Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Workloads zur Datentransformation mit SageMaker Verarbeitung
SageMaker Verarbeitung bezieht sich auf die Fähigkeit der SageMaker KI, Aufgaben vor und nach der Verarbeitung, Feature-Engineering und Modellevaluierung in der vollständig verwalteten SageMaker KI-Infrastruktur auszuführen. Diese Aufgaben werden als Verarbeitungsaufträge ausgeführt. Im Folgenden finden Sie Informationen und Ressourcen, um mehr über die SageMaker Verarbeitung zu erfahren.
Mithilfe der SageMaker Processing API können Datenwissenschaftler Skripte und Notizbücher ausführen, um Datensätze zu verarbeiten, zu transformieren und zu analysieren, um sie für maschinelles Lernen vorzubereiten. In Kombination mit den anderen wichtigen Aufgaben des maschinellen Lernens, die von SageMaker KI bereitgestellt werden, wie Schulung und Hosting, bietet Ihnen Processing die Vorteile einer vollständig verwalteten Umgebung für maschinelles Lernen, einschließlich der gesamten in SageMaker KI integrierten Sicherheits- und Compliance-Unterstützung. Sie haben die Flexibilität, die integrierten Datenverarbeitungscontainer zu verwenden oder Ihre eigenen Container für die benutzerdefinierte Verarbeitungslogik zu verwenden und dann Jobs zur Ausführung auf einer SageMaker KI-verwalteten Infrastruktur einzureichen.
Anmerkung
Sie können einen Verarbeitungsauftrag programmgesteuert erstellen, indem Sie die CreateProcessingJobAPI-Aktion in einer beliebigen von SageMaker KI unterstützten Sprache aufrufen oder indem Sie den verwenden. AWS CLI Informationen dazu, wie diese API-Aktion in eine Funktion in der Sprache Ihrer Wahl übersetzt wird, finden Sie im Abschnitt „Siehe auch“ von CreateProcessingJob und wählen Sie ein SDK aus. Ein Beispiel für Python-Benutzer finden Sie im Abschnitt Amazon SageMaker Processing
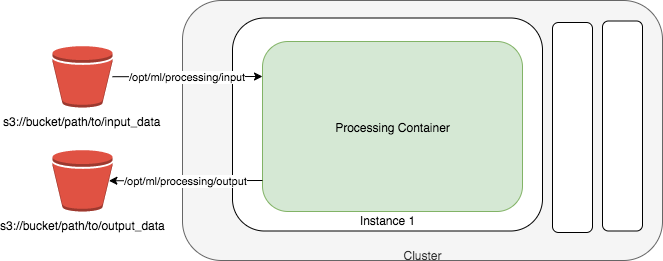
Das folgende Diagramm zeigt, wie Amazon SageMaker AI einen Verarbeitungsjob auslöst. Amazon SageMaker AI nimmt Ihr Skript, kopiert Ihre Daten aus Amazon Simple Storage Service (Amazon S3) und ruft dann einen Verarbeitungscontainer ab. Die zugrunde liegende Infrastruktur für einen Verarbeitungsauftrag wird vollständig von Amazon SageMaker AI verwaltet. Nachdem Sie einen Verarbeitungsauftrag eingereicht haben, startet SageMaker KI die Compute-Instances, verarbeitet und analysiert die Eingabedaten und gibt die Ressourcen nach Abschluss frei. Die Ausgabe des Processing-Auftrages wird im Amazon-S3-Bucket gespeichert, den Sie angegeben haben.
Anmerkung
Die Eingabedaten müssen in einem Amazon-S3-Bucket gespeichert sein. Alternativ können Sie Amazon Athena oder Amazon Redshift als Eingabequellen verwenden.
Tipp
Bewährte Methoden für verteiltes Rechnen für Training und Verarbeitung von Machine Learning (ML) im Allgemeinen finden Sie unter Verteiltes Rechnen mit Best Practices für SageMaker KI.
Verwenden Sie Amazon SageMaker Processing Sample Notebooks
Anhand von zwei Beispiel-Jupyter-Notebooks zeigen wir, wie Datenvorverarbeitung, Modellauswertung oder beides durchgeführt werden.
Ein Beispielnotizbuch, das zeigt, wie Scikit-Learn-Skripte ausgeführt werden, um Datenvorverarbeitung und Modelltraining und -auswertung mit dem SageMaker Python-SDK for Processing durchzuführen, finden Sie unter scikit-learn Processing.
Ein Beispielnotizbuch, das zeigt, wie Amazon SageMaker Processing für die verteilte Datenvorverarbeitung mit Spark verwendet wird, finden Sie unter Distributed Processing (Spark)
Anweisungen zum Erstellen und Zugreifen auf Jupyter-Notebook-Instanzen, mit denen Sie diese Beispiele in KI ausführen können, finden Sie unter. SageMaker SageMaker Amazon-Notebook-Instanzen Nachdem Sie eine Notebook-Instanz erstellt und geöffnet haben, wählen Sie die Registerkarte SageMaker KI-Beispiele, um eine Liste aller KI-Beispiele anzuzeigen. SageMaker Zum Öffnen eines Notebooks wählen Sie die Registerkarte Verwenden und dann Kopie erstellen aus.
Überwachen Sie SageMaker Amazon-Verarbeitungsaufträge mit CloudWatch Protokollen und Metriken
Amazon SageMaker Processing stellt CloudWatch Amazon-Protokolle und -Metriken zur Überwachung von Verarbeitungsaufträgen bereit. CloudWatch bietet Metriken zu CPU, GPU, Arbeitsspeicher, GPU-Speicher und Festplatte sowie Ereignisprotokollierung. Weitere Informationen erhalten Sie unter SageMaker Amazon-KI-Metriken bei Amazon CloudWatch und CloudWatch Protokolle für Amazon SageMaker AI.
