Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Migrieren Sie Daten mithilfe DistCp von AWS PrivateLink für Amazon S3 von einer lokalen Hadoop-Umgebung zu Amazon S3
Jason Owens, Andres Cantor, Jeff Klopfenstein, Bruno Rocha Oliveira und Samuel Schmidt, Amazon Web Services
Übersicht
Dieses Muster zeigt, wie fast jede Datenmenge aus einer lokalen Apache Hadoop-Umgebung in die Amazon Web Services (AWS) -Cloud migriert werden kann, indem das Open-Source-Tool Apache DistCp
Dieses Handbuch enthält Anweisungen DistCp zur Migration von Daten in die AWS-Cloud. DistCp ist das am häufigsten verwendete Tool, es sind jedoch auch andere Migrationstools verfügbar. Sie können beispielsweise Offline-AWS-Tools wie AWS Snowball oder AWS Snowmobile oder Online-AWS-Tools wie AWS Storage Gateway oder AWS verwenden. DataSync
Voraussetzungen und Einschränkungen
Voraussetzungen
Ein aktives AWS-Konto mit einer privaten Netzwerkverbindung zwischen Ihrem lokalen Rechenzentrum und der AWS-Cloud
Ein Hadoop-Benutzer mit Zugriff auf die Migrationsdaten im Hadoop Distributed File System (HDFS)
AWS-Befehlszeilenschnittstelle (AWS CLI), installiert und konfiguriert
Berechtigungen zum Ablegen von Objekten in einen S3-Bucket
Einschränkungen
Einschränkungen der Virtual Private Cloud (VPC) gelten PrivateLink für AWS für Amazon S3. Weitere Informationen finden Sie unter Eigenschaften und Einschränkungen von Schnittstellenendpunkten und PrivateLink AWS-Kontingente ( PrivateLink AWS-Dokumentation).
AWS PrivateLink für Amazon S3 unterstützt Folgendes nicht:
Architektur
Quelltechnologie-Stack
Hadoop-Cluster mit installiertem DistCp
Zieltechnologie-Stack
Amazon S3
Amazon VPC
Zielarchitektur
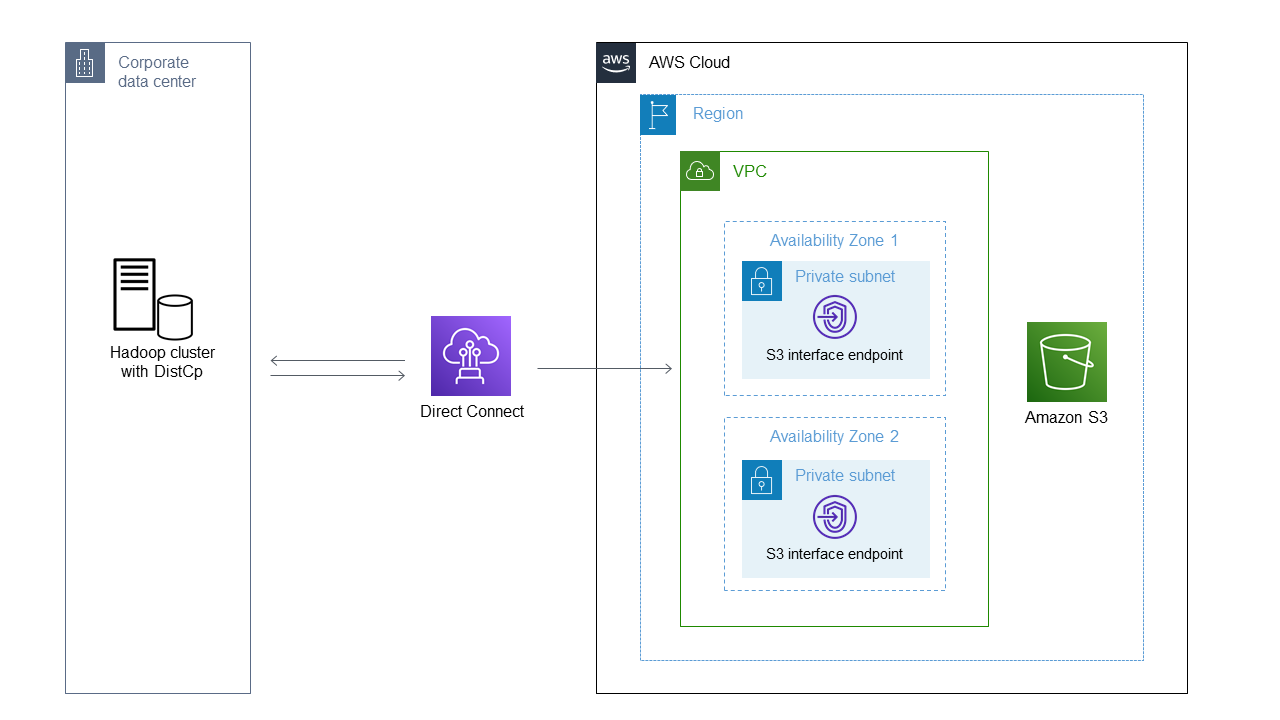
Das Diagramm zeigt, wie der DistCp Hadoop-Administrator Daten aus einer lokalen Umgebung über eine private Netzwerkverbindung wie AWS Direct Connect über einen Amazon S3-Schnittstellenendpunkt nach Amazon S3 kopiert.
Tools
AWS-Services
AWS Identity and Access Management (IAM) hilft Ihnen dabei, den Zugriff auf Ihre AWS-Ressourcen sicher zu verwalten, indem kontrolliert wird, wer authentifiziert und autorisiert ist, diese zu verwenden.
Amazon Simple Storage Service (Amazon S3) ist ein cloudbasierter Objektspeicherservice, der Sie beim Speichern, Schützen und Abrufen beliebiger Datenmengen unterstützt.
Amazon Virtual Private Cloud (Amazon VPC) hilft Ihnen, AWS-Ressourcen in einem von Ihnen definierten virtuellen Netzwerk zu starten. Dieses virtuelle Netzwerk ähnelt einem herkömmlichen Netzwerk, das Sie in Ihrem eigenen Rechenzentrum betreiben würden, mit den Vorteilen der skalierbaren Infrastruktur von AWS.
Andere Tools
Apache Hadoop DistCp
(Distributed Copy) ist ein Tool, das zum Kopieren großer Inter-Cluster und Intra-Cluster verwendet wird. DistCp verwendet Apache MapReduce für die Verteilung, Fehlerbehandlung und Wiederherstellung sowie für die Berichterstattung.
Epen
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
Erstellen Sie einen Endpunkt für AWS PrivateLink für Amazon S3. |
| AWS-Administrator |
Überprüfen Sie die Endpunkte und suchen Sie nach den DNS-Einträgen. |
| AWS-Administrator |
Überprüfen Sie die Firewall-Regeln und Routing-Konfigurationen. | Um zu überprüfen, ob Ihre Firewallregeln geöffnet sind und ob Ihre Netzwerkkonfiguration korrekt eingerichtet ist, testen Sie den Endpunkt mit Telnet auf Port 443. Zum Beispiel:
AnmerkungWenn Sie den Eintrag Regional verwenden, zeigt ein erfolgreicher Test, dass das DNS zwischen den beiden IP-Adressen wechselt, die Sie auf der Registerkarte Subnetze für Ihren ausgewählten Endpunkt in der Amazon VPC-Konsole sehen können. | Netzwerkadministrator, AWS-Administrator |
Konfigurieren Sie die Namensauflösung. | Sie müssen die Namensauflösung so konfigurieren, dass Hadoop auf den Amazon S3 S3-Schnittstellenendpunkt zugreifen kann. Sie können den Endpunktnamen selbst nicht verwenden. Stattdessen müssen Sie Wählen Sie eine der folgenden Konfigurationsoptionen:
| AWS-Administrator |
Konfigurieren Sie die Authentifizierung für Amazon S3. | Um sich über Hadoop bei Amazon S3 zu authentifizieren, empfehlen wir, temporäre Rollenanmeldedaten in die Hadoop-Umgebung zu exportieren. Weitere Informationen finden Sie unter Authentifizierung mit S3 Um temporäre Anmeldeinformationen zu verwenden, fügen Sie die temporären Anmeldeinformationen zu Ihrer Anmeldeinformationsdatei hinzu oder führen Sie die folgenden Befehle aus, um die Anmeldeinformationen in Ihre Umgebung zu exportieren:
Wenn Sie über eine herkömmliche Kombination aus Zugriffsschlüssel und geheimer Taste verfügen, führen Sie die folgenden Befehle aus:
AnmerkungWenn Sie eine Kombination aus Zugriffsschlüssel und geheimem Schlüssel verwenden, ändern Sie den Anbieter der Anmeldeinformationen in den DistCp Befehlen von | AWS-Administrator |
Daten übertragen mit DistCp. | Führen Sie DistCp die folgenden Befehle aus, um Daten zu übertragen:
AnmerkungDie AWS-Region des Endpunkts wird nicht automatisch erkannt, wenn Sie den DistCp Befehl mit AWS PrivateLink for Amazon S3 verwenden. Hadoop 3.3.2 und spätere Versionen lösen dieses Problem, indem sie die Option aktivieren, die AWS-Region des S3-Buckets explizit festzulegen. Weitere Informationen finden Sie unter S3A, um die Option fs.s3a.endpoint.region hinzuzufügen, um die AWS-Region Weitere Informationen zu zusätzlichen S3A-Anbietern finden Sie unter Allgemeine S3A-Client-Konfiguration (Hadoop-Website).
AnmerkungUm den Schnittstellenendpunkt mit S3A zu verwenden, müssen Sie einen DNS-Aliaseintrag für den S3-Regionalnamen (z. B. Wenn Sie Signaturprobleme mit Amazon S3 haben, fügen Sie eine Option hinzu, um Signature Version 4 (Sigv4) zu signieren:
| Migrationsingenieur, AWS-Administrator |
