Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden der Amazon Aurora Global Database
Mit der Amazon Aurora Global Database-Funktion richten Sie mehrere Aurora-DB-Cluster ein, die sich über mehrere erstrecken AWS-Regionen. Aurora synchronisiert automatisch alle im primären DB-Cluster vorgenommenen Änderungen mit einem oder mehreren sekundären Clustern. Eine globale Aurora-Datenbank hat einen primären DB-Cluster in einer Region und bis zu 10 sekundäre DB-Cluster in verschiedenen Regionen. Diese Konfiguration mit mehreren Regionen ermöglicht eine schnelle Wiederherstellung nach dem seltenen Ausfall, der sich auf eine gesamte Region auswirken kann. AWS-Region Eine vollständige Kopie all Ihrer Daten an mehreren geografischen Standorten ermöglicht auch Lesevorgänge mit geringer Latenz für Anwendungen, die von weit voneinander entfernten Standorten auf der ganzen Welt aus eine Verbindung herstellen.
Themen
Überblick über die Amazon Aurora Global Database
Mithilfe der Amazon Aurora Global Database-Funktion können Sie Ihre weltweit verteilten Anwendungen mit einer einzigen Aurora-Datenbank ausführen, die sich über mehrere AWS-Regionen erstreckt.
Eine globale Aurora-Datenbank besteht aus einer primären Datenbank, AWS-Region in die Ihre Daten geschrieben werden, und bis zu 10 schreibgeschützten sekundären Datenbanken. AWS-Regionen Sie führen Schreibvorgänge auf den primären DB-Cluster im primären DB-Cluster aus. AWS-Region Am bequemsten ist es, eine Verbindung zum Aurora Global Database-Writer-Endpunkt herzustellen, der immer auf den primären DB-Cluster verweist, auch nach einem Switchover oder Failover zu einem anderen. AWS-Region Nach jedem Schreibvorgang repliziert Aurora Daten AWS-Regionen mithilfe einer dedizierten Infrastruktur auf die Sekundärseite, wobei die Latenz in der Regel unter einer Sekunde liegt.
In der folgenden Abbildung finden Sie ein Beispiel für eine globale Aurora-Datenbank, die sich über zwei AWS-Regionen erstreckt.
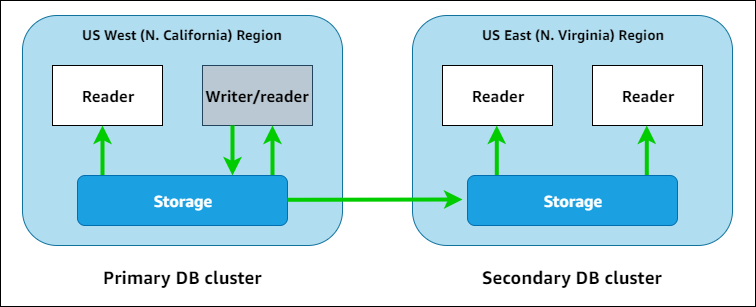
Sie können jeden sekundären Cluster unabhängig skalieren, indem Sie eine oder mehrere Aurora-Reader-Instances hinzufügen, um schreibgeschützte Workloads zu bedienen. Sie können Aurora Serverless v2 für die Reader-Instances eine noch detailliertere und flexiblere Skalierung verwenden.
Nur der primäre Cluster führt Schreibvorgänge aus. Clients, die Schreibvorgänge ausführen, stellen eine Verbindung zum Aurora Global Database-Writer-Endpunkt her, der immer auf die Writer-DB-Instance des primären Clusters verweist. Wie im Diagramm dargestellt, verwendet Aurora das Cluster-Speichervolume und nicht die Datenbank-Engine für eine schnelle Replikation mit geringem Overhead. Weitere Informationen hierzu finden Sie unter Übersicht über Amazon-Aurora-Speicher.
Aurora Global Database wurde für Anwendungen mit weltweiter Präsenz entwickelt. Die mehrfachen schreibgeschützten sekundären DB-Cluster AWS-Regionen tragen dazu bei, Lesevorgänge in der Nähe der Anwendungsbenutzer zu optimieren. Mithilfe der Schreibweiterleitungsfunktion können Sie Ihre globale Datenbank auch so konfigurieren, dass sekundäre Cluster Schreibanforderungen an die primäre Datenbank senden. Weitere Informationen finden Sie unter Verwenden der Schreibweiterleitung in einer Amazon Aurora globalen Datenbank.
Aurora Global Database unterstützt je nach Szenario zwei verschiedene Operationen zum Ändern der Region Ihres primären DB-Clusters: Aurora Global Database-Switchover und Aurora Global Database-Failover.
-
Verwenden Sie für geplante Betriebsverfahren wie die regionale Rotation den Switchover-Mechanismus (früher als „verwaltetes geplantes Failover“ bezeichnet). Mit dieser Funktion können Sie den primären Cluster einer funktionierenden Aurora Global Database ohne Datenverlust in eine ihrer sekundären Regionen verlagern. Weitere Informationen hierzu finden Sie unter Durchführen von Umstellungen für Amazon Aurora Global Databases.
-
Verwenden Sie den Failover-Mechanismus, um Ihre Aurora Global Database nach einem Ausfall in der primären Region wiederherzustellen. Mit dieser Funktion führen Sie einen Failover von Ihrem primären DB-Cluster in eine andere Region durch (regionsübergreifendes Failover). Weitere Informationen hierzu finden Sie unter Ausführen von verwalteten geplanten Failovers für globale Aurora-Datenbanken.
Vorteile von Amazon Aurora Global Database
Durch die Verwendung von Aurora Global Database können Sie die folgenden Vorteile nutzen:
Globale Lesevorgänge mit lokaler Latenz — Wenn Sie Niederlassungen auf der ganzen Welt haben, können Sie Aurora Global Database verwenden, um Ihre wichtigsten Informationsquellen in der Primärdatenbank auf dem neuesten Stand zu halten AWS-Region. Niederlassungen in Ihren anderen Regionen können mit lokaler Latenz auf die Daten in ihrer eigenen Region zugreifen.
Skalierbare sekundäre Aurora-DB-Cluster — Sie können Ihre sekundären Cluster skalieren, indem Sie einem sekundären Cluster weitere schreibgeschützte Instances hinzufügen. AWS-Region Der sekundäre Cluster ist schreibgeschützt, sodass er bis zu 16 schreibgeschützte DB-Instances anstelle der üblichen Grenze von 15 für einen einzelnen Aurora-Cluster unterstützen kann.
Schnelle Replikation vom primären zum sekundären Aurora-DB-Cluster — Die von Aurora Global Database durchgeführte Replikation hat nur geringe Auswirkungen auf die Leistung des primären DB-Clusters. Die Ressourcen der DB-Instances werden ausschließlich für Lese- und Schreib-Workloads von Anwendungen genutzt.
Wiederherstellung nach regionsweiten Ausfällen — Die sekundären Cluster ermöglichen es Ihnen, eine Aurora Global Database schneller (niedrigerer RTO) und mit weniger Datenverlust (niedrigeres RPO) als herkömmliche Replikationslösungen in einer neuen AWS-Region Primärdatenbank verfügbar zu machen.
Verfügbarkeit von Regionen und Versionen
Die Verfügbarkeit von Funktionen und der Support variieren zwischen bestimmten Versionen der einzelnen Aurora-Datenbank-Engines und in allen AWS-Regionen. Weitere Informationen zur Verfügbarkeit von Versionen und Regionen mit Aurora Global Database finden Sie unterUnterstützte Regionen und DB-Engines für globale Aurora-Datenbanken.
Einschränkungen der Amazon Aurora Global Database
Die folgenden Einschränkungen gelten derzeit für Aurora Global Database:
Aurora Global Database ist in bestimmten AWS-Regionen und für bestimmte Versionen von Aurora MySQL und Aurora PostgreSQL verfügbar. Weitere Informationen finden Sie unter Unterstützte Regionen und DB-Engines für globale Aurora-Datenbanken.
Aurora Global Database hat spezifische Konfigurationsanforderungen für unterstützte Aurora-DB-Instance-Klassen AWS-Regionen, die maximale Anzahl von usw. Weitere Informationen finden Sie unter Anforderungen an die Konfiguration einer globalen Amazon-Aurora-Datenbank.
Für Aurora MySQL mit MySQL 5.7-Kompatibilität benötigen Aurora Global Database-Switchover Version 2.09.1 oder eine höhere Nebenversion.
-
Sie können verwaltete regionsübergreifende Switchover oder Failover mit Aurora Global Database nur durchführen, wenn die primären und sekundären DB-Cluster über dieselben Haupt- und Neben-Engine-Versionen verfügen. Je nach Engine- und Engine-Version müssen die Patch-Levels möglicherweise identisch sein oder die Patch-Levels können unterschiedlich sein. Eine Liste der Engines und Engine-Versionen, die diese Operationen zwischen primären und sekundären Clustern mit unterschiedlichen Patch-Stufen ermöglichen, finden Sie unterPatch-Level-Kompatibilität für verwaltete regionsübergreifende Umstellungen und Failovers. Wenn für Ihre Engine-Versionen identische Patch-Levels erforderlich sind, können Sie den Failover manuell durchführen, indem Sie die unter beschriebenen Schritte ausführen. Ausführen von manuellen geplanten Failovers für globale Aurora-Datenbanken
Aurora Global Database unterstützt derzeit die folgenden Aurora-Funktionen nicht:
-
Aurora Serverless v1
-
Rückverfolgung in Aurora
-
Einschränkungen bei der Verwendung der RDS-Proxy-Funktion mit Aurora Global Database finden Sie unterEinschränkungen für RDS Proxy mit globalen Datenbanken.
Das automatische Upgrade der Nebenversion gilt nicht für Aurora MySQL- und Aurora PostgreSQL-Cluster, die Teil einer globalen Datenbank sind. Beachten Sie, dass Sie diese Einstellung für eine DB-Instanz angeben können, die Teil eines globalen Datenbank-Clusters ist, aber die Einstellung hat keine Auswirkungen.
Aurora Global Database unterstützt Aurora Auto Scaling derzeit nicht für sekundäre DB-Cluster.
Um Database Activity Streams (DAS) auf Aurora Global Database verwenden zu können, auf der Aurora MySQL 5.7 ausgeführt wird, muss die Engine-Version 2.08 oder höher sein. Informationen zu DAS finden Sie unterÜberwachung von Amazon Aurora mithilfe von Datenbankaktivitätsstreams.
-
Die folgenden Einschränkungen gelten derzeit für das Upgrade von Aurora Global Database:
Sie können keine benutzerdefinierte Parametergruppe auf den globalen Datenbank-Cluster anwenden, während Sie ein Hauptversions-Upgrade dieser globalen Aurora-Datenbank durchführen. Sie erstellen Ihre benutzerdefinierten Parametergruppen in jeder Region des globalen Clusters und wenden sie nach dem Upgrade manuell auf die regionalen Cluster an.
-
Mit einer globalen Aurora-Datenbank, die auf Aurora MySQL basiert, können Sie kein direktes Upgrade von Aurora MySQL Version 2 auf Version 3 durchführen, wenn der
lower_case_table_names-Parameter aktiviert ist. Weitere Informationen zu den möglichen Verfahren finden Sie unter Hauptversions-Upgrades. Mit Aurora Global Database können Sie kein Hauptversions-Upgrade der Aurora PostgreSQL-DB-Engine durchführen, wenn die Recovery Point Objective (RPO) -Funktion aktiviert ist. Weitere Informationen über RPO-Funktion finden Sie unter Verwaltung RPOs für globale Aurora-PostgreSQL-Datenbanken.
Mit einer Aurora Global Database können Sie kein kleineres Versionsupgrade von Aurora MySQL Version 3.01 oder 3.02 auf 3.03 oder höher mithilfe des Standardprozesses durchführen. Weitere Informationen zu dem zu verwendenden Prozess finden Sie unter Upgrade von Aurora MySQL durch Ändern der Engine-Version.
Informationen zum Upgrade von Aurora Global Database finden Sie unterAktualisieren einer Amazon Aurora Global Database.
Sie können die Aurora-DB-Cluster in Ihrer globalen Datenbank nicht einzeln stoppen oder starten. Weitere Informationen hierzu finden Sie unter Stoppen und Starten eines Amazon Aurora-DB-Clusters.
Aurora-Reader-DB-Instances, die an den sekundären Aurora-DB-Cluster angeschlossen sind, können unter bestimmten Umständen neu gestartet werden. Wenn die AWS-Region Writer-DB-Instance der primären Instanz neu gestartet oder ausgefallen wird, werden auch die Leser-DB-Instances in den sekundären Regionen neu gestartet. Der sekundäre Cluster ist dann nicht verfügbar, bis alle Reader-DB-Instances wieder mit der Writer-Instance des primären DB-Clusters synchronisiert sind. Das Verhalten des primären Clusters beim Neustart oder während eines Failovers ist dasselbe wie bei einem einzelnen, nicht globalen DB-Cluster. Weitere Informationen finden Sie unter Replikation mit Amazon Aurora.
Stellen Sie sicher, dass Sie die Auswirkungen auf Ihre globale Datenbank verstehen, bevor Sie Änderungen an Ihrem primären DB-Cluster vornehmen. Weitere Informationen hierzu finden Sie unter Wiederherstellen einer globalen Amazon Aurora-Datenbank nach einem ungeplanten Ausfall.
Aurora Global Database unterstützt derzeit nicht den
inaccessible-encryption-credentials-recoverableStatus, wenn Amazon Aurora den Zugriff auf den AWS KMS Schlüssel für den DB-Cluster verliert. In diesen Fällen wechselt der verschlüsselte DB-Cluster direkt in den Beendigungszustandinaccessible-encryption-credentials. Weitere Informationen zu diesen Zuständen finden Sie unter Anzeigen des DB-Clusterstatus.-
Secrets Manager unterstützt Aurora Global Database nicht. Wenn Sie einer globalen Datenbank eine Region hinzufügen, müssen Sie zuerst die Secrets Manager Manager-Integration für die DB-Instance deaktivieren.
-
Aurora PostgreSQL-basierte DB-Cluster, die Aurora Global Database verwenden, haben die folgenden Einschränkungen:
Die Cluster-Cache-Verwaltung wird für sekundäre Aurora PostgreSQL-DB-Cluster, die Teil der globalen Aurora-Datenbanken sind, nicht unterstützt.
-
Wenn der primäre DB-Cluster Ihrer globalen Datenbank auf einem Replikat einer Amazon RDS PostgreSQL-Instance basiert, können Sie keinen sekundären Cluster erstellen. Versuchen Sie nicht, mithilfe der API-Operation, der oder der AWS Management Console API-Operation einen sekundären Cluster zu erstellen. AWS CLI
CreateDBClusterSolche Versuche werden unterbrochen und der sekundäre Cluster wird nicht erstellt.
Wir empfehlen, dass Sie sekundäre DB-Cluster für Ihre globalen Datenbanken erstellen, indem Sie dieselbe Version der Aurora-DB-Engine wie die primäre Version verwenden. Weitere Informationen finden Sie unter Erstellen einer Amazon Aurora Global Database.
