Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Einführung
Ihr Workload muss die vorgesehene Funktion korrekt und konsistent erfüllen. Um dies zu erreichen, müssen Sie Ihre Architektur auf Ausfallsicherheit ausrichten. Resilienz ist die Fähigkeit eines Workloads, sich nach Infrastruktur-, Service- oder Anwendungsunterbrechungen zu erholen, Rechenressourcen dynamisch zu erwerben, um den Bedarf zu decken, und Störungen wie Fehlkonfigurationen oder vorübergehende Netzwerkprobleme zu minimieren.
Disaster Recovery (DR) ist ein wichtiger Bestandteil Ihrer Resilienzstrategie und befasst sich damit, wie Ihre Arbeitslast im Notfall reagiert (ein Notfall ist ein Ereignis, das schwerwiegende negative Auswirkungen auf Ihr Unternehmen hat). Diese Reaktion muss auf den Geschäftszielen Ihres Unternehmens basieren, in denen die Strategie Ihres Workloads zur Vermeidung von Datenverlusten (Recovery Point Objective, RPO) und zur Reduzierung von Ausfallzeiten, wenn Ihr Workload nicht zur Verfügung steht, festgelegt wird, das sogenannte Recovery Time Objective (RTO). Sie müssen daher bei der Gestaltung Ihrer Workloads in der Cloud Resilienz implementieren, um Ihre Wiederherstellungsziele (RPO und RTO) für ein bestimmtes einmaliges Katastrophenereignis zu erreichen. Dieser Ansatz hilft Ihrem Unternehmen, die Geschäftskontinuität im Rahmen der Business Continuity Planning (BCP) aufrechtzuerhalten.
Dieses paper konzentriert sich auf die Planung, den Entwurf und die Implementierung von Architekturen, AWS die die Disaster Recovery-Ziele Ihres Unternehmens erfüllen. Die hier bereitgestellten Informationen richten sich an Personen in technologischer Position, wie z. B. Chief Technology Officers (CTOs), Architekten, Entwickler, Mitglieder des Betriebsteams und Personen, die mit der Bewertung und Minderung von Risiken beauftragt sind.
Notfallwiederherstellung und Verfügbarkeit
Disaster Recovery kann mit Verfügbarkeit verglichen werden, was ein weiterer wichtiger Bestandteil Ihrer Resilienzstrategie ist. Während bei der Notfallwiederherstellung die Ziele für einmalige Ereignisse gemessen werden, werden bei Verfügbarkeitszielen Mittelwerte über einen bestimmten Zeitraum gemessen.

Abbildung 1: Resilienzziele
Die Verfügbarkeit wird anhand der Mean Time Between Failures (MTBF) und der Mean Time to Recover (MTTR) berechnet:

Dieser Ansatz wird oft als „neun“ bezeichnet, wobei ein Verfügbarkeitsziel von 99,9% als „drei Neunen“ bezeichnet wird.
Für Ihren Workload ist es möglicherweise einfacher, erfolgreiche und fehlgeschlagene Anfragen zu zählen, anstatt einen zeitbasierten Ansatz zu verwenden. In diesem Fall kann die folgende Berechnung verwendet werden:
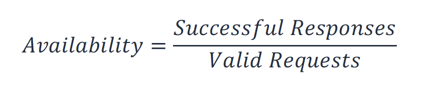
Disaster Recovery konzentriert sich auf Notfallereignisse, wohingegen sich Verfügbarkeit auf häufigere Störungen kleineren Ausmaßes wie Komponentenausfälle, Netzwerkprobleme, Softwarefehler und Lastspitzen konzentriert. Das Ziel der Notfallwiederherstellung ist die Geschäftskontinuität, wohingegen es bei der Verfügbarkeit darum geht, die Zeit zu maximieren, in der ein Workload zur Ausführung seiner beabsichtigten Geschäftsfunktionen verfügbar ist. Beides sollte Teil Ihrer Resilienzstrategie sein.
Sind Sie Well-Architected?
Das AWS Well-Architected Framework
Die in diesem Whitepaper behandelten Konzepte erweitern die bewährten Methoden des Whitepapers zur Säule der Zuverlässigkeit, insbesondere die Frage REL 13, „Wie planen Sie die Notfallwiederherstellung (DR)?“. Nachdem Sie die Methoden in diesem Whitepaper implementiert haben, sollten Sie Ihren Workload mit dem AWS Well-Architected Tool überprüfen (oder erneut überprüfen).
