步驟 4:評估預測器
機器學習中的常見工作流程包括以訓練集訓練一組模型或模型的組合,以及在鑑效資料集上評估其準確性。本節討論如何分割歷史資料,以及要使用哪些指標來評估時間序列預測的模型。對於預測,回測技術是評估預測準確性的主要工具。
回測
適當的評估和回測架構,是藉由機器學習的應用獲致成功的首要因素之一。憑藉對模型的成功回測,您對於模型的未來預測能力將更有信心。此外,您可以透過超參數最佳化 (HPO) 來調整模型、學習模型組合,以及啟用中繼學習和 AutoML。
時間序列預測中的時間特性,使其在評估和回測方法方面與應用機器學習的其他領域有所不同。在 ML 任務中,若要藉由回測評估預測誤差,通常可按項目來分割資料集。例如,若要在影像相關任務中進行交叉驗證,您可以訓練某個百分比的圖片,然後將其他部分用於測試和驗證。在預測中,您主要需按時間分割 (而在較低程度上按項目分割),以確保您不會將訓練集的資訊流入測試集或驗證集中,且您將盡可能真實模擬生產案例。
按時間分割必須謹慎,因為您要選擇的是多個時間點,而不是單一時間點。若是單一時間點,準確性將過於依賴於藉由分割點而定義的預測開始日期。滾動式預測評估可讓您在多個時間點進行一系列分割,並輸出平均結果,而產生更穩健可靠的回測結果。下圖說明四種不同的回測分割。

此圖例顯示訓練集大小增加、但測試集大小不變的四種不同的回測案例
在上圖中,所有回測案例在其整個過程中都有可用的資料,而能夠根據實際值評估預測值。
需要多個回測時段的原因是,現實世界中的多數時間序列通常是非靜止的。案例研究中的電子商務企業將總部設在北美洲,其產品需求許多都是來自 Q4 旺季的推動,尤其是感恩節前後和聖誕節之前的高峰。在 Q4 購物旺季,時間序列的變化性會高於一年中的其餘時間。有了多個回測時段,您即可在更平衡的設定中評估預測模型。
下圖針對每個回測案例顯示 Amazon Forecast 術語中的基本要素。Amazon Forecast 會自動將資料分割到訓練資料集和測試資料集。Amazon Forecast 會使用在 create_predictor API 中指定為參數的 BackTestWindowOffset 參數來決定如何分割輸入資料,或使用其 ForecastHorizon 的預設值來決定。
在下圖中,BackTestWindowOffset 和 ForecastHorizon 參數不相等,您會看到較為典型的第一種情況。BackTestWindowOffset 參數會定義虛擬預測開始日期,在下圖中顯示為虛線垂直線。這可用來回答以下假設問題:如果模型在這一天部署,將會有何預測? ForecastHorizon 會定義從虛擬預測開始日期到預測的時階數。
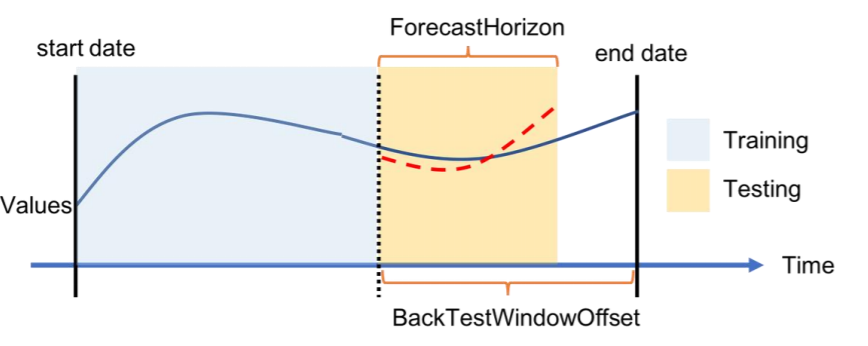
此圖例顯示單一回測案例及其在 Amazon Forecast 中的組態
Amazon Forecast 可匯出在回測期間產生的預測值和準確性指標。匯出的資料可用來就特定的時間點和分位數評估特定項目。
預測分位數和準確性指標
預測分位數可提供預測的上限和下限。例如,對於使用預測類型 0.1 (P10)、0.5 (P50) 和 0.9 (P90) 產生的值範圍,我們可稱之為 P50 預測的 80% 信賴區間。藉由產生對 P10、P50 和 P90 的預測,您可以預期實際值有 80% 的時間會落在這些界限內。
本白皮書將在步驟 5 中進一步討論分位數。
Amazon Forecast 會使用加權分位數損失 (wQL)、均方根誤差 (RMSE) 和加權絕對百分比誤差 (WAPE) 準確性指標來評估回測期間的預測器。
加權分位數損失 (wQL)
加權分位數損失 (wQL) 誤差指標會測量模型預測在指定分位數上的準確性。這在預測不足和過度預測的成本不同時尤有效用。設定 wQL 函數的權重 (τ),會自動納入用於預測不足和過度預測的不同懲罰。
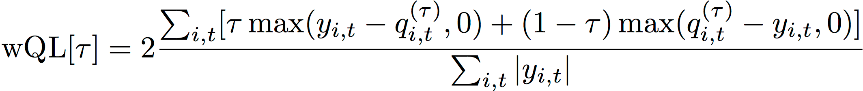
wQL 函數
其中:
-
τ — {0.01, 0.02, ..., 0.99} 集合中的一個分位數
-
qi,t(τ) — 模型預測的 τ-quantile (τ 分位數)。
-
yi,t — 在點 (i,t) 處的觀測值
加權絕對百分比誤差 (WAPE)
加權絕對百分比誤差 (WAPE) 是測量模型準確性的常用指標。它會測量預測值與觀測值的整體偏差。
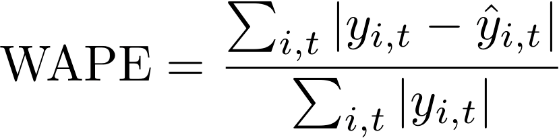
WAPE
其中:
-
yi,t - 在點 (i,t) 處的觀測值
-
ŷi,t - 在點 (i,t) 處的預測值
Forecast 會使用平均值預測作為預測值 ŷi,t。
均方根誤差 (RMSE)
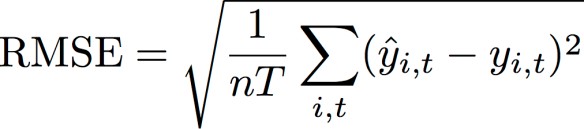
均方根誤差 (RMSE) 是測量模型準確性的常用指標。和 WAPE 一樣,它會測量估計值與觀察值的整體偏差。
其中:
-
yi,t - 在點 (i,t) 處的觀測值
-
ŷi,t - 在點 (i,t) 處的預測值
-
nT - 測試集中的資料點數量
Forecast 會使用平均值預測作為預測值 ŷi,t。計算預測器指標時,nT 是回測時段中的資料點數量。
WAPE 和 RMSE 的相關問題
在大多數的情況下,可在內部或從其他預測工具產生的點預測,應會與 p50 分位數或平均值預測相符。對於 WAPE 和 RMSE,Amazon Forecast 會使用平均值預測來表示預測值 (yhat)。
若 wQL[tau] 方程式中的 tau = 0.5,則兩個權重會相等,且 wQL[0.5] 會降至點預測常用的加權絕對百分比誤差 (WAPE):
![wQL[0.5] 方程式的圖片。](images/wql.png)
其中,yhat = q(0.5) 是運算預測。wQL 公式中使用縮放係數 2 來取消 0.5 係數,以取得精確的 WAPE[median] 運算式。
請注意,上述 WAPE 定義與平均絕對百分比誤差 (MAPE
不同於使用加權分位數損失指標,tau 不等於 0.5 時,每個分位數中的固有偏差無法藉由 WAPE (其權重相等) 之類的計算得出。WAPE 的缺點還包括它不是對稱的、對微小數字的百分比誤差會過度膨脹,以及只是一個逐點指標。
RMSE 是 WAPE 中的誤差項平方,在其他 ML 應用程式中則是常見的誤差指標。RMSE 指標較適用於個別誤差具有一致幅度的模型,因為較大的誤差變化將會超比例推升 RMSE。由於平方誤差,一些不當預測的值在其他方面皆良好的預測中可能會推升 RMSE。此外,由於平方項,較小的誤差項在 RMSE 中的權重會低於 WAPE 中的權重。
準確性指標可用來進行預測的定量評估。對大規模的比較 (方法 A 整體上是否優於方法 B) 而言,這一點格外重要。不過,以個別 SKU 的視覺效果予以補強,往往也很重要。
