情境 5:使用 Apache Kafka 即時遙測資料監控
ABC1Cabs 是一家線上計程車預訂服務公司。所有計程車都有物聯網裝置,用於從車輛收集遙測資料。目前,ABC1Cabs 執行 Apache Kafka 叢集,這些叢集旨在即時使用事件、收集系統運作狀態指標、活動追蹤以及將資料提供到基於 Hadoop 叢集內部部署建置的 Apache Spark Streaming 平台。
ABC1Cabs 使用 OpenSearch 儀表板進行業務指標、偵錯、提醒和建立其他儀表板。他們對 Amazon MSK、Amazon EMR with Spark Streaming 以及 OpenSearch Service with OpenSearch 儀表板感興趣。他們的要求是減少 Apache Kafka 和 Hadoop 叢集的維護管理開銷,同時使用熟悉的開放原始碼軟體和 API 來協調其資料管道。下面的架構圖表顯示他們在 AWS 上的解決方案。
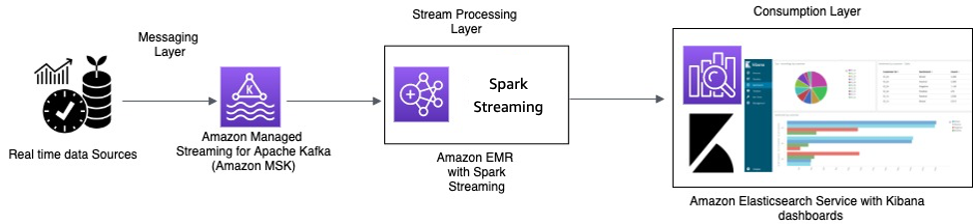
透過 Amazon MSK 即時處理,並在 Amazon EMR 和 Amazon OpenSearch Service with OpenSearch 儀表板使用 Apache Spark Streaming 來進行串流處理
計程車 IoT 裝置收集遙測資料並傳送到來源中樞。來源中樞已設定為將資料即時傳送到 Amazon MSK。使用 Apache Kafka 生產者庫 API,Amazon MSK 已設定為將資料串流到 Amazon EMR 叢集。Amazon EMR 叢集安裝了 Kafka 用戶端和 Spark Streaming,以便能夠使用和處理資料串流。
Spark Streaming 具有接收連接器,可以直接將資料寫入 Elasticsearch 的已定義索引。具有 OpenSearch 儀表板的 Elasticsearch 叢集可用於指標和儀表板。Amazon MSK、Amazon EMR with Spark Streaming,和 OpenSearch Service with OpenSearch 儀表板都是受管服務,AWS 管理不同叢集基礎設施管理的無差異繁重工作,這使您能夠點擊幾下,即可使用熟悉的開放原始碼軟體建置應用程式。下一節將詳細介紹這些服務。
Amazon Managed Streaming for Apache Kafka (Amazon MSK)
Apache Kafka 是開放原始碼平台,使客户能夠擷取串流資料,如點擊流事件、交易、IoT 事件以及應用程式和機器日誌。您可以透過此資訊,開發執行即時分析、執行連續轉換以及即時將此資料分配到資料湖和資料庫的應用程式。
您可以使用 Kafka 作為串流資料存放區,將應用程式與生產者和消費者分離,並在兩個組件之間實現可靠的資料傳輸。雖然 Kafka 是常用的企業資料串流和傳訊平台,但在生產環境中進行設定、擴展和管理可能很困難。
Amazon MSK 負責處理這些管理任務,使您可以在遵循高可用性和安全性之最佳實務的環境中,輕鬆設定、設定和執行 Kafka,以及 Apache Zookeeper。您仍然可以使用 Kafka 的控制面操作和資料平面操作,來管理資料的產生和使用。
Amazon MSK 會執行和管理開放原始碼 Apache Kafka,因此客户可以輕鬆地在 AWS 上遷移和執行現有的 Apache Kafka 應用程式,而無需變更其應用程式程式碼。
擴展
Amazon MSK 提供擴展操作,以便使用者可以在叢集執行時主動擴展叢集。建立 Amazon MSK 叢集時,您可以在叢集啟動時指定代理程式的執行個體類型。您可以從 Amazon MSK 叢集中的少數代理程式開始。然後,使用 AWS Management Console 或 AWS CLI,您就可以將每個叢集擴充規模到數百個代理程式。
您也可以透過變更 Apache Kafka 代理程式的大小或系列來擴展叢集。變更代理程式的大小或系列可讓您靈活地調整 Amazon MSK 叢集運算容量,以應對工作負載的變更。使用 Amazon MSK 規模調整和定價試算表
建立 Amazon MSK 叢集後,您可以增加每個代理程式的 EBS 儲存量,但儲存量減少除外。在此向上擴展操作期間,儲存磁碟區仍然可供使用。其提供兩種擴展操作:自動擴展和手動擴展。
Amazon MSK 支援使用應用程式 Auto Scaling 政策自動擴展叢集儲存,以應對使用量的增加。自動擴展政策會設定目標磁碟利用率和擴展容量上限。
儲存利用率閾值有助於 Amazon MSK 觸發自動擴展操作。要使用手動擴展來增加儲存空間,請等待叢集處於 ACTIVE 狀態。儲存擴展在事件之間至少有六個小時的冷卻時間。即使該操作可立即使其他儲存空間可用,但該服務在叢集上執行的最佳化最長可能需要 24 小時或更長時間。
這些最佳化的持續時間與儲存空間大小成正比。此外,它還在 AWS 區域內提供多可用區域複寫,以提供高可用性。
組態
Amazon MSK 為代理程式,主題和 Apache ZooKeeper 節點提供預設組態。您也可建立自訂組態,將其用於建立新的 Amazon MSK 叢集或更新現有叢集。建立 MSK 叢集,而不指定自訂 Amazon MSK 組態時,Amazon MSK 會建立並使用預設組態。如需預設值的清單,請參閱 Apache Kafka Configuration。
出於監控目的,Amazon MSK 會收集 Apache Kafka 指標,並將其傳送到 Amazon CloudWatch,您可以在其中檢視這些指標。系統會自動收集您為 MSK 叢集設定的指標,並將其推送到 CloudWatch。監控消費者延遲,可讓您識別未跟上主題中最新可用資料的緩慢或卡住的消費者。在必要時,您可以採取補救措施,例如擴展或重新啟動這些消費者。
遷移至 Amazon MSK
您可以透過以下方法之一實現從內部部署到 Amazon MSK 的遷移。
-
MirrorMaker2.0 — MirrorMaker2.0 (MM2) MM2 是以 Apache Kafka Connect 架構為基礎的多叢集、資料複寫引擎。MM2 是 Apache Kafka 來源連接器和接收連接器的組合。您可以使用單個 MM2 叢集,在多個叢集之間遷移資料。MM2 會自動偵測新的主題和分區,同時確保在叢集之間同步主題組態。MM2 支援遷移 ACL、主題組態和偏移轉換。如需遷移的更多詳細資訊,請參閲使用 Apache Kafka 的 MirrorMaker 遷移叢集。MM2 可用於與自動複寫主題組態和偏移轉換相關的使用案例。
-
Apache Flink — MM2 支援至少一次的語意。記錄可以複寫到目的地,而消費者應具備等冪處理複寫記錄的能力。在精確一次的情境下,需要語意,客户才可以使用 Apache Flink。其提供實現精確一次語意的替代方案。
Apache Flink 還可用於將資料提交到目的地叢集之前,需要映射或轉換動作的情境。Apache Flink 為 Apache Kafka 提供連接器,其中包含可以從某個 Apache Kafka 叢集讀取資料並寫入到另一個叢集的來源和接收。Apache Flink 可以透過啟動 Amazon EMR 叢集在 AWS 上執行,或使用 Amazon Kinesis Data Analytics 將 Apache Flink 作為應用程式執行。
-
AWS Lambda— 透過支援 Apache Kafka 作為 AWS Lambda
的事件來源,客户現在可以透過 Lambda 函數使用來自主題的訊息。AWS Lambda 服務在內部輪詢來自事件來源的新記錄或訊息,然後同步叫用目標 Lambda 函數來使用這些訊息。Lambda 會批次讀取訊息,並在事件酬載中向函數批次提供訊息以供處理。然後,您可以將使用的訊息轉換和/或直接寫入目的地 Amazon MSK 叢集。
Amazon EMR 和 Spark Streaming
Amazon EMR
Amazon EMR 提供 Spark 的功能,可用於啟動 Spark Streaming 以使用來自 Kafka 的資料。Spark Streaming 是核心 Spark API 的延伸,可實現即時資料串流的可擴展、高輸送量、容錯串流處理。
您可以在建立叢集時,使用 AWS Command Line Interface
處理過的資料可以被推送到檔案系統、資料庫和即時儀表板。
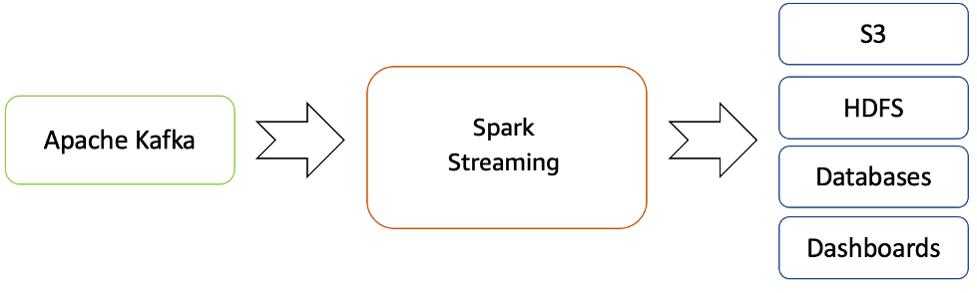
從 Apache Kafka 到 Hadoop 生態系統的即時串流
預設情況下,Apache Spark Streaming 具有微批次執行模型。但是,自 Spark 2.3 推出以來,Apache 推出了一種稱為「連續處理」的新低延遲處理模式,該模式可以實現低至一毫秒的端到端延遲,並且有至少一次的保證。
無需變更查詢中的 Dataset/DataFrames 操作,您可以根據應用程式要求選擇模式。Spark Streaming 的一些好處是:
-
它將 Apache Spark 的語言整合 API
用於串流處理,讓您以編寫批次處理任務的方式編寫串流處理任務。 -
其支援 Java、Scala 和 Python。
-
其可以立即復原遺失的工作和運算子狀態 (例如滑動時段),而不需要您編寫任何額外的程式碼。
-
透過在 Spark 上執行,Spark Streaming 允許您重複使用相同的程式碼進行批次處理,根據歷史資料連接串流,或對串流狀態執行臨機查詢,並建置功能強大的互動式應用程式,而不僅僅是分析。
-
使用 Spark Streaming 處理資料串流後,OpenSearch Sink Connector 可用於向 OpenSearch Service 叢集寫入資料,而 OpenSearch Service with OpenSearch 儀表板也可用作消費層。
Amazon OpenSearch Service with OpenSearch 儀表板。
OpenSearch Service 是受管服務,可讓您輕鬆部署、操作和擴展 AWS 雲端中的 OpenSearch 叢集。OpenSearch 是使用案例 (日誌分析的、即時應用程式監控和點擊流分析) 熱門開放原始碼搜尋和分析引擎。
OpenSearch 儀表板
OpenSearch 儀表板提供了與 OpenSearch
總結
您可以藉助 Apache Kafka 在 AWS 上提供的受管服務專注於消費,而不是管理代理程式之間的協調,這通常需要對 Apache Kafka 有詳細的了解。諸如高可用性、代理程式可擴展性和精細存取控制等功能皆由 Amazon MSK 平台管理。
ABC1Cabs 利用這些服務建置生產應用程式,而無需基礎設施管理專業知識。他們可以專注於處理層,以使用來自 Amazon MSK 的資料,並進一步傳播到視覺化層。
Amazon EMR 上的 Spark Streaming 有助於即時分析串流資料,並在視覺化層 Amazon OpenSearch Service 上的 OpenSearch 儀表板
