Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Bereiten Sie einen Datensatz vor
In diesem Schritt laden Sie den Datensatz Adult Census
Um das folgende Beispiel auszuführen, fügen Sie den Beispielcode in eine Zelle in Ihrer Notebook-Instance ein.
Laden Sie den Datensatz zur Volkszählung von Erwachsenen mit SHAP
Importieren Sie den Datensatz der Volkszählung für Erwachsene mithilfe der SHAP-Bibliothek wie folgt:
import shap X, y = shap.datasets.adult() X_display, y_display = shap.datasets.adult(display=True) feature_names = list(X.columns) feature_names
Anmerkung
Wenn der aktuelle Jupyter-Kernel nicht über die SHAP-Bibliothek verfügt, installieren Sie sie, indem Sie den folgenden conda Befehl ausführen:
%conda install -c conda-forge shap
Wenn Sie verwenden JupyterLab, müssen Sie den Kernel manuell aktualisieren, nachdem die Installation und die Updates abgeschlossen sind. Führen Sie das folgende IPython Skript aus, um den Kernel herunterzufahren (der Kernel wird automatisch neu gestartet):
import IPython IPython.Application.instance().kernel.do_shutdown(True)
Das feature_names Listenobjekt sollte die folgende Liste von Features zurückgeben:
['Age', 'Workclass', 'Education-Num', 'Marital Status', 'Occupation', 'Relationship', 'Race', 'Sex', 'Capital Gain', 'Capital Loss', 'Hours per week', 'Country']
Tipp
Wenn Sie mit unbeschrifteten Daten beginnen, können Sie Amazon SageMaker Ground Truth verwenden, um innerhalb von Minuten einen Datenkennzeichnungsworkflow zu erstellen. Weitere Informationen finden Sie unter Beschriftungsdaten.
Überblick über den Datensatz
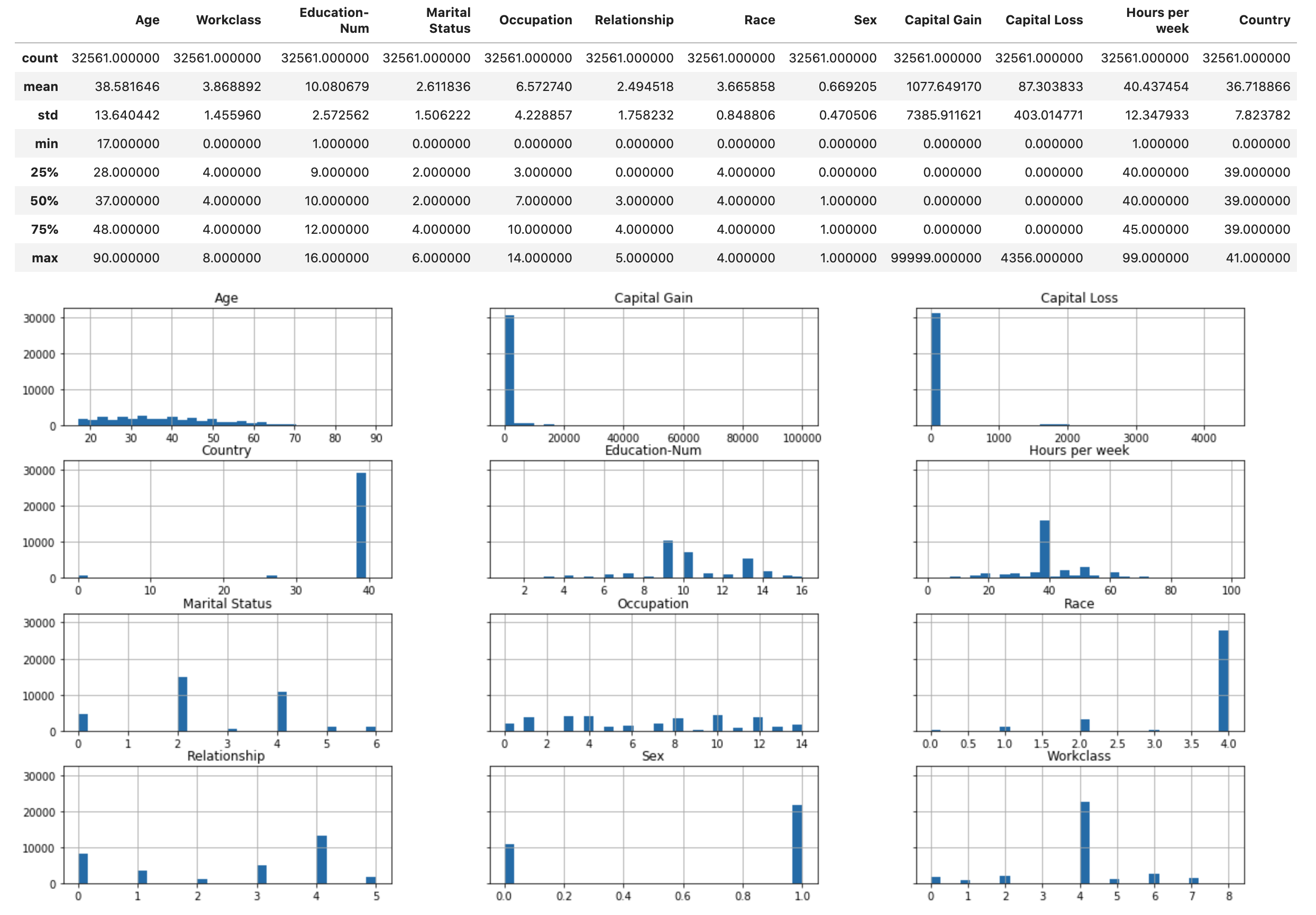
Führen Sie das folgende Skript aus, um die statistische Übersicht des Datensatzes und die Histogramme der numerischen Merkmale anzuzeigen.
display(X.describe()) hist = X.hist(bins=30, sharey=True, figsize=(20, 10))
Tipp
Wenn Sie einen Datensatz verwenden möchten, der bereinigt und transformiert werden muss, können Sie die Datenvorverarbeitung und das Feature-Engineering mit Amazon SageMaker Data Wrangler vereinfachen und optimieren. Weitere Informationen finden Sie unter Vorbereiten von ML-Daten mit Amazon SageMaker Data Wrangler.
Teilen Sie den Datensatz in Trainings-, Validierungs- und Testdatensätze auf
Teilen Sie den Datensatz mithilfe von Sklearn in einen Trainingssatz und einen Testsatz auf. Der Trainingssatz wird verwendet, um das Modell zu trainieren, während der Testsatz verwendet wird, um die Leistung des endgültigen trainierten Modells zu bewerten. Der Datensatz wird nach dem Zufallsprinzip mit der festen Zufallszahl sortiert: 80 Prozent des Datensatzes für den Trainingssatz und 20 Prozent davon für einen Testsatz.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1) X_train_display = X_display.loc[X_train.index]
Teilen Sie den Trainingssatz auf, um einen Validierungssatz zu trennen. Der Validierungssatz wird verwendet, um die Leistung des trainierten Modells zu bewerten und gleichzeitig die Hyperparameter des Modells zu optimieren. 75 Prozent des Trainingssatzes werden zum endgültigen Trainingssatz, und der Rest ist der Validierungssatz.
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=1) X_train_display = X_display.loc[X_train.index] X_val_display = X_display.loc[X_val.index]
Richten Sie mithilfe des Pandas-Pakets jeden Datensatz explizit aus, indem Sie die numerischen Merkmale mit den tatsächlichen Beschriftungen verketten.
import pandas as pd train = pd.concat([pd.Series(y_train, index=X_train.index, name='Income>50K', dtype=int), X_train], axis=1) validation = pd.concat([pd.Series(y_val, index=X_val.index, name='Income>50K', dtype=int), X_val], axis=1) test = pd.concat([pd.Series(y_test, index=X_test.index, name='Income>50K', dtype=int), X_test], axis=1)
Prüfen Sie, ob der Datensatz wie erwartet aufgeteilt und strukturiert ist:
train
validation
test
Konvertiert das Trainings- und Validierungsdatensätze in CSV-Dateien
Konvertiert die Objekte train und validation DataFrame in CSV-Dateien, sodass sie dem Eingabedateiformat für den XGBoost Algorithmus entsprechen.
# Use 'csv' format to store the data # The first column is expected to be the output column train.to_csv('train.csv', index=False, header=False) validation.to_csv('validation.csv', index=False, header=False)
Hochladen der Datensätze auf Amazon S3
Laden Sie mithilfe von SageMaker KI und Boto3 die Trainings- und Validierungsdatensätze in den standardmäßigen Amazon S3 S3-Bucket hoch. Die Datensätze im S3-Bucket werden von einer rechenoptimierten SageMaker Instance auf Amazon EC2 für Schulungen verwendet.
Der folgende Code richtet die standardmäßige S3-Bucket-URI für Ihre aktuelle SageMaker AI-Sitzung ein, erstellt einen neuen demo-sagemaker-xgboost-adult-income-prediction Ordner und lädt die Trainings- und Validierungsdatensätze in den Unterordner hoch. data
import sagemaker, boto3, os bucket = sagemaker.Session().default_bucket() prefix = "demo-sagemaker-xgboost-adult-income-prediction" boto3.Session().resource('s3').Bucket(bucket).Object( os.path.join(prefix, 'data/train.csv')).upload_file('train.csv') boto3.Session().resource('s3').Bucket(bucket).Object( os.path.join(prefix, 'data/validation.csv')).upload_file('validation.csv')
Führen Sie den folgenden Befehl aus AWS CLI , um zu überprüfen, ob die CSV-Dateien erfolgreich in den S3-Bucket hochgeladen wurden.
! aws s3 ls {bucket}/{prefix}/data --recursive
Dies sollte die folgende Ausgabe ergeben:

