Invoke an AWS Lambda function in a pipeline in CodePipeline
AWS Lambda is a compute service that lets you run code without provisioning or managing servers. You can create Lambda functions and add them as actions in your pipelines. Because Lambda allows you to write functions to perform almost any task, you can customize the way your pipeline works.
Important
Do not log the JSON event that CodePipeline sends to Lambda because this can result in user
credentials being logged in CloudWatch Logs. The CodePipeline role uses a JSON event to pass temporary
credentials to Lambda in the artifactCredentials field. For an example
event, see Example JSON event.
Here are some ways Lambda functions can be used in pipelines:
-
To create resources on demand in one stage of a pipeline using CloudFormation and delete them in another stage.
-
To deploy application versions with zero downtime in AWS Elastic Beanstalk with a Lambda function that swaps CNAME values.
-
To deploy to Amazon ECS Docker instances.
-
To back up resources before building or deploying by creating an AMI snapshot.
-
To add integration with third-party products to your pipeline, such as posting messages to an IRC client.
Note
Creating and running Lambda functions might result in charges to your AWS account. For more information, see Pricing
This topic assumes you are familiar with AWS CodePipeline and AWS Lambda and know how to create pipelines, functions, and the IAM policies and roles on which they depend. This topic shows you how to:
-
Create a Lambda function that tests whether a webpage was deployed successfully.
-
Configure the CodePipeline and Lambda execution roles and the permissions required to run the function as part of the pipeline.
-
Edit a pipeline to add the Lambda function as an action.
-
Test the action by manually releasing a change.
Note
When using cross-Region Lambda invoke action in CodePipeline, the status of the lambda execution using the PutJobSuccessResult and PutJobFailureResult should be sent to the AWS Region where the Lambda function is present and not to the Region where CodePipeline exists.
This topic includes sample functions to demonstrate the flexibility of working with Lambda functions in CodePipeline:
-
-
Creating a basic Lambda function to use with CodePipeline.
-
Returning success or failure results to CodePipeline in the Details link for the action.
-
-
Sample Python function that uses an AWS CloudFormation template
-
Using JSON-encoded user parameters to pass multiple configuration values to the function (
get_user_params). -
Interacting with .zip artifacts in an artifact bucket (
get_template). -
Using a continuation token to monitor a long-running asynchronous process (
continue_job_later). This allows the action to continue and the function to succeed even if it exceeds a fifteen-minute runtime (a limit in Lambda).
-
Each sample function includes information about the permissions you must add to the role. For information about limits in AWS Lambda, see Limits in the AWS Lambda Developer Guide.
Important
The sample code, roles, and policies included in this topic are examples only, and are provided as-is.
Topics
Step 1: Create a pipeline
In this step, you create a pipeline to which you later add the Lambda function. This is the same pipeline you created in CodePipeline tutorials. If that pipeline is still configured for your account and is in the same Region where you plan to create the Lambda function, you can skip this step.
To create the pipeline
-
Follow the first three steps in Tutorial: Create a simple pipeline (S3 bucket) to create an Amazon S3 bucket, CodeDeploy resources, and a two-stage pipeline. Choose the Amazon Linux option for your instance types. You can use any name you want for the pipeline, but the steps in this topic use MyLambdaTestPipeline.
-
On the status page for your pipeline, in the CodeDeploy action, choose Details. On the deployment details page for the deployment group, choose an instance ID from the list.
-
In the Amazon EC2 console, on the Details tab for the instance, copy the IP address in Public IPv4 address (for example,
192.0.2.4). You use this address as the target of the function in AWS Lambda.
Note
The default service role policy for CodePipeline includes the Lambda permissions required
to invoke the function. However, if you have modified the default service role or
selected a different one, make sure the policy for the role allows the
lambda:InvokeFunction and lambda:ListFunctions
permissions. Otherwise, pipelines that include Lambda actions fail.
Step 2: Create the Lambda function
In this step, you create a Lambda function that makes an HTTP request and checks for a line of text on a webpage. As part of this step, you must also create an IAM policy and Lambda execution role. For more information, see Permissions Model in the AWS Lambda Developer Guide.
To create the execution role
Sign in to the AWS Management Console and open the IAM console at https://console.aws.amazon.com/iam/
. -
Choose Policies, and then choose Create Policy. Choose the JSON tab, and then paste the following policy into the field.
-
Choose Review policy.
-
On the Review policy page, in Name, type a name for the policy (for example,
CodePipelineLambdaExecPolicy). In Description, enterEnables Lambda to execute code.Choose Create Policy.
Note
These are the minimum permissions required for a Lambda function to interoperate with CodePipeline and Amazon CloudWatch. If you want to expand this policy to allow functions that interact with other AWS resources, you should modify this policy to allow the actions required by those Lambda functions.
-
On the policy dashboard page, choose Roles, and then choose Create role.
-
On the Create role page, choose AWS service. Choose Lambda, and then choose Next: Permissions.
-
On the Attach permissions policies page, select the check box next to CodePipelineLambdaExecPolicy, and then choose Next: Tags. Choose Next: Review.
-
On the Review page, in Role name, enter the name, and then choose Create role.
To create the sample Lambda function to use with CodePipeline
Sign in to the AWS Management Console and open the AWS Lambda console at https://console.aws.amazon.com/lambda/
. -
On the Functions page, choose Create function.
Note
If you see a Welcome page instead of the Lambda page, choose Get Started Now.
-
On the Create function page, choose Author from scratch. In Function name, enter a name for your Lambda function (for example,
MyLambdaFunctionForAWSCodePipeline). In Runtime, choose Node.js 20.x. -
Under Role, select Choose an existing role. In Existing role, choose your role, and then choose Create function.
The detail page for your created function opens.
-
Copy the following code into the Function code box:
Note
The event object, under the CodePipeline.job key, contains the job details. For a full example of the JSON event CodePipeline returns to Lambda, see Example JSON event.
import { CodePipelineClient, PutJobSuccessResultCommand, PutJobFailureResultCommand } from "@aws-sdk/client-codepipeline"; import http from 'http'; import assert from 'assert'; export const handler = (event, context) => { const codepipeline = new CodePipelineClient(); // Retrieve the Job ID from the Lambda action const jobId = event["CodePipeline.job"].id; // Retrieve the value of UserParameters from the Lambda action configuration in CodePipeline, in this case a URL which will be // health checked by this function. const url = event["CodePipeline.job"].data.actionConfiguration.configuration.UserParameters; // Notify CodePipeline of a successful job const putJobSuccess = async function(message) { const command = new PutJobSuccessResultCommand({ jobId: jobId }); try { await codepipeline.send(command); context.succeed(message); } catch (err) { context.fail(err); } }; // Notify CodePipeline of a failed job const putJobFailure = async function(message) { const command = new PutJobFailureResultCommand({ jobId: jobId, failureDetails: { message: JSON.stringify(message), type: 'JobFailed', externalExecutionId: context.awsRequestId } }); await codepipeline.send(command); context.fail(message); }; // Validate the URL passed in UserParameters if(!url || url.indexOf('http://') === -1) { putJobFailure('The UserParameters field must contain a valid URL address to test, including http:// or https://'); return; } // Helper function to make a HTTP GET request to the page. // The helper will test the response and succeed or fail the job accordingly const getPage = function(url, callback) { var pageObject = { body: '', statusCode: 0, contains: function(search) { return this.body.indexOf(search) > -1; } }; http.get(url, function(response) { pageObject.body = ''; pageObject.statusCode = response.statusCode; response.on('data', function (chunk) { pageObject.body += chunk; }); response.on('end', function () { callback(pageObject); }); response.resume(); }).on('error', function(error) { // Fail the job if our request failed putJobFailure(error); }); }; getPage(url, function(returnedPage) { try { // Check if the HTTP response has a 200 status assert(returnedPage.statusCode === 200); // Check if the page contains the text "Congratulations" // You can change this to check for different text, or add other tests as required assert(returnedPage.contains('Congratulations')); // Succeed the job putJobSuccess("Tests passed."); } catch (ex) { // If any of the assertions failed then fail the job putJobFailure(ex); } }); }; -
Leave Handler at the default value, and leave Role at the default,
CodePipelineLambdaExecRole. -
In Basic settings, for Timeout, enter
20seconds. -
Choose Save.
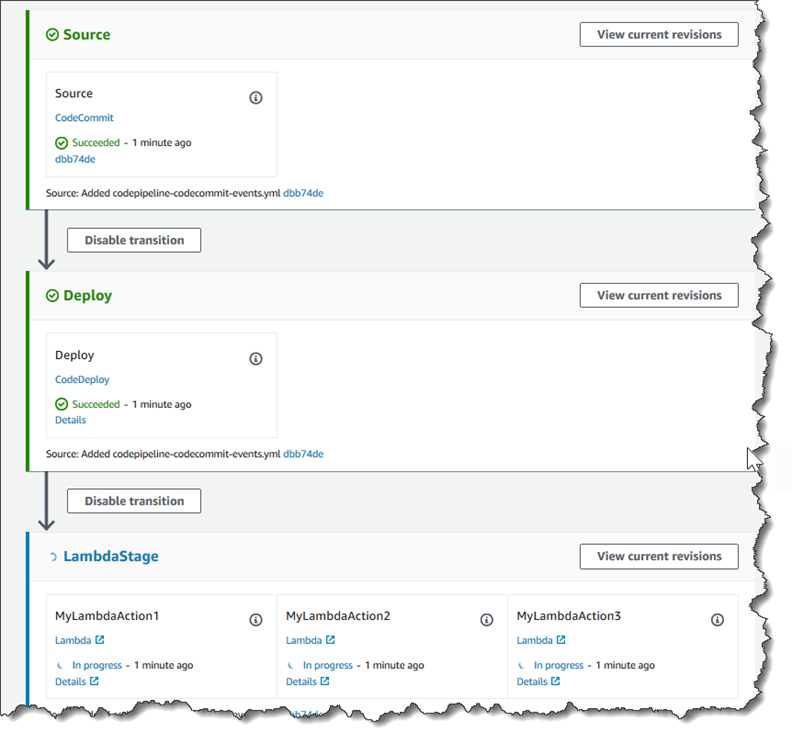
Step 3: Add the Lambda function to a pipeline in the CodePipeline console
In this step, you add a new stage to your pipeline, and then add a Lambda action that calls your function to that stage.
To add a stage
Sign in to the AWS Management Console and open the CodePipeline console at http://console.aws.amazon.com/codesuite/codepipeline/home
. -
On the Welcome page, choose the pipeline you created.
-
On the pipeline view page, choose Edit.
-
On the Edit page, choose + Add stage to add a stage after the deployment stage with the CodeDeploy action. Enter a name for the stage (for example,
LambdaStage), and choose Add stage.Note
You can also choose to add your Lambda action to an existing stage. For demonstration purposes, we are adding the Lambda function as the only action in a stage to allow you to easily view its progress as artifacts progress through a pipeline.
-
Choose + Add action group. In Edit action, in Action name, enter a name for your Lambda action (for example,
MyLambdaAction). In Provider, choose AWS Lambda. In Function name, choose or enter the name of your Lambda function (for example,MyLambdaFunctionForAWSCodePipeline). In User parameters, specify the IP address for the Amazon EC2 instance you copied earlier (for example,http://), and then choose Done.192.0.2.4Note
This topic uses an IP address, but in a real-world scenario, you could provide your registered website name instead (for example,
http://). For more information about event data and handlers in AWS Lambda, see Programming Model in the AWS Lambda Developer Guide.www.example.com -
On the Edit action page, choose Save.
Step 4: Test the pipeline with the Lambda function
To test the function, release the most recent change through the pipeline.
To use the console to run the most recent version of an artifact through a pipeline
-
On the pipeline details page, choose Release change. This runs the most recent revision available in each source location specified in a source action through the pipeline.
-
When the Lambda action is complete, choose the Details link to view the log stream for the function in Amazon CloudWatch, including the billed duration of the event. If the function failed, the CloudWatch log provides information about the cause.
Step 5: Next steps
Now that you've successfully created a Lambda function and added it as an action in a pipeline, you can try the following:
-
Add more Lambda actions to your stage to check other webpages.
-
Modify the Lambda function to check for a different text string.
-
Explore Lambda functions and create and add your own Lambda functions to pipelines.
After you have finished experimenting with the Lambda function, consider removing it from your pipeline, deleting it from AWS Lambda, and deleting the role from IAM to avoid possible charges. For more information, see Edit a pipeline in CodePipeline, Delete a pipeline in CodePipeline, and Deleting Roles or Instance Profiles.
Example JSON event
The following example shows a sample JSON event sent to Lambda by CodePipeline. The structure
of this event is similar to the response to the GetJobDetails API, but
without the actionTypeId and pipelineContext data types. Two
action configuration details, FunctionName and UserParameters,
are included in both the JSON event and the response to the GetJobDetails
API. The values in red italic text are examples or
explanations, not real values.
{ "CodePipeline.job": { "id": "11111111-abcd-1111-abcd-111111abcdef", "accountId": "111111111111", "data": { "actionConfiguration": { "configuration": { "FunctionName": "MyLambdaFunctionForAWSCodePipeline", "UserParameters": "some-input-such-as-a-URL" } }, "inputArtifacts": [ { "location": { "s3Location": { "bucketName": "the name of the bucket configured as the pipeline artifact store in Amazon S3, for example codepipeline-us-east-2-1234567890", "objectKey": "the name of the application, for example CodePipelineDemoApplication.zip" }, "type": "S3" }, "revision": null, "name": "ArtifactName" } ], "outputArtifacts": [], "artifactCredentials": { "secretAccessKey": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY", "sessionToken": "MIICiTCCAfICCQD6m7oRw0uXOjANBgkqhkiG9w 0BAQUFADCBiDELMAkGA1UEBhMCVVMxCzAJBgNVBAgTAldBMRAwDgYDVQQHEwdTZ WF0dGxlMQ8wDQYDVQQKEwZBbWF6b24xFDASBgNVBAsTC0lBTSBDb25zb2xlMRIw EAYDVQQDEwlUZXN0Q2lsYWMxHzAdBgkqhkiG9w0BCQEWEG5vb25lQGFtYXpvbi5 jb20wHhcNMTEwNDI1MjA0NTIxWhcNMTIwNDI0MjA0NTIxWjCBiDELMAkGA1UEBh MCVVMxCzAJBgNVBAgTAldBMRAwDgYDVQQHEwdTZWF0dGxlMQ8wDQYDVQQKEwZBb WF6b24xFDASBgNVBAsTC0lBTSBDb25zb2xlMRIwEAYDVQQDEwlUZXN0Q2lsYWMx HzAdBgkqhkiG9w0BCQEWEG5vb25lQGFtYXpvbi5jb20wgZ8wDQYJKoZIhvcNAQE BBQADgY0AMIGJAoGBAMaK0dn+a4GmWIWJ21uUSfwfEvySWtC2XADZ4nB+BLYgVI k60CpiwsZ3G93vUEIO3IyNoH/f0wYK8m9TrDHudUZg3qX4waLG5M43q7Wgc/MbQ ITxOUSQv7c7ugFFDzQGBzZswY6786m86gpEIbb3OhjZnzcvQAaRHhdlQWIMm2nr AgMBAAEwDQYJKoZIhvcNAQEFBQADgYEAtCu4nUhVVxYUntneD9+h8Mg9q6q+auN KyExzyLwaxlAoo7TJHidbtS4J5iNmZgXL0FkbFFBjvSfpJIlJ00zbhNYS5f6Guo EDmFJl0ZxBHjJnyp378OD8uTs7fLvjx79LjSTbNYiytVbZPQUQ5Yaxu2jXnimvw 3rrszlaEXAMPLE=", "accessKeyId": "AKIAIOSFODNN7EXAMPLE" }, "continuationToken": "A continuation token if continuing job", "encryptionKey": { "id": "arn:aws:kms:us-west-2:111122223333:key/1234abcd-12ab-34cd-56ef-1234567890ab", "type": "KMS" } } } }
Additional sample functions
The following sample Lambda functions demonstrate additional functionality you can use for your pipelines in CodePipeline. To use these functions, you might have to modify the policy for the Lambda execution role, as noted in the introduction for each sample.
Sample Python function that uses an AWS CloudFormation template
The following sample shows a function that creates or updates a stack based on a supplied CloudFormation template. The template creates an Amazon S3 bucket. It is for demonstration purposes only, to minimize costs. Ideally, you should delete the stack before you upload anything to the bucket. If you upload files to the bucket, you cannot delete the bucket when you delete the stack. You must manually delete everything in the bucket before you can delete the bucket itself.
This Python sample assumes you have a pipeline that uses an Amazon S3 bucket as a source action, or that you have access to a versioned Amazon S3 bucket you can use with the pipeline. You create the CloudFormation template, compress it, and upload it to that bucket as a .zip file. You must then add a source action to your pipeline that retrieves this .zip file from the bucket.
Note
When Amazon S3 is the source provider for your pipeline, you may zip your source file or files into a single .zip and upload the .zip to your source bucket. You may also upload a single unzipped file; however, downstream actions that expect a .zip file will fail.
This sample demonstrates:
-
The use of JSON-encoded user parameters to pass multiple configuration values to the function (
get_user_params). -
The interaction with .zip artifacts in an artifact bucket (
get_template). -
The use of a continuation token to monitor a long-running asynchronous process (
continue_job_later). This allows the action to continue and the function to succeed even if it exceeds a fifteen-minute runtime (a limit in Lambda).
To use this sample Lambda function, the policy for the Lambda execution role must
have Allow permissions in CloudFormation, Amazon S3, and CodePipeline, as shown in this
sample policy:
To create the CloudFormation template, open any plain-text editor and copy and paste the following code:
{ "AWSTemplateFormatVersion" : "2010-09-09", "Description" : "CloudFormation template which creates an S3 bucket", "Resources" : { "MySampleBucket" : { "Type" : "AWS::S3::Bucket", "Properties" : { } } }, "Outputs" : { "BucketName" : { "Value" : { "Ref" : "MySampleBucket" }, "Description" : "The name of the S3 bucket" } } }
Save this as a JSON file with the name template.json in a
directory named template-package. Create a compressed (.zip)
file of this directory and file named template-package.zip,
and upload the compressed file to a versioned Amazon S3 bucket. If you already have a
bucket configured for your pipeline, you can use it. Next, edit your pipeline to add
a source action that retrieves the .zip file. Name the output for this action
MyTemplate. For more information, see Edit a pipeline in CodePipeline.
Note
The sample Lambda function expects these file names and compressed structure. However, you can substitute your own CloudFormation template for this sample. If you use your own template, make sure you modify the policy for the Lambda execution role to allow any additional functionality required by your CloudFormation template.
To add the following code as a function in Lambda
-
Open the Lambda console and choose Create function.
-
On the Create function page, choose Author from scratch. In Function name, enter a name for your Lambda function.
-
In Runtime, choose Python 2.7.
-
Under Choose or create an execution role, select Use an existing role. In Existing role, choose your role, and then choose Create function.
The detail page for your created function opens.
-
Copy the following code into the Function code box:
from __future__ import print_function from boto3.session import Session import json import urllib import boto3 import zipfile import tempfile import botocore import traceback print('Loading function') cf = boto3.client('cloudformation') code_pipeline = boto3.client('codepipeline') def find_artifact(artifacts, name): """Finds the artifact 'name' among the 'artifacts' Args: artifacts: The list of artifacts available to the function name: The artifact we wish to use Returns: The artifact dictionary found Raises: Exception: If no matching artifact is found """ for artifact in artifacts: if artifact['name'] == name: return artifact raise Exception('Input artifact named "{0}" not found in event'.format(name)) def get_template(s3, artifact, file_in_zip): """Gets the template artifact Downloads the artifact from the S3 artifact store to a temporary file then extracts the zip and returns the file containing the CloudFormation template. Args: artifact: The artifact to download file_in_zip: The path to the file within the zip containing the template Returns: The CloudFormation template as a string Raises: Exception: Any exception thrown while downloading the artifact or unzipping it """ tmp_file = tempfile.NamedTemporaryFile() bucket = artifact['location']['s3Location']['bucketName'] key = artifact['location']['s3Location']['objectKey'] with tempfile.NamedTemporaryFile() as tmp_file: s3.download_file(bucket, key, tmp_file.name) with zipfile.ZipFile(tmp_file.name, 'r') as zip: return zip.read(file_in_zip) def update_stack(stack, template): """Start a CloudFormation stack update Args: stack: The stack to update template: The template to apply Returns: True if an update was started, false if there were no changes to the template since the last update. Raises: Exception: Any exception besides "No updates are to be performed." """ try: cf.update_stack(StackName=stack, TemplateBody=template) return True except botocore.exceptions.ClientError as e: if e.response['Error']['Message'] == 'No updates are to be performed.': return False else: raise Exception('Error updating CloudFormation stack "{0}"'.format(stack), e) def stack_exists(stack): """Check if a stack exists or not Args: stack: The stack to check Returns: True or False depending on whether the stack exists Raises: Any exceptions raised .describe_stacks() besides that the stack doesn't exist. """ try: cf.describe_stacks(StackName=stack) return True except botocore.exceptions.ClientError as e: if "does not exist" in e.response['Error']['Message']: return False else: raise e def create_stack(stack, template): """Starts a new CloudFormation stack creation Args: stack: The stack to be created template: The template for the stack to be created with Throws: Exception: Any exception thrown by .create_stack() """ cf.create_stack(StackName=stack, TemplateBody=template) def get_stack_status(stack): """Get the status of an existing CloudFormation stack Args: stack: The name of the stack to check Returns: The CloudFormation status string of the stack such as CREATE_COMPLETE Raises: Exception: Any exception thrown by .describe_stacks() """ stack_description = cf.describe_stacks(StackName=stack) return stack_description['Stacks'][0]['StackStatus'] def put_job_success(job, message): """Notify CodePipeline of a successful job Args: job: The CodePipeline job ID message: A message to be logged relating to the job status Raises: Exception: Any exception thrown by .put_job_success_result() """ print('Putting job success') print(message) code_pipeline.put_job_success_result(jobId=job) def put_job_failure(job, message): """Notify CodePipeline of a failed job Args: job: The CodePipeline job ID message: A message to be logged relating to the job status Raises: Exception: Any exception thrown by .put_job_failure_result() """ print('Putting job failure') print(message) code_pipeline.put_job_failure_result(jobId=job, failureDetails={'message': message, 'type': 'JobFailed'}) def continue_job_later(job, message): """Notify CodePipeline of a continuing job This will cause CodePipeline to invoke the function again with the supplied continuation token. Args: job: The JobID message: A message to be logged relating to the job status continuation_token: The continuation token Raises: Exception: Any exception thrown by .put_job_success_result() """ # Use the continuation token to keep track of any job execution state # This data will be available when a new job is scheduled to continue the current execution continuation_token = json.dumps({'previous_job_id': job}) print('Putting job continuation') print(message) code_pipeline.put_job_success_result(jobId=job, continuationToken=continuation_token) def start_update_or_create(job_id, stack, template): """Starts the stack update or create process If the stack exists then update, otherwise create. Args: job_id: The ID of the CodePipeline job stack: The stack to create or update template: The template to create/update the stack with """ if stack_exists(stack): status = get_stack_status(stack) if status not in ['CREATE_COMPLETE', 'ROLLBACK_COMPLETE', 'UPDATE_COMPLETE']: # If the CloudFormation stack is not in a state where # it can be updated again then fail the job right away. put_job_failure(job_id, 'Stack cannot be updated when status is: ' + status) return were_updates = update_stack(stack, template) if were_updates: # If there were updates then continue the job so it can monitor # the progress of the update. continue_job_later(job_id, 'Stack update started') else: # If there were no updates then succeed the job immediately put_job_success(job_id, 'There were no stack updates') else: # If the stack doesn't already exist then create it instead # of updating it. create_stack(stack, template) # Continue the job so the pipeline will wait for the CloudFormation # stack to be created. continue_job_later(job_id, 'Stack create started') def check_stack_update_status(job_id, stack): """Monitor an already-running CloudFormation update/create Succeeds, fails or continues the job depending on the stack status. Args: job_id: The CodePipeline job ID stack: The stack to monitor """ status = get_stack_status(stack) if status in ['UPDATE_COMPLETE', 'CREATE_COMPLETE']: # If the update/create finished successfully then # succeed the job and don't continue. put_job_success(job_id, 'Stack update complete') elif status in ['UPDATE_IN_PROGRESS', 'UPDATE_ROLLBACK_IN_PROGRESS', 'UPDATE_ROLLBACK_COMPLETE_CLEANUP_IN_PROGRESS', 'CREATE_IN_PROGRESS', 'ROLLBACK_IN_PROGRESS', 'UPDATE_COMPLETE_CLEANUP_IN_PROGRESS']: # If the job isn't finished yet then continue it continue_job_later(job_id, 'Stack update still in progress') else: # If the Stack is a state which isn't "in progress" or "complete" # then the stack update/create has failed so end the job with # a failed result. put_job_failure(job_id, 'Update failed: ' + status) def get_user_params(job_data): """Decodes the JSON user parameters and validates the required properties. Args: job_data: The job data structure containing the UserParameters string which should be a valid JSON structure Returns: The JSON parameters decoded as a dictionary. Raises: Exception: The JSON can't be decoded or a property is missing. """ try: # Get the user parameters which contain the stack, artifact and file settings user_parameters = job_data['actionConfiguration']['configuration']['UserParameters'] decoded_parameters = json.loads(user_parameters) except Exception as e: # We're expecting the user parameters to be encoded as JSON # so we can pass multiple values. If the JSON can't be decoded # then fail the job with a helpful message. raise Exception('UserParameters could not be decoded as JSON') if 'stack' not in decoded_parameters: # Validate that the stack is provided, otherwise fail the job # with a helpful message. raise Exception('Your UserParameters JSON must include the stack name') if 'artifact' not in decoded_parameters: # Validate that the artifact name is provided, otherwise fail the job # with a helpful message. raise Exception('Your UserParameters JSON must include the artifact name') if 'file' not in decoded_parameters: # Validate that the template file is provided, otherwise fail the job # with a helpful message. raise Exception('Your UserParameters JSON must include the template file name') return decoded_parameters def setup_s3_client(job_data): """Creates an S3 client Uses the credentials passed in the event by CodePipeline. These credentials can be used to access the artifact bucket. Args: job_data: The job data structure Returns: An S3 client with the appropriate credentials """ key_id = job_data['artifactCredentials']['accessKeyId'] key_secret = job_data['artifactCredentials']['secretAccessKey'] session_token = job_data['artifactCredentials']['sessionToken'] session = Session(aws_access_key_id=key_id, aws_secret_access_key=key_secret, aws_session_token=session_token) return session.client('s3', config=botocore.client.Config(signature_version='s3v4')) def lambda_handler(event, context): """The Lambda function handler If a continuing job then checks the CloudFormation stack status and updates the job accordingly. If a new job then kick of an update or creation of the target CloudFormation stack. Args: event: The event passed by Lambda context: The context passed by Lambda """ try: # Extract the Job ID job_id = event['CodePipeline.job']['id'] # Extract the Job Data job_data = event['CodePipeline.job']['data'] # Extract the params params = get_user_params(job_data) # Get the list of artifacts passed to the function artifacts = job_data['inputArtifacts'] stack = params['stack'] artifact = params['artifact'] template_file = params['file'] if 'continuationToken' in job_data: # If we're continuing then the create/update has already been triggered # we just need to check if it has finished. check_stack_update_status(job_id, stack) else: # Get the artifact details artifact_data = find_artifact(artifacts, artifact) # Get S3 client to access artifact with s3 = setup_s3_client(job_data) # Get the JSON template file out of the artifact template = get_template(s3, artifact_data, template_file) # Kick off a stack update or create start_update_or_create(job_id, stack, template) except Exception as e: # If any other exceptions which we didn't expect are raised # then fail the job and log the exception message. print('Function failed due to exception.') print(e) traceback.print_exc() put_job_failure(job_id, 'Function exception: ' + str(e)) print('Function complete.') return "Complete." -
Leave Handler at the default value, and leave Role at the name you selected or created earlier,
CodePipelineLambdaExecRole. -
In Basic settings, for Timeout, replace the default of 3 seconds with
20. -
Choose Save.
-
From the CodePipeline console, edit the pipeline to add the function as an action in a stage in your pipeline. Choose Edit for the pipeline stage you want to change, and choose Add action group. On the Edit action page, in Action name, enter a name for your action. In Action provider, choose Lambda.
Under Input artifacts, choose
MyTemplate. In UserParameters, you must provide a JSON string with three parameters:-
Stack name
-
CloudFormation template name and path to the file
-
Input artifact
Use curly brackets ({ }) and separate the parameters with commas. For example, to create a stack named
MyTestStack, for a pipeline with the input artifactMyTemplate, in UserParameters, enter: {"stack":"MyTestStack","file":"template-package/template.json","artifact":"MyTemplate"}.Note
Even though you have specified the input artifact in UserParameters, you must also specify this input artifact for the action in Input artifacts.
-
-
Save your changes to the pipeline, and then manually release a change to test the action and Lambda function.
