AWS AppSync resolver mapping template overview
Note
We now primarily support the APPSYNC_JS runtime and its documentation. Please consider using the APPSYNC_JS runtime and its guides here.
AWS AppSync lets you respond to GraphQL requests by performing operations on your resources. For each GraphQL field you wish to run a query or mutation on, a resolver must be attached in order to communicate with a data source. The communication is typically through parameters or operations that are unique to the data source.
Resolvers are the connectors between GraphQL and a data source. They tell AWS AppSync how to
translate an incoming GraphQL request into instructions for your backend data source, and how
to translate the response from that data source back into a GraphQL response. They are written
in the Apache Velocity
Template Language (VTL)
There are two types of resolvers in AWS AppSync that leverage mapping templates in slightly different ways:
-
Unit resolvers
-
Pipeline resolvers
Unit resolvers
Unit resolvers are self-contained entities which include a request and response template only. Use these for simple, single operations such as listing items from a single data source.
-
Request templates: Take the incoming request after a GraphQL operation is parsed and convert it into a request configuration for the selected data source operation.
-
Response templates: Interpret responses from your data source and map it to the shape of the GraphQL field output type.
Pipeline resolvers
Pipeline resolvers contain one or more functions which are performed in sequential order. Each function includes a request template and response template. A pipeline resolver also has a before template and an after template that surround the sequence of functions that the template contains. The after template maps to the GraphQL field output type. Pipeline resolvers differ from unit resolvers in the way that the response template maps output. A pipeline resolver can map to any output you want, including the input for another function or the after template of the pipeline resolver.
Pipeline resolver functions enable you to write common logic that you can reuse across multiple resolvers in your schema. Functions are attached directly to a data source, and like a unit resolver, contain the same request and response mapping template format.
The following diagram demonstrates the process flow of a unit resolver on the left and a pipeline resolver on the right.
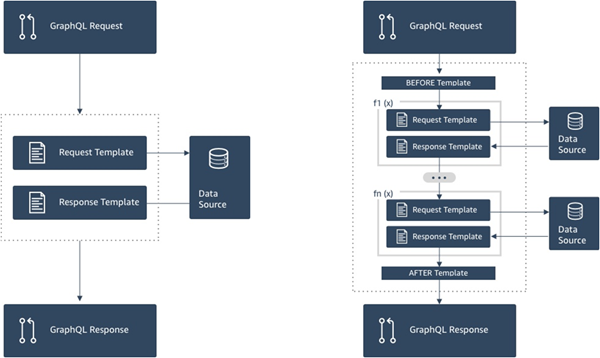
Pipeline resolvers contain a superset of the functionality that unit resolvers support, and more, at the cost of a little more complexity.
Anatomy of a pipeline resolver
A pipeline resolver is composed of a Before mapping template, an After mapping template, and a list of functions. Each function has a request and response mapping template that it executes against a data source. As a pipeline resolver delegates execution to a list of functions, it is therefore not linked to any data source. Unit resolvers and functions are primitives that execute operation against data sources. See the Resolver mapping template overview for more information.
Before mapping template
The request mapping template of a pipeline resolver, or the Before step, allows you to perform some preparation logic before executing the defined functions.
Functions list
The list of functions a pipeline resolver will run in sequence. The pipeline
resolver request mapping template evaluated result is made available to the first
function as $ctx.prev.result. Each function output is available to the
next function as $ctx.prev.result.
After mapping template
The response mapping template of a pipeline resolver, or the After step, allows you to perform some final mapping logic from the
output of the last function to the expected GraphQL field type. The output of the
last function in the functions list is available in the pipeline resolver mapping
template as $ctx.prev.result or $ctx.result.
Execution flow
Given a pipeline resolver comprised of two functions, the list below represents the execution flow when the resolver is invoked:

-
Pipeline resolver Before mapping template
-
Function 1: Function request mapping template
-
Function 1: Data source invocation
-
Function 1: Function response mapping template
-
Function 2: Function request mapping template
-
Function 2: Data source invocation
-
Function 2: Function response mapping template
-
Pipeline resolver After mapping template
Note
Pipeline resolver execution flow is unidirectional and defined statically on the resolver.
Useful Apache Velocity Template Language (VTL) utilities
As the complexity of an application increases, VTL utilities and directives are here to facilitate development productivity. The following utilities can help you when you’re working with pipeline resolvers.
$ctx.stash
The stash is a Map that is made available inside each resolver and
function mapping template. The same stash instance lives through a single resolver
execution. What this means is you can use the stash to pass arbitrary data across
request and response mapping templates, and across functions in a pipeline
resolver. The stash exposes the same methods as the Java
map
$ctx.prev.result
The $ctx.prev.result represents the result of the previous
operation that was executed in the pipeline resolver.
If the previous operation was the pipeline resolver's Before mapping template,
then $ctx.prev.result represents the output of the evaluation of the
template and is made available to the first function in the pipeline. If the
previous operation was the first function, then $ctx.prev.result
represents the output of the first function and is made available to the second
function in the pipeline. If the previous operation was the last function, then
$ctx.prev.result represents the output of the last function and is
made available to the pipeline resolver's After mapping template.
#return(data: Object)
The #return(data: Object) directive comes handy if you need to
return prematurely from any mapping template. #return(data: Object)
is analogous to the return keyword in
programming languages because it returns from the closest scoped block of logic.
What this means is that using #return inside a resolver mapping
template returns from the resolver. Using #return(data: Object) in a
resolver mapping template sets data on the GraphQL field.
Additionally, using #return(data: Object) from a function mapping
template returns from the function and continues the execution to either the next
function in the pipeline or the resolver response mapping template.
#return
This is the same as #return(data: Object), but null
will be returned instead.
$util.error
The $util.error utility is useful to throw a field error. Using
$util.error inside a function mapping template throws a field
error immediately, which prevents subsequent functions from being executed. For
more details and other $util.error signatures, visit the Resolver mapping
template utility reference.
$util.appendError
The $util.appendError is similar to the
$util.error(), with the major distinction that it doesn’t interrupt
the evaluation of the mapping template. Instead, it signals there was an error
with the field, but allows the template to be evaluated and consequently return
data. Using $util.appendError inside a function will not disrupt the
execution flow of the pipeline. For more details and other
$util.error signatures, visit the Resolver mapping
template utility reference.
Example template
Suppose you have a DynamoDB data source and a Unit
resolver on a field named getPost(id:ID!) that returns a Post
type with the following GraphQL query:
getPost(id:1){ id title content }
Your resolver template might look like the following:
{ "version" : "2018-05-29", "operation" : "GetItem", "key" : { "id" : $util.dynamodb.toDynamoDBJson($ctx.args.id) } }
This would substitute the id input parameter value of 1 for
${ctx.args.id} and generate the following JSON:
{ "version" : "2018-05-29", "operation" : "GetItem", "key" : { "id" : { "S" : "1" } } }
AWS AppSync uses this template to generate instructions for communicating with DynamoDB and getting data (or performing other operations as appropriate). After the data returns, AWS AppSync runs it through an optional response mapping template, which you can use to perform data shaping or logic. For example, when we get the results back from DynamoDB, they might look like this:
{ "id" : 1, "theTitle" : "AWS AppSync works offline!", "theContent-part1" : "It also has realtime functionality", "theContent-part2" : "using GraphQL" }
You could choose to join two of the fields into a single field with the following response mapping template:
{ "id" : $util.toJson($context.data.id), "title" : $util.toJson($context.data.theTitle), "content" : $util.toJson("${context.data.theContent-part1} ${context.data.theContent-part2}") }
Here’s how the data is shaped after the template is applied to the data:
{ "id" : 1, "title" : "AWS AppSync works offline!", "content" : "It also has realtime functionality using GraphQL" }
This data is given back as the response to a client as follows:
{ "data": { "getPost": { "id" : 1, "title" : "AWS AppSync works offline!", "content" : "It also has realtime functionality using GraphQL" } } }
Note that under most circumstances, response mapping templates are a simple passthrough of data, differing mostly if you are returning an individual item or a list of items. For an individual item the passthrough is:
$util.toJson($context.result)
For lists the passthrough is usually:
$util.toJson($context.result.items)
To see more examples of both unit and pipeline resolvers, see Resolver tutorials.
Evaluated mapping template deserialization rules
Mapping templates evaluate to a string. In AWS AppSync, the output string must follow a JSON structure to be valid.
Additionally, the following deserialization rules are enforced.
Duplicate keys are not allowed in JSON objects
If the evaluated mapping template string represents a JSON object or contains an object that has duplicate keys, the mapping template returns the following error message:
Duplicate field 'aField' detected on Object. Duplicate JSON keys are not
allowed.
Example of a duplicate key in an evaluated request mapping template:
{ "version": "2018-05-29", "operation": "Invoke", "payload": { "field": "getPost", "postId": "1", "field": "getPost" ## key 'field' has been redefined } }
To fix this error, do not redefine keys in JSON objects.
Trailing characters are not allowed in JSON objects
If the evaluated mapping template string represents a JSON object and contains trailing extraneous characters, the mapping template returns the following error message:
Trailing characters at the end of the JSON string are not allowed.
Example of trailing characters in an evaluated request mapping template:
{ "version": "2018-05-29", "operation": "Invoke", "payload": { "field": "getPost", "postId": "1", } }extraneouschars
To fix this error, ensure that evaluated templates strictly evaluate to JSON.
