Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwenden von Switchover oder Failover in Amazon Aurora Global Database
Die Aurora Global Database-Funktion bietet mehr Schutz vor Geschäftskontinuität und Disaster Recovery (BCDR) als die standardmäßige Hochverfügbarkeit, die ein Aurora-DB-Cluster in einem einzigen AWS-Region bietet. Mithilfe von Aurora Global Database können Sie eine schnellere Wiederherstellung nach seltenen, ungeplanten regionalen Katastrophen planen oder Service-Level-Ausfälle schnell abschließen.
Sie können die folgenden Anleitungen und Verfahren zur Planung, Prüfung und Implementierung Ihrer BCDR-Strategie mithilfe der Aurora Global Database-Funktion nutzen.
Themen
Planung für Geschäftskontinuität und Disaster Recovery
Um Ihre Strategie für Geschäftskontinuität und Disaster Recovery zu planen, ist es hilfreich, die folgenden Branchenterminologien zu verstehen und zu verstehen, wie sich diese Begriffe auf die Funktionen der Aurora Global Database beziehen.
Die Wiederherstellung nach einem Notfall wird in der Regel von den folgenden beiden Geschäftszielen bestimmt:
-
Recovery Time Objective (RTO) – Die Zeit, die ein System benötigt, um nach einem Notfall in einen arbeitsfähigen Zustand zurückzukehren. Mit anderen Worten: RTO misst die Ausfallzeit. Für Aurora Global Database kann RTO in der Größenordnung von Minuten liegen.
-
Recovery Point Objective (RPO) – Die Datenmenge, die nach einer Katastrophe oder einem Serviceausfall verloren gehen kann (gemessen in Zeit). Dieser Datenverlust ist in der Regel auf asynchrone Replikationsverzögerungen zurückzuführen. Für eine globale Aurora-Datenbank wird die RPO in der Regel in Sekunden gemessen. Mit einer Aurora PostgreSQL–basierten globalen Datenbank können Sie den Parameter
rds.global_db_rpoverwenden, um die RPO-Obergrenze festzulegen und zu überwachen, dies könnte jedoch die Transaktionsverarbeitung auf dem Writer-Knoten des primären Clusters beeinträchtigen. Weitere Informationen finden Sie unter Verwaltung RPOs für globale Aurora-PostgreSQL-Datenbanken.
Die Durchführung eines Switchovers oder Failovers mit Aurora Global Database beinhaltet die Heraufstufung eines sekundären DB-Clusters zum primären DB-Cluster. Der Begriff „regionaler Ausfall“ wird häufig verwendet, um eine Vielzahl von Ausfallszenarien zu beschreiben. Ein schlimmstmögliches Szenario könnte ein großflächiger Ausfall aufgrund eines katastrophalen Ereignisses sein, das Hunderte von Quadratkilometern betrifft. Die meisten Ausfälle sind jedoch viel stärker lokal begrenzt und betreffen nur einen kleinen Teil der Cloud-Dienste oder Kundensysteme. Berücksichtigen Sie den gesamten Umfang des Ausfalls, um sicherzustellen, dass regionsübergreifendes Failover die richtige Lösung ist, und wählen Sie die für die jeweilige Situation geeignete Failover-Methode aus. Ob Sie den Failover- oder den Umstellungs-Ansatz verwenden sollten, hängt vom jeweiligen Ausfallszenario ab:
-
Failover – Verwenden Sie diesen Ansatz, um die Daten nach einem ungeplanten Ausfall wiederherzustellen. Damit führen Sie ein regionsübergreifendes Failover auf einen der sekundären DB-Cluster in Ihrer globalen Aurora-Datenbank durch. Das RPO für diesen Ansatz ist in der Regel ein Wert ungleich Null, der in Sekunden gemessen wird. Das Ausmaß des Datenverlusts hängt von der Verzögerung der globalen Aurora-Datenbankreplikation zum AWS-Regionen Zeitpunkt des Ausfalls ab. Weitere Informationen hierzu finden Sie unter Wiederherstellen einer globalen Amazon Aurora-Datenbank nach einem ungeplanten Ausfall.
-
Switchover — Dieser Vorgang wurde zuvor als „verwaltetes geplantes Failover“ bezeichnet. Verwenden Sie diesen Ansatz für kontrollierte Szenarien, z. B. für die betriebliche Wartung und andere geplante Betriebsabläufe, bei denen sich alle Aurora-Cluster und andere Dienste, mit denen sie interagieren, in einem fehlerfreien Zustand befinden. Da diese Funktion die sekundären DB-Cluster mit dem primären synchronisiert, bevor andere Änderungen vorgenommen werden, ist der RPO 0 (kein Datenverlust). Weitere Informationen hierzu finden Sie unter Durchführen von Umstellungen für Amazon Aurora Global Databases.
Anmerkung
Bevor Sie einen Switchover oder ein Failover zu einem kopflosen sekundären Aurora-DB-Cluster durchführen können, müssen Sie ihm eine DB-Instance hinzufügen. Weitere Informationen zu kopflosen DB-Clustern finden Sie unter Erstellen eines Aurora-Headless-DB-Clusters in einer sekundären Region.
Durchführen von Umstellungen für Amazon Aurora Global Databases
Anmerkung
Switchovers wurden früher als verwaltete geplante Failover bezeichnet.
Mithilfe von Switchovers können Sie die Region Ihres primären Clusters routinemäßig ändern. Dieser Ansatz ist für kontrollierte Szenarien gedacht, z. B. für betriebliche Wartung und andere geplante Betriebsverfahren.
Es gibt drei gängige Anwendungsfälle für die Verwendung von Umstellungen.
-
Für Anforderungen an die „regionale Rotation“, die in bestimmten Branchen gelten. Beispielsweise könnten die Vorschriften für Finanzdienstleistungen vorschreiben, dass Tier-0-Systeme für mehrere Monate in eine andere Region wechseln müssen, um sicherzustellen, dass die Notfallwiederherstellungsverfahren regelmäßig geübt werden.
-
Für "follow-the-sun" -Anwendungen mit mehreren Regionen. Beispielsweise möchte ein Unternehmen möglicherweise Schreibvorgänge mit niedrigerer Latenz in verschiedenen Regionen bereitstellen, basierend auf den Geschäftszeiten in verschiedenen Zeitzonen.
-
Als zero-data-loss Methode, um nach einem Failover zur ursprünglichen primären Region zurückzukehren.
Anmerkung
Switchover sind für die Verwendung in einer globalen Aurora-Datenbank konzipiert, in der sich alle Aurora-Cluster und andere Dienste, mit denen sie interagieren, in einem fehlerfreien Zustand befinden. Folgen Sie zur Wiederherstellung nach einem ungeplanten Ausfall dem entsprechenden Verfahren unter Wiederherstellen einer globalen Amazon Aurora-Datenbank nach einem ungeplanten Ausfall.
Sie können verwaltete regionsübergreifende Switchover mit Aurora Global Database nur durchführen, wenn die primären und sekundären DB-Cluster über dieselben Haupt- und Neben-Engine-Versionen verfügen. Je nach Engine- und Engine-Version müssen die Patch-Levels möglicherweise identisch sein oder die Patch-Levels können unterschiedlich sein. Eine Liste der Engines und Engine-Versionen, die diese Operationen zwischen primären und sekundären Clustern mit unterschiedlichen Patch-Stufen ermöglichen, finden Sie unterPatch-Level-Kompatibilität für verwaltete regionsübergreifende Umstellungen und Failovers. Bevor Sie mit der Umstellung beginnen, überprüfen Sie die Engine-Versionen in Ihrem globalen Cluster, um sicherzustellen, dass diese verwaltete regionsübergreifende Umstellungen unterstützen, und aktualisieren Sie sie bei Bedarf.
Während eines Switchovers macht Aurora den Cluster in der von Ihnen ausgewählten sekundären Region zu Ihrem primären Cluster. Der Switchover-Mechanismus behält die bestehende Replikationstopologie Ihrer globalen Datenbank bei: Sie hat immer noch dieselbe Anzahl von Aurora-Clustern in denselben Regionen. Bevor Aurora den Switchover-Prozess startet, wartet es, bis die Cluster der sekundären Zielregion vollständig mit dem Cluster der primären Region synchronisiert sind. Dann wird der DB-Cluster in der primären Region schreibgeschützt. Der gewählte sekundäre Cluster stuft einen seiner schreibgeschützten Knoten in den vollen Writer-Status herauf, sodass dieser sekundäre Cluster die Rolle des primären Clusters übernehmen kann. Da der sekundäre Zielcluster zu Beginn des Prozesses mit dem Primärcluster synchronisiert wurde, setzt der neue Primärcluster den Betrieb für die globale Aurora-Datenbank fort, ohne Daten zu verlieren. Ihre Datenbank ist für kurze Zeit nicht verfügbar, während der primäre und der ausgewählte sekundäre Cluster ihre neuen Rollen übernehmen.
Anmerkung
Informationen zur Verwaltung von Replikationsslots für Aurora PostgreSQL nach einem Switchover finden Sie unter. Verwaltung logischer Steckplätze für Aurora Postgre SQL
Um die Anwendungsverfügbarkeit zu optimieren, empfehlen wir Ihnen, vor der Verwendung dieser Funktion Folgendes zu tun:
-
Führen Sie diesen Vorgang außerhalb der Spitzenzeiten oder zu einem anderen Zeitpunkt durch, wenn die Schreibvorgänge auf den primären DB-Clustern minimal sind.
-
Überprüfen Sie die Verzögerungszeiten für alle sekundären Aurora-DB-Cluster in der globalen Aurora-Datenbank. Verwenden Sie Amazon CloudWatch für alle Aurora PostgreSQL-basierten globalen Datenbanken und für Aurora MySQL-basierte globale Datenbanken ab Engine-Versionen 3.04.0 und höher oder 2.12.0 und höher, um die Metrik für alle sekundären DB-Cluster anzuzeigen.
AuroraGlobalDBRPOLagZeigen Sie für niedrigere Nebenversionen von Aurora MySQL-basierten globalen Datenbanken stattdessen dieAuroraGlobalDBReplicationLag-Metrik an. Diese Metriken geben an, wie weit (in Millisekunden) ein sekundärer Cluster gegenüber dem primären DB-Cluster verzögert ist. Der Wert verhält sich direkt proportional zu der Zeit, die Aurora zum Abschließen der Umstellung benötigt. Je größer der Verzögerungswert, desto länger dauert die Umstellung. Wenn Sie diese Metriken untersuchen, tun Sie dies vom aktuellen primären Cluster aus.Weitere Informationen zu CloudWatch Metriken für Aurora finden Sie unterMetriken auf Clusterebene für Amazon Aurora.
-
Der sekundäre DB-Cluster, der während eines Switchovers heraufgestuft wird, hat möglicherweise andere Konfigurationseinstellungen als der alte primäre DB-Cluster. Wir empfehlen Ihnen, die folgenden Arten von Konfigurationseinstellungen für alle Cluster in Ihren globalen Aurora-Datenbankclustern einheitlich zu halten. Auf diese Weise können Leistungsprobleme, Workload-Inkompatibilitäten und anderes ungewöhnliches Verhalten nach einem Switchover minimiert werden.
-
Aurora-DB-Cluster-Parametergruppe für den neuen primären Cluster konfigurieren, falls erforderlich — Wenn Sie einen sekundären DB-Cluster zur Übernahme der primären Rolle heraufstufen, wird die Parametergruppe des sekundären DB-Clusters möglicherweise anders konfiguriert als die des primären. Ist dies der Fall, ändern Sie die Parametergruppe des hochgestuften sekundären DB-Clusters so, dass sie den Einstellungen des primären Clusters entspricht. Um zu erfahren wie, siehe Ändern von Parametern für eine Aurora globale Datenbank.
-
Überwachungstools und -optionen wie Amazon CloudWatch Events und Alarme konfigurieren — Konfigurieren Sie den beworbenen DB-Cluster mit den gleichen Protokollierungsfunktionen, Alarmen usw., wie es für die globale Datenbank erforderlich ist. Wie bei Parametergruppen wird die Konfiguration für diese Funktionen während der Umstellung nicht vom primären Cluster übernommen. Einige CloudWatch Metriken, wie z. B. die Verzögerung bei der Replikation, sind nur für sekundäre Regionen verfügbar. Daher ändert sich bei einer Umstellung die Art und Weise, wie diese Metriken angezeigt und Alarme für sie eingerichtet werden, und es können Änderungen an allen vordefinierten Dashboards erforderlich sein. Weitere Informationen zu Aurora-DB-Clustern und deren Überwachung finden Sie unterÜberwachung von Amazon Aurora Aurora-Metriken mit Amazon CloudWatch.
-
Integrationen mit anderen AWS Diensten konfigurieren — Wenn Ihre globale Aurora-Datenbank in AWS Dienste wie Amazon S3 integriert ist AWS Secrets Manager AWS Identity and Access Management, stellen Sie sicher AWS Lambda, dass Sie Ihre Integrationen mit diesen Diensten nach Bedarf konfigurieren. Weitere Informationen zur Integration globaler Aurora-Datenbanken in IAM, Amazon S3 und Lambda finden Sie unter Verwenden von globalen Amazon-Aurora-Datenbanken mit anderen AWS -Services. Weitere Informationen zu Secrets Manager finden Sie unter So automatisieren Sie die Replikation von Geheimnissen in AWS Secrets Manager Across AWS-Regionen
.
-
Wenn Sie den Aurora Global Database-Writer-Endpunkt verwenden, müssen Sie die Verbindungseinstellungen in Ihrer Anwendung nicht ändern. Stellen Sie sicher, dass die DNS-Änderungen weitergegeben wurden und dass Sie eine Verbindung herstellen und Schreibvorgänge auf dem neuen primären Cluster ausführen können. Anschließend können Sie den vollen Betrieb Ihrer Anwendung wieder aufnehmen.
Angenommen, Ihre Anwendungsverbindungen verwenden den Cluster-Endpunkt des alten primären Clusters und nicht den globalen Writer-Endpunkt. Stellen Sie in diesem Fall sicher, dass Sie die Verbindungseinstellungen Ihrer Anwendung so ändern, dass sie den Cluster-Endpunkt des neuen primären Clusters verwenden. Wenn Sie die angegebenen Namen beim Erstellen der globalen Aurora-Datenbank akzeptiert haben, können Sie den Endpunkt ändern, indem Sie -ro aus der Endpunkt-Zeichenfolge des hochgestuften Clusters in Ihrer Anwendung entfernen. Beispielsweise wird der Endpunkt des sekundären Clusters my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com zu my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com, wenn dieser Cluster zum primären Cluster hochgestuft wird.
Wenn Sie den RDS-Proxy verwenden, stellen Sie sicher, dass die Schreibvorgänge Ihrer Anwendung an den entsprechenden read/write endpoint of the proxy that's associated with the new primary cluster. This proxy endpoint might be the default endpoint or a custom read/write Endpunkt umgeleitet werden. Weitere Informationen finden Sie unter So funktionieren RDS-Proxy-Endpunkte mit globalen Datenbanken.
Sie können einen Aurora Global Database-Switchover mithilfe der AWS Management Console AWS CLI, der oder der RDS-API durchführen.
So führen Sie eine Umstellung in Ihrer Aurora Global Database durch
Melden Sie sich bei der an AWS Management Console und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. -
Wählen Sie Datenbanken und suchen Sie die globale Aurora-Datenbank, in der Sie den Switchover durchführen möchten.
-
Wählen Sie im Menü Aktionen die Option Failover für globale Datenbank ausführen aus.
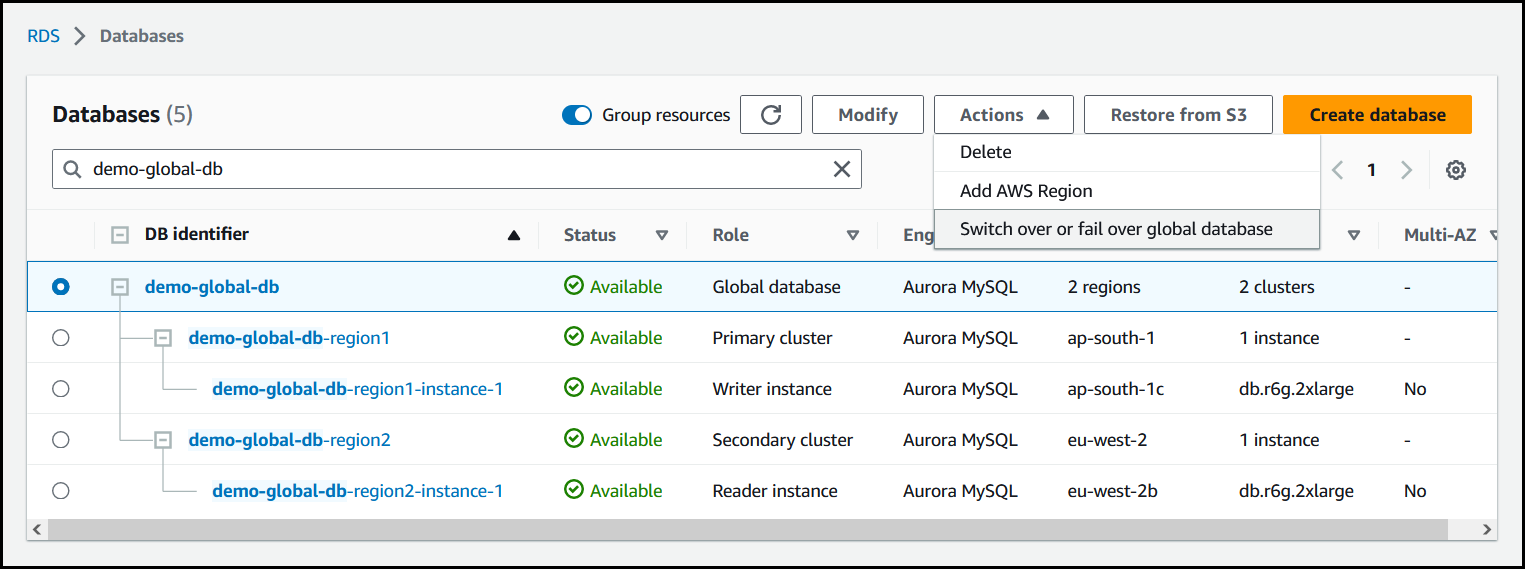
-
Wählen Sie Umschaltung.
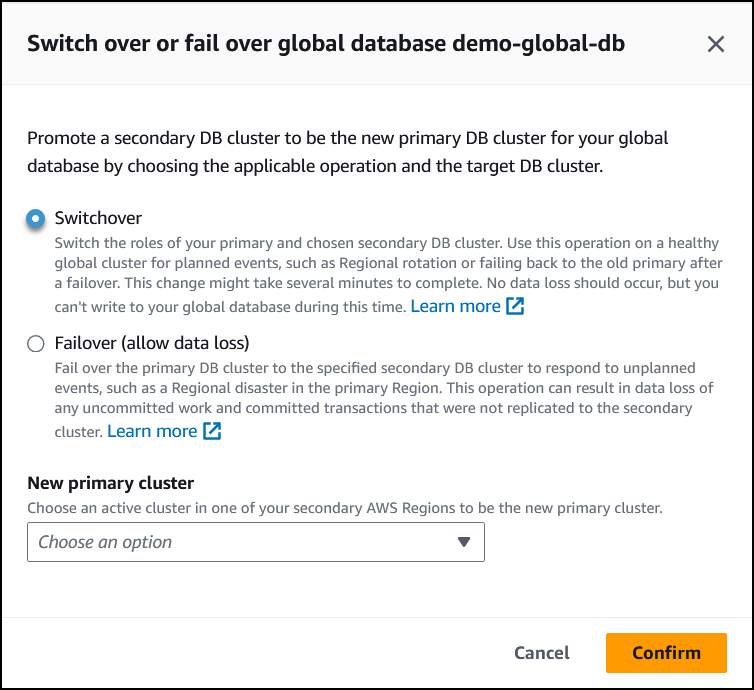
-
Wählen Sie für Neuer primärer Cluster einen aktiven Cluster in einer Ihrer sekundären AWS-Regionen als neuen primären Cluster aus.
-
Wählen Sie Bestätigen aus.
Wenn die Umstellung abgeschlossen ist, werden die Aurora-DB-Cluster und ihr aktueller Status wie im Folgenden dargestellt in der Liste Datenbanken angezeigt.
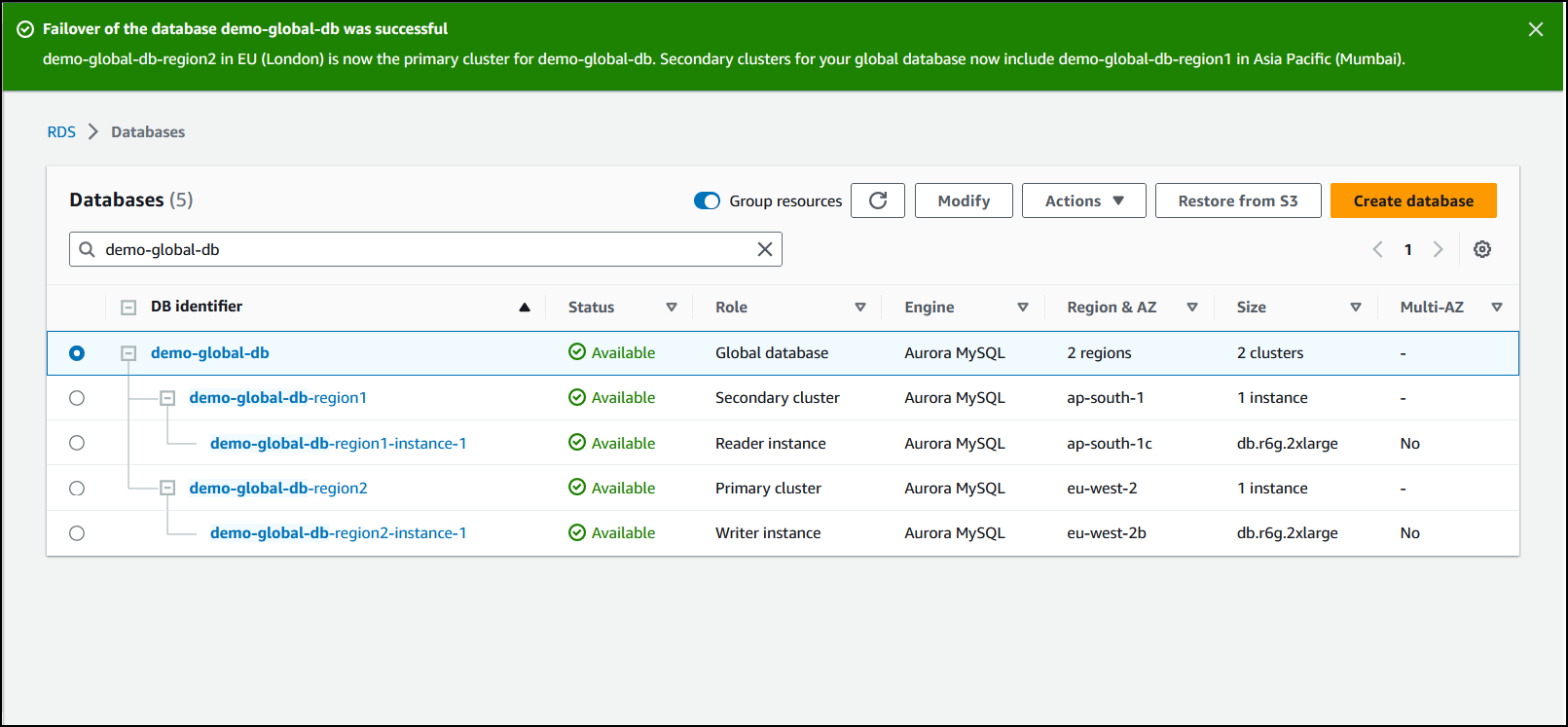
So führen Sie eine Umstellung auf einer Aurora Global Database durch
Verwenden Sie den switchover-global-cluster CLI-Befehl, um einen Switchover für Aurora Global Database durchzuführen. Mit dem Befehl können Sie Werte für die folgenden Parameter übertragen.
-
--region— Geben Sie an AWS-Region , wo der primäre DB-Cluster der globalen Aurora-Datenbank läuft. -
--global-cluster-identifier– Geben Sie den Namen Ihrer globalen Aurora-Datenbank an. -
--target-db-cluster-identifier– Geben Sie den Amazon-Ressourcennamen (ARN) des Aurora-DB-Clusters an, den Sie als primäres Cluster für die globale Aurora-Datenbank hochstufen möchten.
Für LinuxmacOS, oderUnix:
aws rds --regionregion_of_primary\ switchover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote
Windows:
aws rds --regionregion_of_primary^ switchover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote
Um einen Switchover für Aurora Global Database durchzuführen, führen Sie den SwitchoverGlobalClusterAPI-Vorgang aus.
Wiederherstellen einer globalen Amazon Aurora-Datenbank nach einem ungeplanten Ausfall
In seltenen Fällen kann es bei Ihrer globalen Aurora-Datenbank zu einem unerwarteten Ausfall der AWS-Region Primärdatenbank kommen. In einem solchen Fall sind der primäre Aurora-DB-Cluster und sein Writer-Knoten nicht verfügbar, und die Replikation zwischen dem primären Cluster und den sekundären Clustern wird angehalten. Um Ausfallzeiten (RTO) und Datenverlust (RPO) zu minimieren, können Sie schnell ein regionsübergreifendes Failover durchführen.
Aurora Global Database verfügt über zwei Failover-Methoden, die Sie in einer Notfallwiederherstellungssituation verwenden können:
-
Verwaltetes Failover — Diese Methode wird für die Notfallwiederherstellung empfohlen. Wenn Sie diese Methode verwenden, fügt Aurora die alte primäre Region automatisch wieder als sekundäre Region zur globalen Datenbank hinzu, sobald sie wieder verfügbar ist. Somit wird die ursprüngliche Topologie Ihres globalen Clusters beibehalten. Um zu erfahren, wie Sie diese Methode verwenden, vgl. Ausführen von verwalteten geplanten Failovers für globale Aurora-Datenbanken.
-
Manuelles Failover – Diese alternative Methode kann verwendet werden, wenn ein verwaltetes Failover nicht in Frage kommt, z. B. wenn in Ihren primären und sekundären Regionen inkompatible Engine-Versionen ausgeführt werden. Um zu erfahren, wie Sie diese Methode verwenden, vgl. Ausführen von manuellen geplanten Failovers für globale Aurora-Datenbanken.
Wichtig
Beide Failover-Methoden können zum Verlust von Schreibtransaktionsdaten führen, die vor dem Eintreten des Failover-Ereignisses nicht zur gewählten sekundären Region repliziert wurden. Der Wiederherstellungsprozess, der eine DB-Instance auf dem ausgewählten sekundären DB-Cluster zur primären Writer-DB-Instance hochstuft, garantiert jedoch, dass sich die Daten in einem transaktionskonsistenten Zustand befinden. Failovers sind auch anfällig für Split-Brain-Probleme.
Ausführen von verwalteten geplanten Failovers für globale Aurora-Datenbanken
Dieser Ansatz dient der Geschäftskontinuität im Falle einer echten regionalen Katastrophe oder eines kompletten Service-Level-Ausfalls.
Während eines verwalteten Failovers wird der sekundäre Cluster in der von Ihnen ausgewählten sekundären Region zum neuen primären Cluster. Der gewählte sekundäre Cluster stuft einen seiner schreibgeschützten Knoten auf vollen Writer-Status herauf. In diesem Schritt kann der Cluster die Rolle des primären Clusters übernehmen. Ihre Datenbank ist für kurze Zeit nicht verfügbar, während dieser Cluster seine neue Rolle annimmt. Sobald diese alte primäre Region fehlerfrei und wieder verfügbar ist, fügt Aurora sie automatisch wieder als sekundäre Region zum globalen Cluster hinzu. Somit wird die bestehende Replikationstopologie Ihrer globalen Aurora-Datenbank beibehalten.
Anmerkung
Informationen zur Verwaltung von Replikationsslots für Aurora PostgreSQL nach einem Failover finden Sie unter. Verwaltung logischer Steckplätze für Aurora Postgre SQL
Anmerkung
Sie können verwaltete regionsübergreifende Failover mit Aurora Global Database nur durchführen, wenn die primären und sekundären DB-Cluster über dieselben Haupt- und Neben-Engine-Versionen verfügen. Je nach Engine und Engine-Versionen müssen die Patch-Levels möglicherweise identisch sein oder die Patch-Levels können unterschiedlich sein. Eine Liste der Engines und Engine-Versionen, die diese Operationen zwischen primären und sekundären Clustern mit unterschiedlichen Patch-Stufen ermöglichen, finden Sie unterPatch-Level-Kompatibilität für verwaltete regionsübergreifende Umstellungen und Failovers. Bevor Sie mit dem Failover beginnen, überprüfen Sie die Engine-Versionen in Ihrem globalen Cluster, um sicherzustellen, dass sie verwaltetes regionsübergreifendes Switchover unterstützen, und aktualisieren Sie sie bei Bedarf. Wenn für Ihre Engine-Versionen identische Patch-Levels erforderlich sind, aber unterschiedliche Patch-Levels ausgeführt werden, können Sie den Failover manuell durchführen, indem Sie die unter beschriebenen Schritte ausführen. Ausführen von manuellen geplanten Failovers für globale Aurora-Datenbanken
Beim verwalteten Failover wird nicht darauf gewartet, dass Daten zwischen der ausgewählten sekundären Region und der aktuellen primären Region synchronisiert werden. Da Aurora Global Database Daten asynchron repliziert, ist es möglich, dass nicht alle Transaktionen in die gewählte sekundäre AWS Region repliziert wurden, bevor sie auf volle Lese-/Schreibfunktionen heraufgestuft wurde.
Um sicherzustellen, dass sich die Daten in einem konsistenten Zustand befinden, erstellt Aurora nach der Wiederherstellung ein neues Speichervolume für die alte Primärregion. Bevor das neue Speichervolume in der AWS Region erstellt wird, versucht Aurora, zum Zeitpunkt des Fehlers einen Snapshot des alten Speichervolumes zu erstellen. Auf diese Weise können Sie den Snapshot und alle fehlenden Daten wiederherstellen. Wenn dieser Vorgang erfolgreich ist, platziert Aurora diesen Snapshot mit dem Namen rds:unplanned-global-failover- im Snapshot-Abschnitt von AWS Management Console. Sie können auch den name-of-old-primary-DB-cluster-timestampdescribe-db-cluster-snapshots AWS CLI Befehl oder die DescribeDBClusterSnapshots API-Operation verwenden, um Details für den Snapshot anzuzeigen.
Wenn Sie ein verwaltetes Failover initiieren, versucht Aurora auch, den Schreibverkehr über die hochverfügbare Aurora-Speicherschicht zu stoppen. Wir bezeichnen diesen Mechanismus als „Write-Fencing“. Wenn der Vorgang erfolgreich ist, gibt Aurora ein RDS-Ereignis aus, das Sie darüber informiert, dass Schreibvorgänge gestoppt wurden. Im unwahrscheinlichen Fall, dass mehrere AZ-Ausfälle in einer Region auftreten, ist es möglich, dass der Write-Fencing-Prozess nicht rechtzeitig erfolgreich ist. In diesem Fall gibt Aurora ein RDS-Ereignis aus, das Sie darüber informiert, dass das Zeitlimit für den Vorgang zum Stoppen von Schreibvorgängen überschritten wurde. Wenn der alte primäre Cluster im Netzwerk erreichbar ist, zeichnet Aurora diese Ereignisse dort auf. Wenn nicht, zeichnet Aurora die Ereignisse auf dem neuen primären Cluster auf. Weitere Informationen zu diesen Ereignissen finden Sie unterDB-Cluster-Ereignisse. Da das Fencing von Schreibvorgängen ein Versuch nach besten Kräften ist, ist es möglich, dass Schreibvorgänge vorübergehend in der alten primären Region akzeptiert werden, was zu Split-Brain-Problemen führt.
Wir empfehlen, dass Sie die folgenden Aufgaben ausführen, bevor Sie ein Failover mit Aurora Global Database durchführen. Dadurch wird die Möglichkeit von Split-Brain-Problemen oder der Wiederherstellung nicht replizierter Daten aus dem Snapshot des alten primären Clusters minimiert.
-
Um zu verhindern, dass Schreibvorgänge an den primären Cluster von Aurora Global Database gesendet werden, schalten Sie Anwendungen offline.
-
Stellen Sie sicher, dass alle Anwendungen, die eine Verbindung zum primären DB-Cluster herstellen, den globalen Writer-Endpunkt verwenden. Dieser Endpunkt hat einen Wert, der auch dann gleich bleibt, wenn eine neue Region aufgrund von Switchover oder Failover zum primären Cluster wird. Aurora implementiert zusätzliche Sicherheitsvorkehrungen, um die Möglichkeit von Datenverlusten bei Schreibvorgängen zu minimieren, die über den globalen Endpunkt übermittelt werden. Weitere Informationen zu globalen Writer-Endpunkten finden Sie unter. Verbindung zur Amazon Aurora Global Database herstellen
-
Wenn Sie den globalen Writer-Endpunkt verwenden und Ihre Anwendungs- oder Netzwerkschicht DNS-Werte zwischenspeichert, reduzieren Sie die TTL time-to-live (TTL) Ihres DNS-Caches auf einen niedrigen Wert, z. B. 5 Sekunden. Auf diese Weise registriert Ihre Anwendung DNS-Änderungen schnell beim globalen Writer-Endpunkt. Aurora versucht zwar, Schreibvorgänge in der alten Primärregion zu blockieren, es ist jedoch nicht garantiert, dass die Aktion erfolgreich ist. Durch die Reduzierung der DNS-Cache-Dauer wird die Wahrscheinlichkeit von Split-Brain-Problemen weiter reduziert. Als Alternative können Sie nach dem RDS-Ereignis suchen, das Sie darüber informiert, wann Aurora die DNS-Änderungen für den globalen Writer-Endpunkt beobachtet hat. Auf diese Weise können Sie überprüfen, ob Ihre Anwendung die DNS-Änderung auch registriert hat, bevor Sie den Schreibverkehr Ihrer Anwendung neu starten.
-
Überprüfen Sie die Verzögerungszeiten für alle sekundären Aurora-DB-Cluster in der Aurora Global Database. Durch die Auswahl der sekundären Region mit der geringsten Replikationsverzögerung kann der Datenverlust in der aktuell ausgefallenen primären Region minimiert werden.
Verwenden Sie Amazon CloudWatch für alle Versionen von Aurora PostgreSQL-basierten globalen Datenbanken und für Aurora MySQL-basierte globale Datenbanken ab Engine-Versionen 3.04.0 und höher oder 2.12.0 und höher, um die Metrik für alle sekundären DB-Cluster anzuzeigen.
AuroraGlobalDBRPOLagZeigen Sie für niedrigere Nebenversionen von Aurora MySQL-basierten globalen Datenbanken stattdessen dieAuroraGlobalDBReplicationLag-Metrik an. Diese Metriken geben an, wie weit (in Millisekunden) ein sekundärer Cluster gegenüber dem primären DB-Cluster verzögert ist.Weitere Informationen zu CloudWatch Metriken für Aurora finden Sie unterMetriken auf Clusterebene für Amazon Aurora.
Während eines verwalteten Failovers wird der ausgewählte sekundäre DB-Cluster in seine neue Rolle als primärer Cluster hochgestuft. Er übernimmt jedoch nicht die verschiedenen Konfigurationsoptionen des primären DB-Clusters. Wenn die Konfiguration nicht übereinstimmt, kann dies Leistungsprobleme, Workload-Inkompatibilitäten und anderes anomales Verhalten zur Folge haben. Um solche Probleme zu vermeiden, empfehlen wir Ihnen, die Unterschiede zwischen den Clustern Ihrer globalen Aurora-Datenbank wie folgt aufzulösen:
-
Aurora-DB-Cluster-Parametergruppe für den neuen Primärserver konfigurieren, falls erforderlich — Sie können Ihre Aurora-DB-Cluster-Parametergruppen unabhängig für jeden Aurora-Cluster in Ihrer Aurora Global Database konfigurieren. Wenn Sie also einen sekundären DB-Cluster zur Übernahme der primären Rolle hochstufen, kann die Parametergruppe des sekundären Clusters im Vergleich zum primären Cluster möglicherweise anders konfiguriert sein. Ist dies der Fall, ändern Sie die Parametergruppe des hochgestuften sekundären DB-Clusters so, dass sie den Einstellungen des primären Clusters entspricht. Um zu erfahren wie, siehe Ändern von Parametern für eine Aurora globale Datenbank.
-
Überwachungstools und -optionen wie Amazon CloudWatch Events und Alarme konfigurieren — Konfigurieren Sie den beworbenen DB-Cluster mit den gleichen Protokollierungsfunktionen, Alarmen usw., wie es für die globale Datenbank erforderlich ist. Wie bei Parametergruppen wird die Konfiguration für diese Funktionen während des Failover-Prozesses nicht vom primären Cluster übernommen. Einige CloudWatch Metriken, wie z. B. die Verzögerung bei der Replikation, sind nur für sekundäre Regionen verfügbar. Daher ändert ein Failover die Art und Weise, wie diese Metriken angezeigt und Alarme für sie eingerichtet werden, und es können Änderungen an allen vordefinierten Dashboards erforderlich sein. Weitere Informationen zur Überwachung von Aurora-DB-Clustern finden Sie unterÜberwachung von Amazon Aurora Aurora-Metriken mit Amazon CloudWatch.
-
Integrationen mit anderen AWS Diensten konfigurieren — Wenn Ihre Aurora Global Database in andere AWS Dienste wie,, Amazon S3 und integriert ist AWS Secrets Manager AWS Identity and Access Management, müssen Sie sicherstellen AWS Lambda, dass diese so konfiguriert sind, dass sie für den Zugriff aus beliebigen sekundären Regionen erforderlich sind. Weitere Informationen zur Integration globaler Aurora-Datenbanken in IAM, Amazon S3 und Lambda finden Sie unter Verwenden von globalen Amazon-Aurora-Datenbanken mit anderen AWS -Services. Weitere Informationen zu Secrets Manager finden Sie unter So automatisieren Sie die Replikation von Geheimnissen in AWS Secrets Manager Across AWS-Regionen
.
In der Regel übernimmt der gewählte sekundäre Cluster innerhalb weniger Minuten die primäre Rolle. Sobald die Writer-DB-Instance der neuen primären Region verfügbar ist, können Sie Ihre Anwendungen damit verbinden und Ihre Workloads wieder aufnehmen. Nachdem Aurora den neuen primären Cluster hochgestuft hat, werden automatisch alle zusätzlichen Cluster der sekundären Region neu erstellt.
Da die globalen Aurora-Datenbanken die asynchrone Replikation verwenden, kann die Replikationsverzögerung in jeder sekundären Region variieren. Aurora baut diese sekundären Regionen neu auf, sodass sie genau dieselben point-in-time Daten wie der neue Cluster der primären Region haben. Die Dauer der vollständigen Neuerstellungsaufgabe kann je nach Größe des Speichervolumens und der Entfernung zwischen den Regionen einige Minuten bis mehrere Stunden dauern. Wenn der Wiederaufbau der Cluster der sekundären Region aus der neuen primären Region abgeschlossen ist, stehen sie für den Lesezugriff zur Verfügung.
Sobald der neue primäre Writer hochgestuft und verfügbar ist, kann der Cluster der neuen primären Region Lese- und Schreibvorgänge für die globale Aurora-Datenbank abwickeln.
Wenn Sie den globalen Endpunkt verwenden, müssen Sie die Verbindungseinstellungen in Ihrer Anwendung nicht ändern. Stellen Sie sicher, dass die DNS-Änderungen übernommen wurden und dass Sie eine Verbindung herstellen und Schreibvorgänge auf dem neuen primären Cluster ausführen können. Anschließend können Sie den vollen Betrieb Ihrer Anwendung wieder aufnehmen.
Wenn Sie den globalen Endpunkt nicht verwenden, stellen Sie sicher, dass Sie den Endpunkt für Ihre Anwendung so ändern, dass er den Cluster-Endpunkt für den neu hochgestuften primären DB-Cluster verwendet. Wenn Sie die angegebenen Namen beim Erstellen der globalen Aurora-Datenbank akzeptiert haben, können Sie den Endpunkt ändern, indem Sie -ro aus der Endpunkt-Zeichenfolge des hochgestuften Clusters in Ihrer Anwendung entfernen.
Beispielsweise wird der Endpunkt des sekundären Clusters my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com zu my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com, wenn dieser Cluster zum primären Cluster hochgestuft wird.
Wenn Sie den RDS-Proxy verwenden, stellen Sie sicher, dass die Schreibvorgänge Ihrer Anwendung an den entsprechenden read/write endpoint of the proxy that's associated with the new primary cluster. This proxy endpoint might be the default endpoint or a custom read/write Endpunkt umgeleitet werden. Weitere Informationen finden Sie unter So funktionieren RDS-Proxy-Endpunkte mit globalen Datenbanken.
Um die ursprüngliche Topologie des globalen Datenbank-Clusters wiederherzustellen, überwacht Aurora die Verfügbarkeit der alten primären Region. Sobald diese Region fehlerfrei und wieder verfügbar ist, fügt Aurora sie automatisch wieder als sekundäre Region zum globalen Cluster hinzu. Bevor das neue Speichervolume in der alten Primärregion erstellt wird, versucht Aurora, zum Zeitpunkt des Fehlers einen Snapshot des alten Speichervolumes zu erstellen. Auf diese Weise können Sie alle fehlenden Daten wiederherstellen. Wenn dieser Vorgang erfolgreich ist, erstellt Aurora einen Snapshot mit dem Namenrds:unplanned-global-failover-. Sie finden diesen Snapshot im Abschnitt Schnappschüsse der AWS Management Console. Sie können diesen Snapshot auch in den Informationen sehen, die vom API-Vorgang Describe DBCluster Snapshots zurückgegeben werden. name-of-old-primary-DB-cluster-timestamp
Anmerkung
Der Snapshot des alten Speichervolumes ist ein System-Snapshot, der der auf dem alten primären Cluster konfigurierten Aufbewahrungsfrist für Backups unterliegt. Um diesen Snapshot außerhalb des Aufbewahrungszeitraums zu speichern, können Sie ihn kopieren, um ihn als manuellen Snapshot zu speichern. Weitere Informationen zum Kopieren von Snapshots, einschließlich der Preise, finden Sie unter Kopieren von DB-Cluster-Snapshots.
Nachdem die ursprüngliche Topologie wiederhergestellt ist, können Sie ein Failback Ihrer globalen Datenbank auf die ursprüngliche primäre Region durchführen, indem Sie eine Umstellung durchführen, wenn dies für Ihr Unternehmen und Ihren Workload am sinnvollsten ist. Eine Schritt-für-Schritt-Anleitung hierzu finden Sie unter Durchführen von Umstellungen für Amazon Aurora Global Databases.
Sie können ein Failover mit Aurora Global Database mithilfe der AWS Management Console, der oder der AWS CLI RDS-API durchführen.
So starten Sie den verwalteten Failover-Prozess in Ihrer globalen Aurora-Datenbank
Melden Sie sich bei der an AWS Management Console und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. -
Wählen Sie Datenbanken und suchen Sie die globale Aurora-Datenbank, in der Sie den Failover durchführen möchten.
-
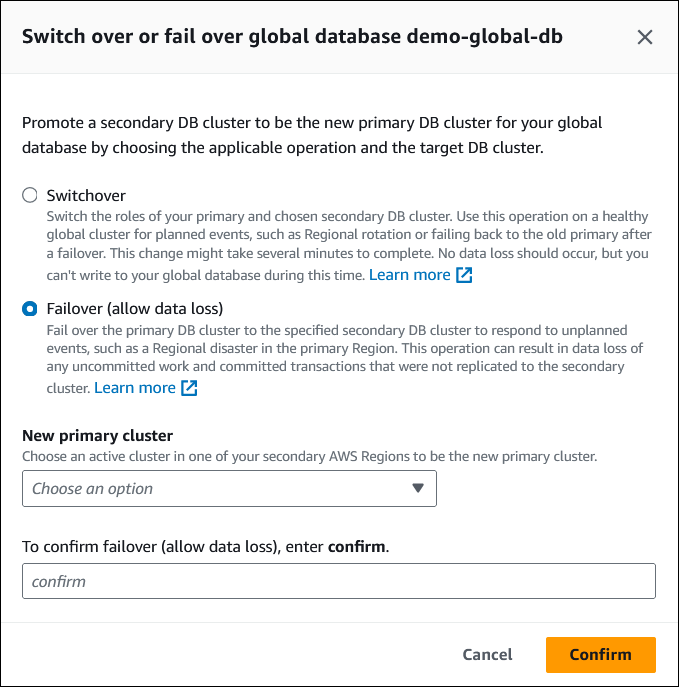
Wählen Sie im Menü Aktionen die Option Failover für globale Datenbank ausführen aus.
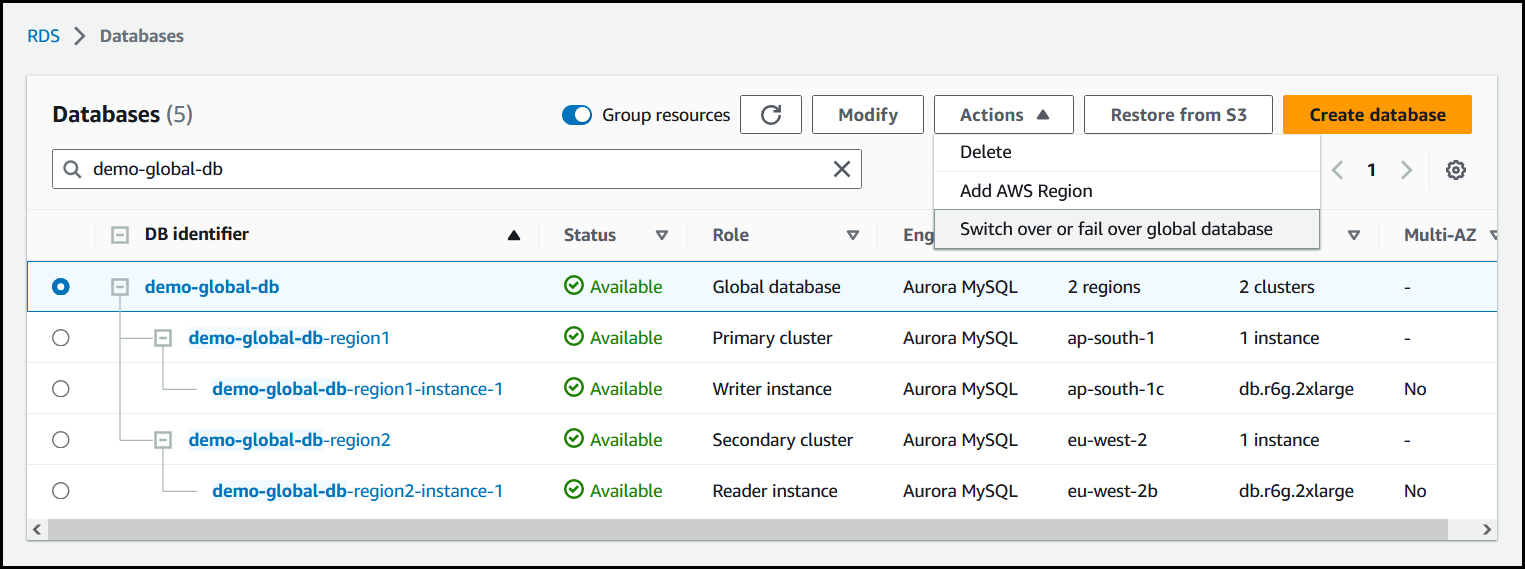
-
Wählen Sie Failover (Datenverlust zulassen).
-
Für Neuer primärer Cluster wählen Sie einen aktiven Cluster in einer Ihrer sekundären AWS-Regionen als neuen primären Cluster aus.
-
Geben Sie
confirmein, und wählen Sie dann Bestätigen.
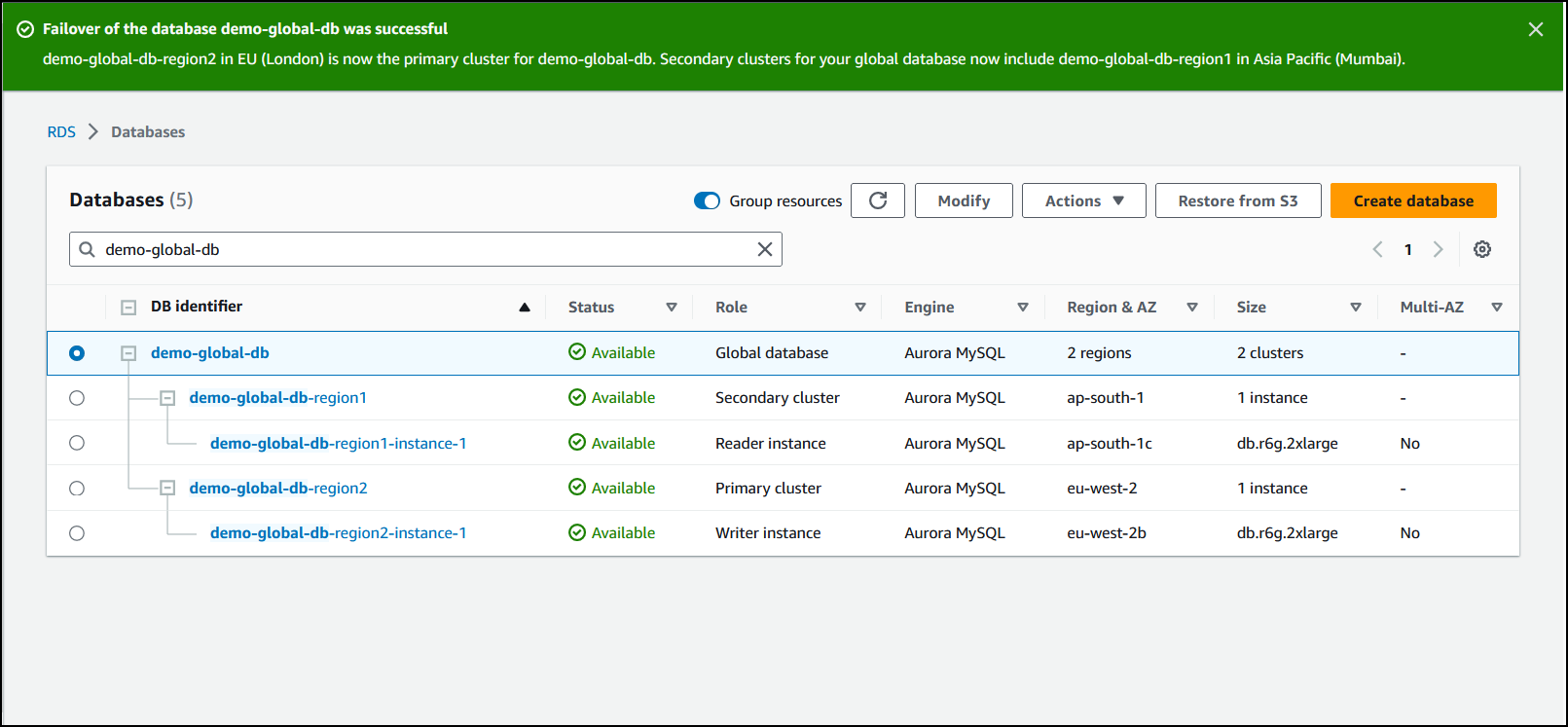
Wenn der Failover abgeschlossen ist, können Sie die Aurora-DB-Cluster und ihren aktuellen Status in der Datenbankliste anzeigen, wie in der folgenden Abbildung dargestellt.
So führen Sie das verwaltete Failover für eine globale Aurora-Datenbank durch
Verwenden Sie den failover-global-cluster CLI-Befehl, um ein Failover mit Aurora Global Database durchzuführen. Mit dem Befehl können Sie Werte für die folgenden Parameter übertragen.
-
--region— Geben Sie an AWS-Region , wo der sekundäre DB-Cluster, den Sie als neuen primären DB-Cluster für die globale Aurora-Datenbank verwenden möchten, ausgeführt wird. -
--global-cluster-identifier– Geben Sie den Namen Ihrer globalen Aurora-Datenbank an. -
--target-db-cluster-identifier– Geben Sie den Amazon-Ressourcennamen (ARN) des Aurora-DB-Clusters an, den Sie als neuen primären Cluster für die globale Aurora-Datenbank hochstufen möchten. -
--allow-data-loss– Machen Sie dies ausdrücklich zu einer Failover- und nicht zu einer Umstellungs-Operation. Ein Failover-Vorgang kann zu Datenverlusten führen, wenn die asynchronen Replikationskomponenten das Senden aller replizierten Daten an die sekundäre Region nicht abgeschlossen haben.
Für LinuxmacOS, oderUnix:
aws rds --regionregion_of_selected_secondary\ failover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote\ --allow-data-loss
Windows:
aws rds --regionregion_of_selected_secondary^ failover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote^ --allow-data-loss
Um ein Failover mit Aurora Global Database durchzuführen, führen Sie den FailoverGlobalClusterAPI-Vorgang aus.
Ausführen von manuellen geplanten Failovers für globale Aurora-Datenbanken
In einigen Szenarien können Sie den verwalteten Failover-Prozess möglicherweise nicht verwenden. Ein Beispiel ist etwa, wenn auf Ihrem primären und sekundären DB-Cluster keine kompatiblen Engine-Versionen ausgeführt werden. In diesem Fall können Sie diesem manuellen Prozess folgen, um ein Failover in Ihre sekundäre Zielregion durchzuführen.
Tipp
Bevor Sie diesen Prozess verwenden, sollten Sie sich damit vertraut machen. Halten Sie einen Plan bereit, um bei den ersten Anzeichen eines regionsweiten Problems schnell handeln zu können. Sie können bereit sein, die sekundäre Region mit der geringsten Replikationsverzögerung zu identifizieren, indem Sie Amazon CloudWatch regelmäßig verwenden, um die Verzögerungszeiten für die sekundären Cluster zu verfolgen. Testen Sie Ihren Plan, um zu überprüfen, ob Ihre Verfahren vollständig und genau sind, und stellen Sie sicher, dass die Mitarbeiter darin geschult sind, ein Failover für die Notfallwiederherstellung durchzuführen, bevor es wirklich erforderlich ist.
Um nach einem ungeplanten Ausfall in der primären Region ein manuelles Failover auf einen sekundären Cluster durchzuführen
-
Beenden Sie die Ausgabe von DML-Anweisungen und anderen Schreibvorgängen auf dem primären Aurora-DB-Cluster in der AWS-Region mit dem Ausfall.
-
Identifizieren Sie einen Aurora-DB-Cluster von einem sekundären AWS-Region , der als neuer primärer DB-Cluster verwendet werden soll. Wenn Sie zwei oder mehr sekundäre Cluster AWS-Regionen in Ihrer globalen Aurora-Datenbank haben, wählen Sie den sekundären Cluster mit der geringsten Replikationsverzögerung.
-
Trennen Sie Ihren ausgewählten sekundären DB-Cluster von der globalen Aurora-Datenbank.
Das Entfernen eines sekundären DB-Clusters aus einer globalen Aurora-Datenbank stoppt sofort die Replikation vom primären zu diesem sekundären Cluster und stuft ihn als ein eigenständiges bereitgestelltes Aurora-DB-Cluster mit uneingeschränkter Lese-/Schreibfunktion ein. Alle anderen sekundären Aurora-DB-Cluster, die mit dem primären Cluster in der Region mit dem Ausfall verknüpft sind, sind weiterhin verfügbar und können Aufrufe von Ihrer Anwendung annehmen. Sie verbrauchen auch Ressourcen. Da Sie die globale Aurora-Datenbank neu erstellen, entfernen Sie die anderen sekundären DB-Cluster, bevor Sie die neue globale Aurora-Datenbank in den folgenden Schritten erstellen. Dadurch werden Dateninkonsistenzen zwischen den DB-Clustern in der globalen Aurora-Datenbank vermieden (split-brain-Probleme).
Ausführliche Schritte zum Trennen finden Sie unter Entfernen eines Clusters aus einer Amazon Aurora Global Database.
-
Konfigurieren Sie Ihre Anwendung neu, um alle Schreibvorgänge mit ihrem neuen Endpunkt an diesen eigenständigen Aurora-DB-Cluster zu senden. Wenn Sie die angegebenen Namen beim Erstellen der globalen Aurora-Datenbank akzeptiert haben, können Sie den Endpunkt ändern, indem Sie
-roaus der Endpunkt-Zeichenfolge des Clusters in Ihrer Anwendung entfernen.Beispielsweise wird der Endpunkt
my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.comdes sekundären Clusters zumy-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com, wenn dieser Cluster von der globalen Aurora-Datenbank getrennt wird.Dieser Aurora-DB-Cluster wird zum primären Cluster einer neuen globalen Aurora-Datenbank, wenn Sie im nächsten Schritt beginnen Regionen hinzuzufügen.
Wenn Sie den RDS-Proxy verwenden, stellen Sie sicher, dass die Schreibvorgänge Ihrer Anwendung an den entsprechenden read/write endpoint of the proxy that's associated with the new primary cluster. This proxy endpoint might be the default endpoint or a custom read/write Endpunkt umgeleitet werden. Weitere Informationen finden Sie unter So funktionieren RDS-Proxy-Endpunkte mit globalen Datenbanken.
-
Fügen Sie AWS-Region dem DB-Cluster eine hinzu. Wenn Sie dies tun, beginnt der Replikationsprozess vom primären zum sekundären Cluster. Ausführliche Schritte zum Hinzufügen einer Region finden Sie unter Hinzufügen einer AWS-Region zu einer globalen Amazon Aurora Aurora-Datenbank.
-
Fügen Sie nach AWS-Regionen Bedarf weitere hinzu, um die Topologie wiederherzustellen, die zur Unterstützung Ihrer Anwendung erforderlich ist.
Stellen Sie sicher, dass Schreibvorgänge der Anwendung vor, während und nach diesen Änderungen an den richtigen Aurora-DB-Cluster gesendet werden. Dadurch werden Dateninkonsistenzen zwischen den DB-Clustern in der globalen Aurora-Datenbank vermieden (split-brain-Probleme).
Wenn Sie als Reaktion auf einen Ausfall in einem neu konfiguriert haben AWS-Region, können Sie diesen nach Behebung AWS-Region des Ausfalls wieder zum primären Server machen. Dazu fügen Sie die alte Datenbank AWS-Region zu Ihrer neuen globalen Datenbank hinzu und wechseln dann mithilfe des Switchover-Prozesses ihre Rolle. Ihre Aurora Global Database muss eine Version von Aurora PostgreSQL oder Aurora MySQL verwenden, die Umstellungen unterstützt. Weitere Informationen finden Sie unter Durchführen von Umstellungen für Amazon Aurora Global Databases.
Verwaltung RPOs für globale Aurora-PostgreSQL-Datenbanken
Mit einer Aurora PostgreSQL–basierten globalen Datenbank können Sie den Recovery Point Objective (RPO)-Wert für Ihre globale Aurora-Datenbank mithilfe des Parameters rds.global_db_rpo verwalten. RPO gibt die maximale Datenmenge an, die im Falle eines Ausfalls verloren gehen kann.
Wenn Sie eine RPO für Ihre Aurora PostgreSQL–basierte globale Datenbank festlegen, überwacht Aurora die RPO-Verzögerungszeit aller sekundären Cluster, um sicherzustellen, dass mindestens ein sekundärer Cluster innerhalb des angestrebten RPO-Bereichs liegt. Die RPO-Verzögerungszeit ist eine weitere zeitbasierte Metrik.
Das RPO wird verwendet, wenn Ihre Datenbank nach einem Failover den Betrieb in einem neuen AWS-Region System wieder aufnimmt. Aurora bewertet RPO- und RPO-Verzögerungszeiten, um Transaktionen auf dem primären Netzwerk wie folgt zu übertragen (oder zu blockieren):
-
Die Transaktion wird durchgeführt, wenn mindestens ein sekundärer DB-Cluster eine RPO-Verzögerungszeit hat, die kleiner ist als die RPO.
-
Die Transaktion wird blockiert, wenn alle sekundären DB-Cluster RPO-Verzögerungszeiten haben, die größer sind als die RPO. Außerdem wird das Ereignis in der PostgreSQL-Protokolldatei erfasst und es werden Warteereignisse ausgegeben, die die blockierten Sessions anzeigen.
Wenn sich also alle sekundären Cluster hinter der Ziel-RPO befinden, pausiert Aurora die Transaktionen im primären Cluster, bis mindestens einer der sekundären Cluster den Rückstand aufholt. Pausierte Transaktionen werden fortgesetzt und übergeben, sobald die Verzögerungszeit mindestens eines sekundären DB-Clusters geringer ist als die RPO. Das Ergebnis ist, dass keine Transaktionen übertragen werden können, bis die RPO erreicht ist.
Der rds.global_db_rpo-Parameter ist dynamisch. Wenn Sie nicht möchten, dass alle Schreibtransaktionen angehalten werden, bis die Verzögerung ausreichend abnimmt, können Sie ihn schnell zurücksetzen. In diesem Fall erkennt Aurora die Änderung und implementiert sie nach einer kurzen Verzögerung.
Wichtig
In einer globalen Datenbank mit nur zwei AWS Regionen empfehlen wir, den Standardwert des rds.global_db_rpo Parameters in der Parametergruppe der sekundären Region beizubehalten. Andernfalls könnte die Durchführung eines Failovers aufgrund eines Verlusts der primären AWS Region dazu führen, dass Aurora Transaktionen unterbricht. Warten Sie stattdessen, bis Aurora die Neuerstellung des Clusters in der alten ausgefallenen AWS Region abgeschlossen hat, bevor Sie diesen Parameter ändern, um ein maximales RPO zu erzwingen.
Wenn Sie diesen Parameter wie im Folgenden beschrieben festlegen, können Sie auch die von ihm generierten Metriken überwachen. Sie können dies tun, indem Sie psql oder ein anderes Tool verwenden, um den primären DB-Cluster der globalen Aurora-Datenbank abzufragen und detaillierte Informationen über den Betrieb Ihrer Aurora PostgreSQL–basierten globalen Datenbank zu erhalten. Um zu erfahren wie, siehe Überwachung globaler Datenbanken SQL auf Basis von Aurora Postgre.
Themen
Festlegen des Recovery Point Objective
Der Parameter rds.global_db_rpo steuert die RPO-Einstellung für eine PostgreSQL-Datenbank. Dieser Parameter wird von Aurora PostgreSQL unterstützt. Gültige Werte für rds.global_db_rpo liegen zwischen 20 und 2.147.483.647 Sekunden (68 Jahre). Wählen Sie einen realistischen Wert, der Ihren Geschäftsanforderungen und Ihrem Anwendungsfall entspricht. Wenn Sie beispielsweise bis zu 10 Minuten für Ihre RPO festlegen möchten, dann setzen Sie den Wert auf 600.
Sie können diesen Wert für Ihre Aurora-PostgreSQL-basierte globale Datenbank festlegen, indem Sie die AWS Management Console, die AWS CLI oder die RDS-API verwenden.
So legen Sie den RPO fest:
Melden Sie sich bei der an AWS Management Console und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. -
Wählen Sie den primären Cluster Ihrer globalen Aurora-Datenbank und öffnen Sie die Registerkarte Konfiguration, um die DB-Cluster-Parametergruppe zu suchen. Die Standardparametergruppe für ein primäres DB-Cluster mit Aurora PostgreSQL 11.7 ist beispielsweise
default.aurora-postgresql11.Parametergruppen können nicht direkt bearbeitet werden. Stattdessen führen Sie die folgenden Schritte aus:
-
Erstellen Sie eine benutzerdefinierte DB-Cluster-Parametergruppe, wobei Sie die entsprechende Standardparametergruppe als Ausgangspunkt verwenden. So erstellen Sie beispielsweise eine benutzerdefinierte DB-Cluster-Parametergruppe basierend au
default.aurora-postgresql11. -
Legen Sie in Ihrer benutzerdefinierten DB-Parametergruppe den Wert des Parameters rds.global_db_rpo fest, der Ihrem Anwendungsfall entspricht. Gültige Werte liegen zwischen 20 Sekunden und dem maximalen ganzzahligen Wert von 2.147.483.647 (68 Jahre).
-
Wenden Sie die geänderte DB-Cluster-Parametergruppe auf Ihr Aurora-DB-Cluster an.
-
Weitere Informationen finden Sie unter Ändern von Parametern in einer DB-Cluster-Parametergruppe in Amazon Aurora.
Verwenden Sie den CLI-Befehl modify-db-cluster-parameter-group, um den rds.global_db_rpo Parameter festzulegen. Geben Sie im Befehl den Namen der Parametergruppe Ihres primären Clusters und die Werte für den RPO-Parameter an.
Im folgenden Beispiel wird die RPO für die primäre DB-Cluster-Parametergruppe namens auf 600 Sekunden (10 Minuten) festgeleg my_custom_global_parameter_group.
Für LinuxmacOS, oderUnix:
aws rds modify-db-cluster-parameter-group \ --db-cluster-parameter-group-namemy_custom_global_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
Windows:
aws rds modify-db-cluster-parameter-group ^ --db-cluster-parameter-group-namemy_custom_global_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
Um den rds.global_db_rpo Parameter zu ändern, verwenden Sie den Amazon RDS Modify DBCluster ParameterGroup API-Vorgang.
Anzeigen des Recovery Point Objective (Zeitraums zwischen zwei Datensicherungen)
Die Recovery Point Objective (RPO) einer globalen Datenbank wird im rds.global_db_rpo-Parameter für jeden DB-Cluster gespeichert. Sie können eine Verbindung zum Endpunkt für den sekundären Cluster herstellen, den Sie anzeigen möchten, und mit psql die Instance nach diesem Wert abfragen.
show rds.global_db_rpo;db-name=>
Wenn dieser Parameter nicht festgelegt ist, gibt die Abfrage Folgendes zurück:
rds.global_db_rpo
-------------------
-1
(1 row)Diese nächste Antwort stammt von einem sekundären DB-Cluster mit einer RPO-Einstellung von einer Minute.
rds.global_db_rpo
-------------------
60
(1 row) Sie können auch die CLI verwenden, um herauszufinden, ob in einem der Aurora-DB-Cluster rds.global_db_rpo aktiviert ist, indem Sie die CLI verwenden, um die Werte aller user-Parameter für den Cluster zu erhalten.
Für LinuxmacOS, oderUnix:
aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-namelab-test-apg-global\ --source user
Windows:
aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-namelab-test-apg-global* --source user
Der Befehl gibt für alle user-Parameter, die keine default-engine- oder system-DB-Cluster-Parameter sind, eine Ausgabe zurück, die der folgenden Ausgabe ähnelt.
{
"Parameters": [
{
"ParameterName": "rds.global_db_rpo",
"ParameterValue": "60",
"Description": "(s) Recovery point objective threshold, in seconds, that blocks user commits when it is violated.",
"Source": "user",
"ApplyType": "dynamic",
"DataType": "integer",
"AllowedValues": "20-2147483647",
"IsModifiable": true,
"ApplyMethod": "immediate",
"SupportedEngineModes": [
"provisioned"
]
}
]
}
Weitere Informationen zum Anzeigen von Parametern der Clusterparametergruppe finden Sie unter Parameterwerte für eine DB-Cluster-Parametergruppe in Amazon Aurora anzeigen.
Deaktivieren des Recovery Point Objective
Um den RPO zu deaktivieren, setzen Sie den rds.global_db_rpo-Parameter zurück. Sie können Parameter über die AWS Management Console, die AWS CLI oder die RDS-API zurücksetzen.
So deaktivieren Sie den RPO:
Melden Sie sich bei der an AWS Management Console und öffnen Sie die Amazon RDS-Konsole unter https://console.aws.amazon.com/rds/
. -
Wählen Sie im Navigationsbereich Parameter groups (Parametergruppen) aus.
-
Wählen Sie in der Liste Ihre primäre DB-Cluster-Parametergruppe aus.
-
Wählen Sie Parameter bearbeiten aus.
-
Wählen Sie das Feld neben dem Parameter rds.global_db_rpo aus.
-
Klicken Sie auf Reset (Zurücksetzen).
-
Wenn auf dem Bildschirm Reset parameters in DB parameter group (Parameter in DB-Parametergruppe zurücksetzen) angezeigt wird, wählen Sie Reset parameters (Parameter zurücksetzen) aus.
Weitere Informationen zum Zurücksetzen eines Parameters mit der Konsole finden Sie unter Ändern von Parametern in einer DB-Cluster-Parametergruppe in Amazon Aurora.
Verwenden Sie den Befehl reset-db-cluster-parameter-group, um den rds.global_db_rpo Parameter zurückzusetzen.
Für LinuxmacOS, oderUnix:
aws rds reset-db-cluster-parameter-group \ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
Windows:
aws rds reset-db-cluster-parameter-group ^ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
Verwenden Sie den Amazon DBClusterParameterGroupRDS-API-Reset-Vorgang, um den rds.global_db_rpo Parameter zurückzusetzen.
