Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Konfigurieren Sie den Datenaufbewahrungsablauf
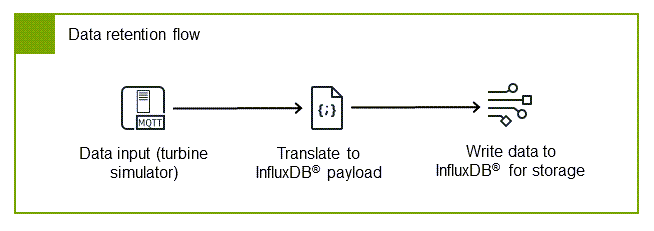
Der Datenaufbewahrungsablauf kann verwendet werden, um die betriebliche Transparenz am Netzwerkrand aufrechtzuerhalten. Dies ist nützlich bei Netzwerkunterbrechungen oder wenn Sie sofortigen Zugriff auf Ihre Daten benötigen. Dieser Flow abonniert den MQTT-Broker für den Empfang von Gerätedaten, konvertiert sie in das InfluxDB® -Format und speichert sie lokal. Durch die Implementierung dieses Flows erstellen Sie einen belastbaren lokalen Datenspeicher, auf den Betreiber ohne Cloud-Abhängigkeiten zugreifen können, was eine Überwachung und Entscheidungsfindung in Echtzeit am Netzwerkrand ermöglicht.
Der Datenfluss besteht aus drei wichtigen Komponenten, die zusammenarbeiten, um sicherzustellen, dass Ihre Daten ordnungsgemäß erfasst und gespeichert werden:
-
MQTT-Abonnement-Client — Empfängt Daten vom Broker und stellt so sicher, dass Sie alle relevanten Industriedaten erfassen
-
InfluxDB-Übersetzer — Konvertiert AWS IoT SiteWise Nutzdaten in das InfluxDB-Format und bereitet die Daten für eine effiziente Speicherung von Zeitreihen vor
-
InfluxDB-Writer — Verwaltet den lokalen Speicher und stellt so die Datenpersistenz und Verfügbarkeit für lokale Anwendungen sicher
Richten Sie den MQTT-Abonnement-Client ein
-
Konfigurieren Sie den MQTT-Abonnement-Client in Node-RED so, dass er Daten vom MQTT EMQX-Broker empfängt, indem Sie das folgende Beispiel importieren. AWS IoT SiteWise
Beispiel : MQTT im Knoten
[ { "id": "string", "type": "mqtt in", "z": "string", "name": "Subscribe to MQTT broker", "topic": "/Renton/WindFarm/Turbine/WindSpeed", "qos": "1", "datatype": "auto-detect", "broker": "string", "nl": false, "rap": true, "rh": 0, "inputs": 0, "x": 290, "y": 340, "wires": [ [ "string" ] ] }, { "id": "string", "type": "mqtt-broker", "name": "emqx", "broker": "127.0.0.1", "port": "1883", "clientid": "", "autoConnect": true, "usetls": false, "protocolVersion": "5", "keepalive": 15, "cleansession": true, "autoUnsubscribe": true, "birthTopic": "", "birthQos": "0", "birthPayload": "", "birthMsg": {}, "closeTopic": "", "closePayload": "", "closeMsg": {}, "willTopic": "", "willQos": "0", "willPayload": "", "willMsg": {}, "userProps": "", "sessionExpiry": "" } ]
Dieses Abonnement stellt sicher, dass alle relevanten Daten, die auf dem Broker veröffentlicht werden, für die lokale Speicherung erfasst werden, sodass Sie eine vollständige Aufzeichnung Ihrer industriellen Abläufe erhalten. Der Knoten verwendet dieselben MQTT-Verbindungsparameter wie der Konfigurieren Sie den MQTT-Publisher Abschnitt mit den folgenden Abonnementeinstellungen:
-
Thema —
/Renton/WindFarm/Turbine/WindSpeed -
QoS —
1
Weitere Informationen finden Sie in der Node-REDDokumentation unter Connect zu einem MQTT-Broker
Konfigurieren Sie den InfluxDB-Übersetzer
InfluxDB organisiert Daten mithilfe von Tags für die Indizierung und Feldern
-
Tags — Qualitäts- und Namenseigenschaften für eine effiziente Indexierung
-
Felder — Zeitstempel (in Millisekunden seit der Epoche) und Wert
Beispiel : Funktionsknoten für die Übersetzung in eine InfluxDB-Nutzlast
[ { "id": "string", "type": "function", "z": "string", "name": "Translate to InfluxDB payload", "func": "let data = msg.payload;\n\nlet timeInSeconds = data.propertyValues[0].timestamp.timeInSeconds;\nlet offsetInNanos = data.propertyValues[0].timestamp.offsetInNanos;\nlet timestampInMilliseconds = (timeInSeconds * 1000) + (offsetInNanos / 1000000);\n\nmsg.payload = [\n {\n \"timestamp(milliseconds_since_epoch)\": timestampInMilliseconds,\n \"value\": data.propertyValues[0].value.doubleValue\n },\n {\n \"name\": data.propertyAlias,\n \"quality\": data.propertyValues[0].quality\n }\n]\n\nreturn msg", "outputs": 1, "timeout": "", "noerr": 0, "initialize": "", "finalize": "", "libs": [], "x": 560, "y": 340, "wires": [ [ "string" ] ] } ]
Zusätzliche Konfigurationsoptionen finden Sie node-red-contrib-influxdb
Richten Sie den InfluxDB-Writer ein
Der InfluxDB-Writer-Knoten ist die letzte Komponente in Ihrem Datenaufbewahrungsablauf, der für die Speicherung Ihrer Industriedaten in der lokalen InfluxDB-Datenbank verantwortlich ist. Dieser lokale Speicher ist wichtig, um die betriebliche Transparenz bei Netzwerkunterbrechungen aufrechtzuerhalten und den sofortigen Zugriff auf Daten für zeitkritische Anwendungen zu ermöglichen.
-
Installieren Sie das node-red-contrib-influxdb Paket über die Option Palette verwalten. Dieses Paket enthält die notwendigen Knoten für die Verbindung von Node-RED mit InfluxDB.
-
Fügen Sie Ihrem Flow einen InfluxDB-Ausgangsknoten hinzu. Dieser Knoten übernimmt das eigentliche Schreiben von Daten in Ihre InfluxDB-Datenbank.
-
Konfigurieren Sie die Servereigenschaften, um eine sichere Verbindung zu Ihrer InfluxDB-Instanz herzustellen:
-
Version auf 2.0 setzen — Dies gibt an, dass Sie eine Verbindung zu InfluxDB v2.x herstellen, die eine andere API als frühere Versionen verwendet
-
URL setzen auf
http://127.0.0.1:8086— Dies verweist auf Ihre lokale InfluxDB-Instanz -
Geben Sie Ihr InfluxDB-Authentifizierungstoken ein. Dieses sichere Token autorisiert die Verbindung zu Ihrer Datenbank. Sie haben das Token während des Richten Sie lokalen Speicher mit InfluxDB ein Verfahrens generiert.
-
-
Geben Sie die Speicherortparameter an, um zu definieren, wo und wie Ihre Daten gespeichert werden:
-
Geben Sie den Namen Ihrer InfluxDB-Organisation ein — Die Organisation ist ein Arbeitsbereich für eine Gruppe von Benutzern, zu dem Ihre Buckets und Dashboards gehören. Weitere Informationen finden Sie unter Organisationen verwalten
in der. InfluxData Documentation -
Geben Sie den InfluxDB-Bucket an (zum Beispiel
WindFarmData) — Der Bucket entspricht einer Datenbank in herkömmlichen Systemen und dient als Container für Ihre Zeitreihendaten -
Legen Sie die InfluxDB-Messung fest (zum Beispiel
TurbineData) — Die Messung ähnelt einer Tabelle in relationalen Datenbanken, in der verwandte Datenpunkte organisiert werden
-
Anmerkung
Suchen Sie den Namen Ihrer Organisation in der linken Seitenleiste der InfluxDB-Instanz. Die Organisations-, Bucket- und Messkonzepte sind grundlegend für das Datenorganisationsmodell von InfluxDB. Weitere Informationen finden Sie in der InfluxDB-Dokumentation
Stellen Sie den Aufbewahrungsablauf bereit und überprüfen Sie ihn
Nachdem Sie alle Komponenten des Datenaufbewahrungsflusses konfiguriert haben, müssen Sie das System bereitstellen und überprüfen, ob es ordnungsgemäß funktioniert. Diese Überprüfung stellt sicher, dass Ihre Industriedaten ordnungsgemäß lokal gespeichert werden, sodass Sie sofort darauf zugreifen und sie analysieren können.
-
Connect die drei Knoten wie im Flussdiagramm zur Datenspeicherung gezeigt. Dadurch entsteht eine vollständige Pipeline vom Datenabonnement bis zum lokalen Speicher.
-
Wählen Sie Deploy, um Ihre Änderungen zu übernehmen und den Ablauf zu aktivieren. Dadurch wird der Datenerfassungs- und Speicherprozess gestartet.
-
Verwenden Sie den InfluxDB Data Explorer, um Ihre Daten abzufragen und zu visualisieren. Mit diesem Tool können Sie überprüfen, ob die Daten ordnungsgemäß gespeichert werden, und erste Visualisierungen Ihrer Zeitreihendaten erstellen.
Im Datenexplorer sollten Sie sehen können, wie Ihre Windgeschwindigkeitsmessungen im Laufe der Zeit aufgezeichnet werden, sodass bestätigt werden kann, dass die gesamte Pipeline von der Datengenerierung bis zur lokalen Speicherung ordnungsgemäß funktioniert.
Weitere Informationen finden Sie unter Abfrage im Daten-Explorer
im InfluxData Documentation.
Da sowohl der Datenveröffentlichungsfluss als auch der Datenaufbewahrungsfluss implementiert sind, verfügen Sie jetzt über ein vollständiges System, das Daten an die AWS IoT SiteWise Cloud sendet und gleichzeitig eine lokale Kopie beibehält, um sofortigen Zugriff und Stabilität zu gewährleisten. Dieser Dual-Path-Ansatz stellt sicher, dass Sie die Vorteile cloudbasierter Analysen und Speicher nutzen und gleichzeitig die betriebliche Transparenz am Netzwerkrand wahren.
