Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Datenkonsumenten
Datenkonsumenten konsumieren die Daten vom Datenproduzenten, nachdem sie vom zentralen Katalog gemeinsam genutzt wurden AWS Lake Formation. Das folgende Diagramm zeigt zwei Datenverbraucher im Data Lake.
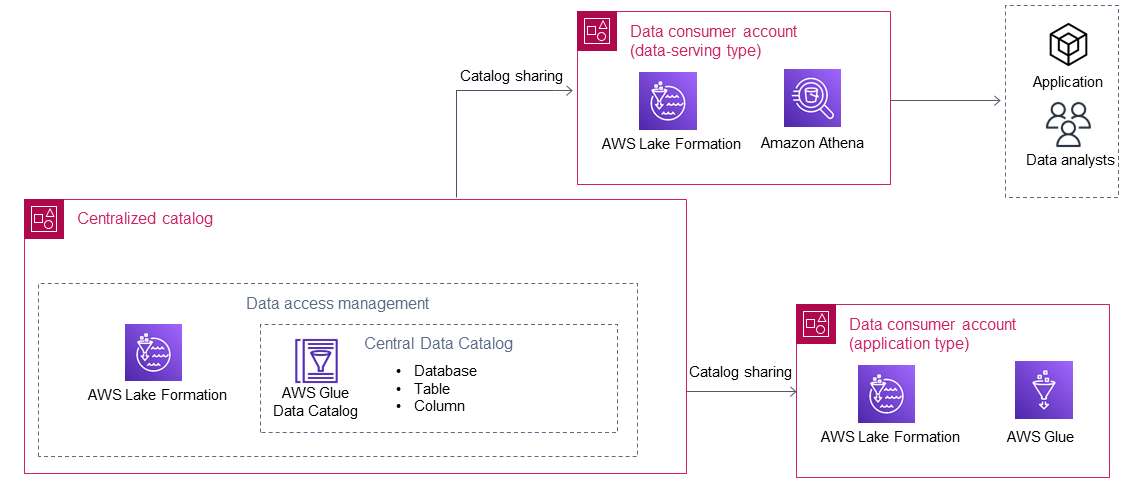
Es gibt zwei Arten von Datenkonsumenten: Anwendung und Datenbereitstellung. In der folgenden Tabelle werden diese beiden Typen beschrieben.
| Art der Anwendung |
Nutzer von Anwendungsdaten führen Anwendungen eigenständig aus AWS-Konten. Die Anwendungen nutzen die AWS Identity and Access Management (IAM-) Rollen, um auf die gemeinsam genutzten Daten eines Datenproduzenten zuzugreifen und sie dann entsprechend ihrer Logik zu verarbeiten. Typischerweise hat diese Art von Datenkonsumenten vorgeschriebene Datenanforderungen, um die Anforderungen einer Anwendung zu erfüllen. |
| Typ der Datenbereitstellung |
Nutzer von Daten, die Daten bereitstellen, sind in der Regel für Einzelpersonen (z. B. Datenanalysten oder Datenwissenschaftler) und Anwendungen (z. B. eine Business Intelligence-Anwendung) gedacht, die keine eigenen haben. AWS-Konten Im Data Lake eines Unternehmens können mehrere datenverarbeitende Datenverbraucher existieren. Beispielsweise könnten sich verschiedene Geschäftsbereiche dafür entscheiden, ihre eigenen Datenverbraucher einzurichten, um Benutzern zu helfen, Daten aus dem Data Lake zu nutzen. Für diese Datenverbraucher sind eigene IAM-Rollenprinzipale konfiguriert AWS-Konto (z. B. zugeordnete IAM-Rollen AWS IAM Identity Center), die von Endbenutzern im Datenverbraucherkonto für den Zugriff auf gemeinsam genutzte Daten über AWS Dienste (z. B. Amazon Athena) verwendet werden. Typischerweise hat diese Art von Datenkonsumenten weitreichende und kontinuierlich steigende Datenanforderungen. |
AWS Lake Formation ist der wichtigste AWS Dienst, der von einem Datenverbraucher für die kontenübergreifende gemeinsame Nutzung von Daten und den Zugriff auf den zentralen Katalog genutzt wird. Nachdem die Datenbanken vom zentralisierten Katalog gemeinsam genutzt wurden, sind die gemeinsam genutzten Ressourcen in Lake Formation im Datenverbraucherkonto verfügbar. Der Datenzugriff kann dann den lokalen IAM-Prinzipalen im Datenverbraucherkonto gewährt werden, sofern erforderlich, mit Genehmigung des Datenproduzenten. Die gemeinsam genutzten Daten können dann von AWS Diensten verwendet werden, die in Lake Formation integriert sind (z. B. Amazon Athena und AWS Glue). Sie können die folgenden AWS Dienste verwenden, um auf gemeinsam genutzte Daten im Datenverbraucherkonto zuzugreifen:
-
Amazon Athena ist ein interaktiver Abfrageservice, mit dem Daten in Amazon Simple Storage Service (Amazon S3) mithilfe von Standard-SQL direkt analysiert werden können. Weitere Informationen zu Athena und Lake Formation finden Sie in der Amazon Athena-Dokumentation unter So greift Athena auf bei Lake Formation registrierte Daten zu.
-
Amazon Redshift Spectrum hilft Ihnen dabei, strukturierte und halbstrukturierte Daten effizient aus Dateien in Amazon S3 abzufragen und abzurufen, ohne die Daten in Amazon Redshift Redshift-Tabellen laden zu müssen. Weitere Informationen zu Redshift Spectrum und Lake Formation finden Sie unter Using Redshift Spectrum with Lake Formation in der Amazon Redshift Redshift-Dokumentation.
-
AWS Glueist ein vollständig verwalteter ETL-Service (Extrahieren, Transformieren und Laden), mit dem Sie Ihre Daten einfach und kostengünstig kategorisieren, bereinigen, anreichern und zuverlässig zwischen verschiedenen Datenspeichern und Datenströmen verschieben können. Die einem AWS Glue ETL-Job zugeordnete IAM-Rolle kann auf die von Lake Formation verwalteten Data Lake-Daten zugreifen, sofern sie über die erforderlichen Zugriffsberechtigungen verfügt.
-
Amazon EMR unterstützt den Betrieb von Big-Data-Frameworks (z. B. Apache Hadoop
und Apache Spark ) zur Verarbeitung und Analyse großer Datenmengen. Weitere Informationen zu Amazon EMR und Lake Formation finden Sie unter Integrieren von Amazon EMR in Lake Formation in der Amazon EMR-Dokumentation. -
Amazon QuickSight ist ein skalierbarer, serverloser, einbettbarer und auf maschinellem Lernen (ML) basierender Business Intelligence-Service, mit dem Sie Daten aus Ihrem Data Lake analysieren und visualisieren können. Weitere Informationen zu QuickSight Lake Formation finden Sie in der QuickSight Dokumentation unter Autorisieren von Verbindungen über Lake Formation.
-
Amazon SageMaker AI Data Wrangler (Data Wrangler) reduziert den Zeitaufwand für die Aggregation und Vorbereitung von Daten für ML. Weitere Informationen zu Data Wrangler und Lake Formation finden Sie unter Vorbereiten von ML-Daten mit Amazon SageMaker AI Data Wrangler in der Amazon AI-Dokumentation. SageMaker
