Use an external Hive metastore
You can use the Amazon Athena data connector for external Hive metastore to query data sets in Amazon S3 that use an Apache Hive metastore. No migration of metadata to the AWS Glue Data Catalog is necessary. In the Athena management console, you configure a Lambda function to communicate with the Hive metastore that is in your private VPC and then connect it to the metastore. The connection from Lambda to your Hive metastore is secured by a private Amazon VPC channel and does not use the public internet. You can provide your own Lambda function code, or you can use the default implementation of the Athena data connector for external Hive metastore.
Topics
Overview of features
With the Athena data connector for external Hive metastore, you can perform the following tasks:
-
Use the Athena console to register custom catalogs and run queries using them.
-
Define Lambda functions for different external Hive metastores and join them in Athena queries.
-
Use the AWS Glue Data Catalog and your external Hive metastores in the same Athena query.
-
Specify a catalog in the query execution context as the current default catalog. This removes the requirement to prefix catalog names to database names in your queries. Instead of using the syntax
catalog.database.tabledatabase.table -
Use a variety of tools to run queries that reference external Hive metastores. You can use the Athena console, the AWS CLI, the AWS SDK, Athena APIs, and updated Athena JDBC and ODBC drivers. The updated drivers have support for custom catalogs.
API support
Athena Data Connector for External Hive Metastore includes support for catalog registration API operations and metadata API operations.
-
Catalog registration – Register custom catalogs for external Hive metastores and federated data sources.
-
Metadata – Use metadata APIs to provide database and table information for AWS Glue and any catalog that you register with Athena.
-
Athena JAVA SDK client – Use catalog registration APIs, metadata APIs, and support for catalogs in the
StartQueryExecutionoperation in the updated Athena Java SDK client.
Reference implementation
Athena provides a reference implementation for the Lambda function that connects to
external Hive metastores. The reference implementation is provided on GitHub as an
open source project at Athena Hive
metastore
The reference implementation is available as the following two AWS SAM applications in the AWS Serverless Application Repository (SAR). You can use either of these applications in the SAR to create your own Lambda functions.
-
AthenaHiveMetastoreFunction– Uber Lambda function.jarfile. An "uber" JAR (also known as a fat JAR or JAR with dependencies) is a.jarfile that contains both a Java program and its dependencies in a single file. -
AthenaHiveMetastoreFunctionWithLayer– Lambda layer and thin Lambda function.jarfile.
Workflow
The following diagram shows how Athena interacts with your external Hive metastore.
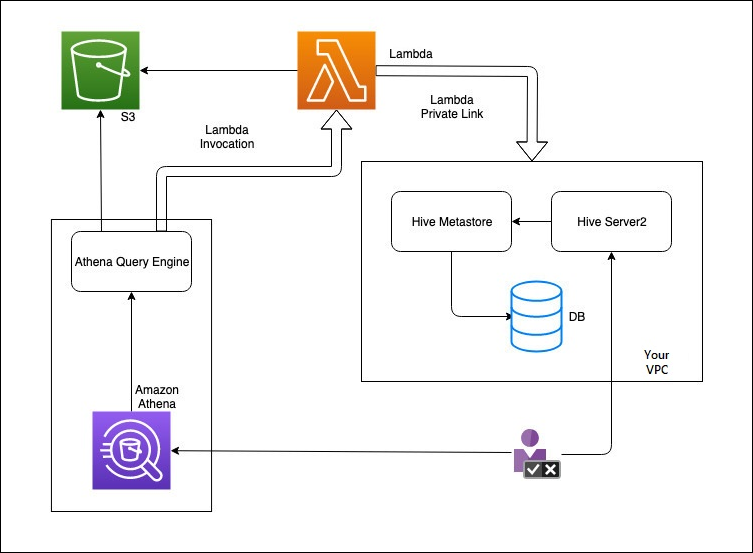
In this workflow, your database-connected Hive metastore is inside your VPC. You use Hive Server2 to manage your Hive metastore using the Hive CLI.
The workflow for using external Hive metastores from Athena includes the following steps.
-
You create a Lambda function that connects Athena to the Hive metastore that is inside your VPC.
-
You register a unique catalog name for your Hive metastore and a corresponding function name in your account.
-
When you run an Athena DML or DDL query that uses the catalog name, the Athena query engine calls the Lambda function name that you associated with the catalog name.
-
Using AWS PrivateLink, the Lambda function communicates with the external Hive metastore in your VPC and receives responses to metadata requests. Athena uses the metadata from your external Hive metastore just like it uses the metadata from the default AWS Glue Data Catalog.
Considerations and limitations
When you use Athena Data Connector for External Hive Metastore, consider the following points:
-
You can use CTAS to create a table on an external Hive metastore.
-
You can use INSERT INTO to insert data into an external Hive metastore.
-
DDL support for external Hive metastore is limited to the following statements.
-
ALTER DATABASE SET DBPROPERTIES
-
ALTER TABLE ADD COLUMNS
-
ALTER TABLE ADD PARTITION
-
ALTER TABLE DROP PARTITION
-
ALTER TABLE RENAME PARTITION
-
ALTER TABLE REPLACE COLUMNS
-
ALTER TABLE SET LOCATION
-
ALTER TABLE SET TBLPROPERTIES
-
CREATE DATABASE
-
CREATE TABLE
-
CREATE TABLE AS
-
DESCRIBE TABLE
-
DROP DATABASE
-
DROP TABLE
-
SHOW COLUMNS
-
SHOW CREATE TABLE
-
SHOW PARTITIONS
-
SHOW SCHEMAS
-
SHOW TABLES
-
SHOW TBLPROPERTIES
-
-
The maximum number of registered catalogs that you can have is 1,000.
-
Kerberos authentication for Hive metastore is not supported.
-
To use the JDBC driver with an external Hive metastore or federated queries, include
MetadataRetrievalMethod=ProxyAPIin your JDBC connection string. For information about the JDBC driver, see Connect to Amazon Athena with JDBC. -
The Hive hidden columns
$path,$bucket,$file_size,$file_modified_time,$partition,$row_idcannot be used for fine-grained access control filtering. -
Hive hidden system tables like
example_table$partitionsexample_table$properties
Permissions
Prebuilt and custom data connectors might require access to the following resources to function correctly. Check the information for the connector that you use to make sure that you have configured your VPC correctly. For information about required IAM permissions to run queries and create a data source connector in Athena, see Allow access to the Athena Data Connector for External Hive Metastore and Allow Lambda function access to external Hive metastores.
-
Amazon S3 – In addition to writing query results to the Athena query results location in Amazon S3, data connectors also write to a spill bucket in Amazon S3. Connectivity and permissions to this Amazon S3 location are required. For more information, see Spill location in Amazon S3 later in this topic.
-
Athena – Access is required to check query status and prevent overscan.
-
AWS Glue – Access is required if your connector uses AWS Glue for supplemental or primary metadata.
-
AWS Key Management Service
-
Policies – Hive metastore, Athena Query Federation, and UDFs require policies in addition to the AWS managed policy: AmazonAthenaFullAccess. For more information, see Identity and access management in Athena.
Spill location in Amazon S3
Because of the limit on Lambda function response sizes, responses larger than the threshold spill into an Amazon S3 location that you specify when you create your Lambda function. Athena reads these responses from Amazon S3 directly.
Note
Athena does not remove the response files on Amazon S3. We recommend that you set up a retention policy to delete response files automatically.
