This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
AWS accounts
Building an ML platform on AWS starts with setting up AWS accounts, and it is recommended to set up a multi-accounts architecture to meet the needs of an enterprise and its busines units. The following section discusses one multi-account pattern for building out an enterprise ML platform.
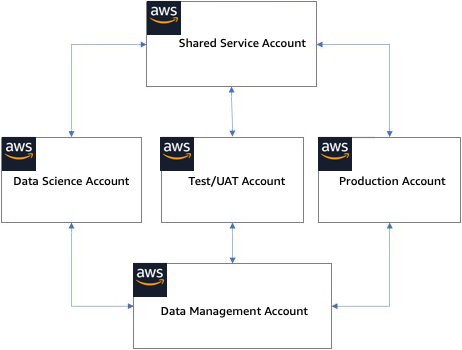
AWS account design
-
Shared Services account — A Shared Services account is used to deploy and operate common services and resources within an enterprise ML platform. Common resources like shared code repositories, library package repositories, Docker image repositories, service catalog factory, and model repository can be hosted in the Shared Services Account. In addition to common resources, the Shared Services account would also host automation pipelines for end-to-end ML workflows. While it is not explicitly listed here, you also need to establish lower environments for the development and testing of common resources and services in the Shared Services account.
-
Data management account — While data management is outside of this document's scope, it is recommended to have a separate data management AWS account that can feed data to the various machine learning workload or business unit accounts and is accessible from those accounts. Similar to the Shared Services account, data management also should have multiple environments for the development and testing of data services.
-
Data science account — The data science account is used by data scientists and ML engineering to perform science experimentation. Data scientists use tools such as Amazon SageMaker AI
to perform exploratory data analysis against data sources such as Amazon Simple Storage Service (Amazon S3), and they build, train, and evaluate the model. They also have access to resources in the Shared Services account such as code, container, and library repositories, as well as access to on-prem resources. Note that data scientists need production datasets to build and train models in the data science account, so the access and distribution of data in the data science account need to be treated as data in a production environment. -
Testing/UAT account — MLOps engineers use testing/UAT accounts to build and train ML models in automated pipelines using automation services such as AWS CodePipeline
and AWS CodeBuild hosted in the shared services account. Data scientists and ML engineers should not have change access to the testing/UAT account. If needed, they can be provided with read access to view model training metrics or training logs. If the model building and training workflows need to be tested in a lower environment before moving to the Testing/UAT account, the workflows can run in the data science account or a separate development account. -
Production account — The production account is used for production model deployment for both online inference and batch inference. Machine learning models should be deployed in the production account using automation pipelines defined in the Shared Services account.
You can use AWS Control Tower
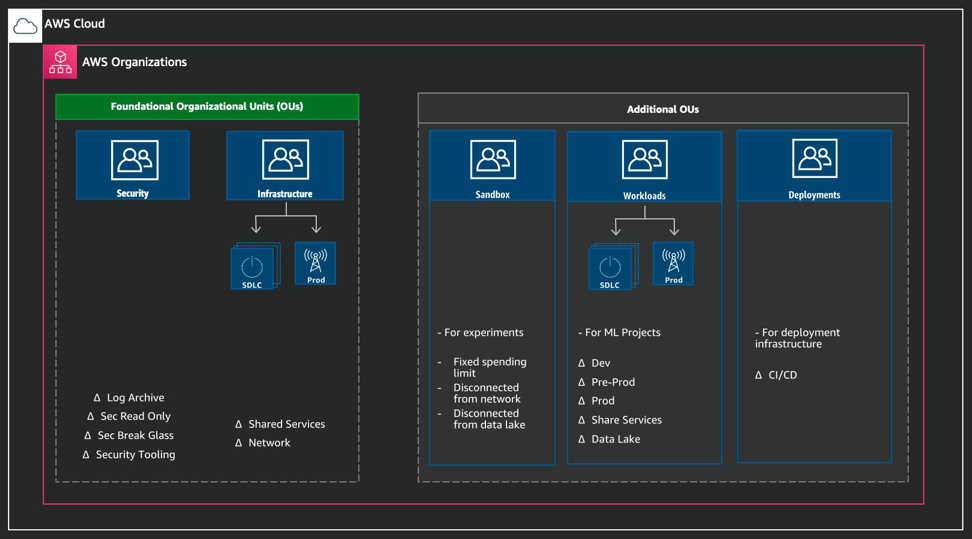
AWS Organizations
For machine learning projects, the accounts can be created within the Workloads OU or Line of Business (LoB) OU, as shown in the figure.
The creation of OUs enables you to set up organizational level pre-defined guardrails. These guardrails consist of AWS Config Rules that are designed to help you maintain the compliance of your environment. You can use them to identify and audit non-compliant resources that are launched in your environment; for example, for data protection, a common set of guardrails may be:
-
Disallow public access to Amazon S3 buckets.
-
Disallow S3 buckets that are not encrypted.
-
Disallow S3 buckets that don't have versioning enabled.
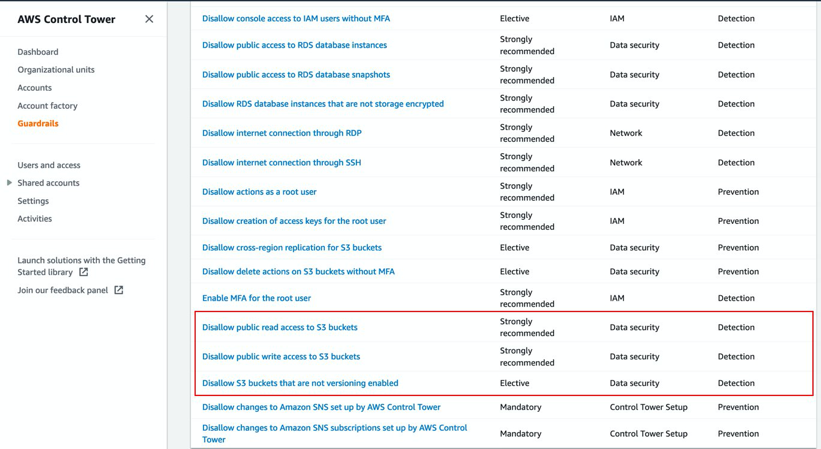
AWS Control Tower Guardrails
To set up additional guardrails, you can use Service Control Policies, which are described in more detail later in this document.
