本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
擴展訓練
下列各節涵蓋您可能想要擴展訓練的案例,以及如何使用 AWS 資源進行擴展。您可能想要在下列其中一種情況下擴展訓練:
-
從單一 GPU 擴展到許多 GPUs
-
從單一執行個體擴展至多個執行個體
-
使用自訂訓練指令碼
從單一 GPU 擴展到許多 GPUs
機器學習使用的資料量或模型大小可能會導致訓練模型的時間比您願意等待的時間更長。有時,訓練根本沒有作用,因為模型或訓練資料太大。一種解決方案是增加您用於訓練的 GPU 數量。在具有多個 GPU 的執行個體,(例如具有 8 個 GPU 的 p3.16xlarge),資料和處理會分割到八個 GPU。當您使用分散式訓練程式庫時,這可能會導致訓練模型所需的時間近乎線性的加速。與使用一個 GPU 的 p3.2xlarge 相比,它所花費的時間略多於 1/8。
| 執行個體類型 | GPU |
|---|---|
| p3.2xlarge | 1 |
| p3.8xlarge | 4 |
| p3.16xlarge | 8 |
| p3dn.24xlarge | 8 |
注意
SageMaker 訓練所使用的 ml 執行個體類型與對應的 p3 執行個體類型具有相同的 GPU 數量。例如,ml.p3.8xlarge 的 GPU 數目與 p3.8xlarge -4 相同。
從單一執行個體擴展至多個執行個體
如果您想要進一步擴展訓練規模,可以使用更多執行個體。不過,您應該先選擇較大的執行個體類型,然後再新增更多執行個體。請參閱上表,了解每個 p3 執行個體類型有多少 GPU。
如果您已從 p3.2xlarge 的單一 GPU 躍升至 p3.8xlarge 的四個 GPU,但您決定需要更多處理能力,那麼在嘗試增加執行個體計數之前選擇 p3.16xlarge,您可能會看到更好的效能並產生更低的成本。視您使用的程式庫而定,當您在單一執行個體進行訓練時,與使用多個執行個體的情況相比,效能更好、成本更低。
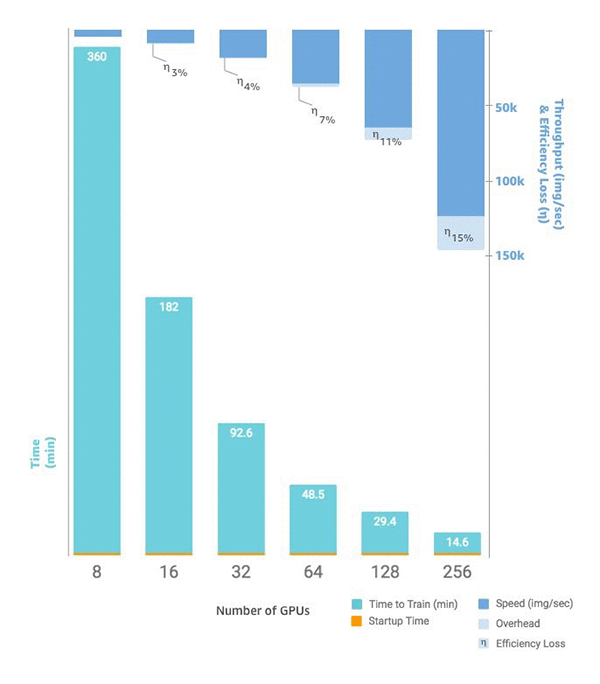
當您準備好擴展執行個體數量時,可以透過設定您的 來使用 SageMaker AI Python estimatorSDKfunction 來執行此操作instance_count。例如,您可以建立 instance_type = p3.16xlarge 與 instance_count =
2。您可以在兩個相同的執行個體擁有 16 個 GPU,而不是單一 p3.16xlarge 的 8 個 GPU。下圖顯示了擴展功能及輸送量,從單一執行個體的 8 個 GPU 開始,
自訂訓練指令碼
雖然 SageMaker AI 可讓您輕鬆地部署和擴展執行個體和 GPUs 的數量,但根據您的選擇架構,管理資料和結果可能非常具有挑戰性,這就是為什麼經常使用外部支援程式庫的原因。這種最基本的分散式訓練形式需要修改訓練指令碼來管理資料分佈。
SageMaker AI 也支援 Horovod 和實作每個主要深度學習架構原生的分散式訓練。如果您選擇使用這些架構的範例,您可以遵循 SageMaker AI 的深度學習容器容器指南,以及各種示範實作的範例筆記本
