Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Export
In Ihrem Data-Wrangler-Flow können Sie einige oder alle Transformationen exportieren, die Sie an Ihren Datenverarbeitungspipelines vorgenommen haben.
Ein Data-Wrangler-Flow besteht aus der Reihe von Datenvorbereitungsschritten, die Sie an Ihren Daten vorgenommen haben. Bei Ihrer Datenaufbereitung führen Sie an Ihren Daten eine oder mehrere Transformationen durch. Jede Transformation wird mit einem Transformationsschritt durchgeführt. Der Flow besteht aus einer Reihe von Knoten, die den Import Ihrer Daten und die von Ihnen durchgeführten Transformationen darstellen. Ein Beispiel für Knoten sehen Sie in der folgenden Abbildung.
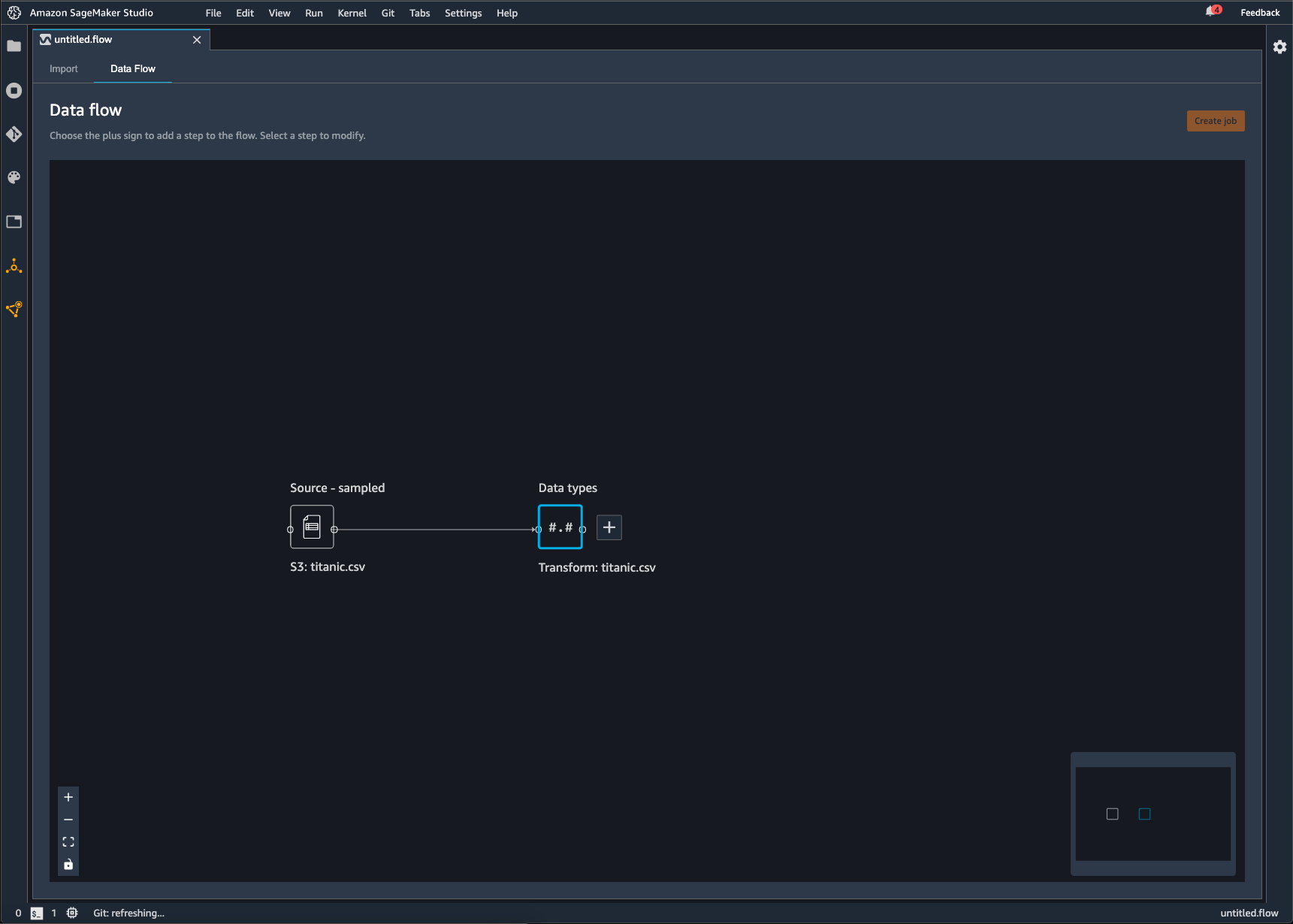
Das vorige Bild zeigt einen Data-Wrangler-Flow mit zwei Knoten. Der Knoten Quelle – Stichprobe zeigt die Datenquelle, aus der Sie Ihre Daten importiert haben. Der Knoten Datentypen gibt an, dass Data Wrangler eine Transformation vorgenommen hat, um den Datensatz in ein verwendbares Format zu konvertieren.
Jede Transformation, die Sie zum Data-Wrangler-Flow hinzufügen, wird als zusätzlicher Knoten angezeigt. Informationen zu den Transformationen, die Sie hinzufügen können, finden Sie unter Daten transformieren. Die folgende Abbildung zeigt einen Data-Wrangler-Flow, der über einen Rename-Column-Knoten verfügt, mit dem der Name einer Spalte in einem Datensatz geändert werden kann.
Ihre Datentransformationen können Sie zu folgenden Zielen exportieren:
-
Amazon S3
-
Pipelines
-
Amazon SageMaker Feature Store
-
Python Code
Wichtig
Wir empfehlen Ihnen, die von IAM AmazonSageMakerFullAccess verwaltete Richtlinie zu verwenden, um die AWS Erlaubnis zur Nutzung von Data Wrangler zu erteilen. Wenn Sie die verwaltete Richtlinie nicht verwenden, können Sie eine IAM-Richtlinie verwenden, die Data Wrangler Zugriff auf einen Bucket von Amazon S3 gewährt. Weitere Informationen zu der Richtlinie finden Sie unter Sicherheit und Berechtigungen.
Wenn Sie Ihren Datenfluss exportieren, werden Ihnen die AWS Ressourcen, die Sie verwenden, in Rechnung gestellt. Sie können die Kosten für diese Ressourcen mit Hilfe von Kostenzuordnungs-Tags organisieren und verwalten. Sie erstellen diese Tags für Ihr Benutzerprofil. Data Wrangler wendet sie dann automatisch auf die für den Export des Datenflusses verwendeten Ressourcen an. Weitere Informationen finden Sie unter Verwendung von Kostenzuordnungs-Tags.
Exportieren zu Amazon S3
Mit Data Wrangler können Sie Ihre Daten an einen Ort in einem Bucket von Amazon S3 exportieren. Sie können den Speicherort mit einer der folgenden Methoden angeben:
-
Zielknoten – Hier speichert Data Wrangler die Daten, nachdem sie verarbeitet wurden.
-
Exportieren nach – Exportiert die Daten, die sich aus einer Transformation ergeben, nach Amazon S3.
-
Daten exportieren – Bei kleinen Datensätzen können Sie die transformierten Daten schnell exportieren.
In den folgenden Abschnitten erfahren Sie mehr über jede dieser Methoden.

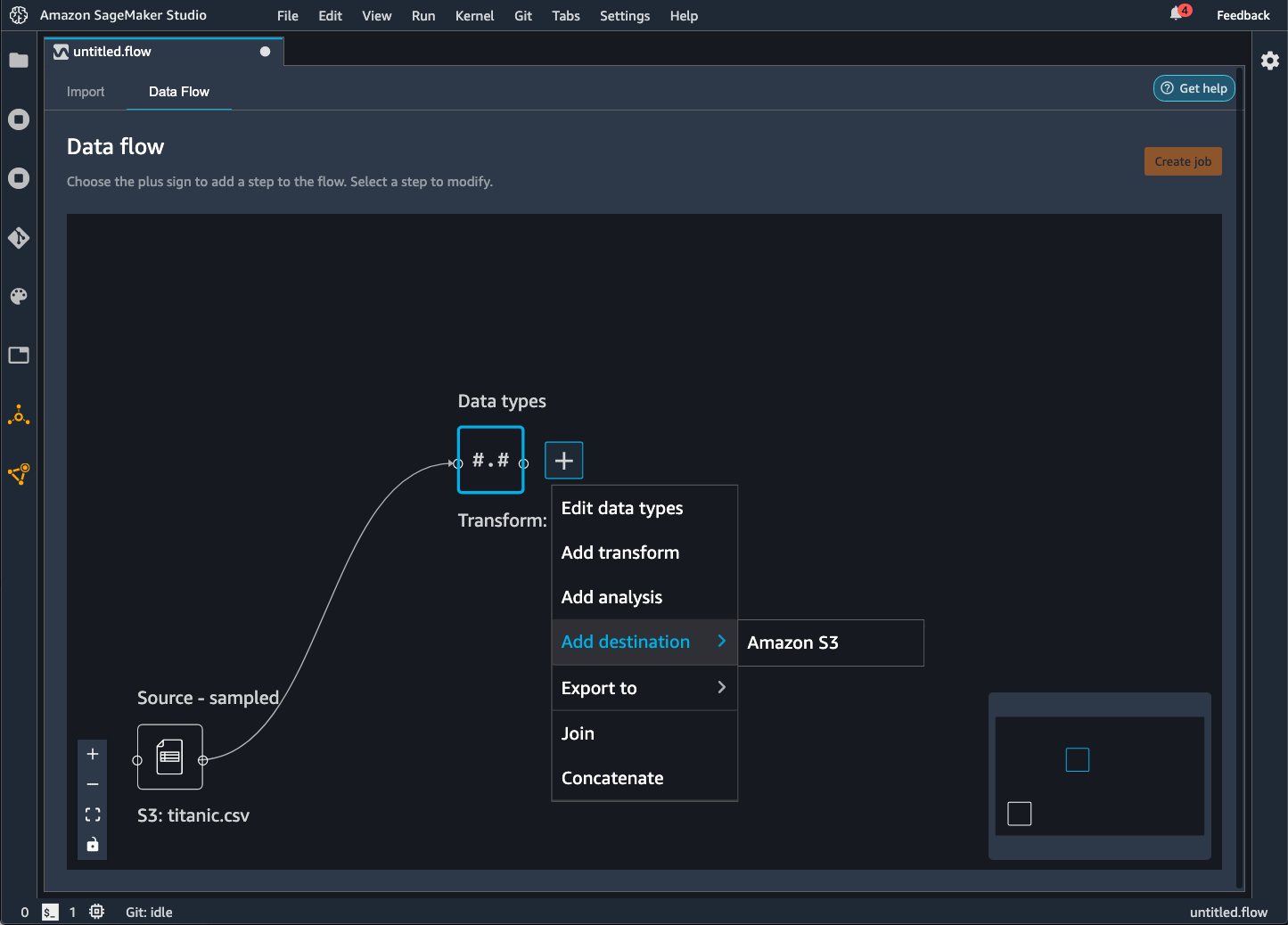
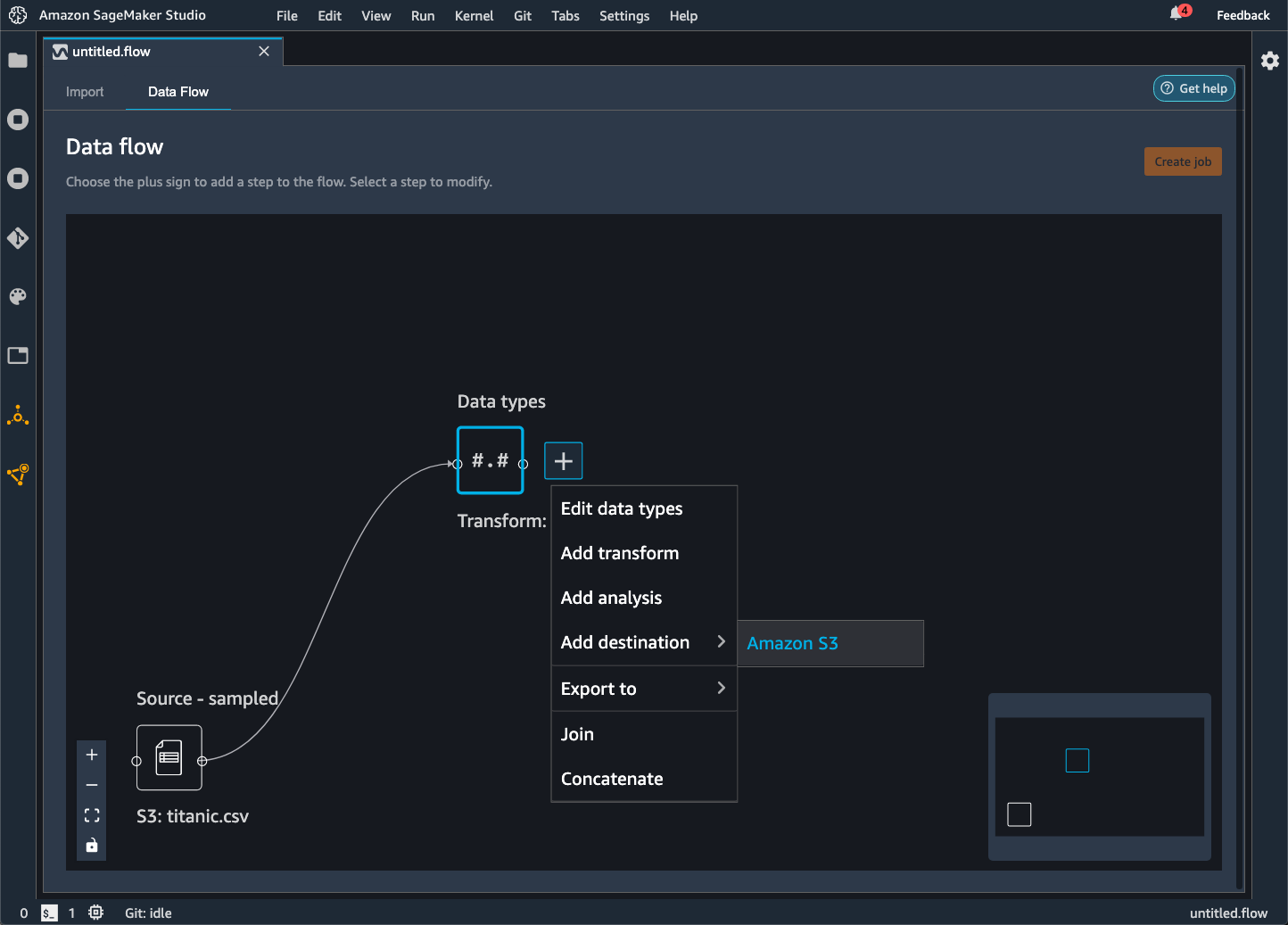
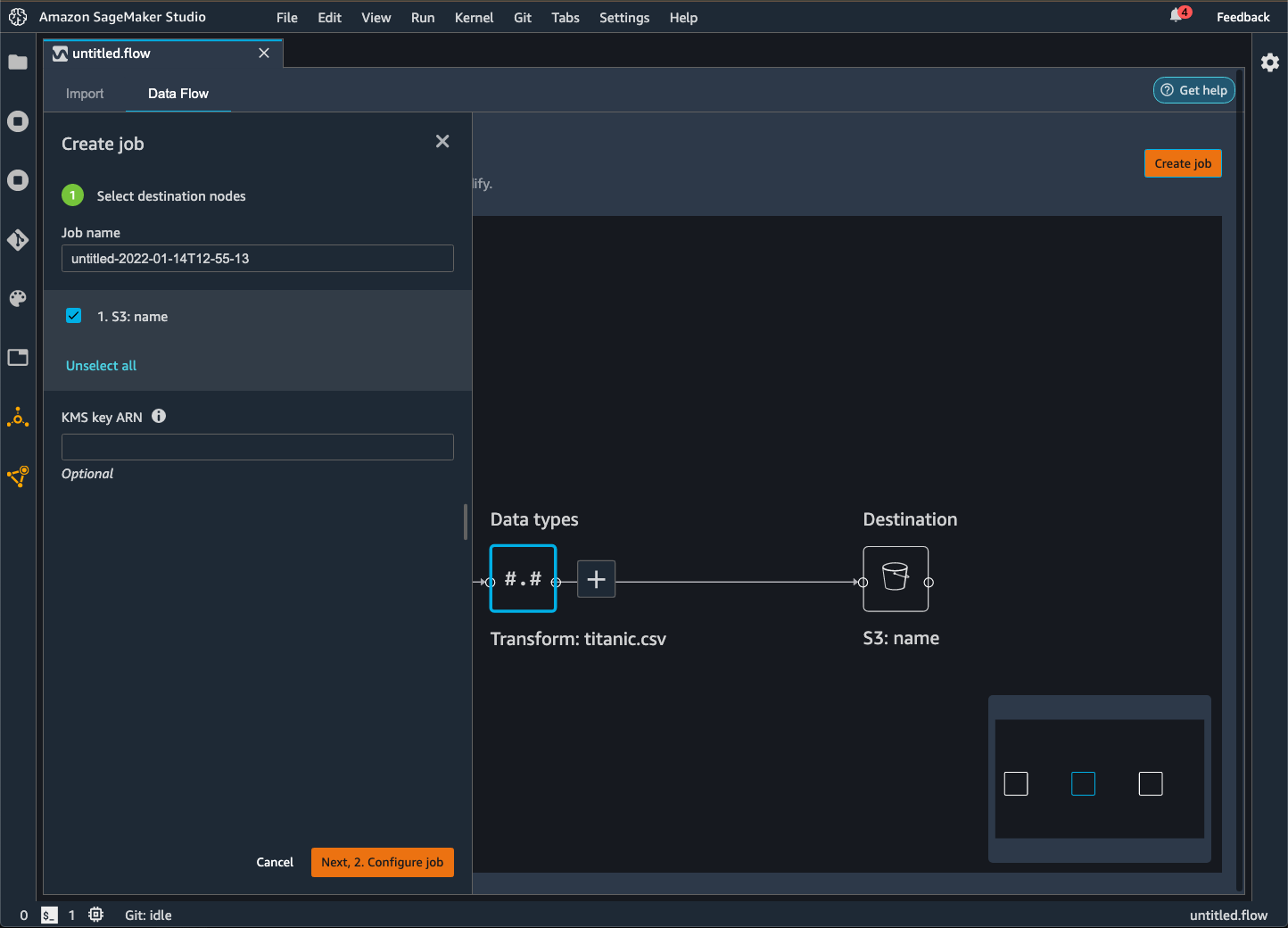
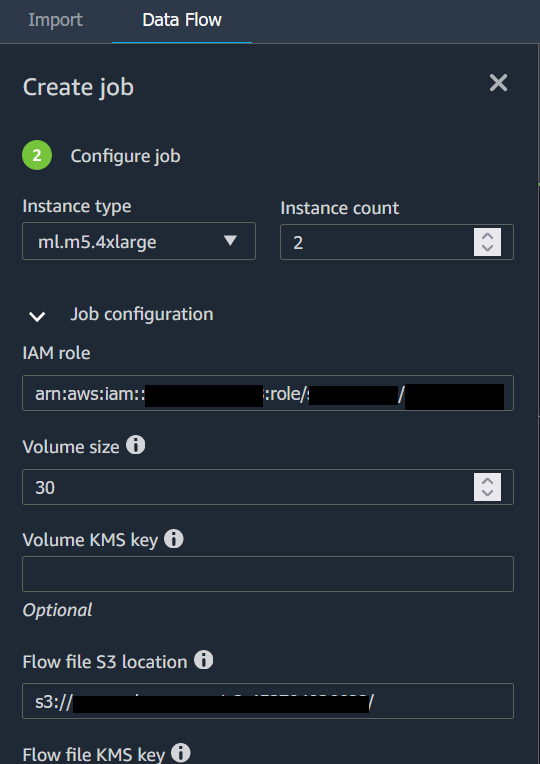
Wenn Sie Ihren Datenfluss in einen Bucket von Amazon S3 exportieren, speichert Data Wrangler eine Kopie der Flow-Datei im S3-Bucket. Er speichert die Flow-Datei unter dem Präfix data_wrangler_flows. Wenn Sie zum Speichern Ihrer Flow-Dateien den Standard-Bucket von Amazon S3 verwenden, verwendet es die folgende Namenskonvention:sagemaker-. Wenn Ihre Kontonummer beispielsweise 111122223333 lautet und Sie Studio Classic in us-east-1 verwenden, werden Ihre importierten Datensätze in gespeichert. region-account
numbersagemaker-us-east-1-111122223333 In diesem Beispiel werden Ihre in us-east-1 erstellten .flow-Dateien in s3://sagemaker- gespeichert. region-account
number/data_wrangler_flows/
In Pipelines exportieren
Wenn Sie umfangreiche Workflows für maschinelles Lernen (ML) erstellen und bereitstellen möchten, können Sie Pipelines verwenden, um Workflows zu erstellen, die SageMaker KI-Jobs verwalten und bereitstellen. Mit Pipelines können Sie Workflows erstellen, mit denen Sie Ihre Aufgaben zur SageMaker KI-Datenvorbereitung, zum Modelltraining und zur Modellbereitstellung verwalten. Mithilfe von Pipelines können Sie die von SageMaker KI angebotenen Erstanbieter-Algorithmen verwenden. Weitere Informationen zu Pipelines finden Sie unter Pipelines. SageMaker
Wenn Sie einen oder mehrere Schritte aus Ihrem Datenfluss in Pipelines exportieren, erstellt Data Wrangler ein Jupyter-Notebook, mit dem Sie eine Pipeline definieren, instanziieren, ausführen und verwalten können.
Verwenden Sie zur Erstellung einer Pipeline ein Jupyter Notebook
Gehen Sie wie folgt vor, um ein Jupyter-Notebook zu erstellen, um Ihren Data Wrangler-Flow in Pipelines zu exportieren.
Verwenden Sie das folgende Verfahren, um ein Jupyter-Notebook zu generieren und es auszuführen, um Ihren Data Wrangler-Flow nach Pipelines zu exportieren.
-
Wählen Sie das + neben dem Knoten aus, die Sie exportieren möchten.
-
Klicken Sie auf Exportieren nach.
-
Wählen Sie Pipelines (über Jupyter Notebook).
-
Führen Sie das Jupyter Notebook aus.

Sie können das von Data Wrangler erstellte Jupyter Notebook verwenden, um eine Pipeline zu definieren. Die Pipeline beinhaltet die Datenverarbeitungsschritte, die durch Ihren Data-Wrangler-Flow festgelegt werden.
Sie können zu Ihrer Pipeline weitere Schritte hinzufügen, indem Sie zu der steps Liste im folgenden Code im Notebook Schritte hinzufügen:
pipeline = Pipeline( name=pipeline_name, parameters=[instance_type, instance_count], steps=[step_process], #Add more steps to this list to run in your Pipeline )
Zu einem Inferenz-Endpunkt exportieren
Verwenden Sie Ihren Data Wrangler-Flow, um Daten zum Zeitpunkt der Inferenz zu verarbeiten, indem Sie aus Ihrem Data Wrangler-Flow eine serielle SageMaker KI-Inferenz-Pipeline erstellen. Eine Inference Pipeline besteht aus einer Reihe von Schritten, die dazu führen, dass ein trainiertes Modell Vorhersagen zu neuen Daten trifft. Eine serielle Inference Pipeline innerhalb von Data Wrangler transformiert die Rohdaten und stellt sie dem Machine-Learning-Modell zur Verfügung, damit es eine Vorhersage trifft. Sie erstellen, führen und verwalten die Inferenz-Pipeline von einem Jupyter-Notebook in Studio Classic aus. Weitere Informationen zum Zugriff auf das Notebook finden Sie unter Erstellen Sie einen Inferenz-Endpunkt mit Hilfe eines Jupyter Notebooks.
Im Notebook können Sie entweder ein Machine-Learning-Modell trainieren oder eines angeben, das Sie bereits trainiert haben. Sie können entweder Amazon SageMaker Autopilot verwenden oder XGBoost das Modell anhand der Daten trainieren, die Sie in Ihrem Data Wrangler-Flow transformiert haben.
Die Pipeline bietet die Möglichkeit, entweder eine Batch- oder Echtzeit-Inferenz vorzunehmen. Sie können den Data Wrangler-Flow auch zu Model Registry hinzufügen. SageMaker Weitere Informationen über Hosting-Modelle finden Sie unter Multimodell-Endpunkte.
Wichtig
Sie können Ihren Data-Wrangler-Flow nicht zu einem Inference-Endpunkt exportieren, wenn er die folgenden Transformationen aufweist:
-
Join
-
Verketten
-
Gruppierung nach
Wenn Sie Ihre Daten mit Hilfe der vorangegangenen Transformationen vorbereiten müssen, gehen Sie wie folgt vor.
So bereiten Sie Ihre Daten für die Inferenz mit nicht unterstützten Transformationen vor
-
Erstellen Sie einen Data-Wrangler-Flow.
-
Wenden Sie die vorangegangenen Transformationen an, die nicht unterstützt werden.
-
Exportieren Sie die Daten in einen Bucket von Amazon S3.
-
Erstellen Sie einen separaten Data-Wrangler-Flow.
-
Importieren Sie die Daten, die Sie aus dem vorangegangenen Flow exportiert haben.
-
Wenden Sie die übrigen Transformationen an.
-
Erstellen Sie mit dem von uns bereitgestellten Jupyter Notebook eine serielle Inference Pipeline.
Informationen zum Exportieren Ihrer Daten in einen Bucket von Amazon S3 finden Sie unter Exportieren zu Amazon S3. Informationen zum Öffnen des Jupyter Notebooks, mit dem die serielle Inference Pipeline erstellt wird, finden Sie unter Erstellen Sie einen Inferenz-Endpunkt mit Hilfe eines Jupyter Notebooks.
Data Wrangler ignoriert Transformationen, die zum Zeitpunkt der Inferenz Daten entfernen. Data Wrangler ignoriert z. B. die Transformation Fehlende Werte behandeln, wenn Sie die Konfiguration Drop missing verwenden.
Wenn Sie Transformationen an Ihren gesamten Datensatz angepasst haben, werden die Transformationen in Ihre Inference Pipeline übertragen. Wenn Sie z. B. fehlende Werte mit Hilfe des Medianwertes zugeschrieben haben, wird der Medianwert aus der Neuanpassung der Transformation auf Ihre Inferenzanforderungen angewendet. Sie können entweder die Transformationen aus Ihrem Data-Wrangler-Flow neu anpassen, wenn Sie das Jupyter Notebook verwenden oder wenn Sie Ihre Daten in eine Inference Pipeline exportieren. Informationen zur Neuanpassung von Transformationen finden Sie unter Transformationen für den gesamten Datensatz erneut anpassen und exportieren.
Die serielle Inference Pipeline unterstützt die folgenden Datentypen für die Eingabe- und Ausgabezeichenfolgen. Für jeden Datentyp gibt es eine Reihe von Anforderungen.
Unterstützte Datentypen
-
text/csv– der Datentyp für CSV-Zeichenfolgen-
Die Zeichenfolge darf keinen Header haben.
-
Die für die Inference Pipeline verwendeten Features müssen dieselbe Reihenfolge haben wie die Features im Trainingsdatensatz.
-
Die Features muss durch Komma getrennt sein.
-
Datensätze müssen durch ein Zeilenumbruchzeichen getrennt sein.
Es folgt das Beispiel einer gültig formatierten CSV-Zeichenfolge, die Sie in einer Inferenzanforderung angeben können.
abc,0.0,"Doe, John",12345\ndef,1.1,"Doe, Jane",67890 -
-
application/json– der Datentyp für JSON-Zeichenfolgen-
Die im Datensatz für die Inference Pipeline verwendeten Features müssen die gleiche Reihenfolge haben wie die Features im Trainingsdatensatz.
-
Die Daten müssen ein bestimmtes Schema haben. Sie definieren ein Schema als
instancesEinzelobjekt mit einer Reihe vonfeatures. Jedesfeatures-Objekt stellt eine Beobachtung dar.
Es folgt das Beispiel einer gültig formatierten JSON-Zeichenfolge, die Sie in einer Inferenzanforderung angeben können.
{ "instances": [ { "features": ["abc", 0.0, "Doe, John", 12345] }, { "features": ["def", 1.1, "Doe, Jane", 67890] } ] } -
Erstellen Sie einen Inferenz-Endpunkt mit Hilfe eines Jupyter Notebooks
Gehen Sie wie folgt vor, um Ihren Data-Wrangler-Flow zu exportieren, um eine Inference Pipeline zu erstellen.
Gehen Sie wie folgt vor, um mithilfe eines Jupyter Notebooks eine Inference Pipeline zu erstellen.
-
Wählen Sie das + neben dem Knoten aus, die Sie exportieren möchten.
-
Klicken Sie auf Exportieren nach.
-
Wählen Sie SageMaker AI Inference Pipeline (über Jupyter Notebook).
-
Führen Sie das Jupyter Notebook aus.
Wenn Sie das Jupyter Notebook ausführen, erstellt es einen Inferenz-Flow-Artefakt. Ein Inferenz-Flow-Artefakt ist eine Data-Wrangler-Flow-Datei mit zusätzlichen Metadaten, die zur Erstellung der seriellen Inference Pipeline verwendet werden. Der exportierte Knoten beinhaltet alle Transformationen der vorangehenden Knoten.
Wichtig
Data Wrangler braucht den Inference-Flow-Artefakt zum Ausführen der Inference Pipeline. Sie können Ihre eigene Flow-Datei nicht als Artefakt verwenden. Sie müssen sie anhand des o.a. Verfahrens erstellen.
In Python-Code exportieren
Gehen Sie wie folgt vor, um alle Schritte in Ihrem Datenfluss in eine Python-Datei zu exportieren, die Sie manuell in jeden Datenverarbeitungs-Workflow integrieren können.
Verwenden Sie das folgende Verfahren, um ein Jupyter Notebook zu erzeugen und es auszuführen, um Ihren Data-Wrangler-Flow nach Python-Code zu exportieren.
-
Wählen Sie das + neben dem Knoten aus, die Sie exportieren möchten.
-
Klicken Sie auf Exportieren nach.
-
Wählen Sie Python-Code aus.
-
Führen Sie das Jupyter Notebook aus.
Sie müssen das Python-Skript ggf. so konfigurieren, dass es in Ihrer Pipeline ausgeführt werden kann. Wenn Sie beispielsweise eine Spark-Umgebung ausführen, stellen Sie sicher, dass Sie das Skript in einer Umgebung ausführen, die berechtigt ist, auf Ressourcen zuzugreifen. AWS
In den Amazon SageMaker Feature Store exportieren
Sie können Data Wrangler verwenden, um von Ihnen erstellte Funktionen in den Amazon SageMaker Feature Store zu exportieren. Ein Feature ist eine Spalte in Ihrem Datensatz. Feature Store ist ein zentraler Speicher für Features und die zugehörigen Metadaten. Mit dem Feature Store können Sie kuratierte Daten für die Entwicklung von Machine Learning (ML) erstellen, diese gemeinsam nutzen und verwalten. Zentrale Speicher sorgen dafür, dass Ihre Daten leichter auffindbar und wiederverwendbar sind. Weitere Informationen zum Feature Store finden Sie unter Amazon SageMaker Feature Store.
Ein zentrales Konzept im Feature Store ist eine Feature-Gruppe. Eine Feature-Gruppe ist eine Sammlung von Features, ihren Datensätzen (Beobachtungen) und den zugehörigen Metadaten. Sie ähnelt einer Tabelle in einer Datenbank.
Mit Data Wrangler können Sie u.a. folgende Dinge tun:
-
Eine bestehende Feature-Gruppe mit neuen Datensätzen aktualisieren. Ein Datensatz ist eine Beobachtung im Datensatz.
-
Aus einem Knoten in Ihrem Data-Wrangler-Flow eine neue Feature-Gruppe erstellen. Data Wrangler fügt die Beobachtungen aus Ihren Datensätzen als Datensätze in Ihre Feature-Gruppe ein.
Wenn Sie eine bestehende Feature-Gruppe aktualisieren, muss das Schema Ihres Datensatzes mit dem Schema der Feature-Gruppe übereinstimmen. Alle Datensätze in der Feature-Gruppe werden durch die Beobachtungen in Ihrem Datensatz ersetzt.
Sie können entweder ein Jupyter Notebook oder einen Zielknoten verwenden, um Ihre Feature-Gruppe mit den Beobachtungen im Datensatz zu aktualisieren.
Wenn Ihre Feature-Gruppen mit dem Iceberg-Tabellenformat über einen benutzerdefinierten Offline-Store-Verschlüsselungsschlüssel verfügen, stellen Sie sicher, dass Sie dem IAM, das Sie für den Amazon SageMaker Processing-Job verwenden, die Erlaubnis zur Verwendung dieses Schlüssels erteilen. Sie müssen ihm mindestens Berechtigungen zum Verschlüsseln der Daten erteilen, die Sie in Amazon S3 schreiben. Um die Berechtigungen zu erteilen, geben Sie der IAM-Rolle die Möglichkeit, die zu verwenden. GenerateDataKey Weitere Informationen zur Erteilung von Berechtigungen für die Verwendung AWS KMS von Schlüsseln durch IAM-Rollen finden Sie unter https://docs.aws.amazon.com/kms/latest/developerguide/key-policies.html

Das Notebook erstellt anhand dieser Konfigurationen eine Feature-Gruppe, verarbeitet maßstabsgetreu Ihre Daten und nimmt die verarbeiteten Daten dann in Ihre Online- und Offline-Feature-Stores auf. Weitere Informationen finden Sie unter Datenquellen und Datenaufnahme.
Transformationen für den gesamten Datensatz erneut anpassen und exportieren
Wenn Sie Daten importieren, verwendet Data Wrangler eine Stichprobe der Daten, um die Kodierungen anzuwenden. Standardmäßig verwendet Data Wrangler die ersten 50.000 Zeilen als Stichprobe. Sie können jedoch auch den gesamten Datensatz importieren oder eine andere Methode zur Stichprobennahme verwenden. Weitere Informationen finden Sie unter Import.
Die folgenden Transformationen erstellen anhand Ihrer Daten eine Spalte im Datensatz:
Wenn Sie zum Importieren Ihrer Daten Stichproben verwendet haben, verwenden die vorangehenden Transformationen nur die Daten aus der Stichprobe, um die Spalte zu erstellen. Bei der Transformation wurden ggf. nicht alle relevanten Daten verwendet. Wenn Sie z. B. die Transformation Encode Categorical verwenden, gab es im gesamten Datensatz möglicherweise eine Kategorie, die in der Stichprobe nicht enthalten war.
Sie können die Transformationen entweder mit Hilfe eines Zielknotens oder eines Jupyter Notebooks an den gesamten Datensatz anpassen. Wenn Data Wrangler die Transformationen im Flow exportiert, erstellt es einen Verarbeitungsjob. SageMaker Wenn der Processing-Job abgeschlossen ist, speichert Data Wrangler die folgenden Dateien entweder am Standardspeicherort in Amazon S3 oder an einem von Ihnen angegebenen S3-Speicherort:
-
Die Data-Wrangler-Flow-Datei, die die Transformationen angibt, die erneut an den Datensatz angepasst werden
-
Der Datensatz, auf den die angepassten Transformationen angewendet wurden
Sie können in Data Wrangler eine Data-Wrangler-Flow-Datei öffnen und die Transformationen auf einen anderen Datensatz anwenden. Wenn Sie die Transformationen z. B. auf einen Trainingsdatensatz angewendet haben, können Sie die Data-Wrangler-Flow-Datei öffnen und sie dafür verwenden, die Transformationen auf einen Datensatz anzuwenden, der zur Inference verwendet wird.
Informationen zur Verwendung von Zielknoten zur Neuanpassung von Transformationen und zum Exportieren finden Sie auf den folgenden Seiten:
Gehen Sie wie folgt vor, um ein Jupyter Notebook auszuführen, die Transformationen neu anzupassen und die Daten zu exportieren.
Gehen Sie wie folgt vor, um ein Jupyter Notebook auszuführen, die Transformationen neu anzupassen und Ihren Data-Wrangler-Flow zu exportieren.
-
Wählen Sie das + neben dem Knoten aus, die Sie exportieren möchten.
-
Klicken Sie auf Exportieren nach.
-
Wählen Sie den Speicherort aus, an den Sie die Daten exportieren möchten.
-
Stellen Sie für das
refit_trained_paramsObjektrefitaufTrueein. -
Geben Sie für das
output_flowFeld den Namen der Ausgabe-Flow-Datei mit den angepassten Transformationen an. -
Führen Sie das Jupyter Notebook aus.
Erstellen Sie einen Zeitplan für die automatische Verarbeitung neuer Daten
Wenn Sie regelmäßig Daten verarbeiten, können Sie einen Zeitplan für die automatische Ausführung des Processing-Jobs erstellen. Sie können z. B. einen Zeitplan erstellen, der einen Processing-Job automatisch ausführt, wenn Sie neue Daten erhalten. Weitere Informationen zu diesen Processing-Jobs finden Sie unter Exportieren zu Amazon S3 und In den Amazon SageMaker Feature Store exportieren.
Wenn Sie einen Job erstellen, müssen Sie eine IAM-Rolle angeben, die über die Berechtigungen zum Erstellen des Jobs verfügt. Standardmäßig ist die für den Zugriff auf Data Wrangler verwendete IAM-Rolle die SageMakerExecutionRole.
Die folgenden Berechtigungen ermöglichen Data Wrangler den Zugriff auf Verarbeitungsaufträge EventBridge und deren Ausführung: EventBridge
-
Fügen Sie der Amazon SageMaker Studio Classic-Ausführungsrolle die folgende AWS verwaltete Richtlinie hinzu, die Data Wrangler Nutzungsberechtigungen erteilt: EventBridge
arn:aws:iam::aws:policy/AmazonEventBridgeFullAccessWeitere Informationen zu der Richtlinie finden Sie unter AWS Verwaltete Richtlinien für. EventBridge
-
Fügen Sie die folgende Richtlinie zur IAM-Rolle hinzu, die Sie bei der Erstellung eines Jobs in Data Wrangler angeben:
Wenn Sie die Standard-IAM-Rolle verwenden, fügen Sie die vorherige Richtlinie zur Amazon SageMaker Studio Classic-Ausführungsrolle hinzu.
Fügen Sie der Rolle die folgende Vertrauensrichtlinie hinzu, EventBridge damit sie übernommen werden kann.
{ "Effect": "Allow", "Principal": { "Service": "events.amazonaws.com" }, "Action": "sts:AssumeRole" }
Wichtig
Wenn Sie einen Zeitplan erstellen, erstellt Data Wrangler einen eventRule in. EventBridge Es fallen Gebühren sowohl für die von Ihnen erstellten Ereignisregeln als auch für die Instances an, die zur Ausführung des Processing-Jobs verwendet werden.
EventBridge Preisinformationen finden Sie unter EventBridge Amazon-Preise
Sie können mithilfe einer der folgenden Methoden einen Zeitplan erstellen:
-
Anmerkung
Data Wrangler unterstützt die folgenden Ausdrücke nicht:
-
LW#
-
Abkürzungen für Tage
-
Abkürzungen für Monate
-
-
Wiederkehrende – Legen Sie ein stündliches oder tägliches Intervall für die Ausführung des Jobs fest.
-
Bestimmte Zeit – Legen Sie bestimmte Tage und Uhrzeiten für die Ausführung des Jobs fest.
In den folgenden Abschnitten finden Sie Verfahren zum Erstellen von Jobs.
Sie können Amazon SageMaker Studio Classic verwenden, um die Jobs anzuzeigen, deren Ausführung geplant ist. Ihre Verarbeitungsaufträge werden innerhalb von Pipelines ausgeführt. Jeder Processing-Job hat seine eigene Pipeline. Er wird als Verarbeitungsschritt innerhalb der Pipeline ausgeführt. Sie können sich die Zeitpläne anzeigen lassen, die Sie in einer Pipeline erstellt haben. Weitere Informationen zum Anzeigen einer Pipeline finden Sie unter Sehen Sie sich die Details einer Pipeline an.
Gehen Sie wie folgt vor, um sich die von Ihnen geplanten Jobs anzeigen zu lassen.
Gehen Sie wie folgt vor, um sich die von Ihnen geplanten Jobs anzeigen zu lassen.
-
Öffnen Sie Amazon SageMaker Studio Classic.
-
Öffnen Sie Pipelines
-
Sehen Sie sich die Pipelines für die Jobs an, die Sie erstellt haben.
Die Pipeline, in der der Job ausgeführt wird, verwendet den Namen des Jobs als Präfix. Wenn Sie z. B. einen Job mit dem Namen
housing-data-feature-enginneringerstellt haben, lautet der Name der Pipelinedata-wrangler-housing-data-feature-engineering. -
Wählen Sie die Pipeline aus, die Ihren Job enthält.
-
Status der Pipelines anzeigen. Pipelines mit dem Status Erfolgreich haben den Processing-Job erfolgreich ausgeführt.
Gehen Sie wie folgt vor, um die Ausführung des Processing-Jobs zu beenden:
Um die Ausführung eines Processing-Jobs zu beenden, löschen Sie die Ereignisregel, die den Zeitplan angibt. Indem eine Ereignisregel gelöscht wird, werden keine mit dem Zeitplan verknüpften Jobs mehr ausgeführt. Informationen zum Löschen einer Regel finden Sie unter EventBridge Amazon-Regel deaktivieren oder löschen.
Sie können die mit den Zeitplänen verknüpften Pipelines auch beenden und löschen. Informationen zum Stoppen einer Pipeline finden Sie unter StopPipelineExecution. Hinweise zum Löschen einer Pipeline finden Sie unter DeletePipeline.
