Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Integration von Amazon OpenSearch Ingestion-Pipelines mit anderen Services und Anwendungen
Um Daten erfolgreich in eine Amazon OpenSearch Ingestion-Pipeline aufzunehmen, müssen Sie Ihre Client-Anwendung (die Quelle) so konfigurieren, dass sie Daten an den Pipeline-Endpunkt sendet. Ihre Quelle könnten Clients wie Fluent Bit Logs, der OpenTelemetry Collector oder ein einfacher S3-Bucket sein. Die genaue Konfiguration ist für jeden Client unterschiedlich.
Die wichtigsten Unterschiede bei der Quellkonfiguration (im Vergleich zum direkten Senden von Daten an eine OpenSearch Dienstdomäne oder eine OpenSearch serverlose Sammlung) sind der AWS Dienstname (osis) und der Host-Endpunkt, der der Pipeline-Endpunkt sein muss.
Aufbau des Aufnahmeendpunkts
Um Daten in eine Pipeline aufzunehmen, senden Sie sie an den Aufnahmeendpunkt. Um die Aufnahme-URL zu finden, navigieren Sie zur Seite mit den Pipeline-Einstellungen und kopieren Sie die Aufnahme-URL.
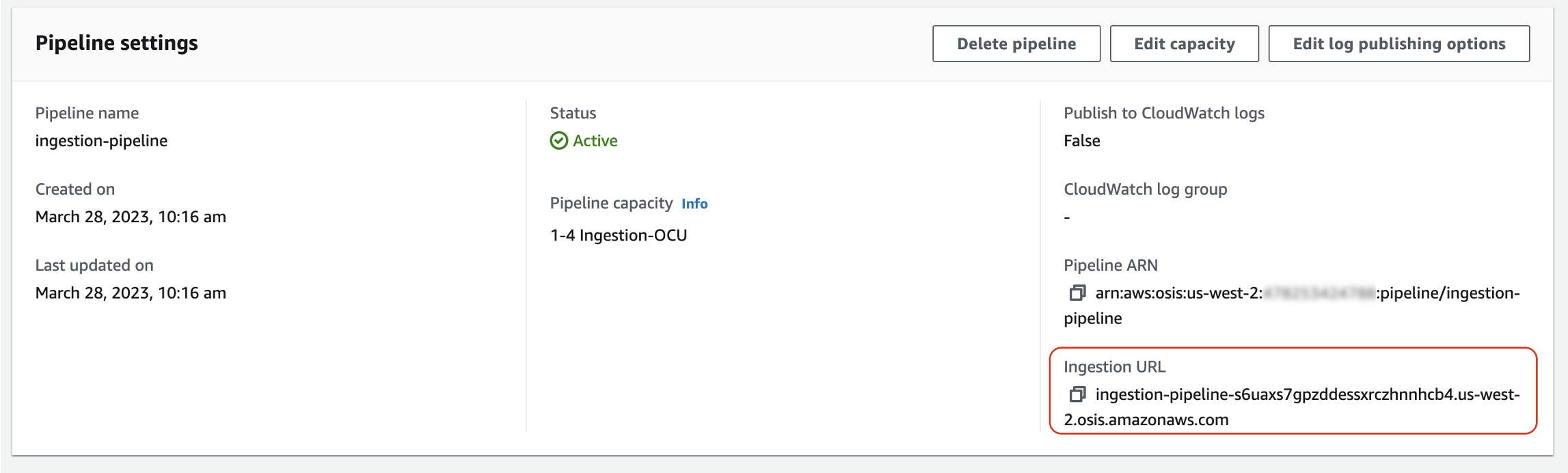
Um den vollständigen Aufnahmeendpunkt für pullbasierte Quellen wie OTel Trace
Nehmen wir zum Beispiel an, dass Ihre Pipeline-Konfiguration den folgenden Aufnahmepfad hat:

Der vollständige Aufnahmeendpunkt, den Sie in Ihrer Client-Konfiguration angeben, hat das folgende Format:. https://ingestion-pipeline-abcdefg.us-east-1.osis.amazonaws.com/my/test_path
Eine Aufnahmerolle erstellen
Alle Anfragen zur OpenSearch Datenerfassung müssen mit Signature Version 4 signiert sein. Der Rolle, die die Anfrage signiert, muss mindestens die Berechtigung für die osis:Ingest Aktion erteilt werden, sodass sie Daten an eine OpenSearch Ingestion-Pipeline senden kann.
Die folgende AWS Identity and Access Management (IAM-) Richtlinie ermöglicht es der entsprechenden Rolle beispielsweise, Daten an eine einzelne Pipeline zu senden:
Anmerkung
Um die Rolle für alle Pipelines zu verwenden, ersetzen Sie den ARN im Resource Element durch einen Platzhalter (*).
Bereitstellung von kontenübergreifendem Zugriff auf Datenerfassung
Anmerkung
Sie können kontenübergreifenden Zugriff auf die Erfassung nur für öffentliche Pipelines bereitstellen, nicht für VPC-Pipelines.
Möglicherweise müssen Sie Daten von einem anderen Konto in eine Pipeline aufnehmen AWS-Konto, z. B. von einem Konto, in dem Ihre Quellanwendung gespeichert ist. Wenn sich der Principal, der in eine Pipeline schreibt, in einem anderen Konto befindet als die Pipeline selbst, müssen Sie den Principal so konfigurieren, dass er einer anderen IAM-Rolle vertraut, um Daten in die Pipeline aufzunehmen.
Um kontoübergreifende Aufnahmeberechtigungen zu konfigurieren
-
Erstellen Sie die Aufnahmerolle mit der entsprechenden
osis:IngestBerechtigung (im vorherigen Abschnitt beschrieben) innerhalb derselben Pipeline. AWS-Konto Anweisungen finden Sie unter IAM-Rollen erstellen. -
Fügen Sie der Aufnahmerolle eine Vertrauensrichtlinie hinzu, die es einem Principal in einem anderen Konto ermöglicht, sie zu übernehmen:
-
Konfigurieren Sie in dem anderen Konto Ihre Client-Anwendung (z. B. Fluent Bit) so, dass sie die Aufnahmerolle übernimmt. Damit dies funktioniert, muss das Anwendungskonto dem Anwendungsbenutzer oder der Rolle der Anwendung die Berechtigungen zur Übernahme der Aufnahmerolle gewähren.
Das folgende Beispiel für eine identitätsbasierte Richtlinie ermöglicht es dem angehängten Prinzipal,
ingestion-rolevom Pipeline-Konto auszugehen:
Die Client-Anwendung kann dann den AssumeRoleVorgang verwenden, um Daten anzunehmen ingestion-role und in die zugehörige Pipeline aufzunehmen.
Nächste Schritte
Nachdem Sie Ihre Daten in eine Pipeline exportiert haben, können Sie sie von der OpenSearch Service-Domäne abfragen, die als Senke für die Pipeline konfiguriert ist. Die folgenden Ressourcen können Ihnen den Einstieg erleichtern:
