Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Phase der Verarbeitung
Amazon Textract extrahiert PDF-Dateiinhalte als Zeichenketten, die nicht direkt von nachgelagerten Anwendungen verwendet werden können (z. B. um Statistiken durch Aggregieren von Zahlen zu generieren). Korrekt identifizierte und transformierte Datenwerte sind erforderlich, da sie von Ihren nachgelagerten Anwendungen einfacher verwendet werden können (z. B. um Kostentrends als Zeitreihe darzustellen). Um die Verarbeitung von PDF-Dateien zu implementieren, muss eine PDF-Datei von jedem neuen PDF-Dateityp einmalig über Amazon Textract verarbeitet werden, das dann eine Datei im Template JSON-Format generiert.
Nachdem die AWS Lambda Funktion in der gestartet wurdePhase der Einnahme, führt sie die in der folgenden Abbildung gezeigten Schritte aus.
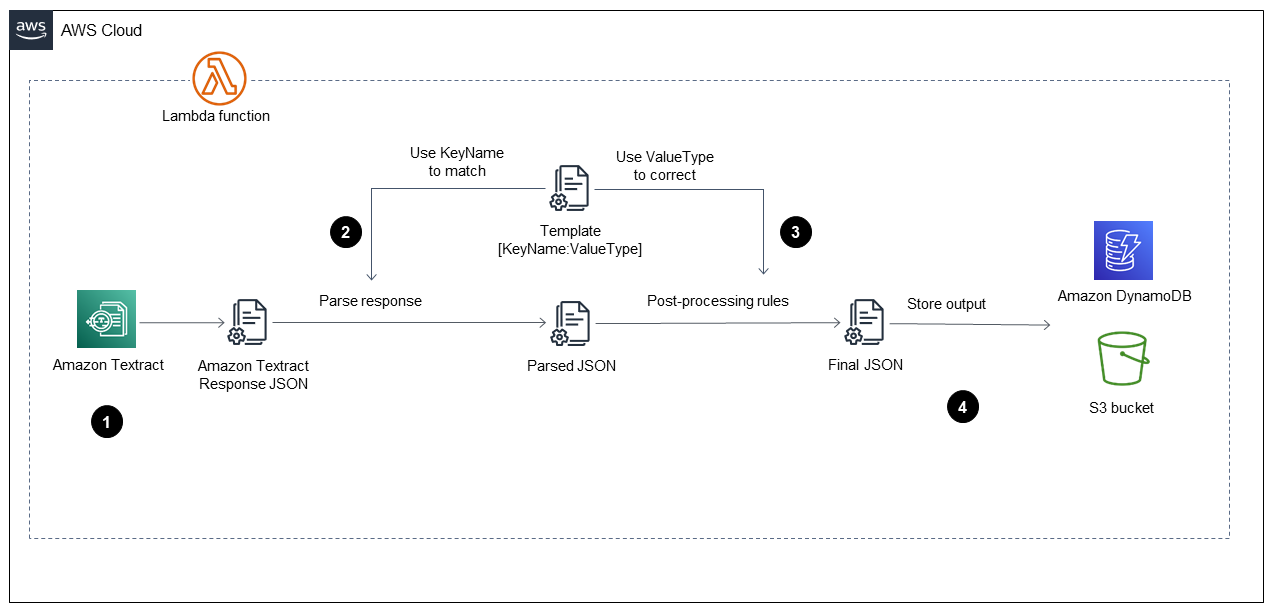
Das Diagramm zeigt, wie die Lambda-Funktion die folgenden Schritte implementiert:
-
Ruft Amazon Textract auf, um die PDF-Datei zu verarbeiten, den Inhalt zu extrahieren und eine Datei im JSON-Format zurückzugeben.
-
Nimmt die JSON-Datei und analysiert Formulare und Tabellen mithilfe einer vordefinierten
TemplateJSON-Datei, die für jedes Feld den richtigen Schlüsselnamen und Wertetyp hat. Dieser Prozess stellt eine geparste JSON-Datei bereit. -
Wendet die Nachverarbeitungsregeln an und verwendet die
TemplateJSON-Datei, um jeden Wert in der geparsten JSON-Datei zu korrigieren. Dadurch wird dieFinalJSON-Datei erzeugt. Die vordefinierteTemplateJSON-Datei kann im S3-Bucket gespeichert werden. -
Speichert die
FinalJSON-Datei in Amazon DynamoDB als einen Datensatz für jede PDF-Datei, zusätzlich zu einer JSON-Datei für jede PDF-Datei in einem S3-Ausgabe-Bucket.
Informationen zu einem step-by-step Workflow, der Amazon Textract verwendet, um Inhalte automatisch aus PDF-Dateien zu extrahieren und zu einer sauberen Ausgabe zu verarbeiten, finden Sie im Muster Automatisches Extrahieren von Inhalten aus PDF-Dateien mithilfe von Amazon Textract auf der AWS Prescriptive Guidance-Website. Das Muster verwendet ein Verfahren zum Abgleich von Vorlagen, um das erforderliche Feld, den Schlüsselnamen und die Tabellen korrekt zu identifizieren, und wendet dann die Nachbearbeitungskorrekturen auf jeden Datentyp an.
Bewährte Methoden für die Verarbeitungsphase
Verwenden Sie die folgenden vier bewährten Methoden, um eine erfolgreiche Verarbeitungsphase sicherzustellen:
-
Erstellen Sie eine JSON-Vorlagendatei für jeden PDF-Dateityp, den Sie verarbeiten möchten. Sie können diese verschiedenen JSON-Vorlagendateien in einem S3-Bucket speichern, der von der Lambda-Funktion aufgerufen wird. Wenn Sie verschiedene PDF-Dateitypen in einer Lambda-Funktion verarbeiten möchten, sollten Sie für jeden PDF-Dateityp eine eindeutige Kennung verwenden (z. B. den Ordnernamen des PDF-Dateityps im S3-Bucket). Nachdem die Lambda-Funktion aufgerufen wurde, ruft sie die entsprechende JSON-Vorlagendatei ab und verarbeitet sie.
-
Richten Sie einen Mechanismus ein, um den Status jedes Schritts in der Lambda-Funktion genau zu verfolgen. Sie könnten beispielsweise
SuccessStatus für die Zeit nach dem Amazon Textract Textract-Aufruf hinzufügen, wenn die endgültige JSON-Datei in einer Amazon DynamoDB-Tabelle gespeichert wird oder wenn die PDF-Dateien in einem S3-Bucket gespeichert werden. Sie können auch eine separate DynamoDB-Tabelle erstellen, um den Status jeder PDF-Datei in den verschiedenen Schritten zu verfolgen, was einen Einblick in den Prozess bietet. -
Managen Sie Drosselungen und Verbindungsabbrüche, indem Sie fehlgeschlagene Vorgänge automatisch wiederholen, wenn Sie viele PDF-Dateien stapelweise verarbeiten. In Amazon Textract kann es zu einer Drosselung kommen, wenn Ihre Verbindung unterbrochen wird oder Sie die maximale Anzahl von Transaktionen pro Sekunde (TPS) überschreiten. Weitere Informationen und Schritte zur automatischen Wiederholung fehlgeschlagener Vorgänge finden Sie unter Umgang mit gedrosselten Anrufen und Verbindungsabbrüchen in der Amazon Textract Textract-Dokumentation.
-
Wenn Sie PDF-Dateien mit mehreren Seiten haben, können Sie entweder einen asynchronen Vorgang verwenden, um die gesamte Datei zu verarbeiten, oder Sie können die PDF-Datei in eine einzelne Seite aufteilen, eine synchrone Operation verwenden, um jede Seite zu verarbeiten, und dann die Ergebnisse jeder Seite kombinieren. Eine vollständige Codeimplementierung eines asynchronen Vorgangs finden Sie unter Erkennen und Analysieren von Text in mehrseitigen Dokumenten in der Amazon Textract Textract-Dokumentation. Weitere Informationen zur Verwendung eines synchronen Vorgangs finden Sie unter Erkennen und Analysieren von Text in einseitigen Dokumenten in der Amazon Textract Textract-Dokumentation.
