Amazon Forecast ist für Neukunden nicht mehr verfügbar. Bestehende Kunden von Amazon Forecast können den Service weiterhin wie gewohnt nutzen. Erfahren Sie mehr“
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
DeepAR+-Algorithmus
Amazon Forecast DeePar+ ist ein überwachter Lernalgorithmus für die Prognose skalarer (eindimensionaler) Zeitreihen mithilfe rekurrenter neuronaler Netze (). RNNs Bei klassischen Prognoseverfahren wie z. B. ARIMA (Autoregressive Integrated Moving Average) oder ETS (Exponential Smoothing) wird ein einzelnes Modell für jede einzelne Zeitreihe verwendet. Mit diesem Modell wird dann die Zeitreihe in die Zukunft extrapoliert. In vielen Anwendungen haben Sie jedoch mehrere ähnliche Zeitreihen über eine Reihe abschnittsübergreifender Einheiten hinweg. Für diese Zeitreihengruppierungen sind unterschiedliche Produkte, Serverlasten und Anforderungen für Webseiten erforderlich. In diesem Fall kann es sinnvoll sein, ein einzelnes Modell für alle Zeitreihen zu schulen. DeepAR+ verwendet diesen Ansatz. Wenn Ihr Dataset hunderte Funktionszeitreihen enthält, erzielen Sie mit dem DeepAR+-Algorithmus bessere Leistungen als mit den standardmäßigen ARIMA- und ETS-Methoden. Sie können das geschulte Modell auch zum Erstellen von Prognosen für ähnliche Zeitreihen wie die ursprünglich für die Schulung verwendete nutzen.
Python-Notizbücher
Eine step-by-step Anleitung zur Verwendung des DeePar+ Algorithmus finden Sie unter Erste Schritte
So funktioniert DeepAR+
DeepAR+ verwendet für die Schulung ein Schulungs-Dataset und optional ein Test-Dataset. Das Test-Dataset wird zur Bewertung des geschulten Modells verwendet. Allgemein müssen das Schulungs- und Test-Dataset nicht dieselben Zeitreihen enthalten. Sie können das mit einem bestimmten Trainingsdatensatz trainierte Modell nutzen, um Prognosen für künftige Versionen der Zeitreihe im Trainingsdatensatz sowie für andere Zeitreihen zu erstellen. Sowohl das Schulungs-Dataset als auch das Test-Dataset enthalten (vorzugsweise mehr als) eine Ziel-Zeitreihe. Optional können sie mit einem Vektor von Merkmalszeitreihen und einem Vektor von kategorialen Merkmalen verknüpft werden (Einzelheiten finden Sie unter DeepAR Input/Output Interface im SageMaker AI Developer Guide). Im folgenden Beispiel sehen Sie, wie dies für ein Element eines mit i indizierten Schulungs-Datasets funktioniert. Das Schulungs-Dataset besteht aus einer Ziel-Zeitreihe, zi,t, sowie zwei zugeordneten Funktionszeitreihen, xi,1,t und xi,2,t.
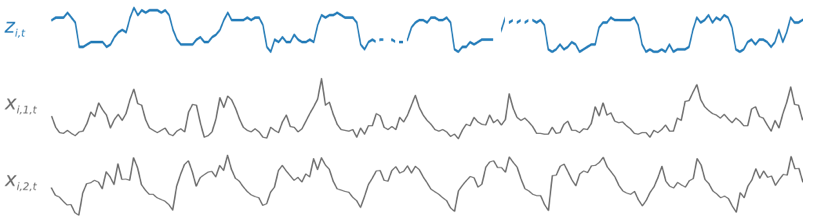
Die Ziel-Zeitreihe kann fehlende Werte enthalten (in den Grafiken durch Unterbrechungen in der Zeitreihe dargestellt). DeepAR+unterstützt nur Funktionszeitreihen, die in der Zukunft bekannt sind. So können Sie kontrafaktische Was-wäre-wenn-Szenarien durchspielen. Beispiel: „Was passiert, wenn ich den Preis eines Produkts anpasse?“
Jede Ziel-Zeitreihe kann auch einer Reihe von kategorischen Features zugeordnet werden. Sie können diese verwenden, um eine Zeitreihe an bestimmte Gruppierungen zu binden. Mithilfe von kategorischen Funktionen kann das Modell typische Verhaltensweisen für diese Gruppierungen erlernen und so genauere Prognosen erstellen. Dies wird im Modell implementiert, indem das Modell für jede Gruppe, die die allgemeinen Eigenschaften aller Zeitreihen in der Gruppe erfasst, einen eingebetteten Vektor lernt.
Um das Erlernen zeitabhängiger Muster wie Spitzen an Wochenenden zu vereinfachen, erstellt DeepAR+ automatisch Funktionszeitreihen basierend auf der Granularität der Zeitreihen. DeepAR+ erstellt beispielsweise zwei Funktionszeitreihen (Tag des Monats und Tag des Jahres) mit einer Häufigkeit von wöchentlich. Diese abgeleiteten Funktionszeitreihen werden zusammen mit der benutzerdefinierten Funktionszeitreihe verwendet, die Sie während der Schulung und Ableitung bereitstellen. Im folgenden Beispiel sehen Sie zwei abgeleitete Zeitreihenfunktionen: ui,1,t stellt die Stunde des Tages dar und ui,2,t den Wochentag.

DeepAR+ bezieht diese Funktionszeitreihen automatisch basierend auf der Datenhäufigkeit und dem Umfang der Schulungsdaten ein. In der folgenden Tabelle sind die Funktionen aufgeführt, die für jede unterstützte Basiszeithäufigkeit abgeleitet werden können.
| Häufigkeit der Zeitreihe | Abgeleitete Funktionen |
|---|---|
| Minute | minute-of-hour, hour-of-day, day-of-week, day-of-month, day-of-year |
| Stunde | hour-of-day, day-of-week, day-of-month, day-of-year |
| Tag | day-of-week, day-of-month, day-of-year |
| Woche | week-of-month, week-of-year |
| Monat | month-of-year |
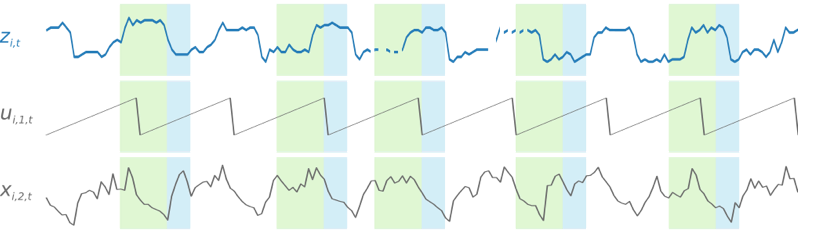
Für die Schulung eines DeepAR+-Modells werden zufällige Stichproben verschiedener Schulungsbeispiele aus den einzelnen Zeitreihen des Schulungs-Datasets verwendet. Jedes Trainingsbeispiel besteht aus einem Paar benachbarter Kontext- und Prognosefenstern mit festen vordefinierten Längen. Mithilfe des Hyperparameters context_length wird festgelegt, wie weit in die Vergangenheit das Netzwerk blicken kann. Ebenso wird mit dem Parameter ForecastHorizon festgelegt, wie weit in der Zukunft Prognosen gemacht werden können. Während der Schulung ignoriert Amazon Forecast Elemente im Schulungs-Dataset mit Zeitreihen, die kürzer sind als die angegebene Prognoselänge. Das folgende Beispiel zeigt fünf Stichproben mit einer Kontextlänge (grün hervorgehoben) von 12 Stunden und einer Prognoselänge (blau hervorgehoben) von 6 Stunden, die dem Element i entnommen sind. Aus Gründen der Übersichtlichkeit haben wir die Funktionszeitreihen xi,1,t und ui,2,t ausgeschlossen.
Um saisonal bedingte Muster zu erfassen, stellt DeepAR+ automatisch verzögerte Werte (aus der vergangenen Periode) aus der Ziel-Zeitreihe bereit. In unserem Beispiel mit stündlich entnommenen Stichproben legt das Modell für jeden Zeitindex t = T die zi,t-Werte offen, die etwa ein, zwei und drei Tage in der Vergangenheit aufgetreten sind (hervorgehoben in Pink).
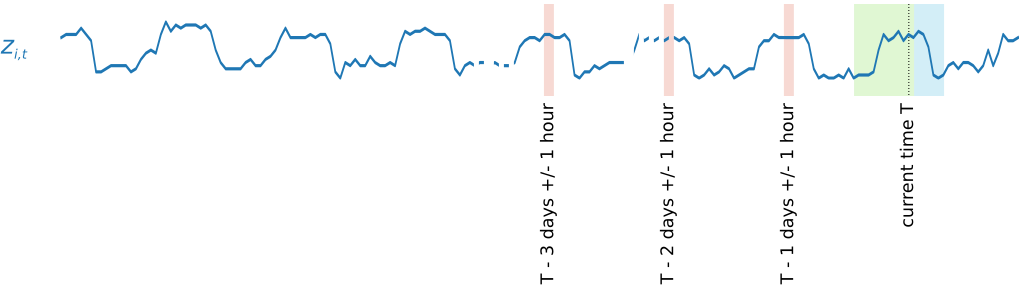
Bei der Inferenz zieht das geschulte Modell die Ziel-Zeitreihe als Eingabe heran (diese kann während der Schulung genutzt worden sein) und generiert eine Prognose mit einer Wahrscheinlichkeitsverteilung für die nächsten ForecastHorizon Werte. Da DeepAR+ mit dem gesamten Dataset geschult wurde, werden bei der Prognose erlernte Muster aus ähnlichen Zeitreihen berücksichtigt.
Weitere Informationen zur Mathematik hinter DeepAR+ finden Sie unter DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks
DeepAR+-Hyperparameter
In der folgenden Tabelle werden die Hyperparameter aufgeführt, die Sie im DeepAR+-Algorithmus verwenden können. Fettgedruckte Parameter sind Teil der Hyperparameter-Optimierung (HPO).
| Name des Parameters | Beschreibung |
|---|---|
context_length |
Die Anzahl der Zeitpunkte, die das Modell einliest, bevor die Prognose erfolgt. Der Wert für diesen Parameter sollte in etwa
|
epochs |
Die maximale Anzahl von Durchläufen der Schulungsdaten. Der optimale Wert hängt von Ihrer Datengröße und Lernrate ab. Kleinere Datensätze und niedrigere Lernraten erfordern mehr Epochen, um gute Ergebnisse zu erzielen.
|
learning_rate |
Die Lernrate in des Trainings.
|
learning_rate_decay |
Die Rate, mit der die Lernrate abnimmt. Die Lernrate wird höchstens
|
likelihood |
Das Modell generiert eine probabilistische Prognose und liefert Quantile für Verteilung und Rückgabe der Stichprobe. Wählen Sie abhängig von Ihren Daten eine geeignete Wahrscheinlichkeit (Stördatenmodell) aus, die für Unsicherheitsschätzungen verwendet wird. Zulässige Werte
|
max_learning_rate_decays |
Dieser Wert gibt an, wie oft die Lernrate maximal reduziert wird.
|
num_averaged_models |
In DeepAR+ kann ein Schulungs-Zielpfad auf mehrere Modelle stoßen. Jedes dieser Modelle hat unterschiedliche Stärken und Schwächen beim Erstellen von Prognosen. DeepAR+ kann für das Verhalten des Modells Durchschnittswerte berechnen, um die Stärken aller Modelle zu nutzen.
|
num_cells |
Die Anzahl von Zellen, die in den ausgeblendeten Layern des rekurrenten neuronalen Netzwerks (RNN) verwendet werden sollen.
|
num_layers |
Die Anzahl von ausgeblendeten Layers im RNN.
|
Optimieren der DeepAR+-Modelle
Befolgen Sie zur Optimierung von Amazon Forecast DeepAR+-Modellen diese Empfehlungen zur Optimierung des Schulungsprozesses und der Hardwarekonfiguration.
Bewährte Methoden für die Prozessoptimierung
Befolgen Sie diese Empfehlungen, um optimale Ergebnisse zu erzielen:
-
Geben Sie, außer Sie teilen die Schulungs- und Test-Datasets auf, für Schulungen und Tests sowie beim Abruf des Modells für Ableitungen immer die gesamte Zeitreihe an. Unabhängig davon, welchen Wert Sie für
context_lengthfestlegen, sollten Sie die Zeitreihe nicht aufteilen oder nur teilweise angeben. Das Modell verwendet für verzögerte Werte auch Datenpunkte, die weiter zurückliegen alscontext_length. -
Sie können das Dataset für die Modelloptimierung in Schulungs- und Test-Datasets aufteilen. In einem typischen Auswertungsszenario sollten Sie das Modell mit derselben Zeitreihe testen, die Sie für die Schulung verwendet haben, jedoch mit den künftigen
ForecastHorizonZeitpunkten direkt nach dem letzten während der Schulung sichtbaren Zeitpunkt. Verwenden Sie zum Erstellen von Schulungs- und Test-Datasets, die diese Kriterien erfüllen, das gesamte Dataset (alle Zeitreihen) als Test-Dataset und entfernen Sie die letztenForecastHorizon-Punkte für jede Zeitreihe zur Schulung. Auf diese Weise sieht das Modell während der Schulung die Zielwerte für die Zeitpunkte nicht, die für die Auswertung während des Tests verwendet werden. In der Testphase werden die letztenForecastHorizon-Punkte jeder Zeitreihe im Test-Dataset zurückgehalten, danach wird die Prognose generiert. Die Prognose wird mit den tatsächlichen Werten für die letztenForecastHorizon-Punkte verglichen. Indem Sie Zeitreihen im Test-Dataset mehrmals wiederholen, aber an unterschiedlichen Endpunkten abschneiden, können Sie noch komplexere Auswertungen durchführen. Hierdurch erhalten Sie Genauigkeitsmetriken, die auf Durchschnittswerten über mehrere Prognosen von verschiedenen Zeitpunkten hinweg basieren. -
Verwenden Sie für
ForecastHorizonkeine extrem hohen Werte (>400), da dadurch das Modell verlangsamt und ungenauer wird. Wenn Sie Prognosen für einen Zeitpunkt weiter in der Zukunft erstellen wollen, sollten Sie Daten für eine höhere Häufigkeit aggregieren. Verwenden Sie z. B.5minstatt1min. -
Aufgrund der Verzögerungen kann das Modell weiter zurückblicken als
context_length. Daher müssen Sie diesen Parameter nicht auf einen hohen Wert setzen. Ein guter Ausgangspunkt für diesen Parameter ist derselbe Wert wie fürForecastHorizon. -
Schulen Sie DeepAR+-Modelle mit möglichst vielen verfügbaren Zeitreihen. Ein DeepAR+-Modell kann auch mit nur einer einzelnen Zeitreihe sehr gut geschult werden, jedoch sind Standardprognosemethoden wie ARIMA oder ETS für solche Anwendungsfälle genauer und besser geeignet. DeepAR+ erzielt erst dann bessere Ergebnisse als die Standardmethoden, wenn das Dataset hunderte von Funktionszeitreihen enthält. Derzeit erfordert DeepAR+, dass die Gesamtanzahl der Beobachtungen, die in allen Schulungszeitreihen verfügbar sind, mindestens 300 beträgt.
