Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Performance und Skalierung für Aurora Serverless v2
Die folgenden Verfahren und Beispiele zeigen, wie Sie den Kapazitätsbereich für Aurora Serverless v2-Cluster und ihre zugehörigen DB-Instances festlegen können. Sie können die folgenden Verfahren auch verwenden, um zu überwachen, wie ausgelastet Ihre DB-Instances sind. Anschließend können Sie anhand Ihrer Ergebnisse feststellen, ob Sie den Kapazitätsbereich nach oben oder unten anpassen müssen.
Stellen Sie sicher, dass Sie mit der Funktionsweise der Skalierung in Aurora Serverless v2 vertraut sind. Der Skalierungsmechanismus ist anders als in Aurora Serverless v1. Details hierzu finden Sie unter Aurora Serverless v2-Skalierung.
Inhalt
Auswählen des Aurora Serverless v2-Kapazitätsbereichs für einen Aurora-Cluster
Auswählen der minimalen Aurora Serverless v2-Kapazitätseinstellung für einen Cluster
Auswählen der maximalen Aurora Serverless v2-Kapazitätseinstellung für einen Cluster
Beispiel: Ändern des Aurora Serverless v2-Kapazitätsbereichs eines Aurora-MySQL-Clusters
Beispiel: Ändern des Aurora Serverless v2-Kapazitätsbereichs eines Aurora-PostgreSQL-Clusters
Wichtige CloudWatch Amazon-Metriken für Aurora Serverless v2
Überwachung der Aurora Serverless v2-Leistung mit Performance Insights
Auswählen des Aurora Serverless v2-Kapazitätsbereichs für einen Aurora-Cluster
Bei Aurora Serverless v2-DB-Instances legen Sie den Kapazitätsbereich, der für alle DB-Instances in Ihrem DB-Cluster gilt, beim Hinzufügen der ersten Aurora Serverless v2-DB-Instance zum DB-Cluster fest. Weitere Informationen zum entsprechenden Verfahren finden Sie unter Festlegen des Aurora Serverless v2-Kapazitätsbereichs für einen Cluster.
Sie können den Kapazitätsbereich für einen vorhandenen Cluster auch ändern. In den folgenden Abschnitten wird ausführlicher beschrieben, wie Sie geeignete Mindest- und Höchstwerte auswählen und was passiert, wenn Sie den Kapazitätsbereich ändern. Durch Ändern des Kapazitätsbereichs können sich beispielsweise die Standardwerte einiger Konfigurationsparameter ändern. Das Anwenden aller Parameteränderungen kann einen Neustart jeder Aurora Serverless v2-DB-Instance erfordern.
Themen
Auswählen der minimalen Aurora Serverless v2-Kapazitätseinstellung für einen Cluster
Auswählen der maximalen Aurora Serverless v2-Kapazitätseinstellung für einen Cluster
Beispiel: Ändern des Aurora Serverless v2-Kapazitätsbereichs eines Aurora-MySQL-Clusters
Beispiel: Ändern des Aurora Serverless v2-Kapazitätsbereichs eines Aurora-PostgreSQL-Clusters
Auswählen der minimalen Aurora Serverless v2-Kapazitätseinstellung für einen Cluster
Es ist verlockend, immer 0,5 für die miminale Aurora Serverless v2-Kapazitätseinstellung auszuwählen. Dieser Wert ermöglicht es der DB-Instance, auf die kleinste Kapazität herunterzuskalieren, wenn sie vollständig inaktiv ist, während sie aktiv bleibt. Sie können das automatische Pausenverhalten auch aktivieren, indem Sie eine Mindestkapazität von 0 angeben ACUs, wie unter erklärtSkalierung auf Null ACUs mit automatischer Pause und Wiederaufnahme für Aurora Serverless v2. Je nachdem, wie Sie diesen Cluster verwenden und welche anderen Einstellungen Sie konfigurieren, kann eine andere Mindestkapazität jedoch am effektivsten sein. Berücksichtigen Sie bei der Auswahl der Mindestkapazitätseinstellung die folgenden Faktoren:
-
Die Skalierungsrate für eine Aurora Serverless v2-DB-Instance hängt von ihrer aktuellen Kapazität ab. Je höher die aktuelle Kapazität, desto schneller kann sie hochskalieren. Wenn die DB-Instance schnell auf eine sehr hohe Kapazität hochskalieren muss, sollten Sie die Mindestkapazität auf einen Wert einstellen, bei dem die Skalierungsrate Ihren Anforderungen entspricht.
-
Wenn Sie die DB-Instance-Klasse Ihrer DB-Instances in Erwartung einer besonders hohen oder niedrigen Workload in der Regel ändern, können Sie diese Erfahrung verwenden, um den entsprechenden Aurora Serverless v2-Kapazitätsbereich grob einzuschätzen. Informationen zum Ermitteln der Speichergröße, die in Zeiten mit geringem Datenverkehr verwendet werden soll, finden Sie unter Hardware-Spezifikationen für DB-Instance-Klassen für Aurora.
Angenommen, Sie verwenden die DB-Instance-Klasse db.r6g.xlarge, wenn Ihr Cluster eine geringe Workload hat. Diese DB-Instance-Klasse verfügt über 32 GiB Speicher. Somit können Sie eine minimale Einstellung der Aurora-Kapazitätseinheit (ACU) von 16 angeben, um eine Aurora Serverless v2-DB-Instance einzurichten, die auf ungefähr dieselbe Kapazität herunterskalieren kann. Das liegt daran, dass jede ACU ungefähr 2 GiB Speicher entspricht. Sie können einen etwas niedrigeren Wert angeben, damit die DB-Instance weiter herunterskaliert wird, falls Ihre db.r6g.xlarge-DB-Instance manchmal nicht ausgelastet war.
-
Wenn Ihre Anwendung dann am effizientesten arbeitet, wenn die DB-Instances eine bestimmte Datenmenge im Puffer-Cache haben, sollten Sie eine minimale ACU-Einstellung angeben, bei der der Speicher groß genug ist, um die häufig aufgerufenen Daten zu speichern. Andernfalls werden einige Daten im Puffer-Cache bereinigt, wenn Aurora Serverless v2-DB-Instances auf eine niedrigere Speichergröße herunterskalieren. Wenn die DB-Instances dann wieder hochskaliert werden, werden die Informationen im Zeitverlauf wieder in den Puffer-Cache eingelesen. Wenn die Menge, mit der I/O die Daten wieder in den Puffercache zurückgebracht werden sollen, erheblich ist, ist es möglicherweise effektiver, einen höheren ACU-Mindestwert zu wählen.
-
Wenn Ihre Aurora Serverless v2-DB-Instances die meiste Zeit mit einer bestimmten Kapazität ausgeführt werden, erwägen Sie, eine Mindestkapazitätseinstellung anzugeben, die zwar niedriger als diese Baseline, aber nicht zu niedrig ist. Aurora Serverless v2 DB-Instances können am effektivsten abschätzen, wie viel und wie schnell hochskaliert werden muss, wenn die aktuelle Kapazität nicht deutlich niedriger als die erforderliche Kapazität ist.
-
Wenn Ihre bereitgestellte Workload Speicheranforderungen hat, die für kleine DB-Instance-Klassen wie T3 oder T4g zu hoch sind, wählen Sie eine minimale ACU-Einstellung, die ähnlichen Speicher bietet wie eine R5- oder R6g-DB-Instance.
Insbesondere empfehlen wir die folgende Mindestkapazität für die Verwendung mit den angegebenen Funktionen (diese Empfehlungen können sich ändern):
-
Performance Insights — 2 ACUs
-
Globale Aurora-Datenbanken — 8 ACUs (gilt nur für die Primärdatenbank AWS-Region)
-
-
In Aurora erfolgt die Replikation auf der Speicherebene, sodass sich die Lesekapazität nicht direkt auf die Replikation auswirkt. Stellen Sie bei Aurora Serverless v2 Leser-DB-Instances, die unabhängig skalieren, jedoch sicher, dass die Mindestkapazität ausreicht, um Workloads in schreibintensiven Zeiten zu bewältigen, um Abfragelatenz zu vermeiden. Wenn bei Leser-DB-Instances der Promotion-Stufen 2—15 Leistungsprobleme auftreten, sollten Sie eine Erhöhung der Mindestkapazität des Clusters in Betracht ziehen. Weitere Informationen zur Entscheidung, ob Reader-DB-Instances zusammen mit dem Writer oder unabhängig skaliert werden, finden Sie unter Auswählen der Hochstufungsstufe für einen Aurora Serverless v2-Reader.
-
Wenn Sie über einen DB-Cluster mit Aurora Serverless v2 Leser-DB-Instances verfügen, skalieren die Lesegeräte nicht zusammen mit der Writer-DB-Instance, wenn die Heraufstufungsstufe der Lesegeräte nicht 0 oder 1 ist. In diesem Fall kann das Festlegen einer geringen Mindestkapazität zu einer übermäßigen Replikationsverzögerung führen. Das liegt daran, dass die Reader möglicherweise nicht genug Kapazität haben, um Änderungen vom Writer zu übernehmen, wenn die Datenbank ausgelastet ist. Wir empfehlen, dass Sie die Mindestkapazität auf einen Wert festlegen, der einer vergleichbaren Speicher- und CPU-Menge entspricht wie bei der Writer-DB-Instance.
-
Der Wert des
max_connectionsParameters für Aurora Serverless v2 DB-Instances basiert auf der Speichergröße, die vom Maximum abgeleitet wird ACUs. Wenn Sie jedoch eine Mindestkapazität von 0 oder 0,5 für PostgreSQL-kompatible DB-Instances angeben,max_connectionsist der Höchstwert von ACUs auf 2.000 begrenzt.Wenn Sie beabsichtigen, den Aurora-PostgreSQL-Cluster für einen Workload mit hohem Verbindungsdurchsatz zu verwenden, sollten Sie eine Mindest-ACU-Einstellung von 1 oder höher verwenden. Details darüber, wie Aurora Serverless v2 den
max_connections-Konfigurationsparameter behandelt, finden Sie unter Maximale Anzahl der Verbindungen für Aurora Serverless v2. -
Die Zeit, die eine Aurora Serverless v2-DB-Instance benötigt, um von ihrer minimalen Kapazität auf ihre maximale Kapazität zu skalieren, hängt von der Differenz zwischen ihren minimalen und maximalen ACU-Werten ab. Wenn die aktuelle Kapazität der DB-Instance groß ist, skaliert Aurora Serverless v2 in größeren Schritten, als wenn die DB-Instance mit einer geringen Kapazität beginnt. Wenn Sie also eine relativ große maximale Kapazität angeben und die DB-Instance die meiste Zeit in diesem Kapazitätsbereich bleibt, sollten Sie erwägen, die minimale ACU-Einstellung zu erhöhen. Auf diese Weise kann eine inaktive DB-Instance schneller wieder auf maximale Kapazität skaliert werden.
Auswählen der maximalen Aurora Serverless v2-Kapazitätseinstellung für einen Cluster
Es ist verlockend, immer einen hohen Wert für die maximale Aurora Serverless v2-Kapazitätseinstellung auszuwählen. Eine große maximale Kapazität ermöglicht es der DB-Instance, bei intensiver Workload am stärksten hochzuskalieren. Mit einem niedrigen Wert entfällt die Möglichkeit unerwarteter Gebühren. Je nachdem, wie Sie diesen Cluster verwenden und die anderen Einstellungen konfigurieren, kann der effektivste Wert höher oder niedriger sein, als Sie ursprünglich dachten. Berücksichtigen Sie bei der Auswahl der maximalen Kapazitätseinstellung die folgenden Faktoren:
-
Die maximale Kapazität muss mindestens so hoch sein wie die Mindestkapazität. Sie können die minimale und maximale Kapazität auf den gleichen Wert festlegen. In diesem Fall skaliert sich die Kapazität jedoch niemals hoch oder herunter. Daher ist die Verwendung identischer Werte für die minimale und maximale Kapazität außerhalb von Testsituationen nicht geeignet.
-
Die maximale Kapazität muss höher als 0,5 sein. ACUs Sie können die minimale und maximale Kapazität in den meisten Fällen auf den gleichen Wert festlegen. Sie können 0,5 jedoch nicht sowohl für das Minimum als auch für das Maximum angeben. Verwenden Sie einen Wert von 1 oder höher für die maximale Kapazität.
-
Wenn Sie die DB-Instance-Klasse Ihrer DB-Instances in Erwartung einer besonders hohen oder niedrigen Workload in der Regel ändern, können Sie diese Erfahrung verwenden, um den entsprechenden Aurora Serverless v2-Kapazitätsbereich einzuschätzen. Informationen zum Ermitteln der Speichergröße, die in Zeiten mit hohem Datenverkehr verwendet werden soll, finden Sie unter Hardware-Spezifikationen für DB-Instance-Klassen für Aurora.
Angenommen, Sie verwenden die DB-Instance-Klasse db.r6g.4xlarge, wenn Ihr Cluster eine hohe Workload hat. Diese DB-Instance-Klasse verfügt über 128 GiB Speicher. Somit können Sie eine maximale ACU-Einstellung von 64 angeben, um eine Aurora Serverless v2-DB-Instance einzurichten, die auf ungefähr dieselbe Kapazität hochskalieren kann. Das liegt daran, dass jede ACU ungefähr 2 GiB Speicher entspricht. Sie können einen etwas höheren Wert angeben, damit die DB-Instance weiter hochskalieren kann, falls Ihre db.r6g.4xlarge-DB-Instance manchmal nicht genug Kapazität hat, um die Workload effektiv zu bewältigen.
-
Wenn Sie eine Haushaltsobergrenze für Ihre Datenbankauslastung haben, wählen Sie einen Wert, der innerhalb dieser Obergrenze bleibt, auch wenn alle Ihre Aurora Serverless v2-DB-Instances ständig mit maximaler Kapazität laufen. Denken Sie daran, dass wenn Sie n Aurora Serverless v2-DB-Instances in Ihrem Cluster haben, die theoretische maximale Aurora Serverless v2-Kapazität, die der Cluster jederzeit verbrauchen kann, n-mal die maximale ACU-Einstellung für den Cluster ist. (Der tatsächlich verbrauchte Betrag ist möglicherweise geringer, wenn beispielsweise einige Reader unabhängig vom Writer skalieren.)
-
Wenn Sie Aurora Serverless v2-Reader-DB-Instances dazu verwenden, den schreibgeschützten Workload der Writer-DB-Instance teilweise auszulagern, können Sie möglicherweise eine niedrigere Maximalkapazitätseinstellung auswählen. Damit berücksichtigen Sie die Tatsache, dass jede Reader-DB-Instance nicht gleichermaßen hoch skaliert werden muss wie im Falle, dass der Cluster nur eine einzelne DB-Instance enthält.
-
Angenommen, Sie möchten sich vor übermäßiger Auslastung aufgrund falsch konfigurierter Datenbankparameter oder ineffizienter Abfragen in Ihrer Anwendung schützen. In diesem Fall können Sie eine versehentliche Überbeanspruchung vermeiden, indem Sie eine maximale Kapazitätseinstellung wählen, die niedriger ist als die absolut höchste, die Sie festlegen können.
-
Wenn Spitzen aufgrund realer Benutzeraktivitäten zwar selten sind, aber dennoch auftreten, können Sie diese Situationen bei der Auswahl der maximalen Kapazitätseinstellung berücksichtigen. Wenn die Priorität darin besteht, dass die Anwendung weiterhin mit voller Leistung und Skalierbarkeit ausgeführt wird, können Sie eine maximale Kapazitätseinstellung angeben, die höher ist, als Sie bei normaler Auslastung beobachten. Wenn es akzeptabel ist, dass die Anwendung bei sehr extremen Aktivitätsspitzen mit reduziertem Durchsatz ausgeführt wird, können Sie eine etwas niedrigere maximale Kapazitätseinstellung wählen. Stellen Sie sicher, dass Sie eine Einstellung auswählen, die immer noch über genügend Speicher- und CPU-Ressourcen verfügt, damit die Anwendung weiterhin ausgeführt wird.
-
Wenn Sie Einstellungen in Ihrem Cluster aktivieren, die die Speicherauslastung für jede DB-Instance erhöhen, berücksichtigen Sie diesen Speicher bei der Entscheidung über den maximalen ACU-Wert. Zu diesen Einstellungen gehören diejenigen für Performance Insights, parallele Aurora MySQL-Abfragen, Aurora MySQL-Leistungsschema und Aurora MySQL-Binärprotokollreplikation. Stellen Sie sicher, dass der maximale ACU-Wert Aurora Serverless v2-DB-Instances erlaubt, ausreichend hoch zu skalieren, um die Workload zu bewältigen, wenn diese Funktion verwendet wird. Informationen zur Fehlerbehebung von Problemen, die durch die Kombination einer niedrigen maximalen ACU-Einstellung und Aurora-Funktionen verursacht werden, die Speicher-Overhead verursachen, finden Sie unter Fehler vermeiden out-of-memory.
Beispiel: Ändern des Aurora Serverless v2-Kapazitätsbereichs eines Aurora-MySQL-Clusters
Das folgende AWS CLI Beispiel zeigt, wie der ACU-Bereich für Aurora Serverless v2 DB-Instances in einem vorhandenen Aurora MySQL-Cluster aktualisiert wird. Anfänglich liegt der Kapazitätsbereich für den Cluster zwischen 8 ACUs und 32.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 8.0, "MaxCapacity": 32.0 }
Die DB-Instance befindet sich im Leerlauf und wurde auf 8 herunterskaliert. ACUs Die folgenden kapazitätsbezogenen Einstellungen gelten zu diesem Zeitpunkt für die DB-Instance. Zum Darstellen der Größe des Pufferpools in leicht lesbaren Einheiten teilen wir ihn durch 2 hoch 30, was zu einer Messung in Gibibyte (GiB) führt. Das liegt daran, dass speicherbezogene Messungen für Aurora Einheiten verwenden, die auf Zweierpotenzen und nicht auf Zehnerpotenzen basieren.
mysql> select @@max_connections; +-------------------+ | @@max_connections | +-------------------+ | 3000 | +-------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size; +---------------------------+ | @@innodb_buffer_pool_size | +---------------------------+ | 9294577664 | +---------------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size / pow(2,30) as gibibytes; +-----------+ | gibibytes | +-----------+ | 8.65625 | +-----------+ 1 row in set (0.00 sec)
Als Nächstes ändern wir den Kapazitätsbereich für den Cluster. Nachdem der modify-db-cluster-Befehl abgeschlossen ist, beträgt der ACU-Bereich für den Cluster 12,5 bis 80.
aws rds modify-db-cluster --db-cluster-identifier serverless-v2-cluster \ --serverless-v2-scaling-configuration MinCapacity=12.5,MaxCapacity=80 aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 12.5, "MaxCapacity": 80.0 }
Durch Ändern des Kapazitätsbereichs können sich die Standardwerte einiger Konfigurationsparameter ändern. Aurora kann einige dieser neuen Standardwerte sofort anwenden. Einige der Parameteränderungen werden jedoch erst nach einem Neustart wirksam. Der Status pending-reboot gibt an, dass ein Neustart erforderlich ist, um einige Parameteränderungen anzuwenden.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "pending-reboot" } ] }
Zu diesem Zeitpunkt befindet sich der Cluster im Leerlauf und die DB-Instance serverless-v2-instance-1 verbraucht 12,5 ACUs. Der innodb_buffer_pool_size-Parameter ist bereits basierend auf der aktuellen Kapazität der DB-Instance angepasst. Der max_connections-Parameter spiegelt immer noch den Wert der früheren maximalen Kapazität wider. Das Zurücksetzen dieses Werts erfordert einen Neustart der DB-Instance.
Anmerkung
Wenn Sie den max_connections Parameter direkt in einer benutzerdefinierten DB-Parametergruppe festlegen, ist kein Neustart erforderlich.
mysql> select @@max_connections; +-------------------+ | @@max_connections | +-------------------+ | 3000 | +-------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size; +---------------------------+ | @@innodb_buffer_pool_size | +---------------------------+ | 15572402176 | +---------------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size / pow(2,30) as gibibytes; +---------------+ | gibibytes | +---------------+ | 14.5029296875 | +---------------+ 1 row in set (0.00 sec)
Jetzt starten wir die DB-Instance neu und warten darauf, dass sie wieder verfügbar ist.
aws rds reboot-db-instance --db-instance-identifier serverless-v2-instance-1 { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBInstanceStatus": "rebooting" } aws rds wait db-instance-available --db-instance-identifier serverless-v2-instance-1
Der pending-reboot-Status ist gelöscht. Der Wert in-sync bestätigt, dass Aurora alle ausstehenden Parameteränderungen übernommen hat.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "in-sync" } ] }
Der innodb_buffer_pool_size-Parameter hat sich auf seine endgültige Größe für eine inaktive DB-Instance erhöht. Der max_connections-Parameter wurde erhöht, um einen vom maximalen ACU-Wert abgeleiteten Wert widerzuspiegeln. Die Formel, die Aurora für max_connections verwendet, führt zu einem Anstieg von 1.000, wenn sich die Speichergröße verdoppelt.
mysql> select @@innodb_buffer_pool_size; +---------------------------+ | @@innodb_buffer_pool_size | +---------------------------+ | 16139681792 | +---------------------------+ 1 row in set (0.00 sec) mysql> select @@innodb_buffer_pool_size / pow(2,30) as gibibytes; +-----------+ | gibibytes | +-----------+ | 15.03125 | +-----------+ 1 row in set (0.00 sec) mysql> select @@max_connections; +-------------------+ | @@max_connections | +-------------------+ | 4000 | +-------------------+ 1 row in set (0.00 sec)
Wir setzen den Kapazitätsbereich auf 0,5—128 ACUs und starten die DB-Instance neu. Jetzt hat die inaktive DB-Instance eine Puffer-Cache-Größe von weniger als 1 GiB. Daher messen wir sie nun in Mebibyte (MiB). Der max_connections-Wert 5.000 wird von der Speichergröße der maximalen Kapazitätseinstellung abgeleitet.
mysql> select @@innodb_buffer_pool_size / pow(2,20) as mebibytes, @@max_connections; +-----------+-------------------+ | mebibytes | @@max_connections | +-----------+-------------------+ | 672 | 5000 | +-----------+-------------------+ 1 row in set (0.00 sec)
Beispiel: Ändern des Aurora Serverless v2-Kapazitätsbereichs eines Aurora-PostgreSQL-Clusters
Das folgende CLI-Beispiel zeigt, wie Sie den ACU-Bereich für DB-Instances von Aurora Serverless v2 in einem bestehenden Aurora-PostgreSQL-Cluster aktualisieren.
-
Der Kapazitätsbereich für den Cluster beginnt bei 0,5 bis 1 ACU.
-
Ändern Sie den Kapazitätsbereich auf 8—32. ACUs
-
Ändern Sie den Kapazitätsbereich auf 12,5—80. ACUs
-
Ändern Sie den Kapazitätsbereich auf 0,5—128. ACUs
-
Legen Sie die Kapazität wieder auf den ursprünglichen Bereich von 0,5 bis 1 ACU fest.
Die folgende Abbildung zeigt die Kapazitätsänderungen in Amazon CloudWatch.
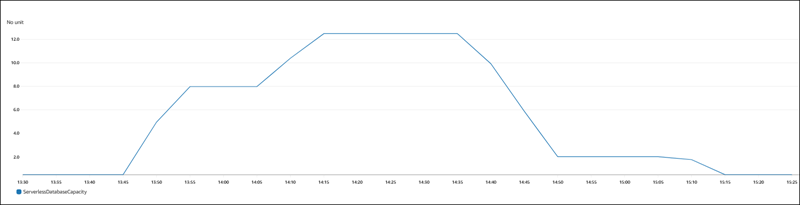
Die DB-Instance befindet sich im Leerlauf und wurde auf 0,5 ACUs herunterskaliert. Die folgenden kapazitätsbezogenen Einstellungen gelten zu diesem Zeitpunkt für die DB-Instance.
postgres=> show max_connections; max_connections ----------------- 189 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 16384 (1 row)
Als Nächstes ändern wir den Kapazitätsbereich für den Cluster. Nachdem der modify-db-cluster-Befehl abgeschlossen ist, beträgt der ACU-Bereich für den Cluster 8,0 bis 32.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 8.0, "MaxCapacity": 32.0 }
Durch Ändern des Kapazitätsbereichs können sich die Standardwerte einiger Konfigurationsparameter ändern. Aurora kann einige dieser neuen Standardwerte sofort anwenden. Einige der Parameteränderungen werden jedoch erst nach einem Neustart wirksam. Der Status pending-reboot gibt an, dass ein Neustart erforderlich ist, um einige Parameteränderungen anzuwenden.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "pending-reboot" } ] }
Zu diesem Zeitpunkt befindet sich der Cluster im Leerlauf und die DB-Instance serverless-v2-instance-1 verbraucht 8,0 ACUs. Der shared_buffers-Parameter ist bereits basierend auf der aktuellen Kapazität der DB-Instance angepasst. Der max_connections-Parameter spiegelt immer noch den Wert der früheren maximalen Kapazität wider. Das Zurücksetzen dieses Werts erfordert einen Neustart der DB-Instance.
Anmerkung
Wenn Sie den max_connections Parameter direkt in einer benutzerdefinierten DB-Parametergruppe festlegen, ist kein Neustart erforderlich.
postgres=> show max_connections; max_connections ----------------- 189 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 1425408 (1 row)
Wir starten die DB-Instance neu und warten darauf, dass sie wieder verfügbar ist.
aws rds reboot-db-instance --db-instance-identifier serverless-v2-instance-1 { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBInstanceStatus": "rebooting" } aws rds wait db-instance-available --db-instance-identifier serverless-v2-instance-1
Nachdem die DB-Instance neu gestartet wurde, ist der Status pending-reboot gelöscht. Der Wert in-sync bestätigt, dass Aurora alle ausstehenden Parameteränderungen übernommen hat.
aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query '*[].{DBClusterMembers:DBClusterMembers[*].{DBInstanceIdentifier:DBInstanceIdentifier,DBClusterParameterGroupStatus:DBClusterParameterGroupStatus}}|[0]' { "DBClusterMembers": [ { "DBInstanceIdentifier": "serverless-v2-instance-1", "DBClusterParameterGroupStatus": "in-sync" } ] }
Nach dem Neustart zeigt max_connections den Wert der neuen maximalen Kapazität an.
postgres=> show max_connections; max_connections ----------------- 5000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 1425408 (1 row)
Als Nächstes ändern wir den Kapazitätsbereich für den Cluster auf ACUs 12,5—80.
aws rds modify-db-cluster --db-cluster-identifier serverless-v2-cluster \ --serverless-v2-scaling-configuration MinCapacity=12.5,MaxCapacity=80 aws rds describe-db-clusters --db-cluster-identifier serverless-v2-cluster \ --query 'DBClusters[*].ServerlessV2ScalingConfiguration|[0]' { "MinCapacity": 12.5, "MaxCapacity": 80.0 }
Zu diesem Zeitpunkt befindet sich der Cluster im Leerlauf und die DB-Instance verbraucht 12,5serverless-v2-instance-1. ACUs Der shared_buffers-Parameter ist bereits basierend auf der aktuellen Kapazität der DB-Instance angepasst. Der max_connections-Wert beträgt immer noch 5 000.
postgres=> show max_connections; max_connections ----------------- 5000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 2211840 (1 row)
Wir führen einen weiteren Neustart durch, aber die Parameterwerte bleiben gleich. Dies liegt daran, dass für max_connections ein Höchstwert von 5 000 für einen DB-Cluster von Aurora Serverless v2 gilt, auf dem Aurora PostgreSQL ausgeführt wird.
postgres=> show max_connections; max_connections ----------------- 5000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 2211840 (1 row)
Jetzt legen wir den Kapazitätsbereich von 0,5 bis 128 fest ACUs. Der DB-Cluster wird auf 10 ACUs und dann auf 2 herunterskaliert. Wir starten die DB-Instance neu.
postgres=> show max_connections; max_connections ----------------- 2000 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 16384 (1 row)
Der max_connections Wert für Aurora Serverless v2 DB-Instances basiert auf der Speichergröße, die vom Maximum abgeleitet wird ACUs. Wenn Sie jedoch eine Mindestkapazität von 0 oder 0,5 für PostgreSQL-kompatible DB-Instances angeben, max_connections ist der Höchstwert von ACUs auf 2.000 begrenzt.
Jetzt legen wir die Kapazität wieder auf den ursprünglichen Bereich von 0,5 bis 1 ACU fest und starten die DB-Instance neu. Der max_connections-Parameter ist auf seinen ursprünglichen Wert zurückgekehrt.
postgres=> show max_connections; max_connections ----------------- 189 (1 row) postgres=> show shared_buffers; shared_buffers ---------------- 16384 (1 row)
Arbeiten mit Parametergruppen für Aurora Serverless v2
Wenn Sie Ihren Aurora Serverless v2-DB-Cluster erstellen, wählen Sie eine bestimmte Aurora-DB-Engine und eine zugehörige DB-Cluster-Parametergruppe. Wenn Sie nicht damit vertraut sind, wie Aurora Parametergruppen verwendet, um Konfigurationseinstellungen konsistent auf Cluster anzuwenden, finden Sie weitere Informationen unter Parametergruppen für Amazon Aurora. Alle diese Verfahren zum Erstellen, Ändern, Anwenden sowie andere Aktionen für Parametergruppen gelten für Aurora Serverless v2.
Die Parametergruppen-Funktion funktioniert im Allgemeinen für bereitgestellte Cluster und Cluster, dieAurora Serverless v2-DB-Instances enthalten, gleich:
-
Die Standardparameterwerte für alle DB-Instances im Cluster werden von der Cluster-Parametergruppe definiert.
-
Sie können einige Parameter für bestimmte DB-Instances überschreiben, indem Sie eine benutzerdefinierte DB-Parametergruppe für diese DB-Instances angeben. Diesen Vorgang können Sie während des Debuggens oder der Leistungsoptimierung für bestimmte DB-Instances durchführen. Angenommen, Sie haben einen Cluster, der einige Aurora Serverless v2-DB-Instances und einige bereitgestellte DB-Instances enthält. In diesem Fall können Sie mithilfe einer benutzerdefinierten DB-Parametergruppe einige andere Parameter für die bereitgestellten DB-Instances angeben.
-
Bei Aurora Serverless v2 können Sie alle Parameter verwenden, die den Wert
provisionedimSupportedEngineModes-Attribut der Parametergruppe aufweisen. In Aurora Serverless v1 können Sie nur die Teilmenge von Parametern verwenden, dieserverlessimSupportedEngineModes-Attribut enthalten.
Themen
Standard-Parameterwerte
Der entscheidende Unterschied zwischen bereitgestellten DB-Instances und Aurora Serverless v2-DB-Instances besteht darin, dass Aurora alle benutzerdefinierten Parameterwerte für bestimmte Parameter außer Kraft setzt, die sich auf die Kapazität der DB-Instance beziehen. Die benutzerdefinierten Parameterwerte gelten weiterhin für alle bereitgestellten DB-Instances in Ihrem Cluster. Weitere Details darüber, wie Aurora Serverless v2-DB-Instances die Parameter aus Aurora-Parametergruppen interpretieren, finden Sie unter Konfigurationsparameter für Aurora-Cluster. Die spezifischen Parameter, die Aurora Serverless v2 außer Kraft setzen, finden Sie unter Parameter, die Aurora anpasst, während Aurora Serverless v2 hoch- und herunterskaliert und Parameter, die Aurora basierend auf der maximalen Kapazität von Aurora Serverless v2 berechnet.
Sie können eine Liste der Standardwerte für die Standardparametergruppen für die verschiedenen Aurora-DB-Engines abrufen, indem Sie den describe-db-cluster-parametersCLI-Befehl verwenden und die AWS-Region abfragen. Die folgenden Werte können Sie für die Optionen --db-parameter-group-family und -db-parameter-group-name für Engine-Versionen verwenden, die mit Aurora Serverless v2 kompatibel sind.
| Datenbank-Engine und -Version | Parametergruppenfamilie | Name der Standard-Parametergruppe |
|---|---|---|
|
Aurora-MySQL-Version 3 |
|
|
|
Aurora-PostgreSQL-Version 13.x |
|
|
|
Aurora-PostgreSQL-Version 14.x |
|
|
|
Aurora-PostgreSQL-Version 15.x |
|
|
|
Aurora PostgreSQL Version 16.x |
|
|
|
Aurora PostgreSQL versie 17.x |
|
|
Im folgenden Beispiel wird eine Liste von Parametern aus der Standard-DB-Cluster-Gruppe für Aurora-MySQL-Version 3 und Aurora PostgreSQL 13 abgerufen. Dies sind die Aurora-MySQL- und Aurora-PostgreSQL-Versionen, die Sie mit Aurora Serverless v2 verwenden.
FürLinux, oder: macOS Unix
aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-name default.aurora-mysql8.0 \ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' \ --output text aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-name default.aurora-postgresql13 \ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' \ --output text
Windows:
aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-name default.aurora-mysql8.0 ^ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' ^ --output text aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-name default.aurora-postgresql13 ^ --query 'Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `provisioned`) == `true`] | [*].[ParameterName]' ^ --output text
Maximale Anzahl der Verbindungen für Aurora Serverless v2
Sowohl für Aurora MySQL als auch für Aurora PostgreSQL halten Aurora Serverless v2-DB-Instances den Parameter max_connections konstant, damit Verbindungen nicht unterbrochen werden, wenn die DB-Instance herunterskaliert wird. Der Standardwert für diesen Parameter leitet sich von einer Formel ab, die auf der Speichergröße der DB-Instance beruht. Weitere Informationen zur Formel und zu den Standardwerten für bereitgestellte DB-Instance-Klassen finden Sie unter Maximale Verbindungen zu einer Aurora MySQL-DB-Instance und Maximale Verbindungen zu einer Aurora PostgreSQL-DB-Instance.
Bei der Aurora Serverless v2 Auswertung der Formel wird die Speichergröße verwendet, die auf den maximalen Aurora-Kapazitätseinheiten (ACUs) für die DB-Instance basiert, nicht auf dem aktuellen ACU-Wert. Wenn Sie den Standardwert ändern, empfehlen wir, eine Variante der Formel zu verwenden, anstatt einen konstanten Wert anzugeben. Auf diese Weise kann Aurora Serverless v2 basierend auf der maximalen Kapazität eine angemessene Einstellung verwenden.
Wenn Sie die maximale Kapazität eines DB-Clusters von Aurora Serverless v2 ändern, müssen Sie die DB-Instances von Aurora Serverless v2 neu starten, um den max_connections-Wert zu aktualisieren. Dies liegt daran, dass es sich bei max_connections um einen statischen Parameter für Aurora Serverless v2 handelt.
Die folgende Tabelle zeigt die Standardwerte für max_connections für Aurora Serverless v2 basierend auf dem maximalen ACU-Wert.
| Maximal ACUs | Standardmäßige maximale Verbindungen für Aurora MySQL | Standardmäßige maximale Verbindungen für Aurora PostgreSQL |
|---|---|---|
| 1 | 90 | 189 |
| 4 | 135 | 823 |
| 8 | 1.000 | 1.669 |
| 16 | 2.000 | 3.360 |
| 32 | 3,000 | 5,000 |
| 64 | 4.000 | 5,000 |
| 128 | 5,000 | 5,000 |
| 192 | 6.000 | 5,000 |
| 256 | 6.000 | 5,000 |
Anmerkung
Der max_connections Wert für Aurora Serverless v2 DB-Instances basiert auf der Speichergröße, die sich aus dem Maximum ACUs ergibt. Wenn Sie jedoch eine Mindestkapazität von 0 oder 0,5 für PostgreSQL-kompatible DB-Instances angeben, max_connections ist der Höchstwert von ACUs auf 2.000 begrenzt.
Konkrete Beispiele, die zeigen, wie sich max_connections mit dem maximalen ACU-Wert ändert, finden Sie unter Beispiel: Ändern des Aurora Serverless v2-Kapazitätsbereichs eines Aurora-MySQL-Clusters und Beispiel: Ändern des Aurora Serverless v2-Kapazitätsbereichs eines Aurora-PostgreSQL-Clusters.
Parameter, die Aurora anpasst, während Aurora Serverless v2 hoch- und herunterskaliert
Bei der automatischen Skalierung muss Aurora Serverless v2 in der Lage sein, Parameter zu ändern, damit jede DB-Instance optimal für die erhöhte oder verringerte Kapazität funktioniert. Daher können Sie einige Parameter im Zusammenhang mit der Kapazität nicht außer Kraft setzen. Vermeiden Sie bei einigen Parametern, die Sie außer Kraft setzen können, eine Hartcodierung fester Werte. Die folgenden Überlegungen gelten für diese Einstellungen, die sich auf die Kapazität beziehen.
Bei Aurora MySQL ändert Aurora Serverless v2 die Größe einiger Parameter während der Skalierung dynamisch. Für die folgenden Parameter verwendet Aurora Serverless v2 keine benutzerdefinierten Parameterwerte, die Sie angeben:
-
innodb_buffer_pool_size -
innodb_purge_threads -
table_definition_cache -
table_open_cache
Bei Aurora PostgreSQL ändert Aurora Serverless v2 die Größe der folgenden Parameter während der Skalierung dynamisch. Für die folgenden Parameter verwendet Aurora Serverless v2 keine benutzerdefinierten Parameterwerte, die Sie angeben:
-
shared_buffers
Für alle anderen Parameter als die hier aufgelisteten funktionieren DB-Instances von Aurora Serverless v2 genauso wie bereitgestellte DB-Instances. Der Standardparameterwert wird von der Cluster-Parametergruppe geerbt. Sie können den Standardwert für den gesamten Cluster mit einer benutzerdefinierten Cluster-Parametergruppe ändern. Den Standardwert für bestimmte DB-Instances können Sie auch mithilfe einer benutzerdefinierten DB-Parametergruppe ändern. Die dynamischen Parameter werden sofort aktualisiert. Änderungen an statischen Parametern werden erst wirksam, nachdem Sie die DB-Instance neu gestartet haben.
Parameter, die Aurora basierend auf der maximalen Kapazität von Aurora Serverless v2 berechnet
Für die folgenden Parameter verwendet Aurora PostgreSQL auch Standardwerte, die genau wie bei max_connections von der Speichergröße basierend auf der maximalen ACU-Einstellung abgeleitet werden:
-
autovacuum_max_workers -
autovacuum_vacuum_cost_limit -
autovacuum_work_mem -
effective_cache_size -
maintenance_work_mem
Fehler vermeiden out-of-memory
Wenn eine Ihrer Aurora Serverless v2-DB-Instances konsequent die Grenze ihrer maximalen Kapazität erreicht, weist Aurora auf diese Bedingung hin, indem die DB-Instance auf den Status incompatible-parameters festgelegt wird. Während die DB-Instance den Status incompatible-parameters aufweist, sind einige Operationen blockiert. Beispielsweise können Sie die Engine-Version nicht aktualisieren.
In der Regel wechselt Ihre DB-Instance in diesen Status, wenn sie aufgrund von out-of-memory Fehlern häufig neu gestartet wird. Aurora zeichnet ein Ereignis auf, wenn diese Art von Neustart stattfindet. Sie können das Ereignis anzeigen, indem Sie die Vorgehensweise unter RDSAmazon-Ereignisse anzeigen befolgen. Eine ungewöhnlich hohe Speicherauslastung kann aufgrund von Overhead durch Aktivieren von Einstellungen wie Performance Insights und IAM-Authentifizierung auftreten. Sie kann auch durch eine hohe Workload Ihrer DB-Instance oder durch die Verwaltung der Metadaten entstehen, die mit einer großen Anzahl von Schemaobjekten verknüpft sind.
Wenn die Speicherauslastung sinkt, sodass die DB-Instance ihre maximale Kapazität nicht sehr oft erreicht, ändert Aurora den Status der DB-Instance automatisch wieder in available.
Zur Wiederherstellung nach diesem Zustand können Sie einige oder alle der folgenden Aktionen ausführen:
-
Erhöhen Sie die untere Kapazitätsgrenze für Aurora Serverless v2-DB-Instances durch Ändern des Mindestwerts der Aurora-Kapazitätseinheit (ACU) für den Cluster. Dadurch werden Probleme vermieden, bei denen eine inaktive Datenbank auf eine Kapazität mit weniger Speicher herunterskaliert wird, als für die in Ihrem Cluster aktivierten Funktionen benötigt wird. Nachdem Sie die ACU-Einstellungen für den Cluster geändert haben, starten Sie die Aurora Serverless v2-DB-Instance neu. Dadurch wird geprüft, ob Aurora den Status wieder auf
availablezurücksetzen kann. -
Erhöhen Sie die untere Kapazitätsgrenze für Aurora Serverless v2-DB-Instances durch Ändern des maximalen Werts der Aurora-Kapazitätseinheit (ACU) für den Cluster. Auf diese Weise werden Probleme vermieden, bei denen eine ausgelastete Datenbank nicht auf eine Kapazität mit genügend Speicher für die in Ihrem Cluster aktivierten Funktionen und die Datenbank-Workload hochskaliert werden kann. Nachdem Sie die ACU-Einstellungen für den Cluster geändert haben, starten Sie die Aurora Serverless v2-DB-Instance neu. Dadurch wird geprüft, ob Aurora den Status wieder auf
availablezurücksetzen kann. -
Deaktivieren Sie Konfigurationseinstellungen, die Speicher-Overhead erfordern. Angenommen, Sie haben Funktionen wie AWS Identity and Access Management (IAM), Performance Insights oder Aurora MySQL-Binärprotokollreplikation aktiviert, verwenden sie aber nicht. In diesem Fall können Sie sie deaktivieren. Oder Sie können die minimalen und maximalen Kapazitätswerte für den Cluster nach oben korrigieren, um den von diesen Funktionen verwendeten Speicher zu berücksichtigen. Richtlinien zur Auswahl der minimalen und maximalen Kapazitätseinstellungen finden Sie unter Auswählen des Aurora Serverless v2-Kapazitätsbereichs für einen Aurora-Cluster.
-
Reduzieren Sie die Workload der DB-Instance. Beispielsweise können Sie dem Cluster Reader-DB-Instances hinzufügen, um die Last von schreibgeschützten Abfragen auf weitere DB-Instances zu verteilen.
-
Optimieren Sie den von Ihrer Anwendung verwendeten SQL-Code, um weniger Ressourcen zu verwenden. Sie können beispielsweise Ihre Abfragepläne untersuchen, das langsame Abfrageprotokoll überprüfen oder die Indizes in Ihren Tabellen anpassen. Außerdem können Sie andere traditionelle Arten von SQL-Optimierung durchführen.
Wichtige CloudWatch Amazon-Metriken für Aurora Serverless v2
Informationen zu den ersten Schritten mit Amazon CloudWatch für Ihre Aurora Serverless v2 DB-Instance finden Sie unterAurora Serverless v2Logs in Amazon anzeigen CloudWatch. Weitere Informationen zur Überwachung von Aurora-DB-Clustern finden CloudWatch Sie unterÜberwachen von Protokollereignissen in Amazon CloudWatch.
Anhand der ServerlessDatabaseCapacity Metrik können Sie Ihre Aurora Serverless v2 DB-Instances anzeigen CloudWatch , um die von jeder DB-Instance verbrauchte Kapazität zu überwachen. Sie können auch alle CloudWatch Aurora-Standardmetriken wie DatabaseConnections und überwachenQueries. Die vollständige Liste der CloudWatch Messwerte, die Sie für Aurora überwachen können, finden Sie unter CloudWatch Amazon-Metriken für Amazon Aurora. Die Metriken sind in Metriken auf Clusterebene für Amazon Aurora und Metriken auf Instance-Ebene für Amazon Aurora in Metriken auf Cluster-Ebene und auf Instance-Ebene unterteilt.
Es ist wichtig, die folgenden Metriken CloudWatch auf Instance-Ebene zu überwachen, damit Sie verstehen, wie Ihre Aurora Serverless v2 DB-Instances nach oben und unten skalieren. Alle diese Metriken werden jede Sekunde berechnet. Auf diese Weise können Sie den aktuellen Status Ihrer Aurora Serverless v2-DB-Instances überwachen. Sie können Alarme einstellen, um sich gegebenenfalls benachrichtigen zu lassen, wenn sich eine Aurora Serverless v2-DB-Instance einem Schwellenwert für kapazitätsbezogene Metriken nähert. Sie können feststellen, ob die minimalen und maximalen Kapazitätseinstellungen angemessen sind oder ob Sie sie anpassen müssen. Sie können bestimmen, worauf Sie sich konzentrieren müssen, um die Effizienz Ihrer Datenbank zu optimieren.
-
ServerlessDatabaseCapacity. Als Metrik auf Instance-Ebene wird die Anzahl der durch die aktuelle ACUs DB-Instance-Kapazität repräsentierten Werte angegeben. Als Metrik auf Cluster-Ebene repräsentiert sie den Durchschnitt derServerlessDatabaseCapacity-Werte aller Aurora Serverless v2-DB-Instances im Cluster. Diese Metrik ist nur eine Metrik auf Cluster-Ebene in Aurora Serverless v1. In Aurora Serverless v2 ist sie auf DB-Instance-Ebene und auf Cluster-Ebene verfügbar. -
ACUUtilization: Diese Metrik ist neu in Aurora Serverless v2. Dieser Wert wird als Prozentsatz dargestellt. Er wird als Wert derServerlessDatabaseCapacity-Metrik geteilt durch den maximalen ACU-Wert des DB-Clusters berechnet. Beachten Sie die folgenden Richtlinien, um diese Metrik zu interpretieren und Maßnahmen zu ergreifen:-
Wenn sich diese Metrik dem Wert
100.0nähert, ist die DB-Instance so hoch wie möglich hochskaliert. Erwägen Sie, die maximale ACU-Einstellung für den Cluster zu erhöhen. Auf diese Weise können sowohl Writer- als auch Reader-DB-Instances auf eine höhere Kapazität skaliert werden. -
Angenommen, eine schreibgeschützte Workload bewirkt, dass sich eine Reader-DB-Instance einem
ACUUtilization-Wert von100.0nähert, während die Writer-DB-Instance ihrer maximalen Kapazität nicht annähernd erreicht. Erwägen Sie in diesem Fall, dem Cluster zusätzliche Reader-DB-Instances hinzuzufügen. Auf diese Weise können Sie den schreibgeschützten Teil der Workload auf mehrere DB-Instances verteilen und so die Last jeder Reader-DB-Instance reduzieren. -
Angenommen, Sie führen eine Produktionsanwendung aus, bei der Leistung und Skalierbarkeit die Hauptüberlegungen sind. In diesem Fall können Sie den maximalen ACU-Wert für den Cluster auf eine hohe Zahl festlegen. Ihr Ziel besteht darin, die
ACUUtilization-Metrik immer unter100.0zu halten. Mit einem hohen maximalen ACU-Wert können Sie sicher sein, dass genügend Spielraum vorhanden ist, falls unerwartete Spitzen bei der Datenbankaktivität auftreten. Berechnet wird Ihnen nur die tatsächlich verbrauchte Datenbankkapazität.
-
-
CPUUtilization: Diese Metrik wird in Aurora Serverless v2 anders interpretiert als in bereitgestellten DB-Instances. Bei Aurora Serverless v2 ist dieser Wert ein Prozentsatz, der als der aktuell CPU-Verbrauch dividiert durch die CPU-Kapazität berechnet wird, die unter dem maximalen ACU-Wert des DB-Clusters verfügbar ist. Aurora überwacht diesen Wert automatisch und skaliert Ihre Aurora Serverless v2-DB-Instance, wenn die DB-Instance konsequent einen hohen Anteil ihrer CPU-Kapazität verbraucht.Wenn sich diese Metrik dem Wert
100.0nähert, hat die DB-Instance ihre maximale CPU-Kapazität erreicht. Erwägen Sie, die maximale ACU-Einstellung für den Cluster zu erhöhen. Wenn sich diese Metrik dem Wert100.0nähert, erwägen Sie bei einer Reader-DB-Instance, dem Cluster weitere Reader-DB-Instances hinzuzufügen. Auf diese Weise können Sie den schreibgeschützten Teil der Workload auf mehrere DB-Instances verteilen und so die Last jeder Reader-DB-Instance reduzieren. -
FreeableMemory: Dieser Wert stellt die Menge des nicht belegten Speichers dar, die verfügbar ist, wenn die Aurora Serverless v2-DB-Instance auf ihre maximale Kapazität skaliert wird. Für jede ACU, bei der die aktuelle Kapazität unter der maximalen Kapazität liegt, erhöht sich dieser Wert ungefähr um 2 GiB. Daher nähert sich diese Metrik erst null, wenn die DB-Instance so hoch wie möglich hochskaliert ist.Wenn sich diese Metrik dem Wert
0nähert, ist die DB-Instance so weit wie möglich hochskaliert und nähert sich der Grenze ihres verfügbaren Speichers. Erwägen Sie, die maximale ACU-Einstellung für den Cluster zu erhöhen. Wenn sich diese Metrik dem Wert0nähert, erwägen Sie bei einer Reader-DB-Instance, dem Cluster weitere Reader-DB-Instances hinzuzufügen. Auf diese Weise können Sie den schreibgeschützten Teil der Workload auf mehrere DB-Instances verteilen und so die Speicherauslastung für jede Reader-DB-Instance reduzieren. -
TempStorageIOPS: Die Anzahl der IOPS, die im lokalen Speicher durchgeführt werden, der der DB-Instance angefügt ist. Dabei sind IOPS für Lese- und Schreibvorgänge enthalten. Diese Metrik stellt eine Zählung dar und wird einmal pro Sekunde gemessen. Dies ist eine neue Metrik für Aurora Serverless v2. Details hierzu finden Sie unter Metriken auf Instance-Ebene für Amazon Aurora. -
TempStorageThroughput: Die Menge der mit der DB-Instance verknüpften Daten, die zu und aus dem lokalen Speicher übertragen wurden. Diese Metrik wird in Byte angegeben und einmal pro Sekunde gemessen. Dies ist eine neue Metrik für Aurora Serverless v2. Details hierzu finden Sie unter Metriken auf Instance-Ebene für Amazon Aurora.
In der Regel wird die Hochskalierung von Aurora Serverless v2-DB-Instances größtenteils durch Speicherauslastung und CPU-Aktivität verursacht. Die Metriken TempStorageIOPS und TempStorageThroughput können Ihnen helfen, die seltenen Fälle zu diagnostizieren, in denen die Netzwerkaktivität für Übertragungen zwischen Ihrer DB-Instance und lokalen Speichergeräten für unerwartete Kapazitätssteigerungen verantwortlich ist. Wenn Sie andere Netzwerkaktivitäten überwachen möchten, können Sie diese vorhandenen Metriken verwenden:
-
NetworkReceiveThroughput -
NetworkThroughput -
NetworkTransmitThroughput -
StorageNetworkReceiveThroughput -
StorageNetworkThroughput -
StorageNetworkTransmitThroughput
Sie können Aurora einige oder alle Datenbankprotokolle in Amazon CloudWatch Logs veröffentlichen lassen. Anweisungen finden Sie je nach Datenbank-Engine im Folgenden:
Wie wirken sich Aurora Serverless v2 Kennzahlen auf Ihre AWS Rechnung aus
Die Aurora Serverless v2 Gebühren auf Ihrer AWS Rechnung werden auf der Grundlage derselben ServerlessDatabaseCapacity Kennzahl berechnet, die Sie überwachen können. Der Abrechnungsmechanismus kann in Fällen, in denen Sie die Aurora Serverless v2 Kapazität nur für einen Teil einer Stunde nutzen, vom berechneten CloudWatch Durchschnitt für diese Kennzahl abweichen. Es kann auch anders sein, wenn die CloudWatch Metrik aufgrund von Systemproblemen für kurze Zeit nicht verfügbar ist. Daher sehen Sie möglicherweise einen etwas anderen Wert von ACU-Stunden auf Ihrer Rechnung, als wenn Sie die Anzahl selbst anhand des ServerlessDatabaseCapacity-Durchschnittswerts berechnen.
Beispiele für CloudWatch Befehle für Aurora Serverless v2 Metriken
Die folgenden AWS CLI Beispiele zeigen, wie Sie die wichtigsten CloudWatch Kennzahlen im Zusammenhang mit überwachen könnenAurora Serverless v2. Ersetzen Sie in jedem Fall die Value=-Zeichenfolge für den --dimensions-Parameter durch den Bezeichner Ihrer eigenen Aurora Serverless v2-DB-Instance.
Im folgenden Linux-Beispiel werden die minimalen, maximalen und durchschnittlichen Kapazitätswerte für eine DB-Instance angezeigt, die alle 10 Minuten über einen Zeitraum von einer Stunde gemessen werden. Der Linux-Befehl date gibt die Start- und Endzeiten relativ zum aktuellen Datum und zur aktuellen Uhrzeit an. Die sort_by-Funktion im --query-Parameter sortiert die Ergebnisse chronologisch basierend auf dem Feld Timestamp.
aws cloudwatch get-metric-statistics --metric-name "ServerlessDatabaseCapacity" \ --start-time "$(date -d '1 hour ago')" --end-time "$(date -d 'now')" --period 600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
Die folgenden Linux-Beispiele veranschaulichen die Überwachung der Kapazität jeder DB-Instance in einem Cluster. Sie messen die minimale, maximale und durchschnittliche Kapazitätsauslastung jeder DB-Instance. Die Messungen werden einmal pro Stunde über einen Zeitraum von drei Stunden durchgeführt. In diesen Beispielen wird die ACUUtilization Metrik verwendet, die einen Prozentsatz der Obergrenze für ServerlessDatabaseCapacity darstellt ACUs, anstatt eine feste Anzahl von ACUs. Auf diese Weise müssen Sie die tatsächlichen Zahlen für die minimalen und maximalen ACU-Werte im Kapazitätsbereich nicht kennen. Sie können Prozentsätze zwischen 0 und 100 sehen.
aws cloudwatch get-metric-statistics --metric-name "ACUUtilization" \ --start-time "$(date -d '3 hours ago')" --end-time "$(date -d 'now')" --period 3600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_writer_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table aws cloudwatch get-metric-statistics --metric-name "ACUUtilization" \ --start-time "$(date -d '3 hours ago')" --end-time "$(date -d 'now')" --period 3600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_reader_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
Im folgenden Linux-Beispiel werden ähnliche Messungen wie die vorherigen ausgeführt. In diesem Fall gelten die Messungen für die CPUUtilization-Metrik Die Messungen werden alle zehn Minuten über einen Zeitraum von einer Stunde durchgeführt. Die Zahlen stellen den Prozentsatz der verwendeten verfügbaren CPU dar, basierend auf den CPU-Ressourcen, die für die maximale Kapazitätseinstellung für die DB-Instance verfügbar sind.
aws cloudwatch get-metric-statistics --metric-name "CPUUtilization" \ --start-time "$(date -d '1 hour ago')" --end-time "$(date -d 'now')" --period 600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
Im folgenden Linux-Beispiel werden ähnliche Messungen wie die vorherigen ausgeführt. In diesem Fall gelten die Messungen für die FreeableMemory-Metrik Die Messungen werden alle zehn Minuten über einen Zeitraum von einer Stunde durchgeführt.
aws cloudwatch get-metric-statistics --metric-name "FreeableMemory" \ --start-time "$(date -d '1 hour ago')" --end-time "$(date -d 'now')" --period 600 \ --namespace "AWS/RDS" --statistics Minimum Maximum Average \ --dimensions Name=DBInstanceIdentifier,Value=my_instance\ --query 'sort_by(Datapoints[*].{min:Minimum,max:Maximum,avg:Average,ts:Timestamp},&ts)' --output table
Überwachung der Aurora Serverless v2-Leistung mit Performance Insights
Mit Performance Insights können Sie die Leistung von Aurora Serverless v2-DB-Instances überwachen. Informationen zu Performance-Insights-Verfahren finden Sie unter Überwachung mit Performance Insights auf .
Die folgenden neuen Performance-Insights-Zähler gelten für Aurora Serverless v2-DB-Instances:
-
os.general.serverlessDatabaseCapacity— Die aktuelle Kapazität der DB-Instance in ACUs. Der Wert entspricht derServerlessDatabaseCapacityCloudWatch Metrik für die DB-Instance. -
os.general.acuUtilization– Der Anteil der aktuellen Kapazität an der maximal konfigurierten Kapazität in Prozent. Der Wert entspricht derACUUtilizationCloudWatch Metrik für die DB-Instance. -
os.general.maxConfiguredAcu– Die maximale Kapazität, die Sie für diese Aurora Serverless v2-DB-Instance konfiguriert haben. Es wird in gemessen ACUs. -
os.general.minConfiguredAcu– Die Mindestkapazität, die Sie für diese Aurora Serverless v2-DB-Instance konfiguriert haben. Es wird gemessen in ACUs
Eine vollständige Liste der Performance-Insights-Zähler finden Sie unter Performance-Insights-Zählermetriken.
Wenn vCPU-Werte für eine Aurora Serverless v2-DB-Instance in Performance Insights angezeigt werden, stellen diese Werte Schätzungen dar, die auf dem ACU-Wert für die DB-Instance basieren. Im Standardintervall von einer Minute werden alle fraktionierten vCPU-Werte auf die nächste ganze Zahl aufgerundet. Für längere Intervalle ist der angezeigte vCPU-Wert der Durchschnitt der ganzzahligen vCPU-Werte für jede Minute.
Behebung von Kapazitätsproblemen bei Aurora Serverless v2
In einigen Fällen wird Aurora Serverless v2 nicht auf die Mindestkapazität herunterskaliert, auch wenn keine Last für die Datenbank vorliegt. Dies kann aus einem der folgenden Gründe geschehen:
-
Bestimmte Funktionen können die Ressourcennutzung erhöhen und verhindern, dass die Datenbank auf die Mindestkapazität herunterskaliert wird. Nachstehend sind einige dieser Features aufgeführt:
-
Globale Aurora-Datenbanken
-
CloudWatch Protokolle exportieren
-
Aktivieren von
pg_auditauf Aurora PostgreSQL kompatiblen DB-Clustern -
Verbesserte Überwachung
-
Performance Insights
Weitere Informationen finden Sie unter Auswählen der minimalen Aurora Serverless v2-Kapazitätseinstellung für einen Cluster.
-
-
Wenn eine Reader-Instance nicht auf das Minimum herunterskaliert wird und dieselbe oder eine höhere Kapazität als die Writer-Instance hat, überprüfen Sie die Prioritätsstufe der Reader-Instance. Reader-DB-Instances von Aurora Serverless v2 in Tier 0 oder 1 werden auf einer Mindestkapazität gehalten, die mindestens so hoch ist wie die der Writer-DB-Instance. Ändern Sie die Prioritätsstufe der Reader-Instance in 2 oder höher, sodass sie unabhängig von der Writer-Instance hoch- und herunterskaliert wird. Weitere Informationen finden Sie unter Auswählen der Hochstufungsstufe für einen Aurora Serverless v2-Reader.
-
Legen Sie alle Datenbankparameter, die sich auf die Größe des gemeinsam genutzten Speichers auswirken, auf ihre Standardwerte fest. Wenn Sie einen höheren Wert als den Standardwert festlegen, erhöht sich der gemeinsam genutzte Speicherbedarf und verhindert, dass die Datenbank auf die Mindestkapazität herunterskaliert wird. Beispiele sind
max_connectionsundmax_locks_per_transaction.Anmerkung
Das Aktualisieren gemeinsam genutzter Speicherparameter erfordert einen Neustart der Datenbank, damit Änderungen wirksam werden.
-
Hohe Datenbank-Workloads können die Ressourcennutzung erhöhen.
-
Große Datenbank-Volumes können die Ressourcennutzung erhöhen.
Amazon Aurora verwendet Speicher- und CPU-Ressourcen für die DB-Cluster-Verwaltung. Aurora benötigt mehr CPU und Arbeitsspeicher, um DB-Cluster mit größeren Datenbank-Volumes zu verwalten. Wenn die Mindestkapazität Ihres Clusters unter der für die Clusterverwaltung erforderlichen Mindestkapazität liegt, skaliert Ihr Cluster nicht auf die Mindestkapazität herunter.
-
Hintergrundprozesse wie das Bereinigen können ebenfalls den Ressourcenverbrauch erhöhen.
-
Einschränkungen der Plattformversion können sich auf die Skalierungsmöglichkeiten auswirken. Der verfügbare Skalierungsbereich für einen bestimmten Cluster wird sowohl von der Engine-Version als auch von der Hardware (Plattformversion) beeinflusst. Es ist möglich, eine leistungsfähigere Engine-Version auf einer weniger leistungsfähigen Plattformversion laufen zu lassen und umgekehrt.
Wenn die Datenbank immer noch nicht auf die konfigurierte Mindestkapazität herunterskaliert wird, beenden Sie die Datenbank und starten Sie sie neu, um alle Speicherfragmente zurückzugewinnen, die sich im Laufe der Zeit angesammelt haben könnten. Das Stoppen und Starten einer Datenbank führt zu Ausfallzeiten, daher empfehlen wir, achtsam vorzugehen.
