This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
Heterogeneous data ingestion patterns
Heterogeneous data files ingestion
This section covers use cases where you are looking to ingest the data and change the original file format and/or load it into a purpose-built data storage destination and/or perform transformations while ingesting data. The use case for this pattern usually falls under outside-in or inside-out data movement in the Modern Data architecture. Common use cases for inside-out data movement include loading the data warehouse storage (for example, Amazon Redshift) or data indexing solutions (for example, Amazon OpenSearch Service) from data lake storage.
Common use cases for outside-in data movement are ingesting CSV files from on-premises to an optimized parquet format for querying or to merge the data lake with changes from the new files. These may require complex transformations along the way, which may involve processes like changing data types, performing lookups, cleaning, and standardizing data, and so on before they are finally ingested into the destination system. Consider the following tools for these use cases.
Data extract, transform, and load (ETL)
AWS Glue
You can build event-driven pipelines for ETL with AWS Glue ETL. Refer to the following example.
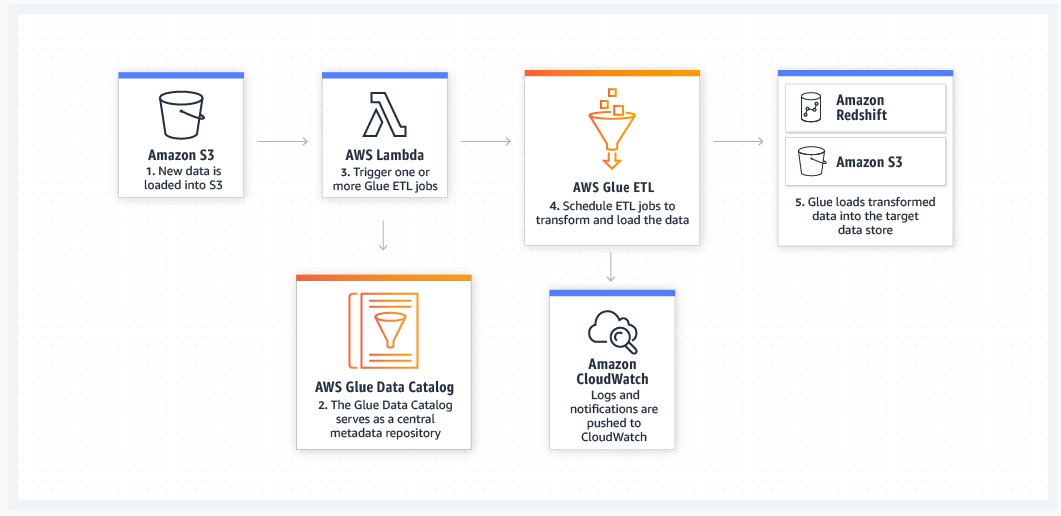
AWS Glue ETL architecture
You can use AWS Glue as a managed ETL tool to connect to your
data centers for ingesting data from files while transforming
data and then load the data into your data storage of choice in
AWS (or example, Amazon S3 data lake storage or Amazon Redshift). For details on how to set up AWS Glue in a hybrid
environment when you are ingesting data from on-premises data
centers, refer to
How
to access and analyze on-premises data stores using AWS Glue
AWS Glue supports various format options for files both as input and as output. These formats include avro, csv, ion, orc, and more. For a complete list of supported formats, refer to Format Options for ETL Inputs and Outputs in AWS Glue.
AWS Glue provide various connectors to connect to the different source and destination targets. For a reference of all connectors and their usage as source or sink, refer to Connection Types and Options for ETL in AWS Glue.
AWS Glue supports Python and Scala for programming your ETL. As part of the transformation, AWS Glue provides various transform classes for programming with both PySpark and Scala.
You can use AWS Glue to meet the most complex data ingestion
needs for your Modern Data architecture. Most of these ingestion
workloads must be automated in enterprises and can follow a
complex workflow. You can use
Workflows
in AWS Glue to achieve orchestration of AWS Glue workloads. For
more complex workflow orchestration and automation, use
AWS Data Pipeline
Using native tools to ingest data into data management systems
AWS services may also provide native tools/APIs to ingest data from files into respective data management systems. For example, Amazon Redshift provides the COPY command which uses the Amazon Redshift massively parallel processing (MPP) architecture to read and load data in parallel from files in Amazon S3, from an Amazon DynamoDB table, or from text output from one or more remote hosts. For a reference to the Amazon Redshift COPY command, refer to Using a COPY command to load data. Note that the files need to follow certain formatting to be loaded successfully. For details, refer to Preparing your input data. You can use AWS Glue ETL to perform the required transformation to bring the input file in the right format.
Amazon Keyspaces (for Apache Cassandra) is a scalable, highly available, managed Cassandra-compatible database service that provides a cqlsh copy command to load data into an Amazon Keyspaces table. For more details, including best practices and performance tuning, refer to Loading data into Amazon Keyspaces with cqlsh.
Using third-party vendor tools
Many customers may already be using third-party vendor tools for ETL jobs in their data centers. Depending upon the access, scalability, skills, and licensing needs, customers can choose to use these tools to ingest files into the Modern Data architecture for various data movement patterns. Some third-party tools include MS SQL Server Integration Services (SSIS), IBM DataStage, and more. This whitepaper does not cover those options here. However, it is important to consider aspects like native connectors provided by these tools (for example, having connectors for Amazon S3, or Amazon Athena) as opposed to getting a connector from another third-party. Further considerations include security scalability, manageability, and maintenance of those options to meet your enterprise data ingestion needs.
Streaming data ingestion
One of the core capabilities of a Modern Data architecture is the ability to ingest streaming data quickly and easily. Streaming data is data that is generated continuously by thousands of data sources, which typically send in the data records simultaneously, and in small sizes (order of Kilobytes). Streaming data includes a wide variety of data such as log files generated by customers using your mobile or web applications, ecommerce purchases, in-game player activity, information from social networks, financial trading floors, or geospatial services, and telemetry from connected devices or instrumentation in data centers.
This data must be processed sequentially and incrementally on a record-by-record basis or over sliding time windows, and used for a wide variety of analytics including correlations, aggregations, filtering, and sampling. When ingesting streaming data, the use case may require to first load the data into your data lake before processing it, or it may need to be analyzed as it is streamed and stored in the destination data lake or purpose-built storage.
Information derived from such analysis gives companies visibility into many aspects of their business and customer activity—such as service usage (for metering/billing), server activity, website clicks, and geo-location of devices, people, and physical goods—and enables them to respond promptly to emerging situations. For example, businesses can track changes in public sentiment on their brands and products by continuously analyzing social media streams and respond in a timely fashion as the necessity arises.
AWS provides several options to work with streaming data. You can
take advantage of the managed streaming data services offered by
Amazon Kinesis
AWS offers streaming and analytics managed services such as Amazon Kinesis Data
Firehose
In addition, you can run other streaming data platforms, such as
Apache Flume, Apache Spark Streaming, and Apache Storm, on Amazon EC2 and Amazon EMR
Amazon Data Firehose
Amazon Data Firehose is the easiest way to load
streaming data into AWS. You can use
Firehose
Amazon Data Firehose is a fully managed service for delivering real-time streaming data directly to Amazon S3. Firehose automatically scales to match the volume and throughput of streaming data, and requires no ongoing administration. Firehose can also be configured to transform streaming data before it’s stored in Amazon S3. Its transformation capabilities include compression, encryption, data batching, and AWS Lambda functions.
Firehose can compress data before it’s stored in Amazon S3. It currently supports GZIP, ZIP, and SNAPPY compression formats. GZIP is the preferred format because it can be used by Amazon Athena, Amazon EMR, and Amazon Redshift.
Firehose encryption supports Amazon S3 server-side
encryption with
AWS KMS
Finally, Firehose can invoke AWS Lambda functions to transform incoming source data and deliver it to Amazon S3. Common transformation functions include transforming Apache Log and Syslog formats to standardized JSON and/or CSV formats. The JSON and CSV formats can then be directly queried using Amazon Athena. If using a Lambda data transformation, you can optionally back up raw source data to another S3 bucket, as shown in the following figure.

Delivering real-time streaming data with Amazon Data Firehose to Amazon S3 with optional backup
Sending data to an Amazon Data Firehose Delivery Stream
There are several options to send data to your delivery stream. AWS offers SDKs for many popular programming languages, each of which provides APIs for Firehose. AWS has also created a utility to help send data to your delivery stream.
Using the API
The Firehose API offers two operations for sending data to your delivery stream: PutRecord sends one data record within one call, PutRecordBatch can send multiple data records within one call.
In each method, you must specify the name of the delivery stream and the data record, or array of data records, when using the method. Each data record consists of a data BLOB that can be up to 1,000 KB in size and any kind of data.
For detailed information and sample code for the Firehose API operations, refer to Writing to a Firehose Delivery Stream Using the AWS SDK.
Using the Amazon Kinesis Agent
The Amazon Kinesis Agent is a stand-alone Java software application that offers an easy way to collect and send data to Kinesis Data Streams and Firehose. The agent continuously monitors a set of files and sends new data to your stream. The agent handles file rotation, checkpointing, and retry upon failures. It delivers all of your data in a reliable, timely, and simple manner. It also emits Amazon CloudWatch metrics to help you better monitor and troubleshoot the streaming process.
You can install the agent on Linux-based server environments such as web servers, log servers, and database servers. After installing the agent, configure it by specifying the files to monitor and the destination stream for the data. After the agent is configured, it durably collects data from the files and reliably sends it to the delivery stream.
The agent can monitor multiple file directories and write to multiple streams. It can also be configured to pre-process data records before they’re sent to your stream or delivery stream.
If you’re considering a migration from a traditional batch file system to streaming data, it’s possible that your applications are already logging events to files on the file systems of your application servers. Or, if your application uses a popular logging library (such as Log4j), it is typically a straight-forward task to configure it to write to local files.
Regardless of how the data is written to a log file, you should consider using the agent in this scenario. It provides a simple solution that requires little or no change to your existing system. In many cases, it can be used concurrently with your existing batch solution. In this scenario, it provides a stream of data to Kinesis Data Streams, using the log files as a source of data for the stream.
In our example scenario, we chose to use the agent to send streaming data to the delivery stream. The source is on-premises log files, so forwarding the log entries to Firehose was a simple installation and configuration of the agent. No additional code was needed to start streaming the data.

Kinesis Agent to monitor multiple file directories
Data transformation
In some scenarios, you may want to transform or enhance your streaming data before it is delivered to its destination. For example, data producers might send unstructured text in each data record, and you may need to transform it to JSON before delivering it to Amazon OpenSearch Service.
To enable streaming data transformations, Firehose
uses an AWS Lambda
Data transformation flow
When you enable Firehose data transformation, Firehose buffers incoming data up to 3 MB or the buffering size you specified for the delivery stream, whichever is smaller. Firehose then invokes the specified Lambda function with each buffered batch asynchronously. The transformed data is sent from Lambda to Firehose for buffering. Transformed data is delivered to the destination when the specified buffering size or buffering interval is reached, whichever happens first. The following figure illustrates this process for a delivery stream that delivers data to Amazon S3.

Kinesis Agent to monitor multiple file directories and write to Firehose
Amazon Kinesis Data Streams
Amazon Kinesis Data Streams
Kinesis Data Streams provide many more controls in terms of how you want to scale the service to meet high demand use cases, such as real-time analytics, gaming data feeds, mobile data captures, log and event data collection, and so on. You can then build applications that consume the data from Amazon Kinesis Data Streams to power real-time dashboards, generate alerts, implement dynamic pricing and advertising, and more. Amazon Kinesis Data Streams supports your choice of stream processing framework including Kinesis Client Library (KCL), Apache Storm, and Apache Spark Streaming.

Custom real-time pipelines using stream-processing frameworks
Sending data to Amazon Kinesis Data Streams
There are several mechanisms to send data to your stream. AWS offers SDKs for many popular programming languages, each of which provides APIs for Kinesis Data Streams. AWS has also created several utilities to help send data to your stream.
Amazon Kinesis Agent
The Amazon Kinesis Agent can be used to send data to Kinesis Data Streams. For details on installing and configuring the Kinesis agent, refer to Writing to Firehose Using Kinesis Agent.
Amazon Kinesis Producer Library (KPL)
The KPL simplifies producer application development, allowing developers to achieve high write throughput to one or more Kinesis streams. The KPL is an easy-to-use, highly configurable library that you install on your hosts that generate the data that you want to stream to Kinesis Data Streams. It acts as an intermediary between your producer application code and the Kinesis Data Streams API actions.
The KPL performs the following primary tasks:
-
Writes to one or more Kinesis streams with an automatic and configurable retry mechanism
-
Collects records and uses PutRecords to write multiple records to multiple shards per request
-
Aggregates user records to increase payload size and improve throughput
-
Integrates seamlessly with the Amazon Kinesis Client Library (KCL) to de- aggregate batched records on the consumer
-
Submits Amazon CloudWatch metrics on your behalf to provide visibility into producer performance
The KPL can be used in either synchronous or asynchronous use cases. We suggest using the higher performance of the asynchronous interface unless there is a specific reason to use synchronous behavior. For more information about these two use cases and example code, refer to Writing to your Kinesis Data Stream Using the KPL.
Using the Amazon Kinesis Client Library (KCL)
You can develop a consumer application for Kinesis Data Streams using the Kinesis Client Library (KCL). Although you can use the Kinesis Streams API to get data from an Amazon Kinesis stream, we recommend using the design patterns and code for consumer applications provided by the KCL.
The KCL helps you consume and process data from a Kinesis stream. This type of application is also referred to as a consumer. The KCL takes care of many of the complex tasks associated with distributed computing, such as load balancing across multiple instances, responding to instance failures, checkpointing processed records, and reacting to resharding. The KCL enables you to focus on writing record-processing logic.
The KCL is a Java library; support for languages other than Java is provided using a multi-language interface. At run time, a KCL application instantiates a worker with configuration information, and then uses a record processor to process the data received from a Kinesis stream. You can run a KCL application on any number of instances. Multiple instances of the same application coordinate on failures and load- balance dynamically. You can also have multiple KCL applications working on the same stream, subject to throughput limits. The KCL acts as an intermediary between your record processing logic and Kinesis Streams.
For detailed information on how to build your own KCL application, refer to Developing KCL 1.x Consumers.
Amazon Managed Streaming for Apache Kafka (Amazon MSK)
Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a fully managed service that makes it easy for you to build and run applications that use Apache Kafka to process streaming data. Apache Kafka is an open-source platform for building real- time streaming data pipelines and applications. With Amazon MSK, you can use native Apache Kafka APIs to populate data lakes, stream changes to and from databases, and power machine learning and analytics applications. Amazon MSK is tailor made for use cases that require ultra-low latency (less than 20 milliseconds) and higher throughput through a single partition. With Amazon MSK, you can offload the overhead of maintaining and operating Apache Kafka to AWS which will result in significant cost savings when compared to running a self-hosted version of Apache Kafka.

Managed Kafka for storing streaming data in an Amazon S3 data lake
Other streaming solutions in AWS
You can install streaming data platforms of your choice on
Amazon EC2 and
Amazon EMR

Moving data to AWS using Amazon EMR
Relational data ingestion
One of common scenarios for
Modern
Data architecture
Customers migrating into Amazon RDS and Amazon Aurora managed database services gain benefits of operating and scaling a database engine without extensive administration and licensing requirements. Also, customers gain access to features such as backtracking where relational databases can be backtracked to a specific time, without restoring data from a backup, restoring database cluster to a specified time, and avoiding database licensing costs.
Customers with data in on-premises warehouse databases gain benefits by moving the data to Amazon Redshift – a cloud data warehouse database that simplifies administration and scalability requirements.
The data migration process across heterogeneous database engines is a two-step process:
Once data is onboarded, you can decide whether to maintain a copy with up-to-date changes of a database in support of modern data architecture or cut-over applications to use the managed database for both application needs and Lake House architecture.
Schema Conversion Tool
AWS Schema Conversion Tool (AWS SCT) is used to facilitate heterogeneous database assessment and migration by automatically converting the source database schema and code objects to a format that’s compatible with the target database engine. The custom code that it converts includes views, stored procedures, and functions. Any code that SCT cannot convert automatically is flagged for manual conversion.

AWS Schema Conversion Tool
AWS Database Migration Service (AWS DMS)
AWS Database Migration Service (AWS DMS) is used to perform initial data load from on-premises database engine into target (Amazon Aurora). After the ingestion load is completed, depending on whether you need an on-going replication, AWS DMS or other migration and change data capture (CDC) solutions can be used for propagating the changes (deltas) from a source to the target database.
Network connectivity in a form of
AWS VPN
When loading large databases, especially in cases when there is
a low bandwidth connectivity between the on-premises data center
and AWS Cloud, it’s recommended to use
AWS Snowball Edge
Once devices are received by AWS, the data is securely loaded
into Amazon Simple Storage Service

AWS Database Migration Service
When moving data from on-premises databases or storing data in
the cloud, security and access control of the data is an
important aspect that must be accounted for in any architecture.
AWS services use Transport Level Security (TLS) for securing
data in transit. For securing data at rest, AWS offers a large
number of encryption options for encrypting data automatically
using AWS provided keys
Ingestion between relational and non-relational data stores
Many organizations consider migrating from commercial relational
data stores to non- relational data stores to align with the
application and analytics modernization strategies. These AWS
customers modernize their applications with
microservices
In addition, relational database management systems (RDBMSs) require up-front schema definition, and changing the schema later is very expensive. There are many use cases where it’s very difficult to anticipate the database schema upfront that the business will eventually need. Therefore, RDBMS backends may not be appropriate for applications that work with a variety of data. However, NoSQL databases (like document databases) have dynamic schemas for unstructured data, and you can store data in many ways. They can be column-oriented, document-oriented, graph-based, or organized as a key-value store. The following section illustrates the ingestion pattern for these use cases.
Migrating or ingesting data from a relational data store to NoSQL data store
Migrating from commercial relational databases like Microsoft
SQL Server or Oracle to
Amazon DynamoDB

Migrating data from a relational data store to NoSQL data store
You can use AWS Database Migration Service
AWS DMS supports migration to a DynamoDB table as a target. You use object mapping to migrate your data from a source database to a target DynamoDB table.
Object mapping enables you to determine where the source data is located in the target. You can also create a DMS task that captures the ongoing changes from the source database and apply these to DynamoDB as target. This task can be full load plus change data capture (CDC) or CDC only.
One of the key challenges when refactoring to Amazon DynamoDB is identifying the access patterns and building the data model. There are many best practices for designing and architecting with Amazon DynamoDB. AWS provides NoSQL Workbench for Amazon DynamoDB. NoSQL Workbench is a cross-platform client-side GUI application for modern database development and operations and is available for Windows, macOS, and Linux. NoSQL Workbench is a unified visual IDE tool that provides data modeling, data visualization, and query development features to help you design, create, query, and manage DynamoDB tables.
Migrating or ingesting data from a relational data store to a document DB (such as Amazon DocumentDB [with MongoDB compatibility])
Amazon
DocumentDB
In this scenario, converting the relational structures to
documents can be complex and may require building complex data
pipelines for transformations.
Amazon Database
Migration Services
AWS DMS maps database objects to Amazon DocumentDB in the following ways:
-
A relational database, or database schema, maps to an Amazon DocumentDB database.
-
Tables within a relational database map to collections in Amazon DocumentDB.
-
Records in a relational table map to documents in Amazon DocumentDB. Each document is constructed from data in the source record.

Migrating data from a relational data store to DocumentDB
AWS DMS reads records from the source endpoint, and constructs JSON documents based on the data it reads. For each JSON document, AWS DMS determines an _id field to act as a unique identifier. It then writes the JSON document to an Amazon DocumentDB collection, using the _id field as a primary key.
Migrating or ingesting data from a document DB (such as Amazon DocumentDB [with MongoDB compatibility] to a relational database
AWS DMS supports Amazon DocumentDB (with MongoDB compatibility)
as a database source. You can use AWS DMS to migrate or
replicate changes from Amazon DocumentDB to relational database
such as Amazon Redshift for data warehousing use cases.
Amazon Redshift
In document mode, the JSON documents from DocumentDB are migrated as is. So, when you use a relational database as a target, the data is a single column named _doc in a target table. You can optionally set the extra connection attribute extractDocID to true to create a second column named "_id" that acts as the primary key. If you use change data capture (CDC), set this parameter to true except when using Amazon DocumentDB as the target.
In table mode, AWS DMS transforms each top-level field in a DocumentDB document into a column in the target table. If a field is nested, AWS DMS flattens the nested values into a single column. AWS DMS then adds a key field and data types to the target table's column set.
The change streams feature in Amazon DocumentDB (with MongoDB compatibility) provides a time-ordered sequence of change events that occur within your cluster’s collections. You can read events from a change stream using AWS DMS to implement many different use cases, including the following:
-
Change notification
-
Full-text search with Amazon OpenSearch Service
(OpenSearch Service) -
Analytics with Amazon Redshift
After change streams are enabled, you can create a migration task in AWS DMS that migrates existing data and at the same time replicates ongoing changes. AWS DMS continues to capture and apply changes even after the bulk data is loaded. Eventually, the source and target databases synchronize, minimizing downtime for a migration.
During a database migration when Amazon Redshift is the target for data warehousing use cases, AWS DMS first moves data to an Amazon S3 bucket. When the files reside in an Amazon S3 bucket, AWS DMS then transfers them to the proper tables in the Amazon Redshift data warehouse.
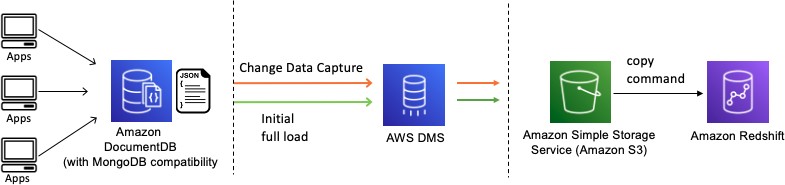
Migrating data from NoSQL store to Amazon Redshift
AWS Database Migration Service supports both full load and
change processing operations. AWS DMS reads the data from the
source database and creates a series of comma-separated value
(.csv) files. For full-load operations, AWS DMS creates files
for each table. AWS DMS then copies the table files for each
table to a separate folder in Amazon S3. When the files are
uploaded to Amazon S3, AWS DMS sends a
COPY
command and the data in the files are copied into Amazon Redshift. For change- processing operations, AWS DMS copies the
net changes to the .csv files. AWS DMS then uploads the net
change files to Amazon S3 and copies the data to Amazon Redshift.
Migrating or ingesting data from a document DB (such as Amazon Document DB [with MongoDB compatibility]) to Amazon OpenSearch Service
Taking the same approach as AWS DMS support for Amazon
DocumentDB (with MongoDB) as a database source, you can migrate
or replicate changes from Amazon DocumentDB to
Amazon OpenSearch Service
In OpenSearch Service, you work with indexes and documents. An index is a collection of documents, and a document is a JSON object containing scalar values, arrays, and other objects. OpenSearch Service provides a JSON-based query language, so that you can query data in an index and retrieve the corresponding documents. When AWS DMS creates indexes for a target endpoint for OpenSearch Service, it creates one index for each table from the source endpoint.
AWS DMS supports multithreaded full load to increase the speed of the transfer, and multithreaded CDC load to improve the performance of CDC. For the task settings and prerequisites that are required to be configured for these modes, refer to Using an Amazon OpenSearch Service cluster as a target for AWS Database Migration Service.

Migrating data from Amazon DocumentDB store to Amazon OpenSearch Service
