Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Bewährte Methoden für die Prognose der Nachfrage nach neuen Produkten
In diesem Abschnitt werden die folgenden bewährten Methoden für die Prognose der Nachfrage nach neuen Produkten erörtert:
Erfüllen Sie die Anforderungen an die Datenverfügbarkeit für datengestützte Nachfrageprognosen NPI
Um datengestützte Ansätze für die NPI Bedarfsprognose einzuführen, sollte Ihr Unternehmen Unterstützung von allen relevanten Interessengruppen erhalten, z. B. von Managern in den Bereichen Datenwissenschaft oder Analytik, Lieferkette, Marketing und IT. Ihr Unternehmen sollte dann Folgendes identifizieren:
-
Die Quellen vorhandener interner Daten und relevanter externer Daten
-
Die Eigentümer dieser Datenquellen
-
Die Verfahren und Genehmigungen, die erforderlich sind, um diese Datenquellen für die Initiative zu verwenden
Sie können Ihre Datenverfügbarkeit anhand der folgenden Arten von erforderlichen und optionalen Datensätzen bewerten. Durch die Verwendung so vieler Datensätze wie möglich, einschließlich der optionalen Datensätze, können Modelle für maschinelles Lernen genauere NPI Nachfrageprognosen erstellen.
Im Folgenden finden Sie Beispiele für erforderliche interne Datenquellen:
-
Vollständige Verkaufshistorie (von der Produkteinführung bis zur Einstellung) für alle Produkte oder eine Teilmenge von Produkten, die ähnliche Eigenschaften wie das neu eingeführte Produkt aufweisen. Die Verkaufshistorie kann aus mehreren Vertriebskanälen stammen oder über alle Kanäle hinweg kombiniert werden.
-
Zuordnung von Produktattributen zur Identifizierung der Teilmenge von Produkten, die ähnliche Eigenschaften wie das neue Produkt aufweisen, das auf den Markt gebracht wird.
Im Folgenden finden Sie Beispiele für optionale interne Datenquellen:
-
Marketingdaten, die Werbeaktionen und Rabatte für ähnliche Produkte verfolgen. Diese Daten sollten der Länge der Verkaufshistorie entsprechen oder diese überschreiten.
-
Produktrezensionen, Bewertungen und Web-Traffic-Daten. Diese Daten sollten mindestens der Länge der Verkaufshistorie entsprechen.
-
Demografische Daten der Verbraucher
Im Folgenden finden Sie Beispiele für optionale externe Datenquellen, die Ihre internen Daten ergänzen können:
-
Daten zum Verbraucherindex
-
Verkaufsdaten der Wettbewerber
-
Daten aus der Umfrage
Entwickeln Sie kosteneffiziente Mechanismen zur Datenerfassung
Sobald Ihre Datenbereitschaftsanforderungen erfüllt sind, kann Ihr Unternehmen die am besten geeigneten Datenerfassungs- und Datenspeichermechanismen auswählen. Wenn die wichtigsten Vertriebsdatenquellen Ihres Unternehmens täglich aus verschiedenen Kanälen erfasst werden, sollten Sie eine Batch-Datenerfassung in Betracht ziehen. Die Erfassung von Streaming-Daten ist eine weitere Option, wenn Sie Self-Service-Prognosen erstellen möchten, die von den neuesten Daten profitieren.
Die Pipeline zur Rohdatenaufnahme sollte für eine einfache Transformation eine Extraktions-, Transformations- und Load (ETL) -Pipeline verwenden. Die Pipeline sollte Datenqualitätsprüfungen durchführen und die verarbeiteten Daten zur späteren Verwendung in einer Datenbank speichern.
Sie können AWS-ServicesAmazon Data Firehose und Amazon Simple Storage Service (Amazon S3) für kostengünstige Datenaufnahme und -speicherung verwenden. AWS GlueAWS Glue Data Catalog AWS Glue ist ein vollständig verwalteter serverloser ETL Service, mit dem Sie Daten kategorisieren, bereinigen, transformieren und zuverlässig zwischen verschiedenen Datenspeichern übertragen können. Die Kernkomponenten von AWS Glue bestehen aus einem zentralen Metadaten-Repository, bekannt als AWS Glue Data Catalog, und einem ETL Jobsystem, das automatisch Python- und Scala-Code generiert und ETL Jobs verwaltet. Amazon Data Firehose unterstützt Sie beim Sammeln, Verarbeiten und Analysieren von Echtzeit-Streaming-Daten in jeder Größenordnung. Firehose kann Streaming-Daten in Echtzeit direkt an Data Lakes (wie Amazon S3), Datenspeicher und Analysedienste zur weiteren Verarbeitung liefern. Amazon S3 ist ein Objektspeicherservice, der Skalierbarkeit, Datenverfügbarkeit, Sicherheit und Leistung bietet.
Ermitteln Sie die praktikablen ML-Ansätze zur NPI Bedarfsprognose
Je nach Anwendungsfall kann Ihr Unternehmen verschiedene Prognoseoptionen in Betracht ziehen.
Ein statistischer Prognoseansatz, wie das Bass-Diffusionsmodell
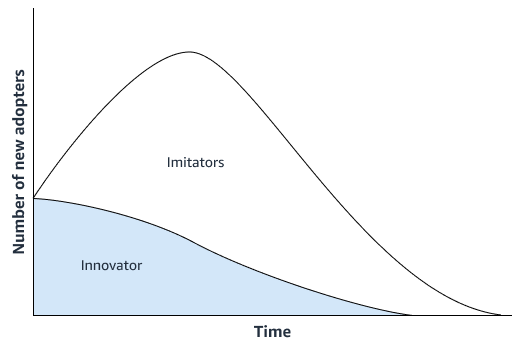
Wenn das neue Produkt keine nennenswerten Innovationen aufweist, kann Ihr Unternehmen Zeitreihen-Prognosemodelle verwenden, die auf der Verkaufshistorie des Produkts basieren, das dem neuen Produkt am ähnlichsten ist. Sie können ML-basierte Prognosealgorithmen verwenden, z. B. den Amazon SageMaker AI DeepAR-Prognosealgorithmus, der Zeitreihen-Verkaufsdaten von mehreren ähnlichen Produkten verwenden kann. Dies eignet sich gut für Kaltstart-Prognoseszenarien, wenn Sie eine Prognose für eine Zeitreihe erstellen möchten, aber nur wenige oder gar keine historischen Daten vorhanden sind. Die folgende Abbildung zeigt, wie Sie Zeitreihendaten aus verwandten Produkten verwenden können, um eine Prognose für ein neues, ähnliches Produkt zu erstellen.
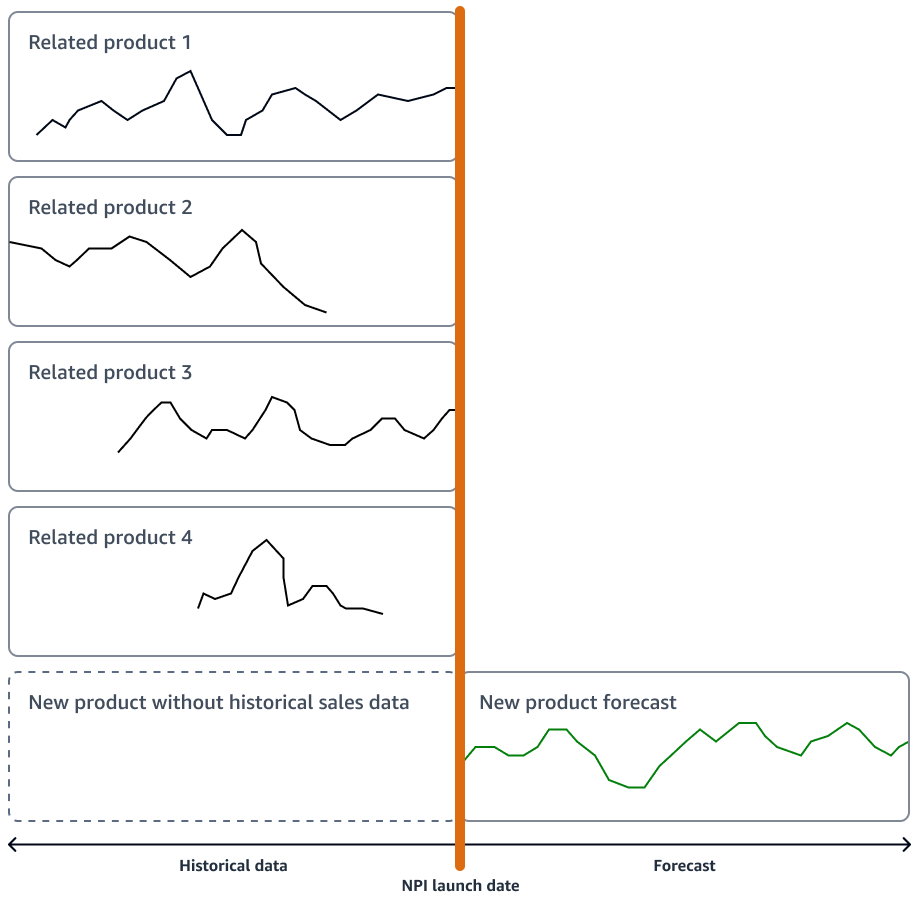
Sie sollten in Betracht ziehen, Prognosen zu erstellen, die mit Ihrem Zeitplan für die Markteinführung neuer Produkte übereinstimmen. Generieren Sie Prognosen weit im Voraus, um ausreichend Puffer für logistische Korrekturen zu haben.
Skalieren und verfolgen Sie die Auswirkungen der Prognosen
Nach Abschluss eines Machbarkeitsnachweises für die NPI Bedarfsprognose sollte die Lösung schließlich so skaliert werden, dass sie weitere Produkte und mehrere Regionen umfasst. Verwenden Sie ein Framework für künstliche Intelligenz und maschinelles Lernen (KI/ML), um Daten aufzubereiten und das Modell zu entwickeln, bereitzustellen und zu überwachen.
Das folgende Diagramm zeigt die Markteinführungs- und Skalierungsstrategie im Zuge der Weiterentwicklung der NPI Prognoselösung des Unternehmens.
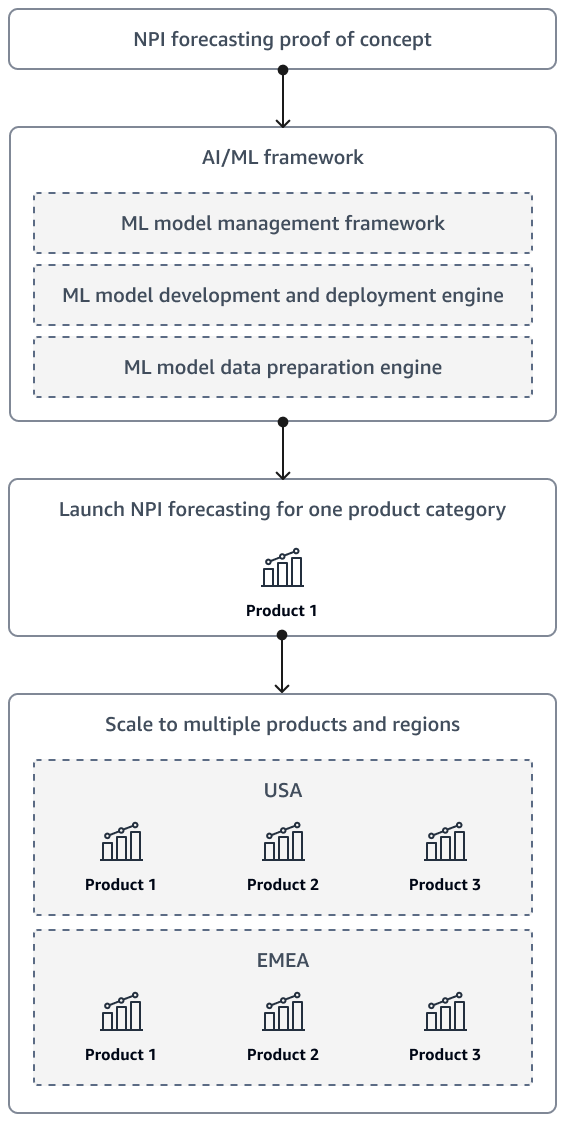
Es wird außerdem empfohlen, die Lösung so zu gestalten, dass Führungskräfte und Stakeholder Prognosen selbst erstellen können. Sie können beispielsweise QuickSightAmazon-Dashboards erstellen, damit Stakeholder bei Bedarf auf die neuesten Prognosen zugreifen können.
Überwachen Sie die Genauigkeit der Prognosen genau und untersuchen Sie Abweichungen gründlich, um eine angemessene Kapitalrendite sicherzustellen ()ROI. Wenn Sie die Modellüberwachung mit Amazon SageMaker AI Model Monitor einrichten, können Sie die Leistung Ihrer Modelle verfolgen, während sie Echtzeitvorhersagen anhand von Live-Daten treffen. Sie können das Amazon SageMaker Model Dashboard verwenden, um Modelle zu finden, die gegen die von Ihnen festgelegten Schwellenwerte für Datenqualität, Modellqualität, Verzerrung und Erklärbarkeit verstoßen. Weitere Informationen finden Sie in der Amazon SageMaker AI-Dokumentation unter Verwenden von Governance zur Verwaltung von Berechtigungen und zur Nachverfolgung der Modellleistung.
