Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Protokolle und Metriken der Inferenz-Pipeline
Die Überwachung ist wichtig, um die Zuverlässigkeit, Verfügbarkeit und Leistung der Amazon SageMaker AI-Ressourcen aufrechtzuerhalten. Verwenden Sie CloudWatch Amazon-Protokolle und Fehlermeldungen, um die Leistung der Inferenz-Pipeline zu überwachen und Fehler zu beheben. Informationen zu den von SageMaker AI bereitgestellten Überwachungstools finden Sie unterAWS Ressourcen in Amazon SageMaker AI überwachen.
Verwenden von Metriken zum Überwachen von Multicontainer-Modellen
Verwenden Sie Amazon, um die Multi-Container-Modelle in Inference Pipelines zu überwachen. CloudWatch CloudWatchsammelt Rohdaten und verarbeitet sie zu lesbaren Metriken, die nahezu in Echtzeit verfügbar sind. SageMaker KI-Schulungsjobs und Endpunkte schreiben CloudWatch Metriken und Protokolle in den AWS/SageMaker Namespace.
Die folgenden Tabellen listen die Metriken und Dimensionen für Folgendes auf:
-
Endpunkt-Aufrufe
-
Trainingsaufträge, Stapeltransformationsaufträge und Endpunkt-Instances
Eine Dimension ist ein Name-Wert-Paar, durch das eine Metrik eindeutig identifiziert wird. Sie können einer Metrik bis zu 10 Dimensionen zuweisen. Weitere Informationen zur Überwachung mit CloudWatch finden Sie unter. SageMaker Amazon-KI-Metriken bei Amazon CloudWatch
Kennzahlen für Endpunktaufrufe
Der AWS/SageMaker-Namespace enthält die folgenden Anforderungsmetriken von InvokeEndpoint-Aufrufen.
Metriken werden in Intervallen von einer Minute gemeldet.
| Metrik | Beschreibung |
|---|---|
Invocation4XXErrors |
Die Anzahl der Einheiten: keine Gültige Statistiken: |
Invocation5XXErrors |
Die Anzahl der Einheiten: keine Gültige Statistiken: |
Invocations |
Die an einen Modellendpunkt gesendeten Mit der Einheiten: keine Gültige Statistiken: |
InvocationsPerInstance |
Die Anzahl der Endpunktaufrufen, die an ein Modell gesendet wurden, normalisiert durch Einheiten: keine Gültige Statistiken: |
ModelLatency |
Die Zeit, die das/die Modell(e) für die Antwort gebraucht hat/haben. Dies umfasst die Zeit, die zum Senden der Anforderung, zum Abrufen der Antwort vom Modell-Container und zum Abschluss der Inferenz in dem Container benötigt wurde. ModelLatency ist die Gesamtzeit von allen Containern in einer Inferenz-Pipeline.Einheiten: Mikrosekunden Gültige Statistiken: |
OverheadLatency |
Die Zeit, die zu der Zeit hinzukommt, die SageMaker KI für die Beantwortung einer Kundenanfrage aufgrund von Overhead benötigt hat. Einheiten: Mikrosekunden Gültige Statistiken: |
ContainerLatency |
Die Zeit, die ein Inference-Pipeline-Container benötigt hat, um zu antworten, aus SageMaker Sicht der KI. ContainerLatencybeinhaltet die Zeit, die benötigt wurde, um die Anfrage zu senden, die Antwort aus dem Container des Modells abzurufen und die Inferenz im Container abzuschließen.Einheiten: Mikrosekunden Gültige Statistiken: |
Dimensionen für Kennzahlen für den Aufruf von Endpunkten
| Dimension | Beschreibung |
|---|---|
EndpointName, VariantName, ContainerName |
Filtert Endpunktaufrufmetriken für ein |
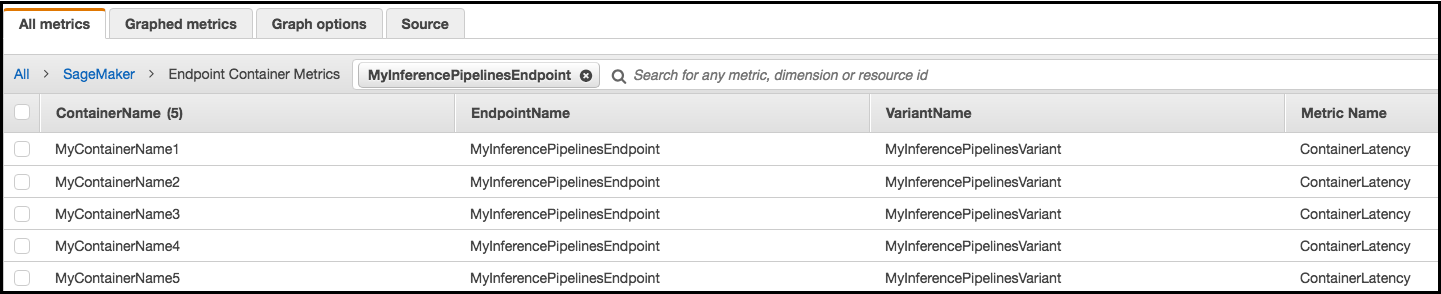
Für einen Inferenz-Pipeline-Endpunkt CloudWatch listet die Latenzmetriken pro Container in Ihrem Konto wie folgt als Endpunkt-Container-Metriken und Endpunktvarianten-Metriken im SageMaker AI-Namespace auf. Die ContainerLatency-Metrik wird nur für Inferenz-Pipelines angezeigt.
Für jeden Endpunkt und jeden Container zeigen die Latenzmetriken die Namen für den Container, den Endpunkt, die Variante und die Metrik an.
Trainingsauftrag-, Stapeltransformationsauftrag- und Endpunkt-Instance-Metriken
Die Namespaces /aws/sagemaker/TrainingJobs, /aws/sagemaker/TransformJobs und /aws/sagemaker/Endpoints beinhalten die folgenden Metriken für die Trainingsaufträge und Endpunkt-Instances.
Metriken werden in Intervallen von einer Minute gemeldet.
| Metrik | Beschreibung |
|---|---|
CPUUtilization |
Der Prozentsatz der CPU-Einheiten, die von den Containern auf einer Instance verwendet werden. Der Wert liegt zwischen 0% und 100% und wird mit der Anzahl von multipliziert. CPUs Wenn es beispielsweise vier gibt CPUs, Bei Trainingsaufträgen ist Bei Stapeltransformationsaufträgen ist Bei Multi-Container-Modellen ist Bei Endpunkt-Varianten ist Einheiten: Prozent |
MemoryUtilization |
Der Prozentsatz des Speichers, der von den Containern auf einer Instance belegt wird. Dieser Wert reicht von 0 bis 100 %. Bei Trainingsaufträgen ist Bei Stapeltransformationsaufträgen ist MemoryUtilization ist die Summe des Speichers für alle Container, die auf der Instance ausgeführt werden.Bei Endpunkt-Varianten ist Einheiten: Prozent |
GPUUtilization |
Der Prozentsatz der GPU-Einheiten, die von den Containern verwendet werden, die auf einer Instance ausgeführt werden. Bei Trainingsaufträgen ist Bei Stapeltransformationsaufträgen ist Bei Multi-Container-Modellen ist Bei Endpunkt-Varianten ist Einheiten: Prozent |
GPUMemoryUtilization |
Der Prozentsatz des GPU-Speichers, der von den Containern verwendet wird, die auf einer Instance ausgeführt werden. GPUMemoryDie Auslastung reicht von 0 bis 100% und wird mit der Anzahl von GPUs multipliziert. Wenn es beispielsweise vier gibt GPUs, Bei Trainingsaufträgen ist Bei Stapeltransformationsaufträgen ist Bei Multi-Container-Modellen ist Bei Endpunkt-Varianten ist Einheiten: Prozent |
DiskUtilization |
Der Prozentsatz des Festplattenspeichers, der von den Containern verwendet wird, die auf einer Instance ausgeführt werden. DiskUtilization reicht von 0 bis 100%. Diese Metrik wird für Stapeltransformationsaufträge nicht unterstützt. Bei Trainingsaufträgen ist Bei Endpunkt-Varianten ist Einheiten: Prozent |
Dimensions for Training Job, Batch Transform Job, and Endpoint Instance Metrics (Dimensionen für Instance-Metriken für Trainingsaufträge, Stapeltransformationsaufträge und Endpunkte)
| Dimension | Beschreibung |
|---|---|
Host |
Bei Trainingsaufträgen hat Bei Stapeltransformationsaufträgen hat Bei Endpunkten hat |
Um Ihnen beim Debuggen Ihrer Trainingsjobs, Endpunkte und Lebenszykluskonfigurationen für Notebooks zu helfen, sendet SageMaker KI auch alles, was ein Algorithmuscontainer, ein Modellcontainer oder eine Notebook-Instance-Lebenszykluskonfiguration an stdout oder stderr an Amazon CloudWatch Logs sendet. Sie können diese Informationen zum Debugging und zur Fortschrittanalyse verwenden.
Verwenden von Protokollen zum Überwachen einer Inferenz-Pipeline
In der folgenden Tabelle sind die Protokollgruppen und Protokollstreams aufgeführt, die SageMaker AI. an Amazon sendet CloudWatch
Ein Protokollstream ist eine Abfolge von Protokollereignissen, die dieselbe Quelle nutzen. Jede einzelne Logquelle CloudWatch bildet einen separaten Log-Stream. Eine Protokollgruppe ist eine Gruppe von Protokollstreams, die dieselben Einstellungen für die Aufbewahrung, Überwachung und Zugriffskontrolle besitzen.
Protokolle
| Protokollgruppenname | Protokollstreamname |
|---|---|
/aws/sagemaker/TrainingJobs |
|
/aws/sagemaker/Endpoints/[EndpointName] |
|
|
|
|
|
|
|
/aws/sagemaker/NotebookInstances |
|
/aws/sagemaker/TransformJobs |
|
|
|
|
|
|
Anmerkung
SageMaker AI erstellt die /aws/sagemaker/NotebookInstances Protokollgruppe, wenn Sie eine Notebook-Instanz mit einer Lebenszykluskonfiguration erstellen. Weitere Informationen finden Sie unter Anpassung einer SageMaker Notebook-Instanz mithilfe eines LCC-Skripts.
Weitere Informationen zur SageMaker KI-Protokollierung finden Sie unterCloudWatch Protokolle für Amazon SageMaker AI.
