Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Verwendung eines Verarbeitungsauftrags für benutzerdefinierte Geodaten-Workloads
Mit Amazon SageMaker Processing können Sie eine vereinfachte, verwaltete SageMaker KI-Umgebung nutzen, um Ihre Datenverarbeitungs-Workloads mit dem speziell entwickelten Geospatial-Container auszuführen.
Die zugrunde liegende Infrastruktur für einen Amazon SageMaker Processing-Job wird vollständig von SageMaker KI verwaltet. Während eines Verarbeitungsauftrags werden Cluster-Ressourcen für die Dauer Ihres Jobs bereitgestellt und nach Abschluss eines Jobs bereinigt.
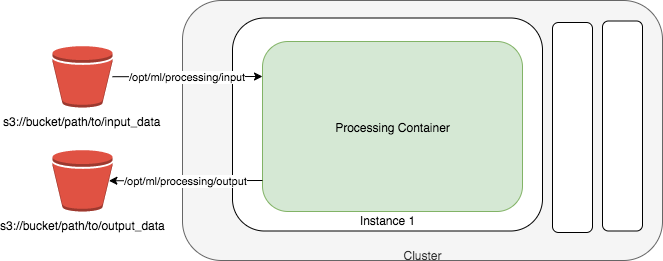
Das obige Diagramm zeigt, wie SageMaker KI einen Auftrag zur Verarbeitung von Geodaten ausführt. SageMaker KI nimmt Ihr Geospatial-Workload-Skript, kopiert Ihre Geodaten aus Amazon Simple Storage Service (Amazon S3) und ruft dann den angegebenen Geodatencontainer ab. Die dem Verarbeitungsauftrag zugrunde liegende Infrastruktur wird vollständig von KI verwaltet. SageMaker Cluster-Ressourcen werden für die Dauer Ihres Jobs bereitgestellt und nach Abschluss eines Jobs bereinigt. Die Ausgabe des Verarbeitungsauftrags wird in dem von Ihnen angegebenen Bucket gespeichert.
Einschränkungen bei der Pfadbenennung
Die lokalen Pfade innerhalb eines Containers für Verarbeitungsaufträge müssen mit /opt/ml/processing/ beginnen.
SageMaker Geospatial stellt einen speziell entwickelten Container bereit081189585635.dkr.ecr.us-west-2.amazonaws.com/sagemaker-geospatial-v1-0:latest, der bei der Ausführung eines Verarbeitungsauftrags spezifiziert werden kann.
Themen
