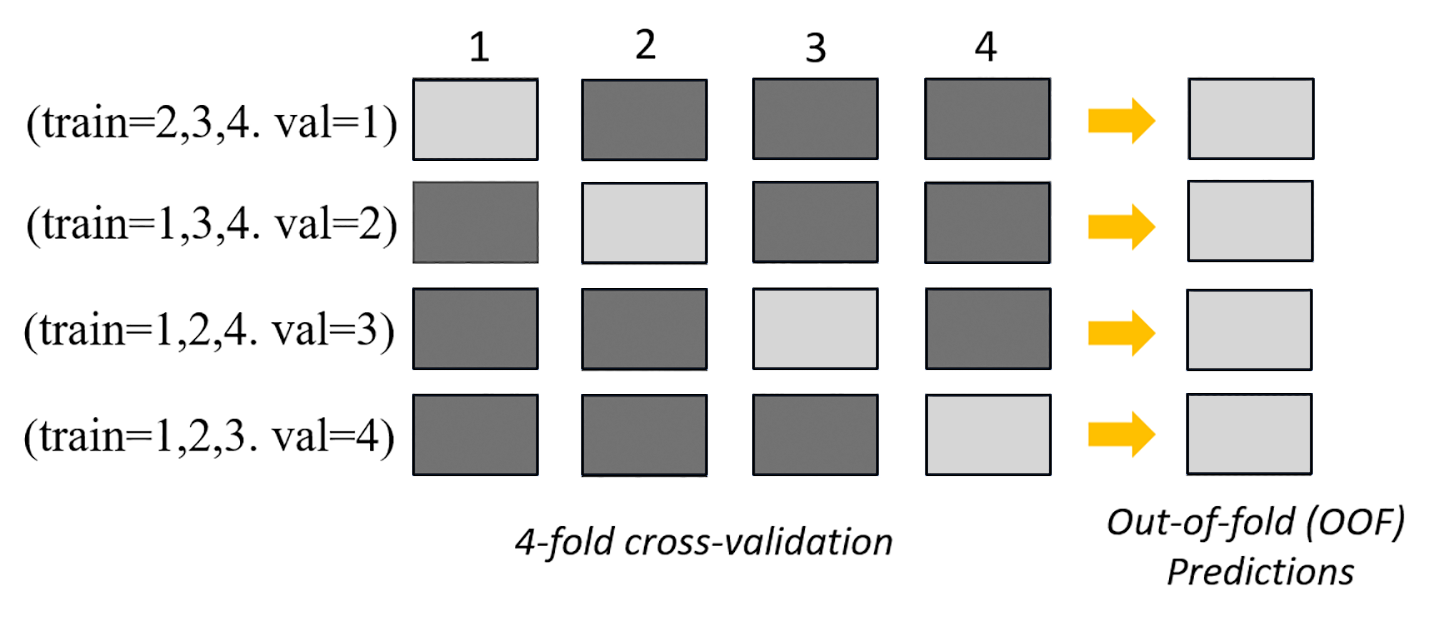
然後,將每個基本模型的 OF 預測用作訓練堆疊模型的功能。堆疊模型會學習每個基本模型的重要性。這些權重用於結合 OF 預測以形成最終預測。驗證資料集的效能會決定哪個基礎模型或堆疊模型最佳,而此模型會以最終模型的傳回。
在集成模式下,您可以提供自己的驗證資料集,或讓 Autopilot 自動執行將輸入資料集分割為 80% 的訓練和 20% 的驗證資料集。然後將訓練資料分成 k 折以進行交叉驗證,並為每個折疊產生 OF 預測和基礎模型。
這些 OF 預測可做為訓練堆疊模型的功能,同時學習每個基本模型的權重。這些權重用於結合 OF 預測以形成最終預測。每個折疊的驗證資料集用於所有基礎模型和堆疊模型的超參數調校。驗證資料集的效能會決定哪個基礎模型或堆疊模型是最佳模型,而此模型會以最終模型的形式傳回。
