Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Erhalten Sie Einblicke in Daten und Datenqualität
Verwenden Sie den Datenqualitäts- und Insights-Bericht, um eine Analyse der Daten durchzuführen, die Sie in Data Wrangler importiert haben. Wir empfehlen, dass Sie den Bericht erstellen, nachdem Sie Ihren Datensatz importiert haben. Sie können den Bericht verwenden, um Ihre Daten zu bereinigen und zu verarbeiten. Er gibt Ihnen Informationen wie die Anzahl der fehlenden Werte und die Anzahl der Ausreißer. Wenn Sie Probleme mit Ihren Daten haben, wie z. B. undichte Zielstellen oder Ungleichgewichte, können Sie mithilfe des Insights-Berichts auf diese Probleme aufmerksam gemacht werden.
Gehen Sie wie folgt vor, um einen Datenqualitäts- und Insights-Bericht zu erstellen. Es wird davon ausgegangen, dass Sie bereits einen Datensatz in Ihren Data Wrangler-Flow importiert haben.
So erstellen Sie einen Datenqualitäts- und Insights-Bericht:
-
Wählen Sie ein + neben einem Knoten in Ihrem Data Wrangler-Flow.
-
Wählen Sie Dateneinblicke abrufen aus.
-
Geben Sie unter Analysename einen Namen für den Insights-Bericht an.
-
(Optional) Geben Sie für Zielspalte die Zielspalte an.
-
Geben Sie als Problemtyp Regression oder Klassifizierung an.
-
Geben Sie für Datengröße einen der folgenden Werte an:
-
50 K – Verwendet die ersten 50000 Zeilen des Datensatzes, den Sie importiert haben, um den Bericht zu erstellen.
-
Gesamter Datensatz – Verwendet den gesamten Datensatz, den Sie importiert haben, um den Bericht zu erstellen.
Anmerkung
Für die Erstellung eines Datenqualitäts- und Insights-Berichts für den gesamten Datensatz wird ein SageMaker Amazon-Verarbeitungsjob verwendet. Ein SageMaker Verarbeitungsjob stellt die zusätzlichen Rechenressourcen bereit, die erforderlich sind, um Einblicke in all Ihre Daten zu erhalten. Weitere Informationen zur SageMaker Verarbeitung von Aufträgen finden Sie unterVerwenden Sie Verarbeitungsjobs, um Datenumwandlungs-Workloads auszuführen.
-
-
Wählen Sie Erstellen.
Die folgenden Themen zeigen die Abschnitte des Berichts:
Sie können den Bericht entweder herunterladen oder online ansehen. Um den Bericht herunterzuladen, wählen Sie die Download-Schaltfläche in der oberen rechten Ecke des Bildschirms. Die folgende Abbildung zeigt die Schaltfläche.

Übersicht
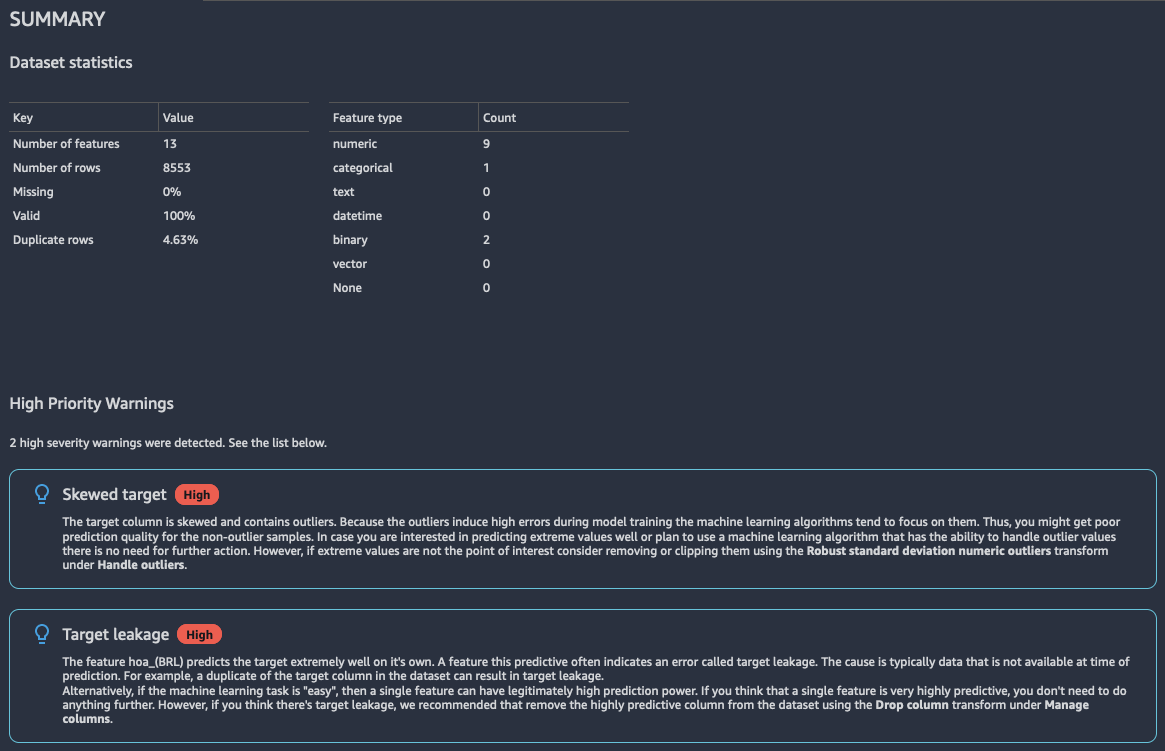
Der Insights-Bericht enthält eine kurze Zusammenfassung der Daten, die allgemeine Informationen wie fehlende Werte, ungültige Werte, Merkmalstypen, Anzahl von Ausreißern und mehr enthält. Er kann auch Warnungen mit hohem Schweregrad enthalten, die auf wahrscheinliche Probleme mit den Daten hinweisen. Wir empfehlen Ihnen, die Warnungen zu überprüfen.
Nachfolgend finden Sie ein Beispiel einer Berichtszusammenfassung.
Zielspalte
Wenn Sie den Bericht über Datenqualität und Einblicke erstellen, bietet Ihnen Data Wrangler die Möglichkeit, eine Zielspalte auszuwählen. Eine Zielspalte ist eine Spalte, die Sie voraussagen möchten. Wenn Sie eine Zielspalte auswählen, erstellt Data Wrangler automatisch eine Zielspaltenanalyse. Außerdem werden die Merkmale in der Reihenfolge ihrer Voraussagekraft eingestuft. Wenn Sie eine Zielspalte auswählen, müssen Sie angeben, ob Sie versuchen, ein Regressions- oder ein Klassifizierungsproblem zu lösen.
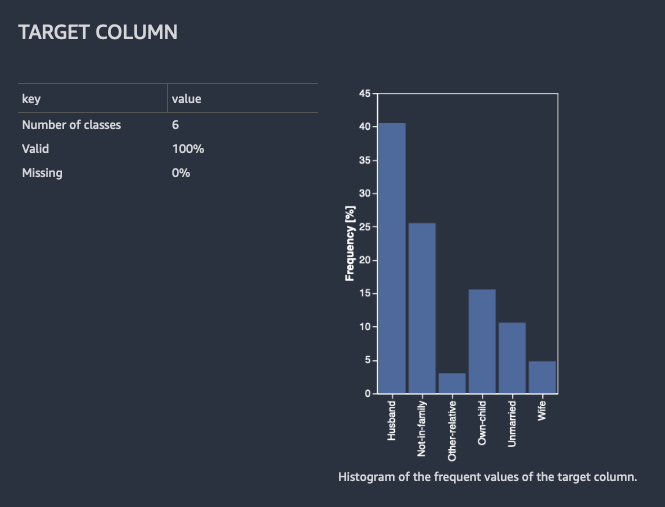
Zur Klassifizierung zeigt Data Wrangler eine Tabelle und ein Histogramm der gängigsten Klassen. Eine Klasse ist eine Kategorie. Sie enthält auch Beobachtungen oder Zeilen mit einem fehlenden oder ungültigen Zielwert.
Die folgende Abbildung zeigt ein Beispiel für eine Zielspaltenanalyse für ein Klassifikationsproblem.
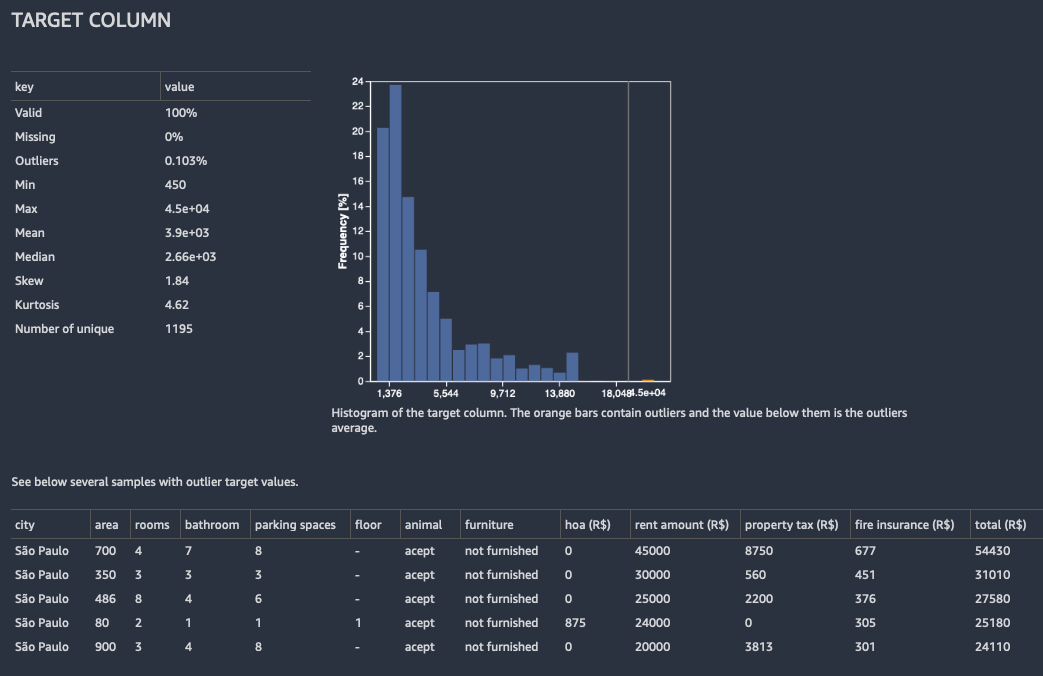
Für die Regression zeigt Data Wrangler ein Histogramm aller Werte in der Zielspalte. Sie enthält auch Beobachtungen oder Zeilen mit einem fehlenden, ungültigen oder einem Ausreißer-Zielwert.
Die folgende Abbildung zeigt ein Beispiel für eine Zielspaltenanalyse für ein Regressionsproblem.
Quick-Modell
Das Quick-Modell bietet eine Schätzung der erwarteten vorausgesagten Qualität eines Modells, das Sie anhand Ihrer Daten trainieren.
Data Wrangler teilt Ihren Datensatz in Trainings- und Validierungsbereiche auf. Es verwendet 80 % der Stichproben für das Training und 20 % der Werte für die Validierung. Zur Klassifizierung wird die Stichprobe stratifiziert und aufgeteilt. Bei einer stratifizierten Aufteilung hat jede Datenpartition das gleiche Verhältnis von Beschriftungen. Bei Klassifikationsproblemen ist es wichtig, dass das gleiche Verhältnis der Beschriftungen zwischen den Kategorien Training und Klassifikationsbereiche eingehalten wird. Data Wrangler trainiert das XGBoost-Modell mit den Standard-Hyperparametern. Es stoppt die Validierungsdaten frühzeitig und führt nur eine minimale Vorverarbeitung der Merkmale durch.
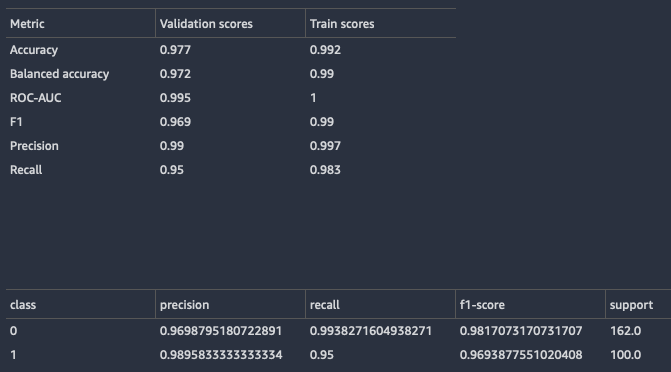
Bei Klassifikationsmodellen gibt Data Wrangler sowohl eine Modellzusammenfassung als auch eine Konfusionsmatrix zurück.
Im Folgenden finden Sie ein Beispiel für die Klassifizierung der Modellübersicht. Weitere Informationen zu den zurückgegebenen Informationen finden Sie unter Definitionen.
Es folgt ein Beispiel für eine Konfusionsmatrix, die das Quick-Modell zurückgibt.
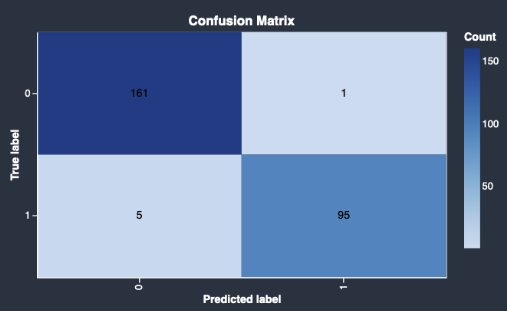
Eine Konfusionsmatrix enthält die folgenden Informationen:
-
Gibt an, wie oft die vorausgesagte Beschriftung mit der wahren Beschriftung übereinstimmt.
-
Gibt an, wie oft die vorausgesagte Beschriftung mit der wahren Beschriftung nicht übereinstimmt.
Die wahre Beschriftung stellt eine tatsächliche Beobachtung in Ihren Daten dar. Wenn Sie beispielsweise ein Modell zur Erkennung betrügerischer Transaktionen verwenden, steht das True Label für eine Transaktion, die tatsächlich betrügerisch oder nicht betrügerisch ist. Das vorausgesagte Beschriftung steht für die Beschriftung, das Ihr Modell den Daten zuweist.
Anhand der Konfusionsmatrix können Sie ermitteln, wie gut das Modell das Vorliegen oder Nichtvorliegen einer Bedingung voraussagt. Wenn Sie betrügerische Transaktionen voraussagen, können Sie die Konfusionsmatrix verwenden, um sich ein Bild von der Sensibilität und Spezifität des Modells zu machen. Die Sensibilität bezieht sich auf die Fähigkeit des Modells, betrügerische Transaktionen zu erkennen. Die Spezifität bezieht sich auf die Fähigkeit des Modells, zu verhindern, dass nicht betrügerische Transaktionen als betrügerisch erkannt werden.
Es folgt ein Beispiel für Quick-Modell-Ausgaben für ein Regressionsproblem.

Übersicht der Funktionen
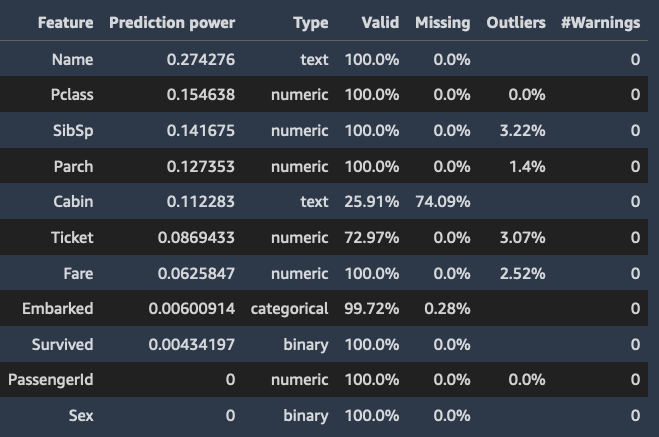
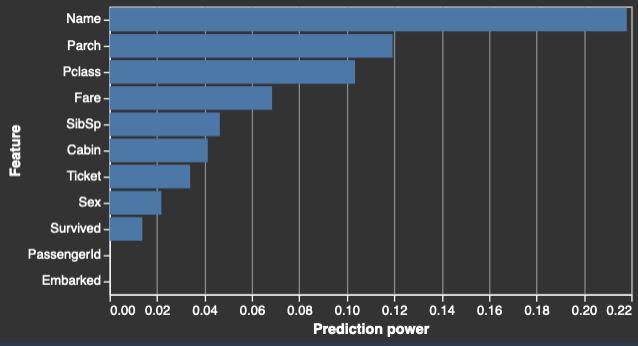
Wenn Sie eine Zielspalte angeben, ordnet Data Wrangler die Funktionen nach ihrer Voraussagekraft. Die Voraussagekraft wird anhand der Daten gemessen, nachdem sie zu 80 % in Trainingseinheiten und zu 20 % in Validierungsstufen aufgeteilt wurden. Data Wrangler passt ein Modell für jedes Merkmal separat im Trainingsbereich an. Es wendet nur eine minimale Merkmalsvorverarbeitung an und misst die Voraussageleistung anhand der Validierungsdaten.
Es normalisiert die Werte auf den Bereich [0,1]. Höhere Voraussagewerte weisen auf Spalten hin, die für die Voraussage des Ziels allein nützlicher sind. Niedrigere Werte weisen auf Spalten hin, die keine Voraussage für die Zielspalte bieten.
Es ist ungewöhnlich, dass eine Spalte, die für sich genommen nicht prädiktiv ist, prädiktiv ist, wenn sie zusammen mit anderen Spalten verwendet wird. Sie können die Voraussagewerte getrost verwenden, um zu bestimmen, ob eine Funktion in Ihrem Datensatz prädiktiv ist.
Ein niedriger Wert weist normalerweise darauf hin, dass die Funktion überflüssig ist. Ein Wert von 1 impliziert perfekte Voraussagefähigkeiten, was häufig auf undichte Zielstellen hindeutet. Undichte Zielstellen treten normalerweise auf, wenn der Datensatz eine Spalte enthält, die zum Voraussagezeitpunkt nicht verfügbar ist. Es könnte sich beispielsweise um ein Duplikat der Zielspalte handeln.
Im Folgenden finden Sie Beispiele für die Tabelle und das Histogramm, die den Voraussagewert der einzelnen Funktionen zeigen.
Beispiele
Data Wrangler liefert Informationen darüber, ob Ihre Stichproben anomal sind oder ob Ihr Datensatz Duplikate enthält.
Data Wrangler erkennt anomale Proben mithilfe des Isolation-Forest-Algorithmus. Der Isolation Forest ordnet jeder Stichprobe (Zeile) des Datensatzes einen Anomaliewert zu. Niedrige Anomaliewerte deuten auf anomale Proben hin. Hohe Werte stehen im Zusammenhang mit Proben, die nicht anomale Werte aufweisen. Proben mit einem negativen Anomaliewert gelten in der Regel als anomal und Proben mit einem positiven Anomaliewert gelten als nicht anomal.
Wenn Sie sich eine Probe ansehen, die möglicherweise anomal ist, empfehlen wir Ihnen, auf ungewöhnliche Werte zu achten. Beispielsweise könnten Sie ungewöhnliche Werte haben, die auf Fehler bei der Erfassung und Verarbeitung der Daten zurückzuführen sind. Im Folgenden finden Sie ein Beispiel für die anomalsten Stichproben gemäß der Implementierung des Isolation-Forest-Algorithmus durch Data Wrangler. Wir empfehlen, bei der Untersuchung der anomalen Stichproben Fachwissen und Geschäftslogik zu verwenden.
Data Wrangler erkennt doppelte Zeilen und berechnet das Verhältnis doppelter Zeilen in Ihren Daten. Einige Datenquellen könnten gültige Duplikate enthalten. Andere Datenquellen könnten Duplikate enthalten, die auf Probleme bei der Datensammlung hinweisen. Doppelte Stichproben, die aus einer fehlerhaften Datensammlung resultieren, könnten Machine-Learning-Prozesse beeinträchtigen, die auf der Aufteilung der Daten in unabhängige Trainings- und Validierungsbereiche beruhen.
Im Folgenden sind Elemente des Insights-Berichts aufgeführt, die durch doppelte Stichproben beeinträchtigt werden können:
-
Quick-Modell
-
Schätzung der Voraussageleistung
-
Automatische Hyperparameteroptimierung
Mithilfe der Transformation Drop-Duplikat unter Zeilen verwalten können Sie doppelte Stichproben aus dem Datensatz entfernen. Data Wrangler zeigt Ihnen die am häufigsten duplizierten Zeilen.
Definitionen
Im Folgenden finden Sie Definitionen für die Fachbegriffe, die im Data Insights-Bericht verwendet werden.
