Lösungen für Streaming-Daten: Beispiele
Szenario 1: Internetangebot basierend auf dem Standort
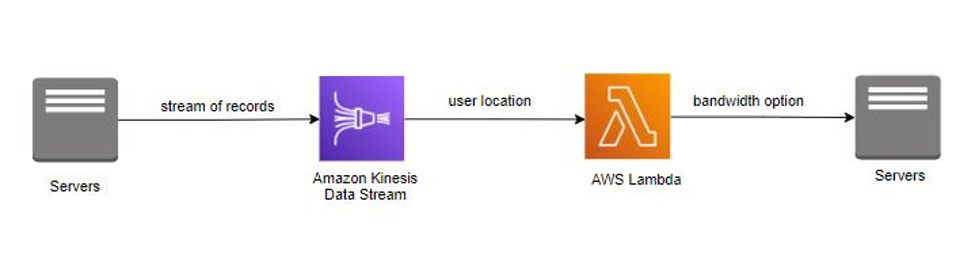
Das Unternehmen InternetProvider bietet Internetdienste mit einer Vielzahl von Bandbreitenoptionen für Benutzer auf der ganzen Welt. Wenn sich ein Benutzer für das Internet anmeldet, bietet das Unternehmen InternetProvider dem Benutzer je nach geografischem Standort verschiedene Bandbreitenoptionen an. Vor dem Hintergrund dieser Anforderungen implementierte das Unternehmen InternetProvider Amazon Kinesis Data Stream, um die Benutzer- und Standortdaten zu nutzen. Die Benutzer- und Standortdaten werden mit verschiedenen Bandbreitenoptionen angereichert, bevor sie an die Anwendung zurückgegeben werden. AWS Lambda
Verarbeitung von Datenströmen mit AWS Lambda
Amazon Kinesis Data Streams
Mit Amazon Kinesis Data Streams
Bei der Implementierung einer Lösung mit Kinesis Data Streams erstellen Sie benutzerdefinierte Datenverarbeitungsanwendungen, die als Kinesis-Data-Streams-Anwendungen bezeichnet werden. Eine typische Kinesis-Data-Streams-Anwendung liest Daten in Form von Datensätzen aus einem Kinesis-Stream.
Die in Kinesis-Data-Streams übertragenen Daten sind hochverfügbar und elastisch und stehen innerhalb von Millisekunden zur Verfügung. Sie können kontinuierlich verschiedene Datentypen wie Clickstreams, Anwendungsprotokolle und soziale Medien aus Hunderttausenden von Quellen einem Kinesis-Stream hinzufügen. Die Daten sind dann innerhalb von Sekunden für Ihre Kinesis-Anwendungen
Amazon Kinesis Data Streams ist ein vollständig verwalteter Daten-Streaming-Service. Er verwaltet Infrastruktur, Speicher, Vernetzung und Konfiguration, die zum Streamen Ihrer Daten mit dem von Ihrer Anwendung benötigten Durchsatzgrad erforderlich sind.
Senden von Daten an Amazon Kinesis Data Streams
Es gibt mehrere Möglichkeiten, Daten an Kinesis Data Streams zu senden, wodurch Sie bei der Gestaltung Ihrer Lösungen flexibel sind.
-
Sie können Code mit einem der AWS SDKs
schreiben, die von mehreren gängigen Sprachen unterstützt werden. -
Sie können den Amazon Kinesis Agent verwenden, ein Tool zum Senden von Daten an Kinesis Data Streams.
Die Amazon Kinesis Producer Library (KPL) vereinfacht die Entwicklung von Produzentenanwendungen, wodurch Entwickler einen hohen Schreibdurchsatz auf einen oder mehreren Kinesis-Datenströmen erzielen.
Die KPL ist eine einfach zu verwendende, hochgradig konfigurierbare Bibliothek, die Sie auf Ihren Hosts installieren. Sie dient als Vermittler zwischen dem Code Ihrer Produzentenanwendung und den Kinesis-Streams-API-Aktionen. Weitere Informationen über die KPL und ihre Fähigkeit, Ereignisse synchron und asynchron zu erzeugen, sowie Codebeispiele finden Sie unter Schreiben in Kinesis-Datenströme mithilfe der KPL
In der API von Kinesis Data Streams gibt es zwei verschiedene Vorgänge, mit denen Daten zu einem Datenstrom hinzugefügt werden: PutRecords und PutRecord. Mit dem PutRecords-Vorgang werden mehrere Datensätze pro HTTP-Anfrage an Ihren Stream gesendet, während mit PutRecord einen Datensatz pro HTTP-Anfrage übermittelt wird. Um einen höheren Durchsatz für die meisten Anwendungen zu erreichen, verwenden Sie PutRecords.
Weitere Informationen zu diesen APIs finden Sie unter Hinzufügen von Daten zu einem Stream. Die Details für jeden API-Vorgang finden Sie in der Referenz zur API von Amazon Kinesis Data Streams.
Verarbeitung von Daten in Amazon Kinesis Data Streams
Um Daten aus Kinesis-Streams zu lesen und zu verarbeiten, müssen Sie eine Verbraucheranwendung erstellen. Es gibt verschiedene Möglichkeiten, Verbraucher für Kinesis Data Streams zu erstellen. Einige dieser Ansätze umfassen die Verwendung von Amazon Kinesis Data Analytics
Verbraucheranwendungen für Kinesis Data Streams können mit der KCL entwickelt werden, die Sie bei der Nutzung und Verarbeitung von Daten aus Kinesis Data Streams unterstützt. Die KCL übernimmt viele der komplexen Aufgaben im Zusammenhang mit verteilter Datenverarbeitung, wie beispielsweise die Vornahme der Lastenverteilung zwischen mehreren Instances, das Reagieren auf Instance-Fehler, das Einrichten von Prüfpunkten für verarbeitete Datensätze und das Reagieren auf Resharding. Die KCL ermöglicht Ihnen, sich auf das Schreiben der Datensatzverarbeitungslogik zu konzentrieren. Weitere Informationen zum Erstellen einer eigenen KCL-Anwendung finden Sie unter Verwenden der Kinesis Client Library.
Sie können Lambda-Funktionen abonnieren, um automatisch Datensatz-Batches aus Ihrem Kinesis-Stream zu lesen und sie zu verarbeiten, wenn Datensätze im Stream erkannt werden. AWS Lambda fragt den Stream regelmäßig (einmal pro Sekunde) nach neuen Datensätzen ab. Werden neue Datensätze erkannt, ruft der Service die Lambda-Funktion auf und übergibt die neuen Datensätze als Parameter. Die Lambda-Funktion wird nur ausgeführt, wenn neue Datensätze erkannt werden. Sie können eine Lambda-Funktion einem Verbraucher mit gemeinsamem Durchsatz (Standard-Iterator) zuordnen.
Sie können einen Verbraucher erstellen, der eine Funktion namens Enhanced Fan-Out (Erweitertes Rundsenden) verwendet, wenn Sie einen speziellen Durchsatz benötigen, der nicht mit anderen Verbrauchern, die Daten aus dem Stream empfangen, konkurrieren soll. Mit dieser Funktion können Verbraucher Datensätze aus einem Stream mit einem Durchsatz von bis zu zwei MB Daten pro Sekunde und Shard empfangen.
In den meisten Fällen sollte Kinesis Data Analytics, KCL, AWS Glue oder AWS Lambda verwendet werden, um Daten aus einem Stream zu verarbeiten. Wenn Sie möchten können Sie jedoch mit der API von Kinesis Data Streams eine Verbraucheranwendung von Grund auf neu erstellen. Die API von Kinesis Data Streams bietet die Methoden GetShardIterator und GetRecords zum Abrufen von Daten aus einem Stream.
Bei diesem Pull-Modell extrahiert Ihr Code Daten direkt aus den Shards des Streams. Weitere Informationen zum Schreiben Ihrer eigenen Verbraucheranwendung mithilfe der API finden Sie unter Entwickeln benutzerdefinierter Verbraucher mit gemeinsam genutztem Durchsatz mithilfe des AWS SDK für Java. Details zur API finden Sie in der Referenz zur API von Amazon Kinesis Data Streams.
Verarbeitung von Datenströmen mit AWS Lambda
Mit AWS Lambda
AWS Lambda lässt sich nativ in Amazon Kinesis Data Streams integrieren. Die Komplexität von Abfragen, Prüfpunkten und Fehlerbehandlung wird durch die Verwendung dieser nativen Integration reduziert. Dadurch kann sich der Lambda-Funktionscode auf die Verarbeitung der Geschäftslogik konzentrieren.
Sie können eine Lambda-Funktion einem Verbraucher mit gemeinsam genutzten Durchsatz (Standard-Iterator) oder einem Verbraucher mit dediziertem Durchsatz mit erweitertem Rundsenden zuordnen. Bei einem Standard-Iterator fragt Lambda jeden Shard in Ihrem Kinesis-Stream nach Datensätzen ab, die das HTTP-Protokoll verwenden. Um die Latenz zu minimieren und den Lesedurchsatz zu maximieren, können Sie einen Datenstromverbraucher mit erweitertem Rundsenden erstellen. Stream-Verbraucher in dieser Architektur erhalten eine dedizierte Verbindung zu jedem Shard, ohne mit anderen Anwendungen zu konkurrieren, die aus demselben Stream lesen. Amazon Kinesis Data Streams überträgt Datensätze über HTTP/2 an Lambda.
Standardmäßig ruft AWS Lambda Ihre Funktion auf, sobald Datensätze im Stream verfügbar sind. Um die Datensätze für Batch-Szenarien zu puffern, können Sie an der Ereignisquelle ein Batch-Fenster von bis zu fünf Minuten implementieren. Wenn Ihre Funktion einen Fehler zurückgibt, wiederholt Lambda die Batch-Verarbeitung, bis diese erfolgreich ist oder die Daten ablaufen.
Übersicht
Das Unternehmen InternetProvider nutzte Amazon Kinesis Data Streams zum Streamen von Benutzer- und Standortdaten. Der Datenstrom wurde von AWS Lambda genutzt, um die Daten mit Bandbreitenoptionen anzureichern, die in der Bibliothek der Funktion gespeichert sind. Nach der Anreicherung übermittelte AWS Lambda die Bandbreitenoptionen zurück an die Anwendung. Amazon Kinesis Data Streams und AWS Lambda übernahmen die Bereitstellung und Verwaltung der Server, sodass sich das Unternehmen InternetProvider stärker auf die Entwicklung von Geschäftsanwendungen konzentrieren konnte.
