Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwendung von CloudWatch Amazon-Metriken zur Analyse der Ressourcennutzung für Aurora PostgreSQL
Aurora sendet automatisch Metrikdaten innerhalb von 1 Minute an CloudWatch . Sie können die Ressourcennutzung für Aurora PostgreSQL mithilfe CloudWatch von Metriken analysieren. Mit den Metriken können Sie den Netzwerkdurchsatz und die Netzwerknutzung bewerten.
Bewertung des Netzwerkdurchsatzes mit CloudWatch
Wenn sich Ihre Systemauslastung den Ressourcenlimits für Ihren Instance-Typ nähert, kann sich die Verarbeitung verlangsamen. Sie können CloudWatch Logs Insights verwenden, um die Nutzung Ihrer Speicherressourcen zu überwachen und sicherzustellen, dass ausreichend Ressourcen verfügbar sind. Bei Bedarf können Sie die DB-Instance auf eine größere Instance-Klasse umstellen.
Die Verarbeitung des Aurora-Speichers kann aus folgenden Gründen langsam sein:
-
Unzureichende Netzwerkbandbreite zwischen Client und DB-Instance.
-
Unzureichende Netzwerkbandbreite für das Speichersubsystem.
-
Eine Workload, die im Hinblick auf Ihren Instance-Typ groß ist.
Sie können CloudWatch Logs Insights abfragen, um ein Diagramm der Aurora-Speicherressourcennutzung zur Überwachung der Ressourcen zu erstellen. Das Diagramm zeigt die CPU-Auslastung und Metriken, anhand derer Sie entscheiden können, ob Sie auf eine größere Instance-Größe hochskalieren sollten. Informationen zur Abfragesyntax für CloudWatch Logs Insights finden Sie unter CloudWatch Logs Insights-Abfragesyntax
Um es zu verwenden CloudWatch, müssen Sie Ihre Aurora PostgreSQL-Protokolldateien nach exportieren. CloudWatch Sie können Ihren vorhandenen Cluster auch ändern, um Logs in diesen zu exportieren. CloudWatch Informationen zum Exportieren von Protokollen nach CloudWatch finden Sie unterAktivierung der Option zum Veröffentlichen von Protokollen auf Amazon CloudWatch.
Sie benötigen die Ressourcen-ID Ihrer DB-Instance, um CloudWatch Logs Insights abzufragen. Die Resource ID (Ressourcen-ID) ist auf der Registerkarte Configuration (Konfiguration) in Ihrer Konsole verfügbar:
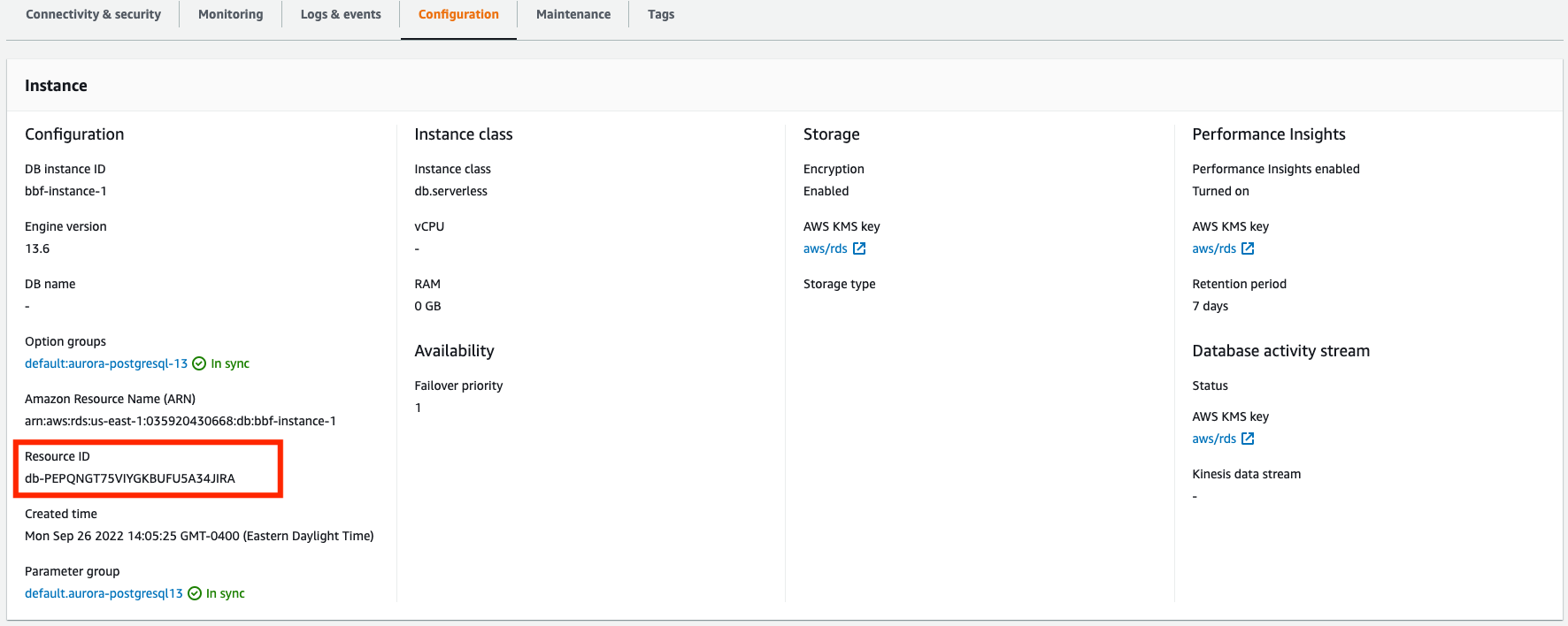
So fragen Sie Ihre Protokolldateien nach Metriken für den Ressourcenspeicher ab:
Öffnen Sie die CloudWatch Konsole unter https://console.aws.amazon.com/cloudwatch/
. Die CloudWatch Übersichts-Startseite wird angezeigt.
-
Ändern Sie, falls erforderlich, die AWS-Region. Wählen Sie in der Navigationsleiste aus, AWS-Region wo sich Ihre AWS Ressourcen befinden. Weitere Informationen finden Sie unter Regionen und Endpunkte.
-
Wählen Sie im Navigationsbereich Logs (Protokolle) und dann Logs Insights aus.
Die Seite Logs Insights wird angezeigt.
-
Wählen Sie die Protokolldateien, die Sie analysieren möchten, aus der Dropdown-Liste aus.
-
Geben Sie die folgende Abfrage in das Feld ein und ersetzen Sie
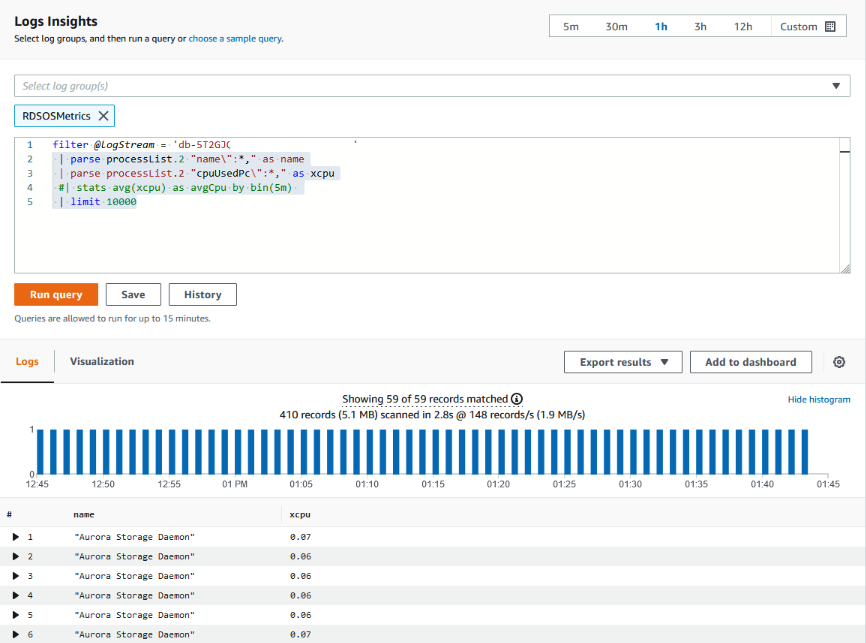
<resource ID>durch die Ressourcen-ID Ihres DB-Clusters:filter @logStream = <resource ID> | parse @message "\"Aurora Storage Daemon\"*memoryUsedPc\":*,\"cpuUsedPc\":*," as a,memoryUsedPc,cpuUsedPc | display memoryUsedPc,cpuUsedPc #| stats avg(xcpu) as avgCpu by bin(5m) | limit 10000 -
Klicken Sie auf Run query (Abfrage ausführen).
Das Diagramm zur Speicherauslastung wird angezeigt.
Die folgende Abbildung veranschaulicht die Seite Logs Insights und die Diagrammanzeige.
Bewertung der DB-Instance-Nutzung für Aurora PostgreSQL anhand von Metriken CloudWatch
Mithilfe von CloudWatch Metriken können Sie den Durchsatz Ihrer Instance beobachten und herausfinden, ob Ihre Instance-Klasse ausreichend Ressourcen für Ihre Anwendungen bereitstellt. Informationen zu Ihren DB-Instance-Klassenlimits finden Sie unter Hardware-Spezifikationen für DB-Instance-Klassen für Aurora. Suchen Sie die Spezifikationen für Ihre DB-Instance-Klasse, um Ihre Netzwerkleistung zu ermitteln.
Wenn sich Ihre DB-Instance-Nutzung dem Instance-Klassenlimit nähert, kann sich die Leistung verschlechtern. Die CloudWatch Metriken können diese Situation bestätigen, sodass Sie planen können, manuell auf eine größere Instance-Klasse hochzuskalieren.
Kombinieren Sie die folgenden CloudWatch Metrikwerte, um herauszufinden, ob Sie sich dem Instance-Klassenlimit nähern:
-
NetworkThroughput— Die Menge des Netzwerkdurchsatzes, der von den Clients für jede Instance im Aurora-DB-Cluster empfangen und übertragen wird. Dieser Durchsatzwert berücksichtigt nicht den Netzwerkdatenverkehr zwischen den Instances im DB-Cluster und dem Cluster-Volume.
-
StorageNetworkThroughput— Die Menge des Netzwerkdurchsatzes, der von jeder Instance im Aurora-DB-Cluster empfangen und an das Aurora-Speichersubsystem gesendet wurde.
Fügen Sie den hinzu NetworkThroughput, StorageNetworkThroughputum den Netzwerkdurchsatz zu ermitteln, der von jeder Instance in Ihrem Aurora-DB-Cluster vom Aurora-Speichersubsystem empfangen und an dieses gesendet wurde. Das Instance-Klassenlimit für Ihre Instance sollte größer sein als die Summe dieser beiden kombinierten Metriken.
Sie können die folgenden Metriken verwenden, um zusätzliche Details des Netzwerkverkehrs Ihrer Client-Anwendungen beim Senden und Empfangen zu überprüfen:
-
NetworkReceiveThroughput— Die Menge des Netzwerkdurchsatzes, den jede Instance im Aurora PostgreSQL-DB-Cluster von Clients erhält. Dieser Durchsatz beinhaltet nicht den Netzwerkdatenverkehr zwischen den Instances im -DB-Cluster und dem Cluster-Volume.
-
NetworkTransmitThroughput— Die Menge des Netzwerkdurchsatzes, der von jeder Instance im Aurora-DB-Cluster an Clients gesendet wird. Dieser Durchsatz beinhaltet nicht den Netzwerkdatenverkehr zwischen den Instances im -DB-Cluster und dem Cluster-Volume.
-
StorageNetworkReceiveThroughput— Die Menge des Netzwerkdurchsatzes, den jede Instance im DB-Cluster vom Aurora-Speichersubsystem erhält.
-
StorageNetworkTransmitThroughput— Die Menge des Netzwerkdurchsatzes, der von jeder Instance im DB-Cluster an das Aurora-Speichersubsystem gesendet wird.
Addieren Sie all diese Metriken, um zu bewerten, wie Ihre Netzwerknutzung im Vergleich zum Instance-Klassenlimit abschneidet. Das Instance-Klassenlimit sollte größer sein als die Summe dieser kombinierten Metriken.
Die Netzwerklimits und die CPU-Auslastung für Speicher bedingen sich gegenseitig. Wenn der Netzwerkdurchsatz steigt, steigt auch die CPU-Auslastung. Die Überwachung der CPU- und Netzwerknutzung gibt Aufschluss darüber, wie und warum die Ressourcen erschöpft werden.
Sie können Folgendes in Betracht ziehen, um die Netzwerknutzung zu minimieren:
-
Verwenden einer größeren Instance-Klasse
-
Verwenden von
pg_partman-Partitionierungsstrategien -
Aufteilen der Schreibanforderungen in Batches, um die Gesamttransaktionen zu reduzieren
-
Weiterleiten der schreibgeschützten Workload an eine schreibgeschützte Instance
-
Löschen aller ungenutzten Indizes
-
Suchen nach aufgeblähten Objekten und VACUUM. Verwenden Sie bei stark aufgeblähten Objekten die PostgreSQL-Erweiterung
pg_repack. Weitere Informationen zupg_repackfinden Sie unter Reorganisieren von Tabellen in PostgreSQL-Datenbanken mit minimalen Sperren.
