Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Richten Sie die Oracle UTL_FILE-Funktionalität auf Aurora PostgreSQL-Compatible ein
Rakesh Raghav und Anuradha Chintha, Amazon Web Services
Übersicht
Im Rahmen Ihrer Migration von Oracle zu Amazon Aurora PostgreSQL-Compatible Edition in der Amazon Web Services (AWS) Cloud können Sie auf mehrere Herausforderungen stoßen. Beispielsweise ist die Migration von Code, der auf dem UTL_FILE Oracle-Hilfsprogramm basiert, immer eine Herausforderung. In Oracle PL/SQL wird das UTL_FILE Paket in Verbindung mit dem zugrunde liegenden Betriebssystem für Dateioperationen wie Lesen und Schreiben verwendet. Das UTL_FILE Hilfsprogramm funktioniert sowohl für Server- als auch für Client-Computersysteme.
Amazon Aurora PostgreSQL-Compatible ist ein Angebot für verwaltete Datenbanken. Aus diesem Grund ist es nicht möglich, auf Dateien auf dem Datenbankserver zuzugreifen. Dieses Muster führt Sie durch die Integration von Amazon Simple Storage Service (Amazon S3) und Amazon Aurora PostgreSQL-kompatibel, um einen Teil der Funktionalität zu erreichen. UTL_FILE Mit dieser Integration können wir Dateien erstellen und verwenden, ohne Tools oder Dienste von Drittanbietern zum Extrahieren, Transformieren und Laden (ETL) zu verwenden.
Optional können Sie CloudWatch Amazon-Überwachung und Amazon SNS-Benachrichtigungen einrichten.
Wir empfehlen, diese Lösung gründlich zu testen, bevor Sie sie in einer Produktionsumgebung implementieren.
Voraussetzungen und Einschränkungen
Voraussetzungen
Ein aktives AWS-Konto
Fachwissen zum AWS Database Migration Service (AWS DMS)
Expertise in PL/pgSQL der Codierung
Ein Amazon Aurora PostgreSQL-kompatibler Cluster
Ein S3-Bucket
Einschränkungen
Dieses Muster bietet nicht die Funktionalität, um das Oracle-Hilfsprogramm zu ersetzen. UTL_FILE Die Schritte und der Beispielcode können jedoch weiter verbessert werden, um Ihre Ziele bei der Datenbankmodernisierung zu erreichen.
Produktversionen
Amazon Aurora PostgreSQL-kompatible Ausgabe 11.9
Architektur
Zieltechnologie-Stack
Amazon Aurora PostgreSQL-kompatibel
Amazon CloudWatch
Amazon-Simple-Notification-Service (Amazon-SNS)
Amazon S3
Zielarchitektur
Das folgende Diagramm zeigt eine allgemeine Darstellung der Lösung.
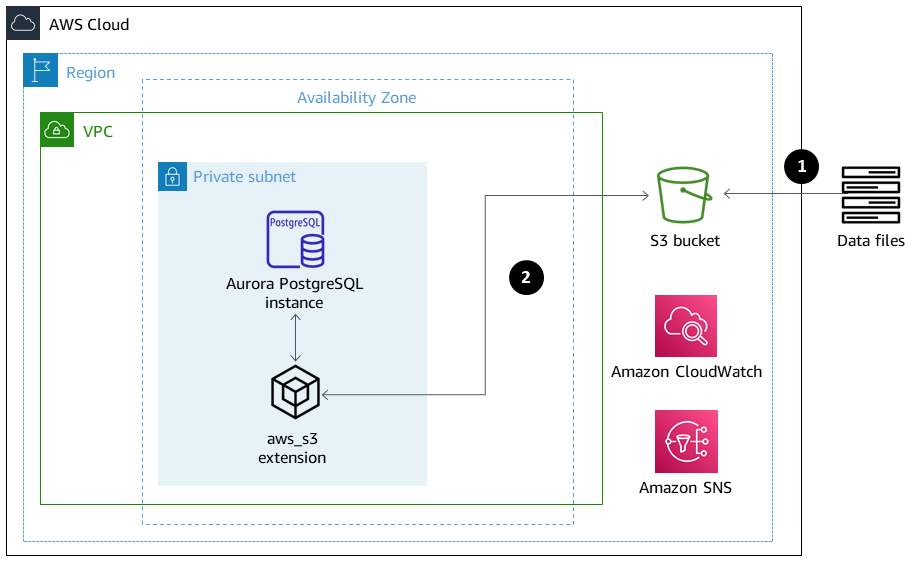
Dateien werden aus der Anwendung in den S3-Bucket hochgeladen.
Die
aws_s3Erweiterung greift mithilfe von PL/pgSQL auf die Daten zu und lädt die Daten in Aurora PostgreSQL-kompatibel hoch.
Tools
Amazon Aurora PostgreSQL-kompatibel — Amazon Aurora PostgreSQL-Compatible Edition ist eine vollständig verwaltete, PostgreSQL-kompatible und ACID-konforme relationale Datenbank-Engine. Sie kombiniert die Geschwindigkeit und Zuverlässigkeit kommerzieller High-End-Datenbanken mit der Wirtschaftlichkeit von Open-Source-Datenbanken.
AWS CLI — Die AWS-Befehlszeilenschnittstelle (AWS CLI) ist ein einheitliches Tool zur Verwaltung Ihrer AWS-Services. Mit nur einem Tool zum Herunterladen und Konfigurieren können Sie mehrere AWS-Services von der Befehlszeile aus steuern und mithilfe von Skripts automatisieren.
Amazon CloudWatch — Amazon CloudWatch überwacht die Ressourcen und die Nutzung von Amazon S3.
Amazon S3 — Amazon Simple Storage Service (Amazon S3) ist Speicher für das Internet. In diesem Muster bietet Amazon S3 eine Speicherebene zum Empfangen und Speichern von Dateien für den Verbrauch und die Übertragung zum und vom Aurora PostgreSQL-kompatiblen Cluster.
aws_s3 — Die
aws_s3Erweiterung integriert Amazon S3 und Aurora PostgreSQL-kompatibel.Amazon SNS — Amazon Simple Notification Service (Amazon SNS) koordiniert und verwaltet die Zustellung oder den Versand von Nachrichten zwischen Herausgebern und Kunden. In diesem Muster wird Amazon SNS zum Senden von Benachrichtigungen verwendet.
pgAdmin
— pgAdmin ist ein Open-Source-Verwaltungstool für Postgres. pgAdmin 4 bietet eine grafische Oberfläche zum Erstellen, Verwalten und Verwenden von Datenbankobjekten.
Code
Um die erforderliche Funktionalität zu erreichen, erstellt das Muster mehrere Funktionen mit einer ähnlichen Benennung wie. UTL_FILE Der Abschnitt Zusätzliche Informationen enthält die Codebasis für diese Funktionen.
Ersetzen Sie den Code testaurorabucket durch den Namen Ihres Test-S3-Buckets. us-east-1Ersetzen Sie durch die AWS-Region, in der sich Ihr Test-S3-Bucket befindet.
Epen
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
| Richten Sie IAM-Richtlinien ein. | Erstellen Sie AWS Identity and Access Management (IAM) -Richtlinien, die Zugriff auf den S3-Bucket und die darin enthaltenen Objekte gewähren. Den Code finden Sie im Abschnitt Zusätzliche Informationen. | AWS-Administrator, DBA |
| Fügen Sie Amazon S3 S3-Zugriffsrollen zu Aurora PostgreSQL hinzu. | Erstellen Sie zwei IAM-Rollen: eine Rolle für den Lese- und eine Rolle für den Schreibzugriff auf Amazon S3. Hängen Sie die beiden Rollen an den Aurora PostgreSQL-kompatiblen Cluster an:
Weitere Informationen finden Sie in der Aurora PostgreSQL-kompatiblen Dokumentation zum Import und Export von Daten nach Amazon S3. | AWS-Administrator, DBA |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
| Erstellen Sie die Erweiterung aws_commons. | Die | DBA, Entwickler |
| Erstellen Sie die Erweiterung aws_s3. | Die | DBA, Entwickler |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
| Testen Sie den Import von Dateien aus Amazon S3 nach Aurora PostgreSQL. | Um den Import von Dateien in Aurora PostgreSQL-Compatible zu testen, erstellen Sie eine CSV-Beispieldatei und laden Sie sie in den S3-Bucket hoch. Erstellen Sie eine Tabellendefinition auf der Grundlage der CSV-Datei und laden Sie die Datei mithilfe der Funktion in die Tabelle. | DBA, Entwickler |
| Testen Sie den Export von Dateien von Aurora PostgreSQL nach Amazon S3. | Um den Export von Dateien aus Aurora PostgreSQL-Compatible zu testen, erstellen Sie eine Testtabelle, füllen Sie sie mit Daten und exportieren Sie die Daten dann mithilfe der Funktion. | DBA, Entwickler |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
| Erstellen Sie das Schema utl_file_utility. | Das Schema hält die Wrapper-Funktionen zusammen. Führen Sie den folgenden Befehl aus, um das Schema zu erstellen.
| DBA, Entwickler |
| Erstellen Sie den Typ file_type. | Verwenden Sie den folgenden Code, um den
| DBA/Entwickler |
| Erstellen Sie die Init-Funktion. | Die | DBA/Entwickler |
| Erstellen Sie die Wrapper-Funktionen. | Erstellen Sie die Wrapper-Funktionen | DBA, Entwickler |
| Aufgabe | Beschreibung | Erforderliche Fähigkeiten |
|---|---|---|
| Testen Sie die Wrapper-Funktionen im Schreibmodus. | Um die Wrapper-Funktionen im Schreibmodus zu testen, verwenden Sie den Code im Abschnitt Zusätzliche Informationen. | DBA, Entwickler |
| Testen Sie die Wrapper-Funktionen im Append-Modus. | Um die Wrapper-Funktionen im Append-Modus zu testen, verwenden Sie den Code im Abschnitt Zusätzliche Informationen. | DBA, Entwickler |
Zugehörige Ressourcen
Zusätzliche Informationen
Richten Sie IAM-Richtlinien ein
Erstellen Sie die folgenden Richtlinien.
Richtlinienname | JSON |
|---|---|
S3 IntRead |
|
S3 IntWrite |
|
Erstellen Sie die Init-Funktion
Um allgemeine Variablen wie bucket oder zu initialisierenregion, erstellen Sie die init Funktion mit dem folgenden Code.
CREATE OR REPLACE FUNCTION utl_file_utility.init( ) RETURNS void LANGUAGE 'plpgsql' COST 100 VOLATILE AS $BODY$ BEGIN perform set_config ( format( '%s.%s','UTL_FILE_UTILITY', 'region' ) , 'us-east-1'::text , false ); perform set_config ( format( '%s.%s','UTL_FILE_UTILITY', 's3bucket' ) , 'testaurorabucket'::text , false ); END; $BODY$;
Erstellen Sie die Wrapper-Funktionen
Erstellen Sie die fclose Wrapper-Funktionen fopenput_line, und.
öffnen
CREATE OR REPLACE FUNCTION utl_file_utility.fopen( p_file_name character varying, p_path character varying, p_mode character DEFAULT 'W'::bpchar, OUT p_file_type utl_file_utility.file_type) RETURNS utl_file_utility.file_type LANGUAGE 'plpgsql' COST 100 VOLATILE AS $BODY$ declare v_sql character varying; v_cnt_stat integer; v_cnt integer; v_tabname character varying; v_filewithpath character varying; v_region character varying; v_bucket character varying; BEGIN /*initialize common variable */ PERFORM utl_file_utility.init(); v_region := current_setting( format( '%s.%s', 'UTL_FILE_UTILITY', 'region' ) ); v_bucket := current_setting( format( '%s.%s', 'UTL_FILE_UTILITY', 's3bucket' ) ); /* set tabname*/ v_tabname := substring(p_file_name,1,case when strpos(p_file_name,'.') = 0 then length(p_file_name) else strpos(p_file_name,'.') - 1 end ); v_filewithpath := case when NULLif(p_path,'') is null then p_file_name else concat_ws('/',p_path,p_file_name) end ; raise notice 'v_bucket %, v_filewithpath % , v_region %', v_bucket,v_filewithpath, v_region; /* APPEND MODE HANDLING; RETURN EXISTING FILE DETAILS IF PRESENT ELSE CREATE AN EMPTY FILE */ IF p_mode = 'A' THEN v_sql := concat_ws('','create temp table if not exists ', v_tabname,' (col1 text)'); execute v_sql; begin PERFORM aws_s3.table_import_from_s3 ( v_tabname, '', 'DELIMITER AS ''#''', aws_commons.create_s3_uri ( v_bucket, v_filewithpath , v_region) ); exception when others then raise notice 'File load issue ,%',sqlerrm; raise; end; execute concat_ws('','select count(*) from ',v_tabname) into v_cnt; IF v_cnt > 0 then p_file_type.p_path := p_path; p_file_type.p_file_name := p_file_name; else PERFORM aws_s3.query_export_to_s3('select ''''', aws_commons.create_s3_uri(v_bucket, v_filewithpath, v_region) ); p_file_type.p_path := p_path; p_file_type.p_file_name := p_file_name; end if; v_sql := concat_ws('','drop table ', v_tabname); execute v_sql; ELSEIF p_mode = 'W' THEN PERFORM aws_s3.query_export_to_s3('select ''''', aws_commons.create_s3_uri(v_bucket, v_filewithpath, v_region) ); p_file_type.p_path := p_path; p_file_type.p_file_name := p_file_name; END IF; EXCEPTION when others then p_file_type.p_path := p_path; p_file_type.p_file_name := p_file_name; raise notice 'fopenerror,%',sqlerrm; raise; END; $BODY$;
put_line
CREATE OR REPLACE FUNCTION utl_file_utility.put_line( p_file_name character varying, p_path character varying, p_line text, p_flag character DEFAULT 'W'::bpchar) RETURNS boolean LANGUAGE 'plpgsql' COST 100 VOLATILE AS $BODY$ /************************************************************************** * Write line, p_line in windows format to file, p_fp - with carriage return * added before new line. **************************************************************************/ declare v_sql varchar; v_ins_sql varchar; v_cnt INTEGER; v_filewithpath character varying; v_tabname character varying; v_bucket character varying; v_region character varying; BEGIN PERFORM utl_file_utility.init(); /* check if temp table already exist */ v_tabname := substring(p_file_name,1,case when strpos(p_file_name,'.') = 0 then length(p_file_name) else strpos(p_file_name,'.') - 1 end ); v_sql := concat_ws('','select count(1) FROM pg_catalog.pg_class c LEFT JOIN pg_catalog.pg_namespace n ON n.oid = c.relnamespace where n.nspname like ''pg_temp_%''' ,' AND pg_catalog.pg_table_is_visible(c.oid) AND Upper(relname) = Upper( ''' , v_tabname ,''' ) '); execute v_sql into v_cnt; IF v_cnt = 0 THEN v_sql := concat_ws('','create temp table ',v_tabname,' (col text)'); execute v_sql; /* CHECK IF APPEND MODE */ IF upper(p_flag) = 'A' THEN PERFORM utl_file_utility.init(); v_region := current_setting( format( '%s.%s', 'UTL_FILE_UTILITY', 'region' ) ); v_bucket := current_setting( format( '%s.%s', 'UTL_FILE_UTILITY', 's3bucket' ) ); /* set tabname*/ v_filewithpath := case when NULLif(p_path,'') is null then p_file_name else concat_ws('/',p_path,p_file_name) end ; begin PERFORM aws_s3.table_import_from_s3 ( v_tabname, '', 'DELIMITER AS ''#''', aws_commons.create_s3_uri ( v_bucket, v_filewithpath, v_region ) ); exception when others then raise notice 'Error Message : %',sqlerrm; raise; end; END IF; END IF; /* INSERT INTO TEMP TABLE */ v_ins_sql := concat_ws('','insert into ',v_tabname,' values(''',p_line,''')'); execute v_ins_sql; RETURN TRUE; exception when others then raise notice 'Error Message : %',sqlerrm; raise; END; $BODY$;
schließen
CREATE OR REPLACE FUNCTION utl_file_utility.fclose( p_file_name character varying, p_path character varying) RETURNS boolean LANGUAGE 'plpgsql' COST 100 VOLATILE AS $BODY$ DECLARE v_filewithpath character varying; v_bucket character varying; v_region character varying; v_tabname character varying; v_sql character varying; BEGIN PERFORM utl_file_utility.init(); v_region := current_setting( format( '%s.%s', 'UTL_FILE_UTILITY', 'region' ) ); v_bucket := current_setting( format( '%s.%s', 'UTL_FILE_UTILITY', 's3bucket' ) ); v_tabname := substring(p_file_name,1,case when strpos(p_file_name,'.') = 0 then length(p_file_name) else strpos(p_file_name,'.') - 1 end ); v_filewithpath := case when NULLif(p_path,'') is null then p_file_name else concat_ws('/',p_path,p_file_name) end ; raise notice 'v_bucket %, v_filewithpath % , v_region %', v_bucket,v_filewithpath, v_region ; /* exporting to s3 */ perform aws_s3.query_export_to_s3 (concat_ws('','select * from ',v_tabname,' order by ctid asc'), aws_commons.create_s3_uri(v_bucket, v_filewithpath, v_region) ); v_sql := concat_ws('','drop table ', v_tabname); execute v_sql; RETURN TRUE; EXCEPTION when others then raise notice 'error fclose %',sqlerrm; RAISE; END; $BODY$;
Testen Sie Ihr Setup und Ihre Wrapper-Funktionen
Verwenden Sie die folgenden anonymen Codeblöcke, um Ihr Setup zu testen.
Testen Sie den Schreibmodus
Der folgende Code schreibt eine Datei mit dem Namen s3inttest im S3-Bucket.
do $$ declare l_file_name varchar := 's3inttest' ; l_path varchar := 'integration_test' ; l_mode char(1) := 'W'; l_fs utl_file_utility.file_type ; l_status boolean; begin select * from utl_file_utility.fopen( l_file_name, l_path , l_mode ) into l_fs ; raise notice 'fopen : l_fs : %', l_fs; select * from utl_file_utility.put_line( l_file_name, l_path ,'this is test file:in s3bucket: for test purpose', l_mode ) into l_status ; raise notice 'put_line : l_status %', l_status; select * from utl_file_utility.fclose( l_file_name , l_path ) into l_status ; raise notice 'fclose : l_status %', l_status; end; $$
Testen Sie den Append-Modus
Der folgende Code fügt Zeilen an die s3inttest Datei an, die im vorherigen Test erstellt wurde.
do $$ declare l_file_name varchar := 's3inttest' ; l_path varchar := 'integration_test' ; l_mode char(1) := 'A'; l_fs utl_file_utility.file_type ; l_status boolean; begin select * from utl_file_utility.fopen( l_file_name, l_path , l_mode ) into l_fs ; raise notice 'fopen : l_fs : %', l_fs; select * from utl_file_utility.put_line( l_file_name, l_path ,'this is test file:in s3bucket: for test purpose : append 1', l_mode ) into l_status ; raise notice 'put_line : l_status %', l_status; select * from utl_file_utility.put_line( l_file_name, l_path ,'this is test file:in s3bucket : for test purpose : append 2', l_mode ) into l_status ; raise notice 'put_line : l_status %', l_status; select * from utl_file_utility.fclose( l_file_name , l_path ) into l_status ; raise notice 'fclose : l_status %', l_status; end; $$
Amazon SNS SNS-Benachrichtigungen
Optional können Sie CloudWatch Amazon-Überwachung und Amazon SNS-Benachrichtigungen im S3-Bucket einrichten. Weitere Informationen finden Sie unter Amazon S3 überwachen und Amazon SNS SNS-Benachrichtigungen einrichten.
