Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Onboarding und Zugangsgewährung
Die Data-Lake-Referenzarchitektur dieses Leitfadens hilft Ihnen dabei, Datenproduzenten und Datenkonsumenten unabhängig voneinander zu skalieren und einen konsistenten Prozess für das Onboarding und die Gewährung des Zugriffs für diese Datenkonsumenten zu definieren und einzurichten.
In den folgenden Abschnitten wird der Onboarding-Prozess für Datenproduzenten und Datenkonsumenten sowie die Gewährung des Zugriffs über ein Datenverbraucherkonto beschrieben. In diesem Handbuch wird die Methode der benannten Ressource zwischen dem zentralisierten Katalog und den Datenverbrauchern verwendet. Das Verfahren für die LF-TBAC-Methode ist ähnlich, unterscheidet sich jedoch geringfügig. Wir empfehlen Ihnen, diese Ansätze zu evaluieren und zu konfigurieren, damit sie den Datenverwaltungspraktiken und -richtlinien Ihres Unternehmens entsprechen.
Weitere Informationen zu diesen beiden Methoden finden Sie im Zentralisierter Katalog Abschnitt dieses Handbuchs.
Onboarding von Datenproduzenten
Das folgende Diagramm zeigt, wie Sie einen neuen Datenproduzenten in Ihren Data Lake integrieren.
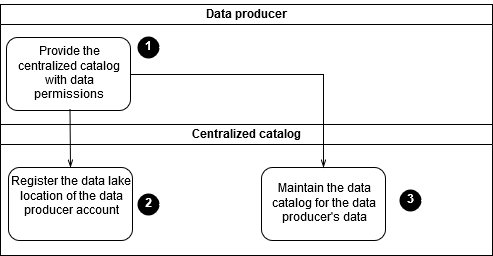
Das Diagramm zeigt den folgenden Onboarding-Prozess:
-
Der Datenproduzent gewährt dem zentralisierten Katalog selektiv Zugriff auf seine Daten (z. B. einen Amazon Simple Storage Service (Amazon S3) -Bucket und AWS KMS key). Den Principals des zentralisierten Katalogs AWS Identity and Access Management (IAM) wird Zugriff gewährt, um den Data Lake-Standort des Datenproduzenten zu registrieren, AWS Lake Formation sowie die IAM-Prinzipale, die zur Verwaltung des Katalogs des Datenproduzenten verwendet werden.
-
Registrieren Sie den Data Lake-Standort des Datenproduzenten (z. B. einen S3-Bucket), der die Lake Formation des zentralisierten Katalogs verwendet.
-
Erstellen Sie die Datenbank, Tabellen und Tabellenschemas für die neuen Daten aus dem Datenproduzenten im AWS Glue Datenkatalog.
Einbindung von Datennutzern
Das folgende Diagramm zeigt, wie Sie einen neuen Datenverbraucher in Ihren Data Lake integrieren können.
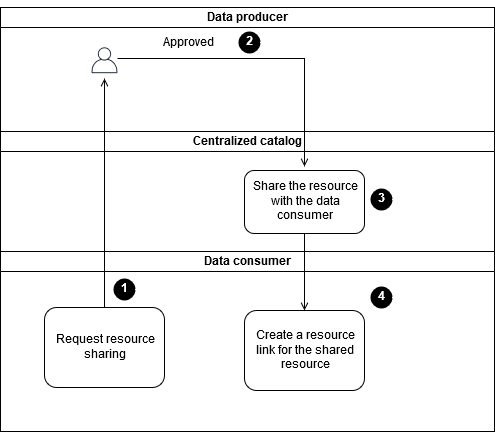
Das Diagramm zeigt den folgenden Onboarding-Prozess:
-
Der Datenverbraucher bittet um die Genehmigung, die Daten des Datenproduzenten einsehen zu dürfen, und gibt an, auf welche Daten er zugreifen muss.
-
Der Datenverwalter des Datenproduzenten prüft die Anfrage des Datenkonsumenten und bewertet, ob:
-
Geben Sie einige oder alle Tabellen in den angeforderten Datenbanken frei. Wir empfehlen die gemeinsame Nutzung auf Datenbankebene, wenn die gemeinsame Nutzung aller Tabellen für den Datenverbraucher keine Auswirkungen auf die Datensicherheit hat, wodurch der Verwaltungsaufwand vermieden wird, der durch die gemeinsame Nutzung auf Tabellenebene entsteht.
-
Teilen Sie Daten auf Organisations-, OU- oder Kontoebene des Datennutzers.
-
-
Nach der Genehmigung durch den Datenproduzenten werden die erforderlichen Datenkatalogressourcen im zentralisierten Katalog gemeinsam mit dem Datenverbraucher genutzt.
-
Ressourcenlinks können mithilfe von Lake Formation im Konto des Datenverbrauchers erstellt werden und dann auf die gemeinsam genutzten Datenkatalogressourcen im zentralen Katalog verweisen.
Nach Abschluss des Onboarding-Vorgangs kann der Lake Formation-Administrator des Datenkonsumenten die Datenbankkatalogressource im zentralen Katalog und im Ressourcenlink sehen. Zu diesem Zeitpunkt kann niemand anderes Mitglied des Kontos des Datenkonsumenten auf die Daten des Datenproduzenten zugreifen.
Gewähren Sie Select-Zugriff in einem Datenverbraucherkonto
Das folgende Diagramm zeigt den Prozess zur Gewährung des SelectZugriffs auf gemeinsam genutzte Datenressourcen mit einem lokalen IAM-Prinzipal im Datenverbraucherkonto. Der lokale IAM-Prinzipal kann die IAM-Rolle für einzelne Benutzer oder eine IAM-Rolle sein, die von bestimmten Diensten genutzt wird. AWS
Anmerkung
Wenn die gemeinsam genutzten Daten wenig sensibel sind, können Sie die Zugriffsgewährung an den Datenverbraucher selbst delegieren, ohne dass die Zustimmung des Datenproduzenten erforderlich ist. Dies liegt daran, dass zwischen ihnen bereits Vertrauen und gemeinsame Nutzung bestehen.
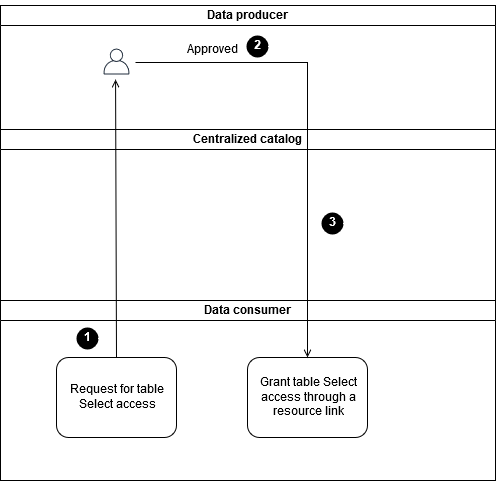
Das Diagramm zeigt den folgenden Prozess:
-
Der einzelne IAM-Prinzipal im Datenverbraucherkonto fordert vom IAM-Prinzipal im Datenverbraucherkonto
SelectZugriff auf den Ressourcenlink an. -
Der Datenverwalter des Datenproduzenten prüft die Anfrage des Datenkonsumenten und erteilt die Genehmigung, wenn alle Anforderungen erfüllt sind.
-
SelectDer Zugriff wird gewährt, sodass der IAM-Principal die angeforderten Daten nutzen kann.
