本文為英文版的機器翻譯版本,如內容有任何歧義或不一致之處,概以英文版為準。
部署模型以進行即時推論
重要
允許 Amazon SageMaker Studio 或 Amazon SageMaker Studio Classic 建立 Amazon SageMaker 資源的自訂 IAM 政策也必須授予許可,才能將標籤新增至這些資源。需要將標籤新增至資源的許可,因為 Studio 和 Studio Classic 會自動標記他們建立的任何資源。如果 IAM 政策允許 Studio 和 Studio Classic 建立資源,但不允許標記,則嘗試建立資源時可能會發生「AccessDenied」錯誤。如需詳細資訊,請參閱提供標記 SageMaker AI 資源的許可。
AWS Amazon SageMaker AI 的 受管政策 提供建立 SageMaker 資源的許可,已包含建立這些資源時新增標籤的許可。
使用 SageMaker AI 託管服務部署模型有幾個選項。您可以使用 SageMaker Studio 以互動方式部署模型。或者,您可以使用 AWS SDK 以程式設計方式部署模型,例如 SageMaker Python SDK 或 SDK for Python (Boto3)。您也可以使用 部署 AWS CLI。
開始之前
部署 SageMaker AI 模型之前,請找出並記下下列項目:
-
AWS 區域 Amazon S3 儲存貯體所在的
-
存放模型成品的 Amazon S3 URI 路徑
-
SageMaker AI 的 IAM 角色
-
自訂映像的 Docker Amazon ECR URI 登錄檔路徑,其中包含推論程式碼,或 支援且由 支援的內建 Docker 映像架構和版本 AWS
如需每個 中 AWS 服務 可用的清單 AWS 區域,請參閱區域地圖和邊緣網路
重要
存放模型成品的 Amazon S3 儲存貯體必須與您正在建立的模型 AWS 區域 位於相同位置。
與多個模型共用資源使用率
您可以使用 Amazon SageMaker AI 將一或多個模型部署至端點。當多個模型共用端點時,它們會共同利用託管在該處的資源,例如 ML 運算執行個體、CPUs和加速器。將多個模型部署到端點的最靈活方法是將每個模型定義為推論元件。
推論元件
推論元件是 SageMaker AI 託管物件,可用來將模型部署至端點。在推論元件設定中,您可以指定模型、端點,以及模型如何利用端點託管的資源。若要指定模型,您可以指定 SageMaker AI 模型物件,也可以直接指定模型成品和映像。
在 設定中,您可以自訂所需 CPU 核心、加速器和記憶體配置給模型的方式,以最佳化資源使用率。您可以將多個推論元件部署到端點,其中每個推論元件包含一個模型,以及該模型的資源使用率需求。
部署推論元件之後,您可以在 SageMaker API 中使用 InvokeEndpoint 動作時直接叫用相關聯的模型。
推論元件提供下列優點:
- 彈性
-
推論元件會從端點本身分離託管模型的詳細資訊。這可提供更多彈性和控制如何託管模型和搭配端點提供服務。您可以在相同的基礎設施上託管多個模型,而且您可以視需要從端點新增或移除模型。您可以獨立更新每個模型。
- 可擴展性
-
您可以指定要託管的每個模型的複本數量,也可以設定最低數量的複本,以確保模型載入您滿足請求所需的數量。您可以將任何推論元件複本縮減為零,讓另一個複本有擴展的空間。
當您使用下列方式部署模型時,SageMaker AI 會將模型封裝為推論元件:
-
SageMaker Studio Classic。
-
SageMaker Python SDK 可部署模型物件 (其中您將端點類型設定為
EndpointType.INFERENCE_COMPONENT_BASED)。 -
適用於 Python (Boto3) 的 AWS SDK 定義您部署到端點的
InferenceComponent物件。
使用 SageMaker Studio 部署模型
完成下列步驟,透過 SageMaker Studio 以互動方式建立和部署模型。如需 Studio 的詳細資訊,請參閱 Studio 文件。如需各種部署案例的更多演練,請參閱部落格套件,並使用 Amazon SageMaker AI 輕鬆部署傳統 ML 模型和 LLMs – 第 2 部分
準備您的成品和許可
在 SageMaker Studio 中建立模型之前,請完成本節。
您有兩個選項可在 Studio 中帶入成品和建立模型:
-
您可以帶上預先封裝的
tar.gz封存,其中應包含模型成品、任何自訂推論程式碼,以及requirements.txt檔案中列出的任何相依性。 -
SageMaker AI 可以為您封裝成品。您只需在
requirements.txt檔案中攜帶原始模型成品和任何相依性,SageMaker AI 就可以為您提供預設推論程式碼 (或者您可以使用自己的自訂推論程式碼覆寫預設程式碼)。SageMaker AI 支援下列架構的此選項:PyTorch、XGBoost。
除了攜帶模型、您的 AWS Identity and Access Management (IAM) 角色和 Docker 容器 (或 SageMaker AI 具有預先建置容器的所需架構和版本),您還必須授予許可,透過 SageMaker AI Studio 建立和部署模型。
您應該將 AmazonSageMakerFullAccess 政策連接到您的 IAM 角色,以便您可以存取 SageMaker AI 和其他相關服務。若要在 Studio 中查看執行個體類型的價格,您也必須連接 AWS PriceListServiceFullAccess 政策 (或者如果您不想連接整個政策,更具體地說是 pricing:GetProducts動作)。
如果您在建立模型時選擇上傳模型成品 (或上傳範例承載檔案以進行推論建議),則必須建立 Amazon S3 儲存貯體。儲存貯體名稱必須以字 開頭SageMaker AI。也可以接受 SageMaker AI 的替代大寫: Sagemaker或 sagemaker。
建議您使用儲存貯體命名慣例 sagemaker-{。此儲存貯體用於存放您上傳的成品。Region}-{accountID}
建立儲存貯體之後,請將下列 CORS (跨來源資源共用) 政策連接至儲存貯體:
[ { "AllowedHeaders": ["*"], "ExposeHeaders": ["Etag"], "AllowedMethods": ["PUT", "POST"], "AllowedOrigins": ['https://*.sagemaker.aws'], } ]
您可以使用下列任一方法,將 CORS 政策連接至 Amazon S3 儲存貯體:
-
透過 Amazon S3 主控台中的編輯跨來源資源共享 (CORS)
頁面 -
使用 Amazon S3 API PutBucketCors
-
使用 put-bucket-cors AWS CLI 命令:
aws s3api put-bucket-cors --bucket="..." --cors-configuration="..."
建立可部署模型
在此步驟中,您會在 SageMaker AI 中提供成品和其他規格,例如所需的容器和架構、任何自訂推論程式碼和網路設定,藉此建立模型的可部署版本。
執行下列動作,在 SageMaker Studio 中建立可部署模型:
-
開啟 SageMaker Studio 應用程式。
-
在左側導覽窗格中選擇 Models (模型)。
-
選擇可部署模型索引標籤。
-
在可部署模型頁面上,選擇建立。
-
在建立可部署模型頁面上的模型名稱欄位,輸入模型的名稱。
建立可部署模型頁面上還有幾個要填寫的區段。
容器定義區段看起來如下螢幕擷取畫面:
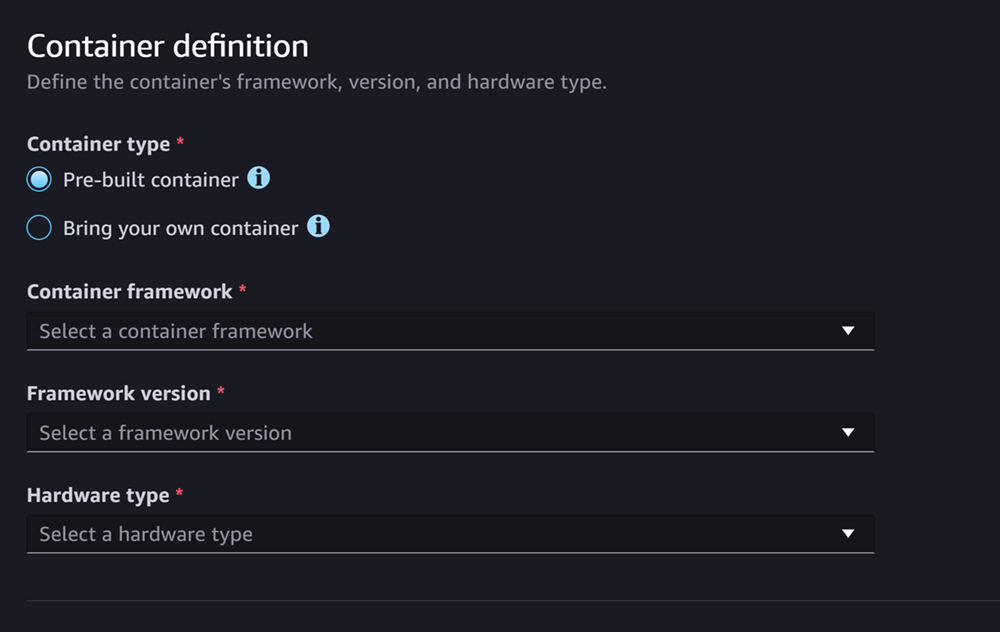
針對容器定義區段,執行下列動作:
-
對於容器類型,如果您想要使用 SageMaker AI 受管容器,請選取預先建置的容器,或者如果您有自己的容器,請選取自帶容器。
-
如果您選取預先建置的容器,請選取您要使用的容器架構、架構版本和硬體類型。
-
如果您選取使用自己的容器,請輸入容器映像的 ECR 路徑的 Amazon ECR 路徑。
然後,填寫成品區段,看起來像下列螢幕擷取畫面:

針對成品區段,執行下列動作:
-
如果您使用 SageMaker AI 支援用於封裝模型成品 (PyTorch 或 XGBoost) 的其中一個架構,則對於成品,您可以選擇上傳成品選項。使用此選項,您可以直接指定原始模型成品、擁有的任何自訂推論程式碼,以及您的 requirements.txt 檔案,而 SageMaker AI 會為您封裝封存。請執行下列操作:
-
針對成品,選取上傳成品以繼續提供您的檔案。否則,如果您已有包含模型檔案、推論程式碼和
requirements.txt檔案的tar.gz封存,請選取輸入 S3 URI 以預先封裝成品。 -
如果您選擇上傳成品,則對於 S3 儲存貯體,輸入 Amazon S3 路徑至您希望 SageMaker AI 在為您封裝成品之後存放成品的儲存貯體。然後,完成下列步驟。
-
對於上傳模型成品,請上傳模型檔案。
-
針對推論程式碼,如果您想要使用 SageMaker AI 提供的預設程式碼來提供推論,請選取使用預設推論程式碼。否則,請選取上傳自訂推論程式碼,以使用您自己的推論程式碼。
-
對於 Upload requirements.txt,上傳文字檔案,其中列出您想要在執行時間安裝的任何相依性。
-
-
如果您未使用 SageMaker AI 支援用於封裝模型成品的架構,則 Studio 會顯示預先封裝成品選項,而且您必須提供已封裝為
tar.gz封存的所有成品。請執行下列操作:-
對於預先封裝成品,如果您的
tar.gz封存已上傳至 Amazon S3,請選取預先封裝模型成品的輸入 S3 URI。 Amazon S3 如果您想要將封存直接上傳至 SageMaker AI,請選取上傳預先封裝的模型成品。 SageMaker -
如果您為預先封裝的模型成品選取輸入 S3 URI,請輸入 S3 URI Amazon S3 S3 路徑。否則,請從本機機器選取並上傳封存。
-
下一節是安全性,如下所示的螢幕擷取畫面:
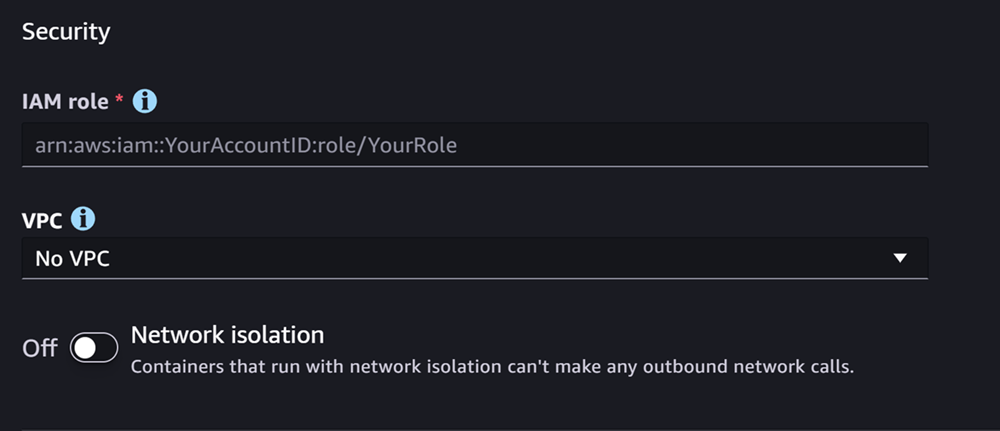
針對安全區段,執行下列動作:
-
針對 IAM 角色,輸入 IAM 角色的 ARN。
-
(選用) 對於虛擬私有雲端 (VPC),您可以選擇 Amazon VPC 來存放模型組態和成品。
-
(選用) 如果您想要限制容器的網際網路存取,請開啟網路隔離切換。
最後,您可以選擇性地填寫進階選項區段,如下所示螢幕擷取畫面:

(選用) 對於進階選項區段,請執行下列動作:
-
如果您想要在建立模型之後執行 Amazon SageMaker 推論建議程式任務,請開啟自訂執行個體建議切換。Inference Recommender 是一種功能,可提供您最佳化推論效能和成本的建議執行個體類型。您可以在準備部署模型時檢視這些執行個體建議。
-
對於新增環境變數,輸入容器的環境變數做為鍵/值對。
-
對於標籤,輸入任何標籤做為鍵值對。
-
完成模型和容器組態後,選擇建立可部署模型。
您現在應該在 SageMaker Studio 中擁有已準備好進行部署的模型。
部署模型
最後,您將您在上一個步驟中設定的模型部署到 HTTPS 端點。您可以將單一模型或多個模型部署到端點。
模型和端點相容性
在您可以將模型部署到端點之前,模型和端點必須具有下列設定的相同值,才能相容:
-
IAM 角色
-
Amazon VPC,包括其子網路和安全群組
-
網路隔離 (啟用或停用)
Studio 會透過以下方式防止您將模型部署至不相容的端點:
-
如果您嘗試將模型部署到新的端點,SageMaker AI 會使用相容的初始設定來設定端點。如果您透過變更這些設定來中斷相容性,Studio 會顯示提醒並防止部署。
-
如果您嘗試部署到現有端點,且該端點不相容,Studio 會顯示提醒並防止部署。
-
如果您嘗試將多個模型新增至部署,Studio 會阻止您部署彼此不相容的模型。
當 Studio 顯示模型和端點不相容的提醒時,您可以選擇在提醒中檢視詳細資訊,以查看哪些設定不相容。
部署模型的其中一種方法是在 Studio 中執行下列動作:
-
開啟 SageMaker Studio 應用程式。
-
在左側導覽窗格中選擇 Models (模型)。
-
在模型頁面上,從 SageMaker AI 模型清單中選擇一或多個模型。
-
選擇部署。
-
針對端點名稱,開啟下拉式選單。您可以選取現有的端點,也可以建立部署模型的新端點。
-
針對執行個體類型,選取您要用於端點的執行個體類型。如果您先前為模型執行了 Inference Recommender 任務,則您建議的執行個體類型會出現在建議標題下的清單中。否則,您會看到一些可能適合您模型的前瞻性執行個體。
JumpStart 的執行個體類型相容性
如果您要部署 JumpStart 模型,Studio 只會顯示模型支援的執行個體類型。
-
針對初始執行個體計數,輸入您要為端點佈建的執行個體初始數量。
-
針對執行個體計數上限,指定端點在擴展時可以佈建的執行個體數量上限,以因應流量增加。
-
如果您要部署的模型是模型中樞中最常使用的 JumpStart LLMs 之一,則執行個體類型和執行個體計數欄位後面會顯示替代組態選項。
對於最熱門的 JumpStart LLM, AWS 具有預先標記的執行個體類型,可最佳化成本或效能。 LLMs 此資料可協助您決定要用於部署 LLM 的執行個體類型。選擇替代組態以開啟包含預先標記資料的對話方塊。面板看起來如下螢幕擷取畫面:
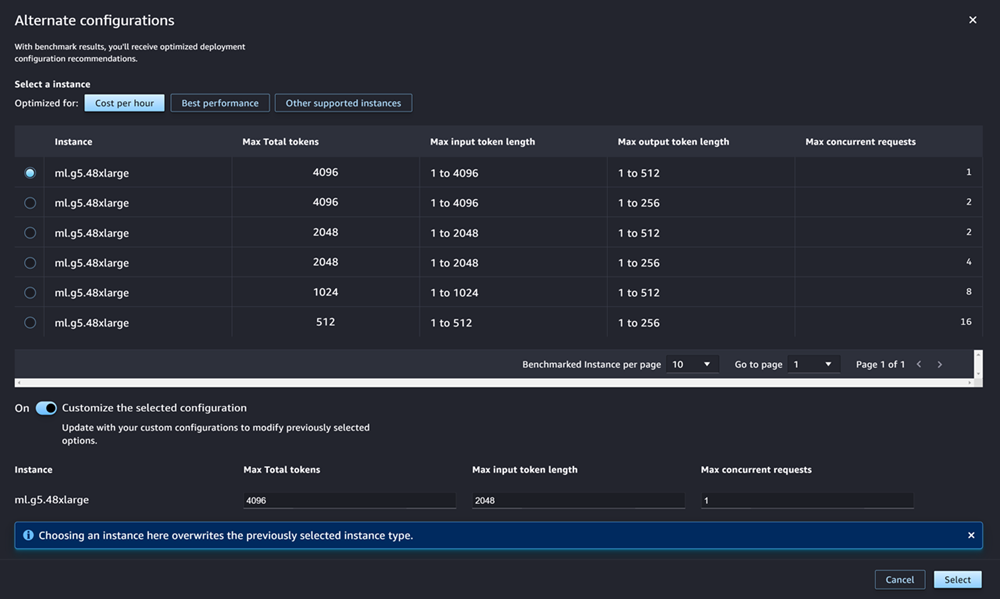
在替代組態方塊中,執行下列動作:
-
選取執行個體類型。您可以選擇每小時成本或最佳效能,以查看最佳化指定模型成本或效能的執行個體類型。您也可以選擇其他支援的執行個體,以查看與 JumpStart 模型相容的其他執行個體類型清單。請注意,在此選取執行個體類型會覆寫步驟 6 中指定的任何先前執行個體選取。
-
(選用) 開啟自訂選取的組態切換以指定最大總字符 (您要允許的字符數量上限,即輸入字符和模型產生的輸出總和)、最大輸入字符長度 (您要允許輸入每個請求的字符數量上限) 和最大並行請求 (一次可處理的請求數量上限)。
-
選擇選取以確認您的執行個體類型和組態設定。
-
-
模型欄位應已填入您要部署的模型名稱。您可以選擇新增模型,將更多模型新增至部署。針對您新增的每個模型,填寫下列欄位:
-
針對 CPU 核心數量,輸入您要專用於模型用量的 CPU 核心。
-
針對最小複本數,輸入您想要在任何指定時間託管在端點上的最小模型複本數。
-
針對最小 CPU 記憶體 (MB),輸入模型所需的記憶體數量下限 (以 MB 為單位)。
-
針對最大 CPU 記憶體 (MB),輸入您要允許模型使用的記憶體數量上限 (以 MB 為單位)。
-
-
(選用) 對於進階選項,請執行下列動作:
-
對於 IAM 角色,請使用預設的 SageMaker AI IAM 執行角色,或指定具有所需許可的自有角色。請注意,此 IAM 角色必須與您在建立可部署模型時指定的角色相同。
-
對於虛擬私有雲端 (VPC),您可以指定要在其中託管端點的 VPC。
-
針對加密 KMS 金鑰,選取 AWS KMS 金鑰來加密連接到託管端點之 ML 運算執行個體的儲存磁碟區上的資料。
-
開啟啟用網路隔離切換以限制容器的網際網路存取。
-
針對逾時組態,輸入模型資料下載逾時 (秒) 和容器啟動運作狀態檢查逾時 (秒) 欄位的值。這些值會決定 SageMaker AI 分別允許將模型下載至容器和啟動容器的時間上限。
-
對於標籤,輸入任何標籤做為鍵值對。
注意
SageMaker AI 會使用與您部署的模型相容的初始值來設定 IAM 角色、VPC 和網路隔離設定。如果您透過變更這些設定來中斷相容性,Studio 會顯示提醒並防止部署。
-
設定您的選項後,頁面看起來應該如下螢幕擷取畫面。

設定部署後,選擇部署以建立端點並部署模型。
使用 Python SDKs部署模型
使用 SageMaker Python SDK,您可以透過兩種方式建置模型。第一個是從 Model或 ModelBuilder類別建立模型物件。如果您使用 Model類別來建立Model物件,則需要指定模型套件或推論程式碼 (取決於您的模型伺服器)、處理用戶端和伺服器之間資料的序列化和還原序列化的指令碼,以及要上傳到 Amazon S3 以供取用的任何相依性。建置模型ModelBuilder的第二個方法是使用 ,您提供模型成品或推論程式碼。 ModelBuilder會自動擷取您的相依性、推斷所需的序列化和還原序列化函數,並封裝您的相依性以建立Model物件。如需有關 ModelBuilder 的詳細資訊,請參閱 使用 ModelBuilder 在 Amazon SageMaker AI 中建立模型 ModelBuilder。
下一節說明兩種建立模型和部署模型物件的方法。
設定
下列範例會準備模型部署程序。它們會匯入必要的程式庫,並定義找到模型成品的 S3 URL。
範例 模型成品 URL
下列程式碼會建置範例 Amazon S3 URL。URL 會在 Amazon S3 儲存貯體中找到預先訓練模型的模型成品。
# Create a variable w/ the model S3 URL # The name of your S3 bucket: s3_bucket = "amzn-s3-demo-bucket" # The directory within your S3 bucket your model is stored in: bucket_prefix = "sagemaker/model/path" # The file name of your model artifact: model_filename = "my-model-artifact.tar.gz" # Relative S3 path: model_s3_key = f"{bucket_prefix}/"+model_filename # Combine bucket name, model file name, and relate S3 path to create S3 model URL: model_url = f"s3://{s3_bucket}/{model_s3_key}"
完整的 Amazon S3 URL 會儲存在變數 中model_url,該變數會用於以下範例。
概觀
您可以使用 SageMaker Python SDK 或適用於 Python 的 SDK (Boto3) 以多種方式部署模型。下列各節摘要說明您針對多種可能方法完成的步驟。這些步驟由以下範例示範。
設定
下列範例會設定將模型部署至 端點所需的資源。
部署
下列範例會將模型部署至 端點。
使用 部署模型 AWS CLI
您可以使用 將模型部署至端點 AWS CLI。
概觀
當您使用 部署模型時 AWS CLI,您可以使用 或不使用推論元件來部署模型。以下各節摘要說明您針對這兩種方法執行的命令。這些命令由以下範例示範。
設定
下列範例會設定將模型部署至 端點所需的資源。
部署
下列範例會將模型部署至 端點。
