Amazon Redshift wird UDFs ab dem 1. November 2025 die Erstellung von neuem Python nicht mehr unterstützen. Wenn Sie Python verwenden möchten UDFs, erstellen Sie das UDFs vor diesem Datum liegende. Bestehendes Python UDFs wird weiterhin wie gewohnt funktionieren. Weitere Informationen finden Sie im Blogbeitrag
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Authentifizierung mit dem Spark-Connector
Das folgende Diagramm beschreibt die Authentifizierung zwischen Amazon S3, Amazon Redshift, dem Spark-Treiber und Spark-Executors.
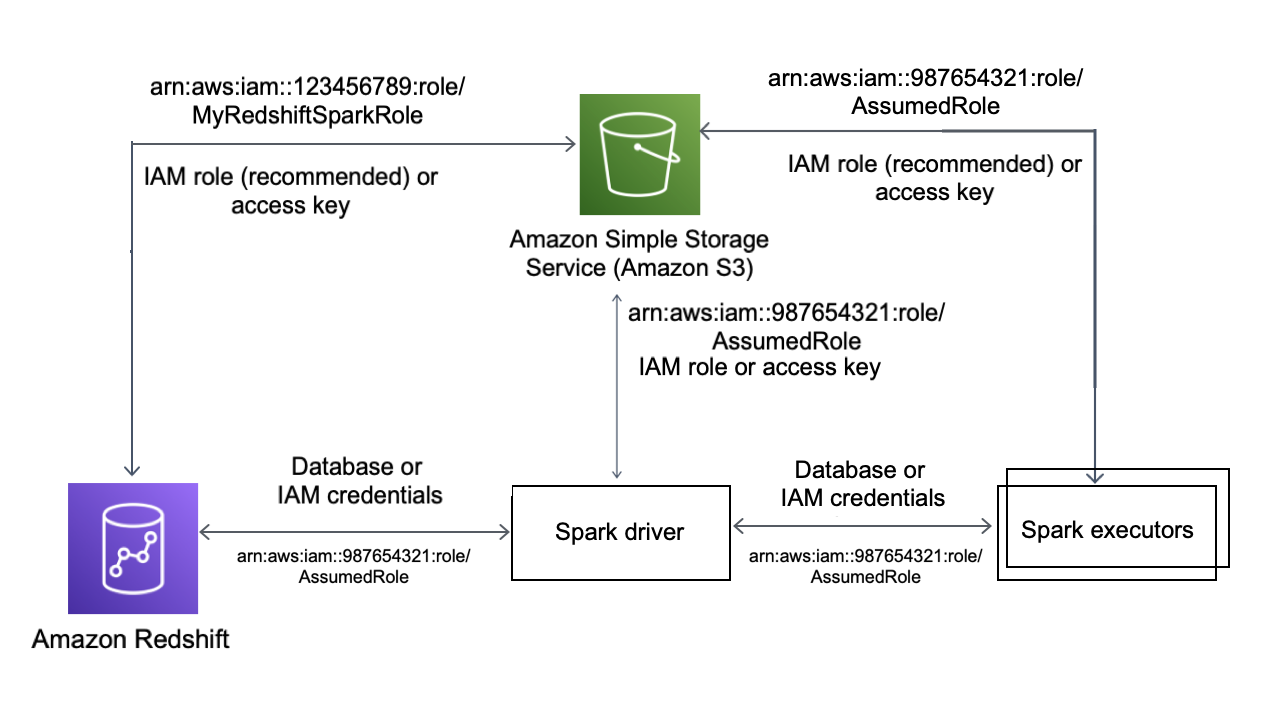
Authentifizierung zwischen Redshift und Spark
Sie können den von Amazon Redshift bereitgestellten JDBC-Treiber Version 2 verwenden, um durch die Angabe von Anmeldeinformationen mit dem Spark-Connector eine Verbindung mit Amazon Redshift herzustellen. Wenn Sie IAM verwenden möchten, konfigurieren Sie Ihre JDBC-URL so, dass die IAM-Authentifizierung verwendet wird. Um von Amazon EMR oder aus eine Verbindung zu einem Redshift-Cluster herzustellen AWS Glue, stellen Sie sicher, dass Ihre IAM-Rolle über die erforderlichen Berechtigungen zum Abrufen temporärer IAM-Anmeldeinformationen verfügt. In der folgenden Liste werden alle Berechtigungen beschrieben, die Ihre IAM-Rolle benötigt, um Anmeldeinformationen abzurufen und Amazon-S3-Operationen auszuführen.
-
Redshift: GetClusterCredentials (für bereitgestellte Redshift-Cluster)
-
Redshift: DescribeClusters (für bereitgestellte Redshift-Cluster)
-
Redshift: GetWorkgroup (für serverlose Amazon Redshift Redshift-Arbeitsgruppen)
-
Redshift: GetCredentials (für serverlose Amazon Redshift Redshift-Arbeitsgruppen)
Weitere Informationen zu GetClusterCredentials finden Sie unter Ressourcenrichtlinien für GetClusterCredentials.
Sie müssen außerdem sicherstellen, dass Amazon Redshift die IAM-Rolle während COPY- und UNLOAD-Operationen übernehmen kann.
Wenn Sie den aktuellen JDBC-Treiber verwenden, verwaltet der Treiber die Umstellung von einem selbstsignierten Amazon-Redshift-Zertifikat auf ein ACM-Zertifikat automatisch. Sie müssen jedoch die SSL-Optionen für die JDBC-URL angeben.
Im Folgenden finden Sie ein Beispiel dafür, wie Sie die JDBC-Treiber-URL und aws_iam_role angeben, um eine Verbindung mit Amazon Redshift herstellen.
df.write \ .format("io.github.spark_redshift_community.spark.redshift ") \ .option("url", "jdbc:redshift:iam://<the-rest-of-the-connection-string>") \ .option("dbtable", "<your-table-name>") \ .option("tempdir", "s3a://<your-bucket>/<your-directory-path>") \ .option("aws_iam_role", "<your-aws-role-arn>") \ .mode("error") \ .save()
Authentifizierung zwischen Amazon S3 und Spark
Wenn Sie eine IAM-Rolle für die Authentifizierung zwischen Spark und Amazon S3 verwenden, nutzen Sie eine der folgenden Methoden:
-
Das AWS SDK for Java versucht automatisch, AWS Anmeldeinformationen zu finden, indem es die von der AWSCredentials ProviderChain Default-Klasse implementierte Standard-Anmeldeinformationsanbieterkette verwendet. Weitere Informationen finden Sie unter Verwenden der standardmäßigen Anbieterkette von Anmeldeinformationen.
-
Sie können AWS Schlüssel über die Hadoop-Konfigurationseigenschaften
angeben. Wenn Ihre tempdir-Konfiguration beispielsweise auf eins3n://-Dateisystem verweist, legen Sie die Eigenschaftenfs.s3n.awsAccessKeyIdundfs.s3n.awsSecretAccessKeyin einer Hadoop-XML-Konfigurationsdatei fest oder rufen Siesc.hadoopConfiguration.set()auf, um die globale Hadoop-Konfiguration von Spark zu ändern.
Wenn Sie beispielsweise das s3n-Dateisystem verwenden, fügen Sie Folgendes hinzu:
sc.hadoopConfiguration.set("fs.s3n.awsAccessKeyId", "YOUR_KEY_ID") sc.hadoopConfiguration.set("fs.s3n.awsSecretAccessKey", "YOUR_SECRET_ACCESS_KEY")
Fügen Sie für das s3a-Dateisystem Folgendes hinzu:
sc.hadoopConfiguration.set("fs.s3a.access.key", "YOUR_KEY_ID") sc.hadoopConfiguration.set("fs.s3a.secret.key", "YOUR_SECRET_ACCESS_KEY")
Wenn Sie Python verwenden, verwenden Sie die folgenden Operationen:
sc._jsc.hadoopConfiguration().set("fs.s3n.awsAccessKeyId", "YOUR_KEY_ID") sc._jsc.hadoopConfiguration().set("fs.s3n.awsSecretAccessKey", "YOUR_SECRET_ACCESS_KEY")
-
Codieren Sie die Authentifizierungsschlüssel in der
tempdir-URL. Beispielsweise codiert die URIs3n://ACCESSKEY:SECRETKEY@bucket/path/to/temp/dirdas Schlüsselpaar (ACCESSKEY,SECRETKEY).
Authentifizierung zwischen Redshift und Amazon S3
Wenn Sie die Befehle COPY und UNLOAD in der Abfrage verwenden, müssen Sie Amazon S3 außerdem Zugriff auf Amazon Redshift gewähren, um Abfragen in Ihrem Namen auszuführen. Autorisieren Sie dazu zunächst Amazon Redshift für den Zugriff auf andere AWS Services und autorisieren Sie dann die COPY- und UNLOAD-Operationen mithilfe von IAM-Rollen.
Als bewährte Methode empfehlen wir, einer IAM-Rolle Berechtigungsrichtlinien anzufügen und sie dann nach Bedarf Benutzern und Gruppen zuzuweisen. Weitere Informationen finden Sie unter Identity and Access Management in Amazon Redshift.
Integration in AWS Secrets Manager
Sie können Ihren Redshift-Benutzernamen und Ihr Passwort aus einem gespeicherten Secret in AWS Secrets Manager abrufen. Wenn Sie Redshift-Anmeldeinformationen automatisch bereitstellen möchten, verwenden Sie den secret.id-Parameter. Weitere Informationen zum Erstellen eines Secrets für Redshift-Anmeldeinformationen Sie unter Erstellen eines AWS Secrets Manager -Datenbank-Secrets.
| GroupID | ArtifactID | Unterstützte Revision(en) | Beschreibung |
|---|---|---|---|
| com.amazonaws.secretsmanager | aws-secretsmanager-jdbc | 1.0.12 | Mit der AWS Secrets Manager SQL Connection Library für Java können Java-Entwickler mithilfe von Geheimnissen, die in AWS Secrets Manager gespeichert sind, auf einfache Weise eine Verbindung zu SQL-Datenbanken herstellen. |
Anmerkung
Danksagung: Diese Dokumentation enthält Beispielcode und Sprache, die von der Apache Software Foundation
