Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Optionen für die Notfallwiederherstellung in der Cloud
Disaster Recovery-Strategien, die Ihnen innerhalb von AWS zur Verfügung stehen, lassen sich grob in vier Ansätze einteilen, die von den niedrigen Kosten und der geringen Komplexität der Erstellung von Backups bis hin zu komplexeren Strategien mit mehreren aktiven Regionen reichen. Active/passive Strategien verwenden einen aktiven Standort (z. B. eine AWS-Region), um den Workload zu hosten und den Datenverkehr bereitzustellen. Die passive Site (z. B. eine andere AWS-Region) wird für die Wiederherstellung verwendet. Die passive Site stellt keinen aktiven Datenverkehr bereit, bis ein Failover-Ereignis ausgelöst wird.
Es ist wichtig, Ihre Disaster-Recovery-Strategie regelmäßig zu überprüfen und zu testen, damit Sie sie im Bedarfsfall auch anwenden können. Verwenden Sie AWS Resilience Hub
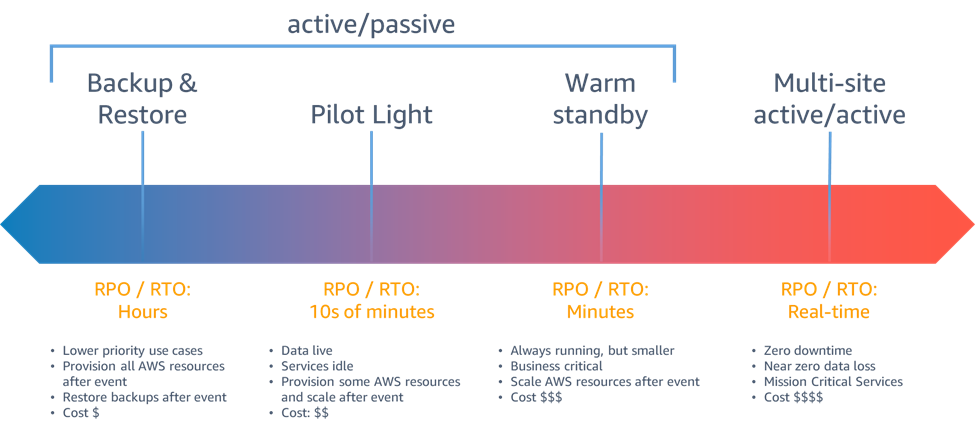
Abbildung 6: Strategien für die Notfallwiederherstellung
Bei einem Notfall, der auf einer Unterbrechung oder dem Verlust eines physischen Rechenzentrums für eine gut
Denken Sie bei der Auswahl Ihrer Strategie und der AWS-Ressourcen für deren Implementierung daran, dass wir innerhalb von AWS Services üblicherweise in die Datenebene und die Kontrollebene unterteilen. Die Datenebene ist zuständig für die Bereitstellung von Echtzeitservices, während die Steuerebene dazu verwendet wird, die Umgebung zu konfigurieren. Für maximale Ausfallsicherheit sollten Sie im Rahmen Ihres Failover-Vorgangs nur Datenebenenoperationen verwenden. Dies liegt daran, dass für die Datenebenen in der Regel eine höhere Verfügbarkeit als für die Steuerungsebenen vorgesehen ist.
Backup und Backup
Backup und Wiederherstellung sind ein geeigneter Ansatz, um Datenverlust oder -beschädigung zu verhindern. Dieser Ansatz kann auch zur Abwehr regionaler Katastrophen verwendet werden, indem Daten in andere AWS-Regionen repliziert werden, oder um fehlende Redundanz für Workloads zu verringern, die in einer einzigen Availability Zone bereitgestellt werden. Zusätzlich zu den Daten müssen Sie die Infrastruktur, die Konfiguration und den Anwendungscode in der Wiederherstellungsregion erneut bereitstellen. Damit die Infrastruktur schnell und ohne Fehler neu bereitgestellt werden kann, sollten Sie bei der Bereitstellung stets Infrastructure as Code (IaC) verwenden und Dienste wie AWS CloudFormation
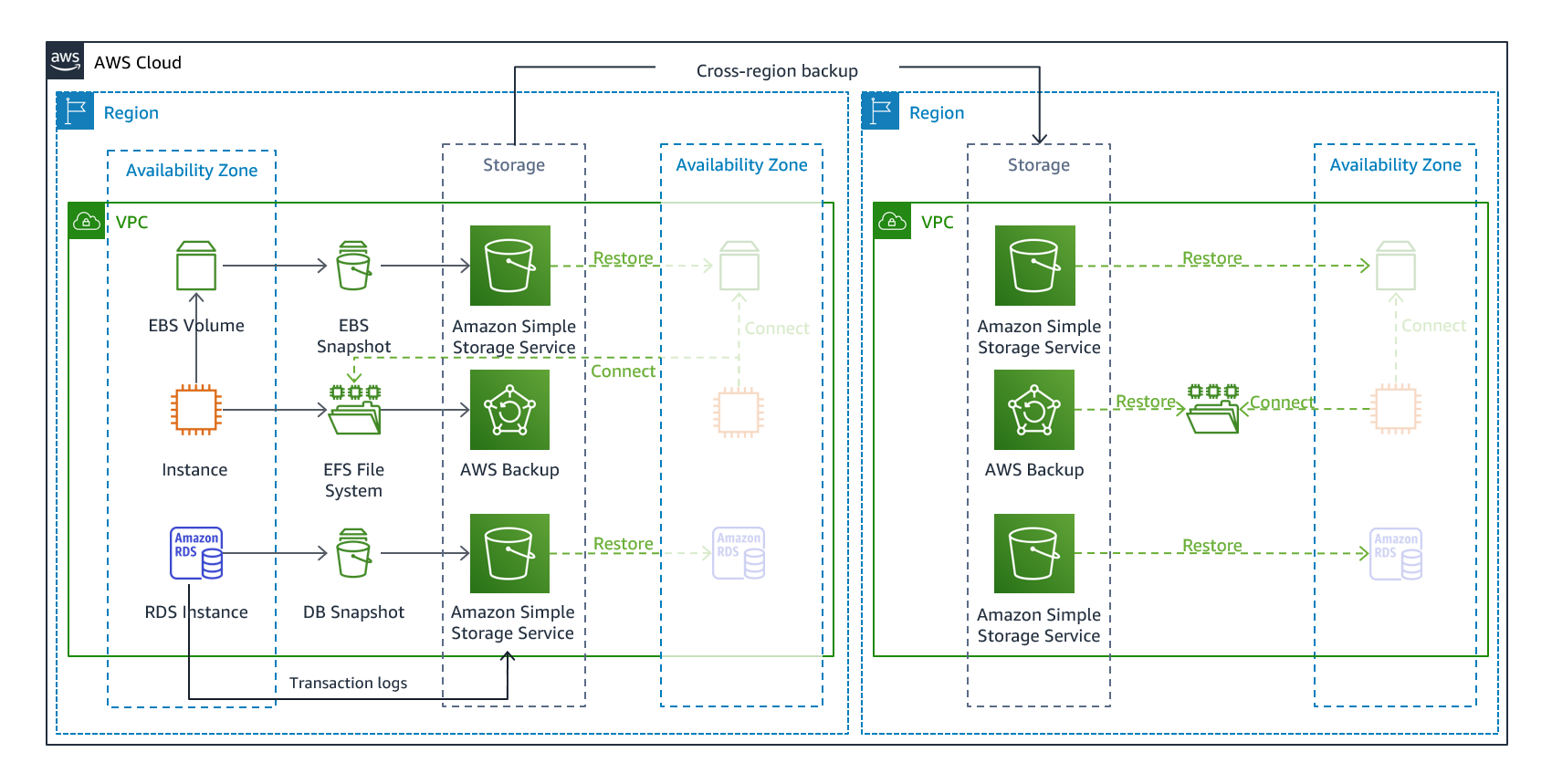
Abbildung 7: Architektur für Backup und Wiederherstellung
AWS-Services
Für Ihre Workload-Daten ist eine Backup-Strategie erforderlich, die regelmäßig oder kontinuierlich ausgeführt wird. Wie oft Sie Ihr Backup ausführen, bestimmt Ihren erreichbaren Wiederherstellungspunkt (der sich an Ihrem RPO orientieren sollte). Das Backup sollte auch eine Möglichkeit bieten, es auf den Zeitpunkt zurückzusetzen, an dem es erstellt wurde. Backup mit point-in-time Wiederherstellung ist über die folgenden Dienste und Ressourcen verfügbar:
-
Amazon EFS-Backup (bei Verwendung AWS Backup)
-
Amazon FSx für Windows File Server, Amazon FSx für Lustre, Amazon FSx für NetApp ONTAP und Amazon FSx für OpenZFS
Für Amazon Simple Storage Service (Amazon S3) können Sie Amazon S3 Cross-Region Replication (CRR)
AWS Backup
-
Volumen im Amazon Elastic Block Store (Amazon EBS)
-
Amazon Relational Database Service (Amazon RDS)
-Datenbanken (einschließlich Amazon Aurora Aurora-Datenbanken ) -
Dateisysteme von Amazon Elastic File System (Amazon EFS)
-
AWS Storage Gateway
-Volumes -
Amazon FSx für Windows File Server, Amazon FSx für Lustre, Amazon FSx für NetApp ONTAP und Amazon FSx für OpenZFS
AWS Backup unterstützt das Kopieren von Backups zwischen Regionen, z. B. in eine Region für die Notfallwiederherstellung.
Als zusätzliche Strategie zur Notfallwiederherstellung für Ihre Amazon S3 S3-Daten aktivieren Sie die Versionierung von S3-Objekten. Die Objektversionierung schützt Ihre Daten in S3 vor den Folgen von Lösch- oder Änderungsaktionen, indem die ursprüngliche Version vor der Aktion beibehalten wird. Die Objektversionierung kann ein nützliches Mittel zur Abmilderung von Katastrophen sein, die auf menschliches Versagen zurückzuführen sind. Wenn Sie die S3-Replikation verwenden, um Daten in Ihrer DR-Region zu sichern, fügt Amazon S3 standardmäßig nur im Quell-Bucket eine Löschmarkierung hinzu, wenn ein Objekt im Quell-Bucket gelöscht wird. Dieser Ansatz schützt Daten in der DR-Region vor böswilligen Löschungen in der Quellregion.
Zusätzlich zu den Daten müssen Sie auch die Konfiguration und Infrastruktur sichern, die für die erneute Bereitstellung Ihres Workloads und die Einhaltung Ihres Recovery Time Objective (RTO) erforderlich sind. AWS CloudFormation
Alle Daten, die in der Disaster Recovery-Region als Backups gespeichert sind, müssen zum Zeitpunkt des Failovers wiederhergestellt werden. AWS Backup bietet Wiederherstellungsfunktionen, ermöglicht derzeit jedoch keine geplante oder automatische Wiederherstellung. Sie können die automatische Wiederherstellung in der DR-Region mithilfe des AWS-SDK auf Anfrage APIs implementieren AWS Backup. Sie können dies als regelmäßig wiederkehrenden Job einrichten oder die Wiederherstellung auslösen, wenn ein Backup abgeschlossen ist. Die folgende Abbildung zeigt ein Beispiel für die automatische Wiederherstellung mithilfe von Amazon Simple Notification Service (Amazon SNS)
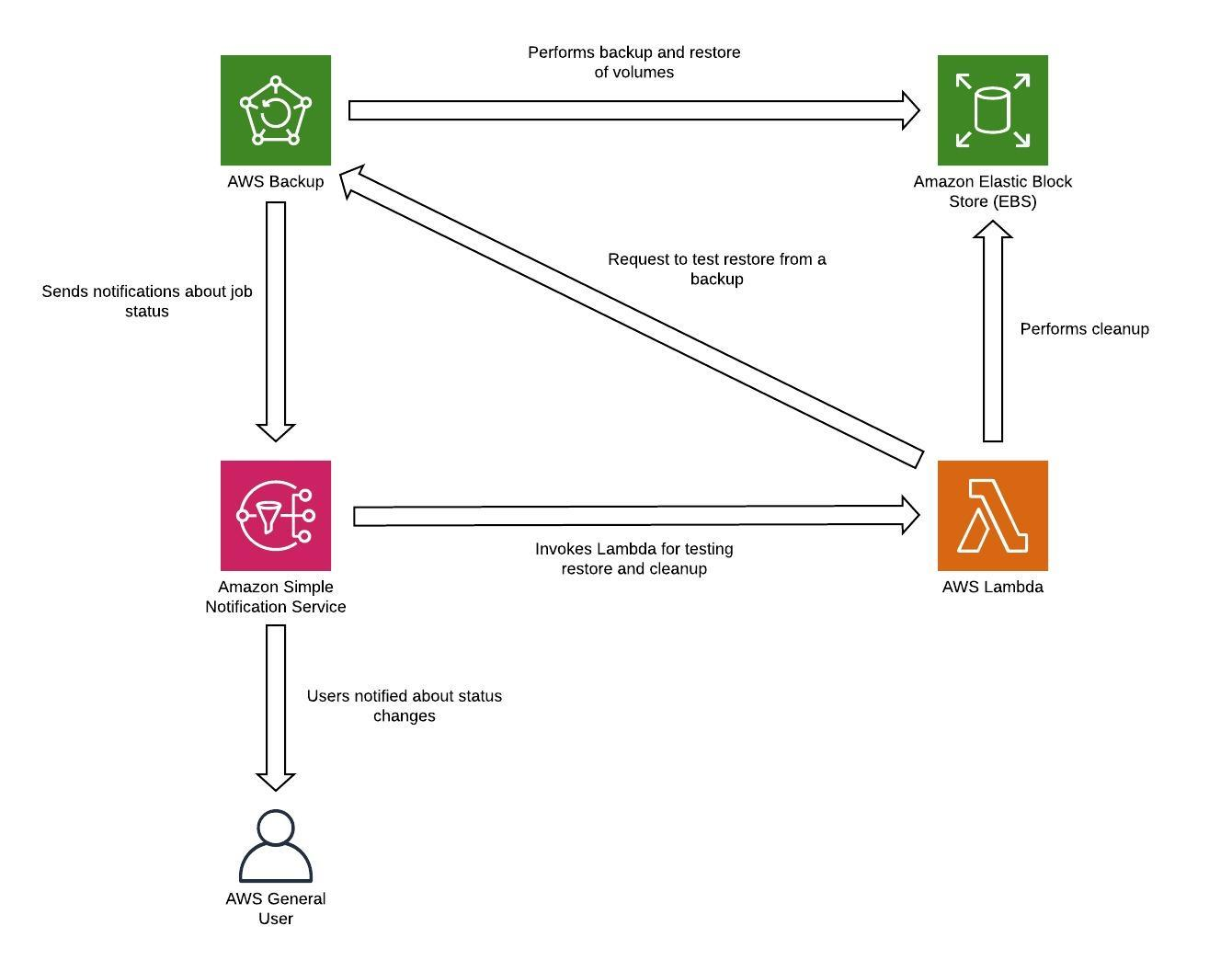
Abbildung 8: Backups wiederherstellen und testen
Anmerkung
Ihre Backup-Strategie muss das Testen Ihrer Backups beinhalten. Weitere Informationen finden Sie im Abschnitt Testen der Notfallwiederherstellung. Eine praktische Demonstration der Implementierung finden Sie im AWS Well-Architected Lab: Testing Backup and Restore of Data
Pilot light
Beim Pilot-Light-Ansatz replizieren Sie Ihre Daten von einer Region in eine andere und stellen eine Kopie Ihrer zentralen Workload-Infrastruktur bereit. Ressourcen, die zur Unterstützung der Datenreplikation und -sicherung erforderlich sind, wie Datenbanken und Objektspeicher, sind immer eingeschaltet. Andere Elemente, wie z. B. Anwendungsserver, enthalten zwar Anwendungscode und Konfigurationen, sind jedoch „ausgeschaltet“ und werden nur beim Testen oder beim Auslösen eines Disaster Recovery-Failovers verwendet. In der Cloud haben Sie die Flexibilität, Ressourcen zu deprovisionieren, wenn Sie sie nicht benötigen, und sie dann bereitzustellen, wenn Sie sie benötigen. Eine bewährte Methode bei ausgeschaltetem System besteht darin, die Ressource nicht bereitzustellen und dann die Konfiguration und die Funktionen zu erstellen, um sie bei Bedarf bereitzustellen („einzuschalten“). Im Gegensatz zum Sicherungs- und Wiederherstellungsansatz ist Ihre Kerninfrastruktur immer verfügbar und Sie haben jederzeit die Möglichkeit, schnell eine vollständige Produktionsumgebung bereitzustellen, indem Sie Ihre Anwendungsserver einschalten und skalieren.
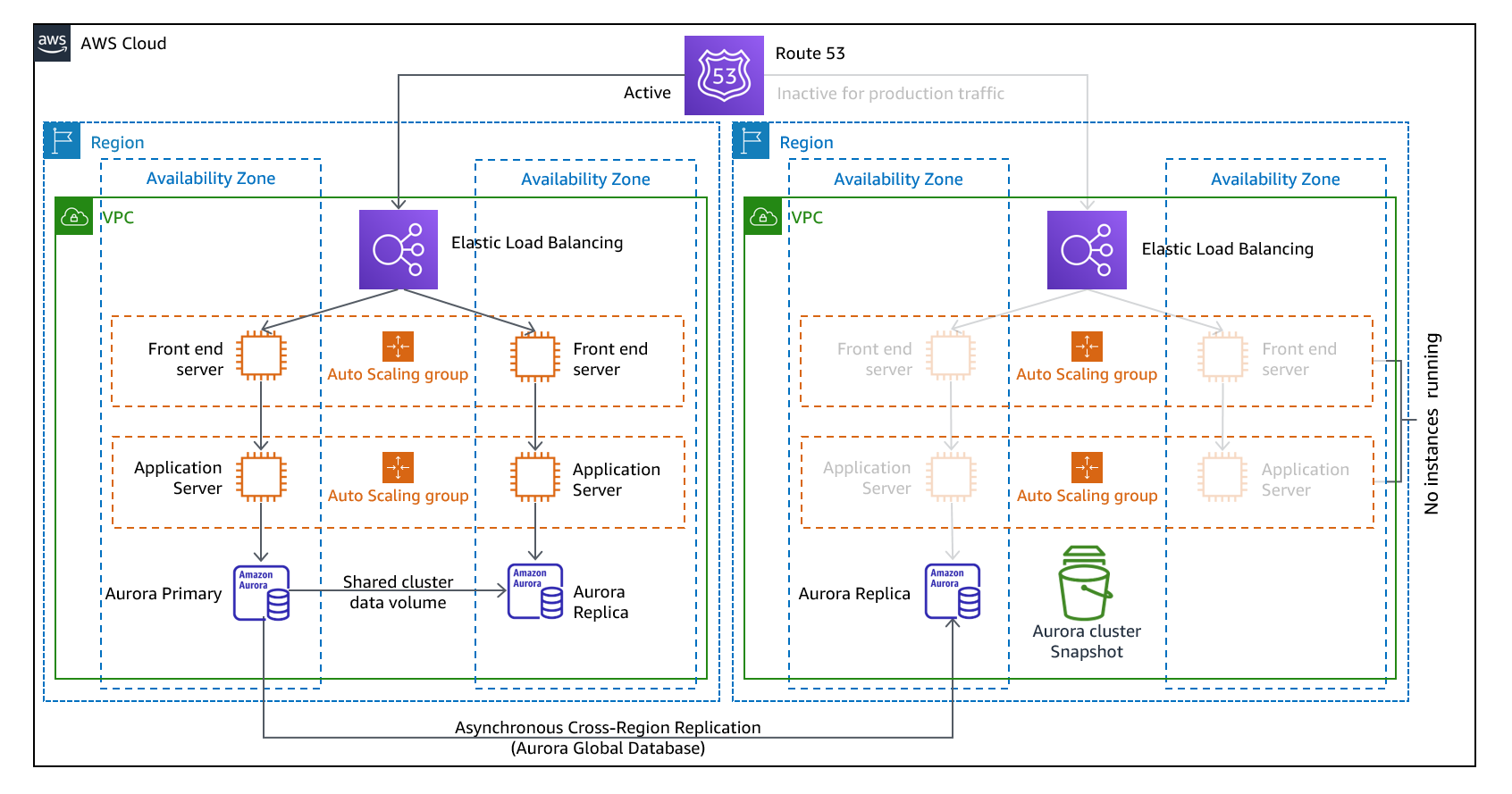
Abbildung 9: Architektur der Zündflamme
Ein Pilot-Light-Ansatz minimiert die laufenden Kosten für die Notfallwiederherstellung, indem die aktiven Ressourcen minimiert werden, und vereinfacht die Wiederherstellung im Notfall, da alle grundlegenden Infrastrukturanforderungen erfüllt sind. Bei dieser Wiederherstellungsoption müssen Sie Ihren Bereitstellungsansatz ändern. Sie müssen in jeder Region Änderungen an der Kerninfrastruktur vornehmen und Änderungen an der Arbeitslast (Konfiguration, Code) gleichzeitig in jeder Region implementieren. Dieser Schritt kann vereinfacht werden, indem Sie Ihre Bereitstellungen automatisieren und Infrastructure as Code (IaC) verwenden, um die Infrastruktur über mehrere Konten und Regionen hinweg bereitzustellen (vollständige Infrastrukturbereitstellung in der primären Region und skalierte Infrastrukturbereitstellung herunterskaliert/abgeschaltete Infrastruktur in DR-Regionen). Es wird empfohlen, pro Region ein anderes Konto zu verwenden, um ein Höchstmaß an Ressourcen- und Sicherheitsisolierung zu gewährleisten (für den Fall, dass kompromittierte Anmeldeinformationen auch Teil Ihrer Notfallwiederherstellungspläne sind).
Mit diesem Ansatz müssen Sie sich auch gegen eine Datenkatastrophe wappnen. Kontinuierliche Datenreplikation schützt Sie vor einigen Arten von Notfällen, aber sie schützt Sie möglicherweise nicht vor Datenbeschädigung oder -vernichtung, sofern Ihre Strategie nicht auch die Versionierung von gespeicherten Daten oder Wiederherstellungsoptionen umfasst. point-in-time Sie können die replizierten Daten in der Notfallregion sichern, um point-in-time Backups in derselben Region zu erstellen.
AWS-Services
Neben der Nutzung der im Abschnitt Backup und Wiederherstellung beschriebenen AWS-Services zur Erstellung von point-in-time Backups sollten Sie auch die folgenden Services für Ihre Pilotstrategie in Betracht ziehen.
Für Pilot Light ist die kontinuierliche Datenreplikation auf Live-Datenbanken und Datenspeicher in der DR-Region der beste Ansatz für ein niedriges RPO (wenn sie zusätzlich zu den zuvor besprochenen point-in-time Backups verwendet wird). AWS bietet eine kontinuierliche, regionsübergreifende, asynchrone Datenreplikation für Daten mithilfe der folgenden Services und Ressourcen:
Dank kontinuierlicher Replikation sind Versionen Ihrer Daten in Ihrer DR-Region fast sofort verfügbar. Die tatsächlichen Replikationszeiten können mithilfe von Servicefunktionen wie S3 Replication Time Control (S3 RTC) für S3-Objekte und Verwaltungsfunktionen der globalen Amazon Aurora Aurora-Datenbanken überwacht werden.
Wenn Sie einen Failover durchführen möchten, um Ihren read/write Workload von der Disaster Recovery-Region aus auszuführen, müssen Sie eine RDS-Read Replica zur primären Instance heraufstufen. Bei anderen DB-Instances als Aurora dauert der Vorgang einige Minuten, und der Neustart ist Teil des Prozesses. Für regionsübergreifende Replikation (CRR) und Failover mit RDS bietet die Verwendung der globalen Amazon Aurora Aurora-Datenbank mehrere Vorteile. Die globale Datenbank verwendet eine dedizierte Infrastruktur, sodass Ihre Datenbanken vollständig für Ihre Anwendung verfügbar sind. Sie kann in die sekundäre Region mit einer typischen Latenz von unter einer Sekunde repliziert werden (und innerhalb einer AWS-Region sind es deutlich weniger als 100 Millisekunden). Mit der globalen Amazon Aurora Aurora-Datenbank können Sie bei Leistungseinbußen oder -ausfällen in Ihrer primären Region eine der sekundären Regionen so befördern, dass sie in weniger als einer Minute Lese-/Schreibaufgaben übernimmt, selbst bei einem vollständigen regionalen Ausfall. Sie können Aurora auch so konfigurieren, dass die RPO-Verzögerungszeit aller sekundären Cluster überwacht wird, um sicherzustellen, dass mindestens ein sekundärer Cluster innerhalb Ihres Ziel-RPO-Fensters bleibt.
In Ihrer DR-Region muss eine verkleinerte Version Ihrer Kern-Workload-Infrastruktur mit weniger oder kleineren Ressourcen bereitgestellt werden. Mithilfe AWS CloudFormation können Sie Ihre Infrastruktur definieren und sie konsistent für alle AWS-Konten und AWS-Regionen bereitstellen. AWS CloudFormation verwendet vordefinierte Pseudo-Parameter, um das AWS-Konto und die AWS-Region zu identifizieren, in der es bereitgestellt wird. Daher können Sie Bedingungslogik in Ihren CloudFormation Vorlagen implementieren, um nur die verkleinerte Version Ihrer Infrastruktur in der DR-Region bereitzustellen. Bei EC2 Bereitstellungen liefert ein Amazon Machine Image (AMI) Informationen wie Hardwarekonfiguration und installierte Software. Sie können eine Image Builder Builder-Pipeline implementieren, die die AMIs benötigten Daten erstellt und diese sowohl in Ihre primäre als auch in Ihre Backup-Region kopiert. Auf diese Weise können Sie sicherstellen, dass diese AMIsGold-Tools über alles verfügen, was Sie benötigen, um Ihren Workload im Katastrophenfall in einer neuen Region neu bereitzustellen oder zu skalieren. EC2 Amazon-Instances werden in einer reduzierten Konfiguration bereitgestellt (weniger Instances als in Ihrer primären Region). Informationen zur Skalierung der Infrastruktur zur Unterstützung des Produktionsverkehrs finden Sie unter Amazon EC2 Auto Scaling im Abschnitt
Bei einer active/passive Konfiguration wie einer Pilotlampe geht der gesamte Datenverkehr zunächst in die primäre Region und wechselt in die Notfallwiederherstellungsregion, wenn die primäre Region nicht mehr verfügbar ist. Dieser Failover-Vorgang kann entweder automatisch oder manuell eingeleitet werden. Automatisch eingeleitetes Failover auf der Grundlage von Zustandsprüfungen oder Alarmen sollte mit Vorsicht verwendet werden. Selbst bei Anwendung der hier erörterten bewährten Methoden werden Wiederherstellungszeit und Wiederherstellungspunkt größer als Null sein, was zu einem gewissen Verlust an Verfügbarkeit und Daten führen kann. Wenn Sie einen Failover durchführen, obwohl dies nicht erforderlich ist (Fehlalarm), erleiden Sie diese Verluste. Daher wird häufig ein manuell initiierter Failover verwendet. In diesem Fall sollten Sie die Schritte für den Failover dennoch automatisieren, sodass die manuelle Auslösung wie ein Knopfdruck wirkt.
Bei der Nutzung von AWS Diensten sind mehrere Optionen für das Verkehrsmanagement zu berücksichtigen.
Eine Option ist die Verwendung von Amazon Route 53.
Eine weitere Option ist die Verwendung AWS Global Accelerator
Amazon CloudFront
AWS Elastische Notfallwiederherstellung
AWS Elastic Disaster Recovery

Abbildung 10: AWS Elastic Disaster Recovery-Architektur
Warmer Bereitschaftsmodus
Beim Warm-Standby-Ansatz wird sichergestellt, dass eine herunterskalierte, aber voll funktionsfähige Kopie Ihrer Produktionsumgebung in einer anderen Region vorhanden ist. Dieser Ansatz erweitert das Konzept des Pilot Light und verkürzt die Zeit bis zur Wiederherstellung, da die Workload in einer anderen Region ständig präsent ist. Dieser Ansatz ermöglicht es Ihnen auch, Tests einfacher durchzuführen oder kontinuierliche Tests zu implementieren, um das Vertrauen in Ihre Fähigkeit zu stärken, sich nach einem Notfall wieder zu erholen.
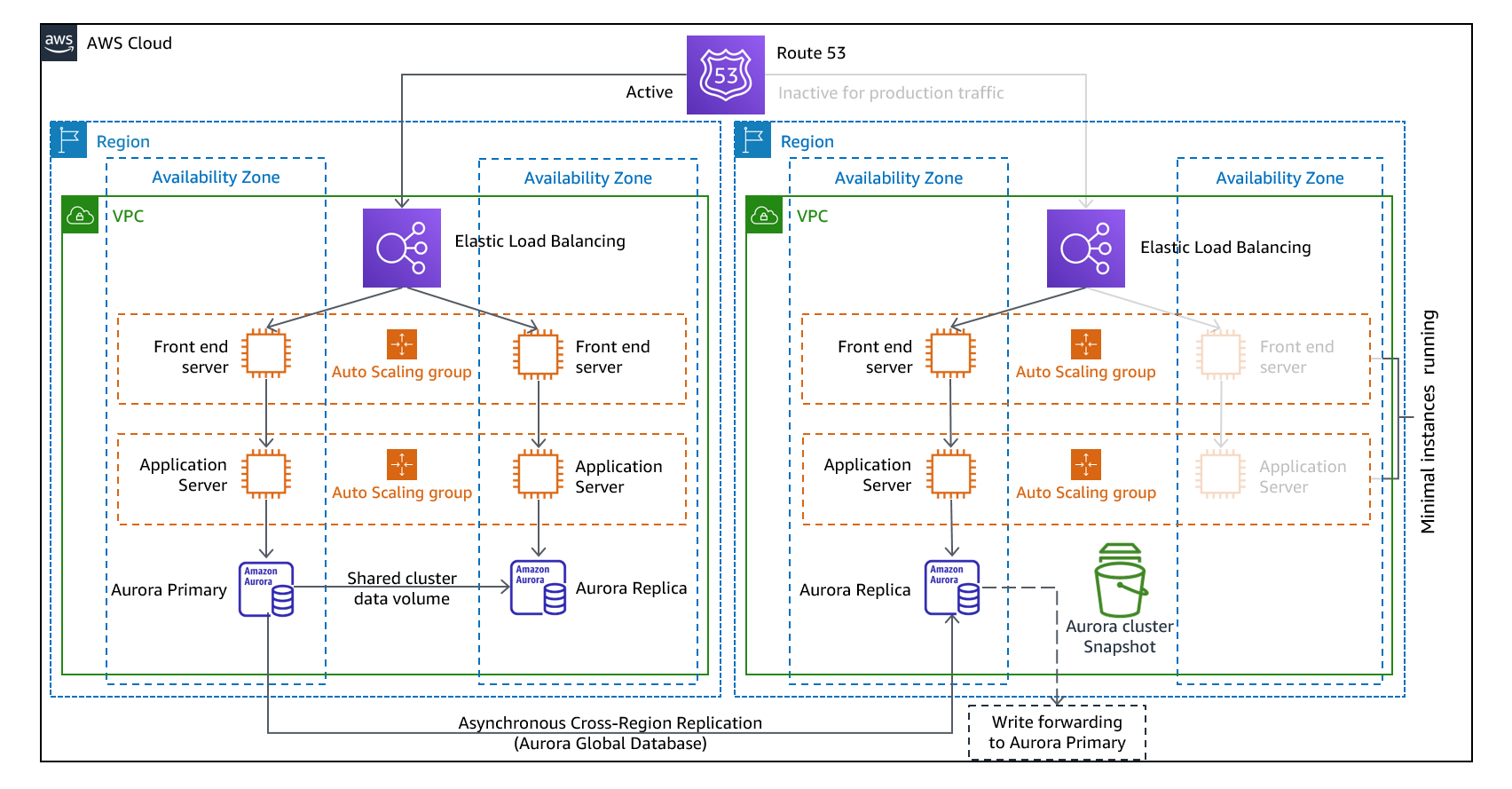
Abbildung 11: Warm-Standby-Architektur
Hinweis: Der Unterschied zwischen Pilotlicht und Warm-Standby kann manchmal schwer zu verstehen sein. Beide beinhalten eine Umgebung in Ihrer DR-Region mit Kopien der Ressourcen Ihrer primären Region. Der Unterschied besteht darin, dass die Kontrolllampe Anfragen nicht bearbeiten kann, ohne dass zuvor zusätzliche Maßnahmen ergriffen werden, wohingegen der Warm-Standby-Modus den Verkehr (bei reduzierter Kapazität) sofort abwickeln kann. Beim Pilot-Light-Ansatz müssen Sie Server „einschalten“, eventuell zusätzliche (nicht zum Kerngeschäft gehörende) Infrastruktur bereitstellen und hochskalieren, wohingegen bei Warm-Standby lediglich eine Skalierung erforderlich ist (alles ist bereits implementiert und läuft). Verwenden Sie Ihre RTO- und RPO-Anforderungen, um sich zwischen diesen Ansätzen zu entscheiden.
AWS-Services
Alle AWS-Services, die unter Backup and Restore und Pilot Light fallen, werden auch im Warm-Standby für Datensicherung, Datenreplikation, active/passive Datenweiterleitung und Bereitstellung der Infrastruktur einschließlich EC2 Instances verwendet.
Amazon EC2 Auto Scaling
Da es sich bei Auto Scaling um eine Aktivität auf der Kontrollebene handelt, verringert die Abhängigkeit davon die Widerstandsfähigkeit Ihrer gesamten Wiederherstellungsstrategie. Es ist ein Kompromiss. Sie können sich dafür entscheiden, ausreichend Kapazität bereitzustellen, sodass die Wiederherstellungsregion die gesamte Produktionslast wie bereitgestellt bewältigen kann. Diese statisch stabile Konfiguration wird als Hot-Standby bezeichnet (siehe nächster Abschnitt). Oder Sie können sich dafür entscheiden, weniger Ressourcen bereitzustellen, was weniger kostet, aber auf Auto Scaling angewiesen ist. Bei einigen DR-Implementierungen werden genügend Ressourcen bereitgestellt, um den anfänglichen Verkehr zu bewältigen, wodurch ein niedriges RTO gewährleistet wird, und sich dann auf Auto Scaling verlassen, um den nachfolgenden Verkehr hochzufahren.
Multi-Site Aktiv/Aktiv
Im Rahmen einer Aktiv/Passiv-Strategie für mehrere Standorte können Sie Ihren Workload gleichzeitig in mehreren Regionen ausführen. An mehreren Standorten active/active wird Datenverkehr aus allen Regionen, in denen sie bereitgestellt wird, bedient, wohingegen Hot-Standby nur Datenverkehr aus einer einzigen Region verarbeitet und die anderen Regionen nur für die Notfallwiederherstellung verwendet werden. Bei einem standortübergreifenden active/active Ansatz können Benutzer auf Ihre Workloads in allen Regionen zugreifen, in denen sie bereitgestellt werden. Dieser Ansatz ist der komplexeste und teuerste Ansatz für die Notfallwiederherstellung, aber er kann die Wiederherstellungszeit bei den meisten Katastrophen auf nahezu Null reduzieren, wenn die richtige Technologie gewählt und implementiert wird (Datenbeschädigung kann jedoch auf Backups angewiesen sein, was in der Regel dazu führt, dass ein Wiederherstellungspunkt ungleich Null ist). Hot-Standby verwendet eine active/passive Konfiguration, bei der Benutzer nur an eine einzige Region weitergeleitet werden und DR-Regionen keinen Datenverkehr aufnehmen. Die meisten Kunden sind der Meinung, dass es sinnvoll ist, sie aktiv/aktiv zu verwenden, wenn sie eine vollständige Umgebung in der zweiten Region einrichten möchten. Wenn Sie nicht beide Regionen für die Verwaltung des Benutzerverkehrs verwenden möchten, bietet Warm Standby alternativ einen wirtschaftlicheren und betrieblich weniger komplexen Ansatz.
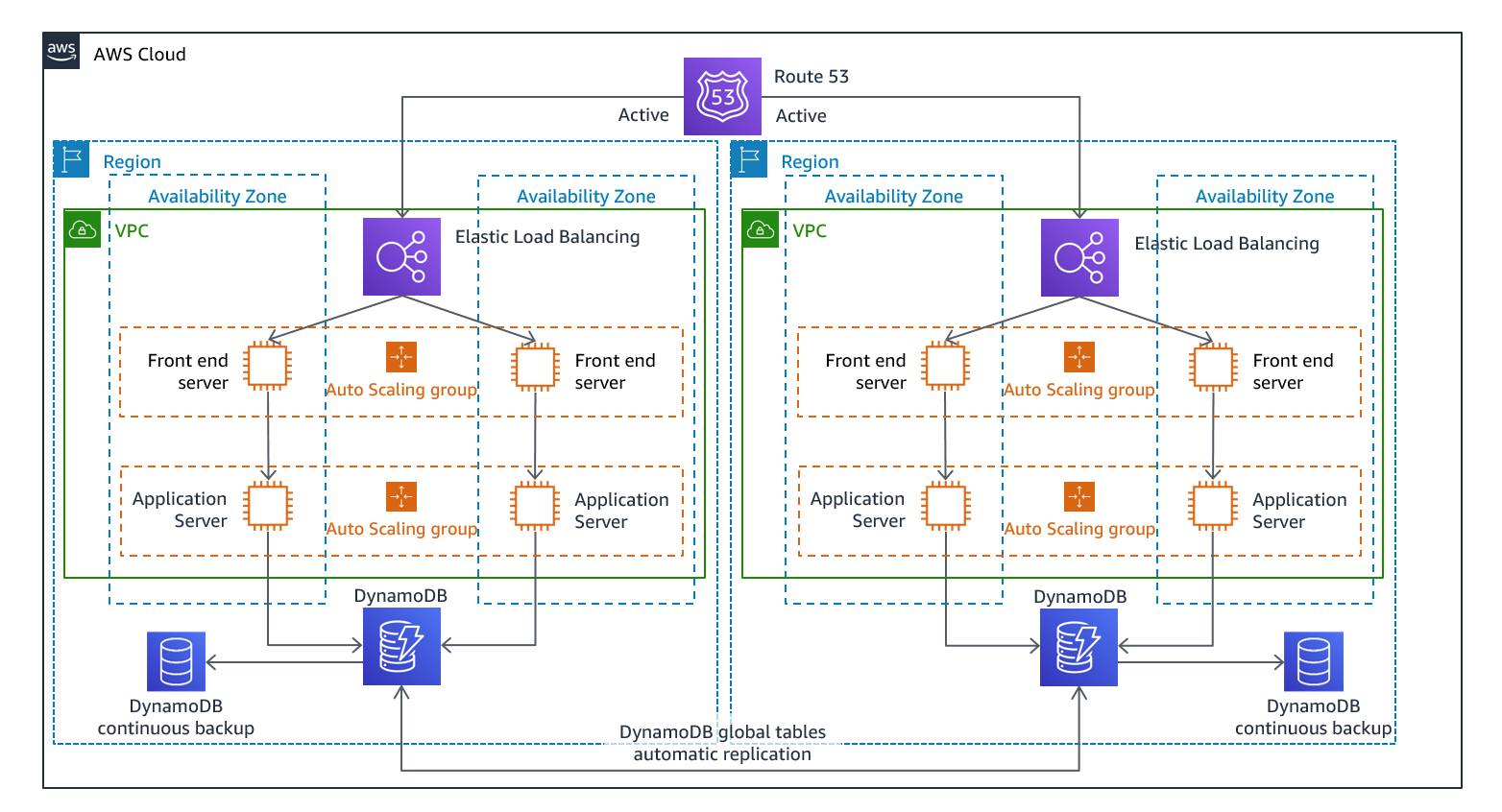
Abbildung 12: active/active Architektur mit mehreren Standorten (ändern Sie einen aktiven Pfad in Inaktiv für Hot-Standby)
Da ein Ansatz mit mehreren active/active, because the workload is running in more than one Region, there is no such thing as failover in this scenario. Disaster recovery testing in this case would focus on how the workload reacts to loss of a Region: Is traffic routed away from the failed Region? Can the other Region(s) handle all the traffic? Testing for a data disaster is also required. Backup and recovery are still required and should be tested regularly. It should also be noted that recovery times for a data disaster involving data corruption, deletion, or obfuscation will always be greater than zero and the recovery point will always be at some point before the disaster was discovered. If the additional complexity and cost of a multi-site active/active Standorten (oder Hot-Standby) erforderlich ist, um Wiederherstellungszeiten von nahezu Null einzuhalten, sollten zusätzliche Anstrengungen unternommen werden, um die Sicherheit aufrechtzuerhalten und menschliches Versagen zu verhindern, um menschliche Katastrophen zu vermeiden.
AWS-Services
Alle AWS-Services, die unter Backup and Restore, Pilot Light und Warm Standby fallen, werden hier auch für point-in-time Datensicherung, Datenreplikation, active/active Datenweiterleitung sowie Bereitstellung und Skalierung der Infrastruktur einschließlich EC2 Instances verwendet.
Für die zuvor erörterten active/passive Szenarien (Pilot Light und Warm Standby) AWS Global Accelerator können sowohl Amazon Route 53 als auch für die Weiterleitung des Netzwerkverkehrs in die aktive Region verwendet werden. Für die hier active/active vorgestellte Strategie ermöglichen beide Dienste auch die Definition von Richtlinien, mit denen festgelegt wird, welche Benutzer zu welchem aktiven regionalen Endpunkt gehen. Außerdem stellen AWS Global Accelerator Sie eine Verkehrswahl ein, um den Prozentsatz des Datenverkehrs zu steuern, der an jeden Anwendungsendpunkt geleitet wird. Amazon Route 53 unterstützt diesen prozentualen Ansatz sowie mehrere andere verfügbare Richtlinien, einschließlich Richtlinien, die auf Geonähe und Latenz basieren. Global Accelerator nutzt automatisch das umfangreiche Netzwerk von AWS-Edge-Servern, um den Datenverkehr so schnell wie möglich in den AWS-Netzwerk-Backbone einzubinden, was zu geringeren Latenzen bei Anfragen führt.
Die asynchrone Datenreplikation mit dieser Strategie ermöglicht einen RPO-Wert von nahezu Null. AWS-Services wie Amazon Aurora Global Database verwenden eine spezielle Infrastruktur, sodass Ihre Datenbanken vollständig für Ihre Anwendung verfügbar sind und in bis zu fünf sekundäre Regionen mit einer typischen Latenz von unter einer Sekunde repliziert werden können. With active/passive strategies, writes occur only to the primary Region. The difference with active/active entwirft, wie die Datenkonsistenz bei Schreibvorgängen in jede aktive Region gehandhabt wird. Es ist üblich, Lesevorgänge für Benutzer so zu gestalten, dass sie von der Region aus zugestellt werden, die ihnen am nächsten ist. Dies wird als lokale Lesevorgänge bezeichnet. Bei Schreibvorgängen stehen Ihnen mehrere Optionen zur Verfügung:
-
Bei einer globalen Schreibstrategie werden alle Schreibvorgänge an eine einzige Region weitergeleitet. Falls diese Region ausfällt, wird eine andere Region befördert, sodass sie Schreibvorgänge akzeptiert. Die globale Aurora-Datenbank eignet sich hervorragend für Write Global, da sie die regionsübergreifende Synchronisation mit Lesereplikaten unterstützt und Sie eine der sekundären Regionen in weniger als einer Minute zur Übernahme von read/write Aufgaben ernennen können. Aurora unterstützt auch die Schreibweiterleitung, sodass sekundäre Cluster in einer globalen Aurora-Datenbank SQL-Anweisungen, die Schreibvorgänge ausführen, an den primären Cluster weiterleiten können.
-
Eine lokale Schreibstrategie leitet Schreibvorgänge in die nächstgelegene Region weiter (genau wie Lesevorgänge). Die globalen Tabellen von Amazon DynamoDB ermöglichen eine solche Strategie und ermöglichen Lese- und Schreibvorgänge aus jeder Region, in der Ihre globale Tabelle bereitgestellt wird. Globale Amazon DynamoDB-Tabellen verwenden einen Last-Writer-Wins-Abgleich zwischen gleichzeitigen Aktualisierungen.
-
Bei einer partitionierten Schreibstrategie werden Schreibvorgänge anhand eines Partitionsschlüssels (wie einer Benutzer-ID) einer bestimmten Region zugewiesen, um Schreibkonflikte zu vermeiden. Die bidirektional konfigurierte
Amazon S3 S3-Replikation kann für diesen Fall verwendet werden und unterstützt derzeit die Replikation zwischen zwei Regionen. Achten Sie bei der Implementierung dieses Ansatzes darauf, die Synchronisierung von Replikatänderungen für beide Buckets A und B zu aktivieren, um Änderungen an Replikat-Metadaten wie Objektzugriffskontrolllisten (ACLs), Objekt-Tags oder Objektsperren für die replizierten Objekte zu replizieren. Sie können auch konfigurieren, ob Löschmarkierungen zwischen Buckets in Ihren aktiven Regionen repliziert werden sollen oder nicht. Neben der Replikation muss Ihre Strategie auch point-in-time Backups zum Schutz vor Datenbeschädigung oder -vernichtung beinhalten.
AWS CloudFormation ist ein leistungsstarkes Tool zur Durchsetzung einer konsistent bereitgestellten Infrastruktur zwischen AWS-Konten in mehreren AWS-Regionen. AWS CloudFormation StackSetserweitert diese Funktionalität, indem es Ihnen ermöglicht, CloudFormation Stacks für mehrere Konten und Regionen mit einem einzigen Vorgang zu erstellen, zu aktualisieren oder zu löschen. AWS CloudFormation Verwendet zwar YAML oder JSON, um Infrastruktur als Code zu definieren, AWS Cloud Development Kit (AWS CDK)
