Amazon Athena HBase connector
The Amazon Athena HBase connector enables Amazon Athena to communicate with your Apache HBase instances so that you can query your HBase data with SQL.
Unlike traditional relational data stores, HBase collections do not have set schema. HBase does not have a metadata store. Each entry in a HBase collection can have different fields and data types.
The HBase connector supports two mechanisms for generating table schema information: basic schema inference and AWS Glue Data Catalog metadata.
Schema inference is the default. This option scans a small number of documents in your collection, forms a union of all fields, and coerces fields that have non overlapping data types. This option works well for collections that have mostly uniform entries.
For collections with a greater variety of data types, the connector supports retrieving metadata from the AWS Glue Data Catalog. If the connector sees an AWS Glue database and table that match your HBase namespace and collection names, it gets its schema information from the corresponding AWS Glue table. When you create your AWS Glue table, we recommend that you make it a superset of all fields that you might want to access from your HBase collection.
If you have Lake Formation enabled in your account, the IAM role for your Athena federated Lambda connector that you deployed in the AWS Serverless Application Repository must have read access in Lake Formation to the AWS Glue Data Catalog.
This connector can be registered with Glue Data Catalog as a federated catalog. It supports data access controls defined in Lake Formation at the catalog, database, table, column, row, and tag levels. This connector uses Glue Connections to centralize configuration properties in Glue.
Prerequisites
Deploy the connector to your AWS account using the Athena console or the AWS Serverless Application Repository. For more information, see Create a data source connection or Use the AWS Serverless Application Repository to deploy a data source connector.
Parameters
Use the parameters in this section to configure the HBase connector.
Note
Athena data source connectors created on December 3, 2024 and later use AWS Glue connections.
The parameter names and definitions listed below are for Athena data source connectors created prior to December 3, 2024. These can differ from their corresponding AWS Glue connection properties. Starting December 3, 2024, use the parameters below only when you manually deploy an earlier version of an Athena data source connector.
We recommend that you configure a HBase connector by using a Glue
connections object. To do this, set the glue_connection
environment variable of the HBase connector Lambda to the name of the Glue
connection to use.
Glue connections properties
Use the following command to get the schema for a Glue connection object. This schema contains all the parameters that you can use to control your connection.
aws glue describe-connection-type --connection-type HBASE
Lambda environment properties
-
glue_connection – Specifies the name of the Glue connection associated with the federated connector.
Note
-
All connectors that use Glue connections must use AWS Secrets Manager to store credentials.
-
The HBase connector created using Glue connections does not support the use of a multiplexing handler.
-
The HBase connector created using Glue connections only supports
ConnectionSchemaVersion2.
-
spill_bucket – Specifies the Amazon S3 bucket for data that exceeds Lambda function limits.
-
spill_prefix – (Optional) Defaults to a subfolder in the specified
spill_bucketcalledathena-federation-spill. We recommend that you configure an Amazon S3 storage lifecycle on this location to delete spills older than a predetermined number of days or hours. -
spill_put_request_headers – (Optional) A JSON encoded map of request headers and values for the Amazon S3
putObjectrequest that is used for spilling (for example,{"x-amz-server-side-encryption" : "AES256"}). For other possible headers, see PutObject in the Amazon Simple Storage Service API Reference. -
kms_key_id – (Optional) By default, any data that is spilled to Amazon S3 is encrypted using the AES-GCM authenticated encryption mode and a randomly generated key. To have your Lambda function use stronger encryption keys generated by KMS like
a7e63k4b-8loc-40db-a2a1-4d0en2cd8331, you can specify a KMS key ID. -
disable_spill_encryption – (Optional) When set to
True, disables spill encryption. Defaults toFalseso that data that is spilled to S3 is encrypted using AES-GCM – either using a randomly generated key or KMS to generate keys. Disabling spill encryption can improve performance, especially if your spill location uses server-side encryption. -
disable_glue – (Optional) If present and set to true, the connector does not attempt to retrieve supplemental metadata from AWS Glue.
-
glue_catalog – (Optional) Use this option to specify a cross-account AWS Glue catalog. By default, the connector attempts to get metadata from its own AWS Glue account.
-
default_hbase – If present, specifies an HBase connection string to use when no catalog-specific environment variable exists.
-
enable_case_insensitive_match – (Optional) When
true, performs case insensitive searches against table names in HBase. The default isfalse. Use if your query contains uppercase table names.
Specifying connection strings
You can provide one or more properties that define the HBase connection details for the HBase instances that you use with the connector. To do this, set a Lambda environment variable that corresponds to the catalog name that you want to use in Athena. For example, suppose you want to use the following queries to query two different HBase instances from Athena:
SELECT * FROM "hbase_instance_1".database.table
SELECT * FROM "hbase_instance_2".database.table
Before you can use these two SQL statements, you must add two environment
variables to your Lambda function: hbase_instance_1 and
hbase_instance_2. The value for each should be a
HBase connection string in the following format:
master_hostname:hbase_port:zookeeper_port
Using secrets
You can optionally use AWS Secrets Manager for part or all of the value for your connection string details. To use the Athena Federated Query feature with Secrets Manager, the VPC
connected to your Lambda function should have internet access
If you use the syntax ${my_secret} to put the name
of a secret from Secrets Manager in your connection string, the connector replaces the
secret name with your user name and password values from Secrets Manager.
For example, suppose you set the Lambda environment variable for
hbase_instance_1 to the following value:
${hbase_host_1}:${hbase_master_port_1}:${hbase_zookeeper_port_1}
The Athena Query Federation SDK automatically attempts to retrieve a secret named hbase_instance_1_creds from Secrets Manager and inject that
value in place of ${hbase_instance_1_creds}.
Any part of the connection string that is enclosed by the ${
} character combination is interpreted as a secret from Secrets Manager. If
you specify a secret name that the connector cannot find in Secrets Manager, the connector
does not replace the text.
Setting up databases and tables in AWS Glue
The connector's built-in schema inference supports only values that are serialized in
HBase as strings (for example, String.valueOf(int)). Because the
connector's built-in schema inference capability is limited, you might want to use AWS Glue
for metadata instead. To enable an AWS Glue table for use with HBase, you must have an
AWS Glue database and table with names that match the HBase namespace and table that you
want to supply supplemental metadata for. The use of HBase column family naming
conventions is optional but not required.
To use an AWS Glue table for supplemental metadata
-
When you edit the table and database in the AWS Glue console, add the following table properties:
hbase-metadata-flag – This property indicates to the HBase connector that the connector can use the table for supplemental metadata. You can provide any value for
hbase-metadata-flagas long as thehbase-metadata-flagproperty is present in the list of table properties.-
hbase-native-storage-flag – Use this flag to toggle the two value serialization modes supported by the connector. By default, when this field is not present, the connector assumes all values are stored in HBase as strings. As such it will attempt to parse data types such as
INT,BIGINT, andDOUBLEfrom HBase as strings. If this field is set with any value on the table in AWS Glue, the connector switches to "native" storage mode and attempts to readINT,BIGINT,BIT, andDOUBLEas bytes by using the following functions:ByteBuffer.wrap(value).getInt() ByteBuffer.wrap(value).getLong() ByteBuffer.wrap(value).get() ByteBuffer.wrap(value).getDouble()
-
Make sure that you use the data types appropriate for AWS Glue as listed in this document.
Modeling column families
The Athena HBase connector supports two ways to model HBase column families: fully
qualified (flattened) naming like family:column, or using
STRUCT objects.
In the STRUCT model, the name of the STRUCT field should
match the column family, and children of the STRUCT should match the
names of the columns of the family. However, because predicate push down and
columnar reads are not yet fully supported for complex types like
STRUCT, using STRUCT is currently not advised.
The following image shows a table configured in AWS Glue that uses a combination of the two approaches.
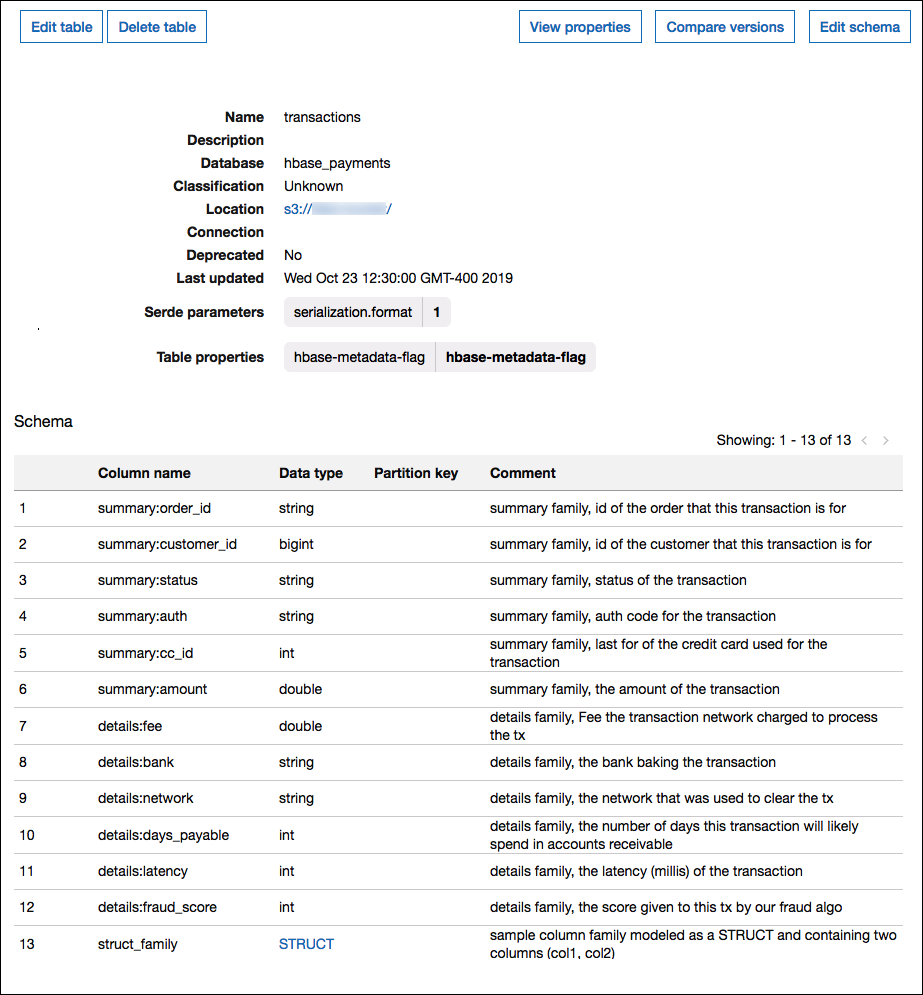
Data type support
The connector retrieves all HBase values as the basic byte type. Then, based on how you defined your tables in AWS Glue Data Catalog, it maps the values into one of the Apache Arrow data types in the following table.
| AWS Glue data type | Apache Arrow data type |
|---|---|
| int | INT |
| bigint | BIGINT |
| double | FLOAT8 |
| float | FLOAT4 |
| boolean | BIT |
| binary | VARBINARY |
| string | VARCHAR |
Note
If you do not use AWS Glue to supplement your metadata, the connector's schema
inferencing uses only the data types BIGINT, FLOAT8, and
VARCHAR.
Required Permissions
For full details on the IAM policies that this
connector requires, review the Policies section of the athena-hbase.yaml
-
Amazon S3 write access – The connector requires write access to a location in Amazon S3 in order to spill results from large queries.
-
Athena GetQueryExecution – The connector uses this permission to fast-fail when the upstream Athena query has terminated.
-
AWS Glue Data Catalog – The HBase connector requires read only access to the AWS Glue Data Catalog to obtain schema information.
-
CloudWatch Logs – The connector requires access to CloudWatch Logs for storing logs.
-
AWS Secrets Manager read access – If you choose to store HBase endpoint details in Secrets Manager, you must grant the connector access to those secrets.
-
VPC access – The connector requires the ability to attach and detach interfaces to your VPC so that it can connect to it and communicate with your HBase instances.
Performance
The Athena HBase connector attempts to parallelize queries against your HBase instance by reading each region server in parallel. The Athena HBase connector performs predicate pushdown to decrease the data scanned by the query.
The Lambda function also performs projection pushdown to decrease
the data scanned by the query. However, selecting a subset of columns sometimes results in a longer query execution runtime. LIMIT clauses reduce the amount of data scanned, but if you don't provide a predicate, you should expect SELECT queries with a LIMIT clause to scan at least 16 MB of data.
HBase is prone to query failures and variable query execution times. You might have to retry your queries multiple times for them to succeed. The HBase connector is resilient to throttling due to concurrency.
Passthrough queries
The HBase connector supports passthrough queries and is NoSQL
based. For information about querying Apache HBase using filtering, see Filter
language
To use passthrough queries with HBase, use the following syntax:
SELECT * FROM TABLE( system.query( database => 'database_name', collection => 'collection_name', filter => '{query_syntax}' ))
The following example HBase passthrough query filters for employees aged 24 or 30
within the employee collection of the default database.
SELECT * FROM TABLE( system.query( DATABASE => 'default', COLLECTION => 'employee', FILTER => 'SingleColumnValueFilter(''personaldata'', ''age'', =, ''binary:30'')' || ' OR SingleColumnValueFilter(''personaldata'', ''age'', =, ''binary:24'')' ))
License information
The Amazon Athena HBase connector project is licensed under the Apache-2.0 License
Additional resources
For additional information about this connector, visit the corresponding site
