Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Einen Data Wrangler-Fluss erstellen und verwenden
Verwenden Sie einen Amazon SageMaker Data Wrangler-Flow oder einen Datenfluss, um eine Datenvorbereitungspipeline zu erstellen und zu ändern. Der Datenfluss verbindet die von Ihnen erstellten Datensätze, Transformationen und Analysen oder Schritte und kann zur Definition Ihrer Pipeline verwendet werden.
Instances
Wenn Sie einen Data Wrangler-Flow in Amazon SageMaker Studio Classic erstellen, verwendet Data Wrangler eine EC2 Amazon-Instance, um die Analysen und Transformationen in Ihrem Flow auszuführen. Standardmäßig verwendet Data Wrangler die m5.4xlarge-Instance. m5-Instances sind Allzweck-Instances, die für ein ausgewogenes Verhältnis zwischen Rechenleistung und Arbeitsspeicher sorgen. Sie können m5-Instances für eine Vielzahl von Rechen-Workloads verwenden.
Data Wrangler bietet Ihnen auch die Möglichkeit, R5-Instances zu verwenden. R5-Instances sind so konzipiert, dass sie eine schnelle Leistung bei der Verarbeitung großer Datensätze im Speicher bieten.
Wir empfehlen Ihnen, eine Instance zu wählen, die für Ihre Workloads am besten optimiert ist. Beispielsweise könnte der Preis für r5.8xlarge höher sein als für den m5.4xlarge, aber der r5.8xlarge ist möglicherweise besser für Ihre Workloads optimiert. Mit besser optimierten Instances können Sie Ihre Datenflüsse in kürzerer Zeit und zu geringeren Kosten ausführen.
Die Instance, die Sie verwenden können, um Ihren Data Wrangler-Fluss auszuführen, sind in der folgenden Tabelle aufgeführt.
| Standard-Instance | vCPU | Arbeitsspeicher |
|---|---|---|
| ml.m5.4xlarge | 16 | 64 GiB |
| ml.m5.8xlarge | 32 | 128 GiB |
| ml.m5.16xlarge | 64 |
256 GiB |
| ml.m5.24xlarge | 96 | 384 GiB |
| r5.4xlarge | 16 | 128 GiB |
| r5.8xlarge | 32 | 256 GiB |
| r5.24xlarge | 96 | 768 GiB |
Weitere Informationen zu R5-Instances finden Sie unter Amazon EC2 R5-Instances
Jedem Data Wrangler-Flow ist eine EC2 Amazon-Instance zugeordnet. Möglicherweise haben Sie mehrere Flüsse, die einer einzelnen Instance zugeordnet sind.
Für jede Fluss-Datei können Sie den Instance-Typ nahtlos wechseln. Wenn Sie den Instance-Typ wechseln, wird die Instance, mit der Sie den Fluss ausgeführt haben, weiterhin ausgeführt.
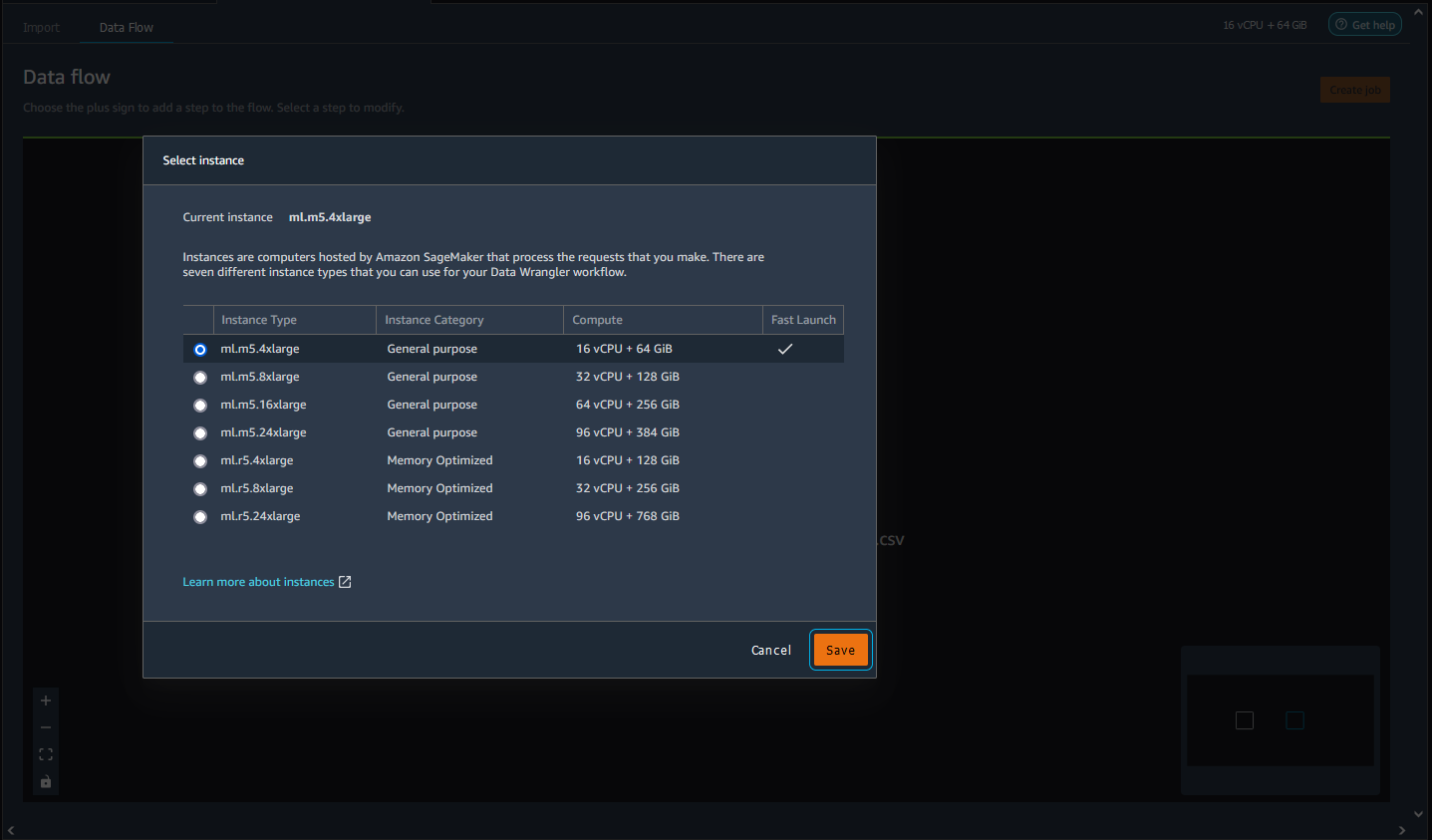
Gehen Sie wie folgt vor, um den Instance-Typ Ihres Flusses zu ändern.
-
Wählen Sie das Symbol Running Terminals and Kernels ().

-
Navigieren Sie zu der Instance, die Sie verwenden, und wählen Sie sie aus.
-
Wählen Sie den Instance-Typ aus, die Sie verwenden möchten.
-
Wählen Sie Speichern.
Sie werden für alle laufenden Instances belastet. Um zusätzliche Gebühren zu vermeiden, sollten Sie die Instances, die Sie nicht verwenden, manuell herunterfahren. Gehen Sie wie folgt vor, um eine laufende Instance herunterzufahren.
So fahren Sie eine laufende Instance herunter.
-
Wählen Sie das Instance-Symbol aus. Die folgende Abbildung zeigt Ihnen, wo Sie das RUNNING INSTANCES-Symbol auswählen können.
-
Wählen Sie neben der Instance, die Sie herunterfahren möchten, die Option Herunterfahren aus.
Wenn Sie eine Instance herunterfahren, die zur Ausführung eines Flusses verwendet wurde, können Sie vorübergehend nicht auf den Fluss zugreifen. Wenn Sie beim Versuch, den Fluss zu öffnen, auf dem eine Instance ausgeführt wird, die Sie zuvor heruntergefahren haben, eine Fehlermeldung erhalten, warten Sie 5 Minuten und versuchen Sie dann erneut, ihn zu öffnen.
Wenn Sie Ihren Datenfluss an einen Ort wie Amazon Simple Storage Service oder Amazon SageMaker Feature Store exportieren, führt Data Wrangler einen SageMaker Amazon-Verarbeitungsjob aus. Verwenden Sie eine der folgenden Instances für den Verarbeitungsauftrag. Weitere Informationen zum Exportieren Ihrer Daten finden Sie unter Export.
| Standard-Instances | vCPU | Arbeitsspeicher |
|---|---|---|
| ml.m5.4xlarge | 16 | 64 GiB |
| ml.m5.12xlarge | 48 |
192 GiB |
| ml.m5.24xlarge | 96 | 384 GiB |
Die Datenfluss-Benutzeroberfläche
Wenn Sie einen Datensatz importieren, wird der ursprüngliche Datensatz im Datenfluss angezeigt und trägt den Namen Quelle. Wenn Sie beim Import Ihrer Daten die Stichprobenauswahl aktiviert haben, erhält dieser Datensatz den Namen Quelle – Stichprobe. Data Wrangler leitet automatisch die Typen der einzelnen Spalten in Ihrem Datensatz ab und erstellt einen neuen Datenrahmen mit dem Namen Data types. Sie können diesen Frame auswählen, um die abgeleiteten Datentypen zu aktualisieren. Nachdem Sie einen einzelnen Datensatz hochgeladen haben, werden Sie Ergebnisse wie im folgenden Bild gezeigt sehen:
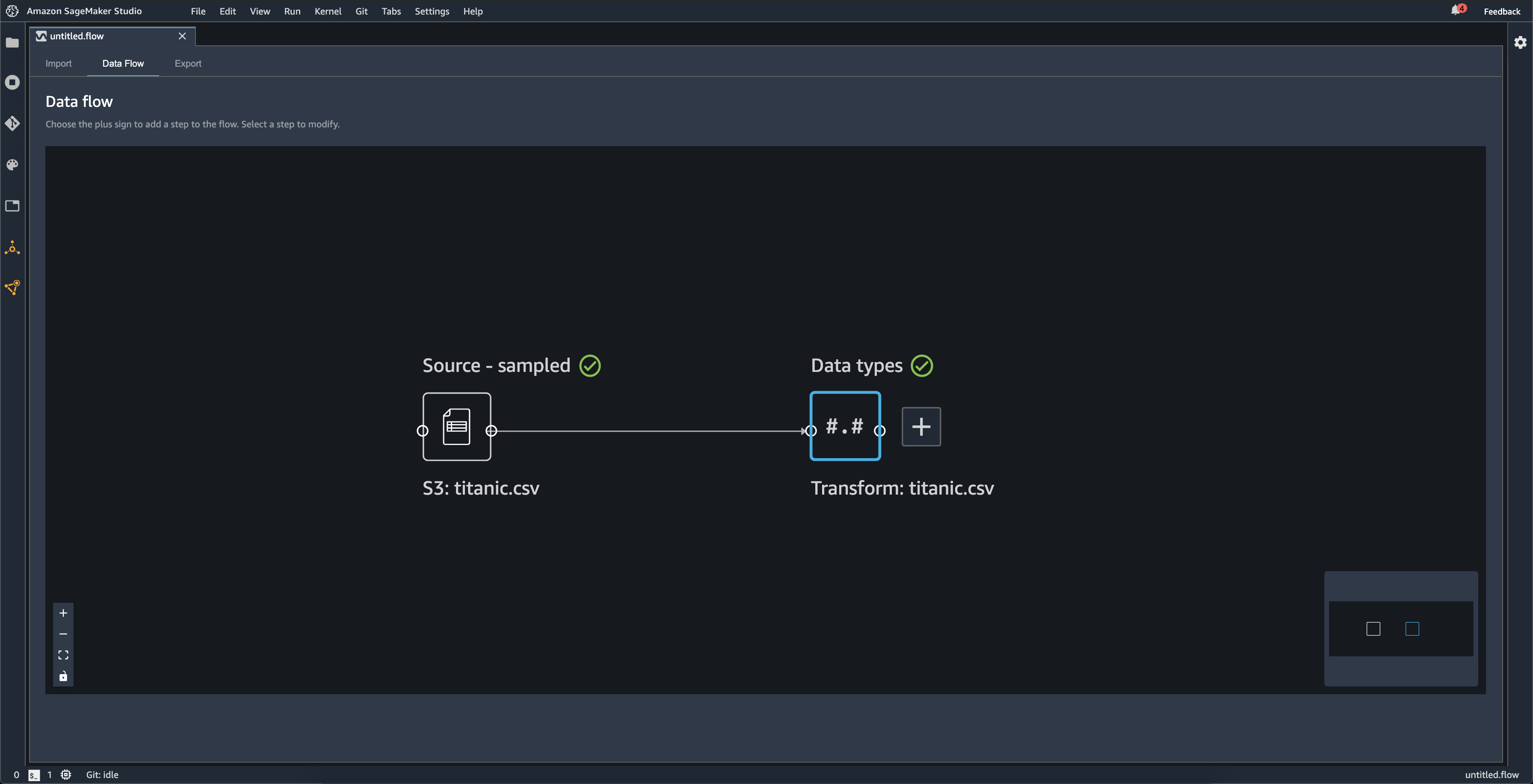
Mit jedem Hinzufügen eines Transformationschritts erstellen Sie einen neuen Datenrahmen. Wenn mehrere Transformationsschritte (außer Join oder Concatenate) zu demselben Datensatz hinzugefügt werden, werden sie gestapelt.
Join und Concatenate erstellen eigenständige Schritte, die den neuen verknüpften oder verketteten Datensatz enthalten.
Das folgende Diagramm zeigt einen Datenfluss mit einer Verknüpfung zwischen zwei Datensätzen sowie zwei Stapeln von Schritten. Der erste Stapel (Schritte (2)) fügt dem im Datentypen-Datensatz abgeleiteten Typ zwei Transformationen hinzu. Der Downstream-Stapel oder der Stapel auf der rechten Seite fügt dem Datensatz Transformationen hinzu, die aus einer Verknüpfung mit dem Namen demo-join resultieren.

Das kleine, graue Feld in der unteren rechten Ecke des Datenflusses bietet einen Überblick über die Anzahl der Stapel und Schritte im Datenfluss sowie über das Layout des Datenflusses. Das hellere Feld innerhalb des grauen Felds gibt die Schritte an, die sich in der UI-Ansicht befinden. Sie können dieses Feld verwenden, um Bereiche Ihres Datenflusses anzuzeigen, die außerhalb der UI-Ansicht liegen. Verwenden Sie das Symbol Bildschirm anpassen (
 ), um alle Schritte und Datensätze in Ihre UI-Ansicht einzupassen.
), um alle Schritte und Datensätze in Ihre UI-Ansicht einzupassen.
Die Navigationsleiste unten links enthält Symbole, mit denen Sie Ihren Datenfluss vergrößern (
 ) und verkleinern (
) und verkleinern (
 ) und die Größe des Datenflusses an den Bildschirm anpassen können ().
Verwenden Sie das Schlosssymbol (
) und die Größe des Datenflusses an den Bildschirm anpassen können ().
Verwenden Sie das Schlosssymbol (
 ), um die Position der einzelnen Schritte auf dem Bildschirm zu sperren oder zu entsperren.
), um die Position der einzelnen Schritte auf dem Bildschirm zu sperren oder zu entsperren.
Fügen Sie Ihrem Datenfluss einen Schritt hinzu
Wählen Sie + neben einem Datensatz oder einem zuvor hinzugefügten Schritt und wählen Sie dann eine der folgenden Optionen aus:
-
Datentypen bearbeiten (nur für einen Datentypen-Schritt): Wenn Sie zu einem Datentypen-Schritt keine Transformationen hinzugefügt haben, können Sie Datentypen bearbeiten auswählen, um die Datentypen zu aktualisieren, die Data Wrangler beim Import Ihres Datensatzes abgeleitet hat.
-
Transformation hinzufügen: Fügt einen neuen Transformationsschritt hinzu. Weitere Informationen zu den Datentransformationen, die Sie hinzufügen können, finden Sie unter Daten transformieren.
-
Analyse hinzufügen: Fügt eine Analyse hinzu. Sie können diese Option verwenden, um Ihre Daten an einem beliebigen Punkt im Datenfluss zu analysieren. Wenn Sie einem Schritt eine oder mehrere Analysen hinzufügen, wird in diesem Schritt ein Analysesymbol (
 ) angezeigt. Weitere Informationen zu den Analysen, die Sie hinzufügen können, finden Sie unter Analysieren und Visualisieren.
) angezeigt. Weitere Informationen zu den Analysen, die Sie hinzufügen können, finden Sie unter Analysieren und Visualisieren. -
Join: Verbindet zwei Datensätze und fügt den resultierenden Datensatz dem Datenfluss hinzu. Weitere Informationen hierzu finden Sie unter Datensätze verknüpfen.
-
Concatenate: Verkettet zwei Datensätze und fügt den resultierenden Datensatz dem Datenfluss hinzu. Weitere Informationen hierzu finden Sie unter Datensätze verketten.
Löschen Sie einen Schritt aus Ihrem Datenfluss
Um einen Schritt zu löschen, wählen Sie den Schritt aus und wählen Sie Löschen aus. Wenn es sich bei dem Knoten um einen Knoten mit einer einzigen Eingabe handelt, löschen Sie nur den Schritt, den Sie auswählen. Wenn Sie einen Schritt löschen, der eine einzige Eingabe hat, werden die nachfolgenden Schritte nicht gelöscht. Wenn Sie einen Schritt für einen Quell-, Verbindungs- oder Verkettungsknoten löschen, werden alle darauf folgenden Schritte ebenfalls gelöscht.
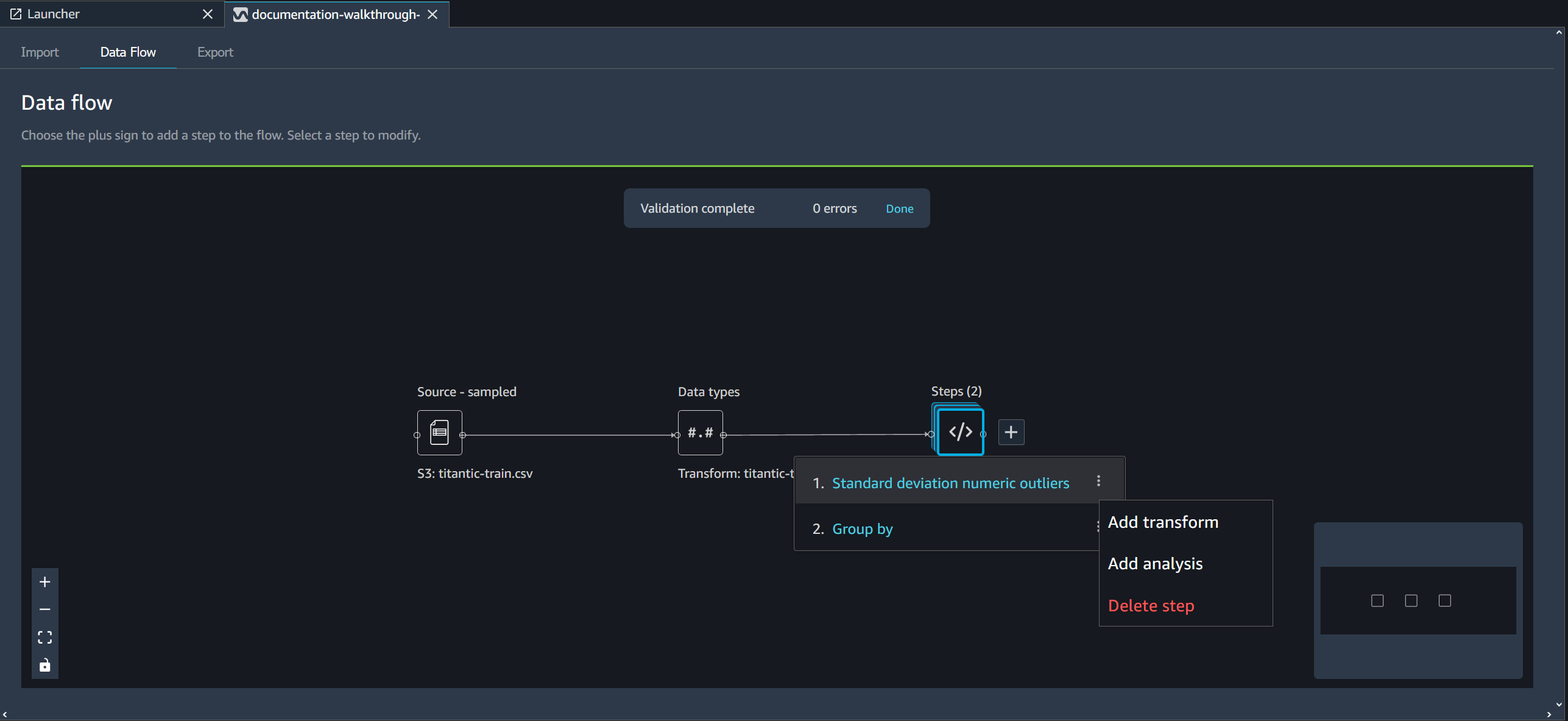
Um einen Schritt aus einem Schrittstapel zu löschen, wählen Sie den Stapel und dann den Schritt aus, den Sie löschen möchten.
Sie können eines der folgenden Verfahren verwenden, um einen Schritt zu löschen, ohne die nachfolgenden Schritte zu löschen.

Bearbeiten Sie einen Schritt in Ihrem Data Wrangler-Fluss
Sie können jeden Schritt bearbeiten, den Sie zu Ihrem Data Wrangler-Fluss hinzugefügt haben. Indem Sie die Schritte bearbeiten, können Sie die Transformationen oder die Datentypen der Spalten ändern. Sie können die Schritte bearbeiten, um Änderungen vorzunehmen, mit denen Sie bessere Analysen durchführen können.
Es gibt viele Möglichkeiten, einen Schritt zu bearbeiten. Einige Beispiele umfassen die Änderung der Imputationsmethode oder die Änderung des Schwellenwerts für die Einstufung eines Werts als Ausreißer.
Gehen Sie wie folgt vor, um einen Schritt zu bearbeiten.
Um einen Schritt zu bearbeiten, gehen Sie wie folgt vor.
-
Wählen Sie einen Schritt im Data Wrangler-Fluss aus, um die Tabellenansicht zu öffnen.

-
Wählen Sie einen Schritt im Datenfluss aus.
-
Bearbeiten Sie den Schritt.
Die folgende Abbildung enthält ein Beispiel für die Bearbeitung eines Schrittes.

Anmerkung
Sie können die gemeinsam genutzten Bereiche innerhalb Ihrer Amazon SageMaker AI-Domain verwenden, um gemeinsam an Ihren Data Wrangler-Flows zu arbeiten. In einer gemeinsam genutzten Umgebung können Sie und Ihre Auftragnehmer eine Flow-Datei in Echtzeit bearbeiten. Weder Sie noch Ihre Auftragnehmer können die Änderungen jedoch in Echtzeit sehen. Wenn jemand eine Änderung am Data Wrangler-Fluss vornimmt, muss er diese sofort speichern. Wenn jemand eine Datei speichert, kann ein Auftragnehmer sie nicht sehen, es sei denn, er schließt die Datei und öffnet sie erneut. Alle Änderungen, die nicht von einer Person gespeichert wurden, werden von der Person überschrieben, die ihre Änderungen gespeichert hat.
