End of support notice: On September 25, 2025, AWS will discontinue support for NICE EnginFrame.
After September 25, 2025, you will no longer be able to access the NICE EnginFrame console or NICE EnginFrame
resources. For more information, visit this blog post
About NICE EnginFrame
EnginFrame is a grid-enabled application portal for user-friendly HPC job submission, control, and monitoring. It includes sophisticated data management for all stages of job lifetime. It's integrated with most important job schedulers and middleware tools to submit, monitor, and manage jobs.
EnginFrame provides a modular system where you can easily add new functionality, such as application integrations, authentication sources, and license monitoring. It also features a sophisticated web services interface that you can use to enhance existing applications and develop custom solutions for your own environment.
EnginFrame is a computing portal that uses existing scripting solutions when available. This means that, while using EnginFrame, you can avoid interacting with a command line interface in situations where you might have not had that option before.
Based on the latest and most advanced Web 2.0 standards, it provides a flexible infrastructure to support current and future computing needs. It's flexible in content presentation and in providing a personalized experience for users according to their role or operational context.
Note
Starting March 31, 2022, NICE EnginFrame doesn't support VNC®, HP® RGS, VirtualGL, and Amazon DCV 2016 and previous versions.
Note
Starting August 5, 2022, NICE EnginFrame is bundled with an embedded version of Tomcat® that doesn't provide any sample webapps.
According to CVE-2022-34305
Architectural overview
EnginFrame has an architecture layered into three tiers, as shown in EnginFrame architecture:
-
The Client Tier usually consists of the user's web browser. It provides an intuitive software interface that uses established web standards such as XHTML and JavaScript®. This tier is independent from the specific software and hardware environment that the end user uses. The Client Tier can also integrate remote visualization technologies such as Amazon DCV.
-
The Server Tier consists of a Server that interacts with EnginFrame Agents and manages the interaction with users.
-
The Resource Tier consists of one or more Agents that are deployed on the back-end infrastructure. Agents manage computing resources on user's behalf and interact with the underlying operating system, job scheduler, or grid infrastructure to run EnginFrame services. For example, they start jobs, move data, and retrieve cluster loads.
Topics
EnginFrame architecture

Basic workflow
EnginFrame abstracts computing resources and data management (Resource Tier) and exposes services to users (Server Tier). Users access the services directly from their browsers (Client Tier).
The internal structure of EnginFrame reflects this high-level architecture and revolves around two main software components: the EnginFrame Server and the EnginFrame Agent.
- The EnginFrame Server
-
The EnginFrame Server is a Java™ web application. It must be deployed inside a Java Servlet container. It exposes services to users. EnginFrame ships with Apache Tomcat® 9.0.64
. - The EnginFrame Agent
-
The EnginFrame Agent is a stand-alone Java™ application that manages the computing resources and run services on user's behalf when running as
root.
EnginFrame Server receives incoming requests from a web browser. The web browser authenticates and authorizes them, and then asks an EnginFrame Agent to run the required actions. For a visual illustration, see Interaction diagram.
Agents can perform different kinds of actions. This includes running a command on the underlying operating system and submitting a job on the grid infrastructure.
The results of the action that was run are gathered by the Agent and sent back to the Server.
The Server applies some post processing transformations, filters output according to defined access control lists (ACL), and transforms the results into an HTML page.
Interaction diagram

EnginFrame creates or reuses a data area each time a new action is run. This area is called spooler.
The spooler is the working directory of the action. It contains files uploaded when the action is submitted. Users can only download files from their spoolers.
The spooler is located on a file-system readable and writable by both Server and Agent. For more information, see Managing spoolers.
Deploying the service
When EnginFrame Portal is installed on one host, it's called a basic installation. The Server Tier contains the Agent that's
used to access the Resource Tier. The efnobody user runs the Server in this scenario. This is the default user that you choose when
you install EnginFrame. The EnginFrame Server contains a local Agent that's used when configured in your service description and you are
submitting a scriptlet. For a visual illustration, see EnginFrame deployed on one
host.
In most cases, the Server contacts the default remote Agent that was configured during setup. Usually, the remote
Agent runs as root and can do the following:
-
Authenticate users using PAM/NIS.
-
Create or delete spoolers on the user's behalf.
-
Run services on the user's behalf.
-
Download files on the user's behalf.
The remote Agent can also run as a user without permission. However, you lose the main features of an Agent running as root.
All spoolers and services are created or run as this user without permission. It also implies that EnginFrame has to use an authentication module that
doesn't require root privileges to check credentials, such as LDAP and Active
Directory.
The Server communicates with the Remote Agent using Java™ RMI protocol
EnginFrame deployed on one host

Distributed deployment
EnginFrame Server can be deployed in a demilitarized zone (DMZ) that's accessible from your intranet or the internet. The default EnginFrame Agent resides in your protected computing environment. EnginFrame Server and EnginFrame Agent reside on different hosts in this scenario. This is called a distributed deployment. For a visual illustration, see EnginFrame deployed on more hosts.
In this scenario, the following requirements must be met:
-
The Server host reaches the Agent host on ports that were specified during setup.
-
The Agent host reaches the Server host by HTTP on a port that was specified during setup.
-
Spoolers are stored on a shared file-system.
-
The Spooler shared file-system is readable and writable by both the
efnobodyandrootusers.
The Server must reach the Agent using RMI. Otherwise, the user's submissions fail.
The Agent must reach the Server using HTTP. Otherwise, the user's downloads fail.
Note
Spoolers must reside on a shared file-system for the following reasons. The Server saves files that users send. A service run on an Agent must access them. Because files are written by the Server,
efnobody needs read access to traverse the directory structures when creating new spoolers and write access to write files. Because
services are run on the user's behalf, root needs write permissions on the spoolers area to give directory and files ownership to the
user that's running the service. This ownership change is necessary because the spooler and the files were created by efnobody.
EnginFrame deployed on more hosts

File downloads
Users can only download files that are contained in their spoolers. The following diagram explains this process flow.

-
EnginFrame Server receives incoming requests from the Web Browser.
-
EnginFrame Server forwards the request to EnginFrame Agent, which then downloads the remote file.
-
As a user, EnginFrame Agent forks a process which reads the file.
-
EnginFrame Agent connects back to EnginFrame Server using HTTP to send back the bytes that were produced by the forked process.
-
EnginFrame Server sends the bytes back to the browser.
-
The browser displays the file or proposes to save it on disk depending on file mime-type and browser settings. For more information, see Managing internet media types.
Step 4 highlights why it's important for EnginFrame Agent to reach EnginFrame Server using HTTP.
You can use EnginFrame to download files in streaming mode. File contents are displayed while they're being downloaded. This is useful for files that grow when the service is running. The flow is the same as the remote file download except that EnginFrame Server polls, at fixed intervals, EnginFrame Agent for some fresh data. This feature mimics Unix tail that displays the last file portion while it grows.
File download interaction
Interactive session broker
EnginFrame 2021.0 includes the interactive plugin, a session broker that's scalable and reliable. Its main purpose is to ease application delivery and manage interactive sessions.
Deployment
The solution relies on the following systems:
-
NICE EnginFrame. This is the kernel that Interactive Plugin is built on.
-
A resource manager software that allocates and reserves resources according to the specified resource sharing policy or a session broker.
-
One or more remote visualization middleware platforms, such as Amazon DCV.
For a complete list of the supported HPC workload managers, session brokers, and visualization middleware, see Prerequisites.
The visualization farm can be Linux® or Windows®.
Workflow
The following picture represents a real-world example infrastructure, including nodes with Amazon DCV, HP® RGS, and RealVNC®. You can use this infrastructure to deliver 2D and 3D applications on Windows® and Linux® through Amazon DCV or VNC®.
Interactive Plugin Use Model
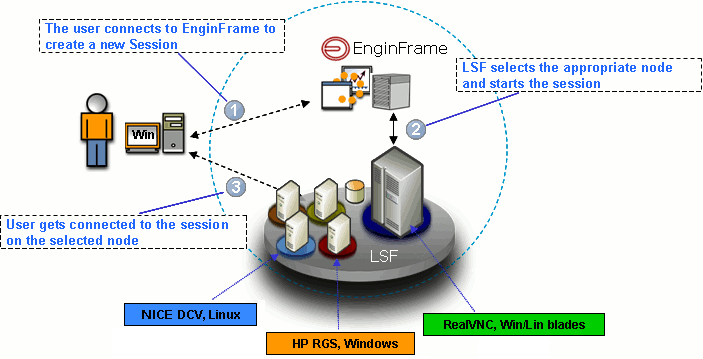
The following explains what happens at each step:
-
The user connects to Interactive Plugin to create a new session. Each session is a distinct job of the underlying HPC workload scheduler or a distinct session in the underlying third-party session broker.
-
The resource manager or the session broker schedules the new session on the most appropriate node. This node complies with the application requirements and the resource sharing policies.
-
After the session is created, Interactive Plugin sends a file to the web browser. This file contains information that allows the browser to start the correct visualization client. The client uses this information to connect to the remote session.
EnginFrame plugins
A plugin is a piece of software that extends EnginFrame Portal. NICE sells and provides many of these extensions at no cost.
The plugins can extend EnginFrame in many different areas:
-
Bundle - a full-featured package containing other plug-ins.
-
Kernel - an extension that enhances EnginFrame core system (for example, WebServices, Interactive Plug-in).
-
Auth - an extension that authenticates users against an authoritative source (for example, PAM Plug-in).
-
Data - an extension that helps display data inside EnginFrame Portal (for example, File Manager, RSpooler Plug-in).
-
Grid - an extension that connects EnginFrame Portal with a grid manager (for example, LSF Plug-in).
-
Util - additional utility components (for example, Demo Portal).
NICE ships many plugins according to these conventions:
-
Certified extensions - are developed and supported by NICE. They're available and supported as add-on products. Add-on products pass a quality assurance process at every new release of EnginFrame. Each extension is individually certified to work on the latest release of EnginFrame. The guidelines are provided to evaluate how different groups of extensions might interact. No implicit commitment is taken about the compatibility between two different extensions.
-
Qualified extensions - are developed or modified by NICE. This ensures a professional development and good functionality under some specific EnginFrame configuration. Qualified extensions are available as project-accelerator solutions, to facilitate integration of your EnginFrame Portal in specific complex scenarios. Further support can be provided as Professional Services.
-
Contributed extensions - are developed by third parties and are made available by the respective authors. They're provided as-is, and no additional endorsement is provided by NICE. Further support on such modules might be sought from the contributing authors, if available.
EnginFrame Enterprise
This section describes the EnginFrame Enterprise version, the solution aimed at enterprise environments where load balancing and fault tolerance are crucial requirements.
All the general concepts about EnginFrame explained in the previous sections apply also to EnginFrame Enterprise version. The following sections illustrate the characteristics of the Enterprise solution. They describe the architecture, highlight the differences with the architectures described earlier, and suggest the best approach for deployment.
Architecture
EnginFrame Enterprise architecture involves multiple EnginFrame Servers and multiple EnginFrame Agents. All the Servers and the Agents maintain the same role and functionalities. However, they do so in an EnginFrame Enterprise infrastructure and EnginFrame Servers are able to communicate with each other over the network to share and manage the system status.
The shared system status involves the following resources:
-
The users' spoolers and spoolers repository
-
EnginFrame triggers
-
Users that are logged in
-
EnginFrame license tokens
Information is shared among EnginFrame Servers and managed in a distributed architecture where there's no single point of failure in the system. Each of the servers alone can cover all the needed functionalities and, at the occurrence, it can keep the whole system up and running, making the system more robust and fault tolerant.
The EnginFrame Enterprise solution relies on a file-system that's not only shared between an EnginFrame Server and an EnginFrame Agent. It's shared among all the Servers and Agents. The EnginFrame Agents need access to the spoolers area. However, EnginFrame Servers have stronger requirements and need other file-system resources to be shared besides spoolers. These include the EnginFrame repository files that contain server-side metadata about spoolers, the file upload cache, and the plugins data directory tree. For more information about the suggested and supported approach for file-system sharing, see Deployment.
Another important component to consider in the EnginFrame architecture is the Database Management System (DBMS). In a standard EnginFrame installation, you can rely on the Apache Derby® database distributed with EnginFrame. In the EnginFrame Enterprise solution, however, use an external JDBC compliant DBMS. All the EnginFrame Servers must have access to the database. For a list of the supported DBMS, see Database management systems.
To maintain a single point of access to EnginFrame, the architecture involves a front-end HTTP/S network load balancer. This component isn't part of the EnginFrame Enterprise deployment. Rather, it's a third-party solution, which might be either a software or hardware component. This might be, for example, a Cisco router of the 6500 or 7600 series. The router, in this example, is configured with the sticky session capability † that dispatches users' requests to the EnginFrame Servers in a balanced way.
NICE can provide and set up the network load balancer based on third-party technology, such as Apache® Web server, as professional services activity according to specific projects with customers.
† Sticky session refers to the feature of many commercial load balancing solutions for web-farms to route the requests for a particular session to the same physical machine that serviced the first request for that session. The balancing occurs on web sessions. It doesn't occur on the single received web requests.
Software distribution and license
EnginFrame Enterprise is distributed with the same software package of EnginFrame. It's the EnginFrame software license that specifically enables EnginFrame Enterprise capabilities. EnginFrame doesn't need a license on an EC2 instance. For instructions on how to get the EnginFrame software and license, see Obtaining NICE EnginFrame.
The following is an example of an EnginFrame Enterprise license.
<?xml version="1.0"?> <ef-licenses> <ef-license-group product="EnginFrame HPC ENT" release="2015.0" format="2"> <ef-license component="EF Base" vendor="NICE" expiration="2015-12-31" ip="172.16.10.171,172.16.10.172" licensee="NICE RnD Team" type="DEMO" units="100" units-per-user="1" license-hosts="false" hosts-preemption="false" signature="MC0CFQCGPmb31gpiGxxEr0DdyoYud..." <!-- Omitted --> /> </ef-license-group> </ef-licenses>
The product attribute value is EnginFrame HPC ENT. This value defines an EnginFrame license for HPC environments with the
ENT string specifying the Enterprise version. The ip attribute of tag ef-license with the list of
the IP addresses of the licensed EnginFrame Servers nodes.
Deployment
Because of its distributed architecture, deployment scenarios of EnginFrame Enterprise might be different and vary in complexity.
You can have each component (specifically EnginFrame Server and Agent) on a different node. You can also decide to pick only the minimum number of parts of the file system to share on each of the node. Remember that, in an EnginFrame Enterprise deployment, you also have file-system resources to be shared among EnginFrame Servers. In many cases, even when resources don't necessarily require sharing, make sure that they're replicated and maintained in alignment among EnginFrame Servers.
Even if, in principle, it's possible to fine-tune the installation of EnginFrame Enterprise, consider the different factors, such as networking and file-system sharing. It's common practice to go for the comparatively fast and easy-to-maintain deployment approach that's described here. If this one doesn't meet your specific requirements, you can use a different approach. Discuss your requirements with NICE professional services to see what is the best approach for you.
The suggested approach to deploy EnginFrame Enterprise involves the following:
-
One node for each pair of EnginFrame Server and Agent that you want to install.
-
A shared file-system for the whole
$EF_TOPdirectory tree. -
$EF_TOPis the top EnginFrame installation directory.
For more information, see Installation directories.
With this approach, you can install and manage the software from one node. All the binaries and data directories such as spoolers, sessions, and licenses are shared among the installation nodes.
For those resources that are expected to be local but might conflict in a shared environment, EnginFrame provides a per-hostname directory tree. This directory tree includes a shared environment like the logging directory where each Server and Agent writes log files with the same names.
We recommend that you host an external database management system (DBMS) on different nodes and configure them to be fault tolerant.
When you install EnginFrame Enterprise, you insert the JDBC URL in the EnginFrame database instance together with the username and password that you use to access it. The EnginFrame database instance must be previously created empty, EnginFramecreates all the needed tables the first time you connect to it.
The details that specifically concern an EnginFrame Enterprise deployment, its requirements and installation notes, are integrated where needed in the next chapters of this guide.
AWS HPC Connector
HPC Connector provides a straight-forward way for HPC customers to use the elastic infrastructure that AWS ParallelCluster dynamically creates and manages on AWS. You can choose to install EnginFrame on-premises and use HPC Connector to extend available HPC environments to AWS. This installation scenario is suitable for use cases such as cloud bursting. Or, you can install EnginFrame directly on an Amazon EC2 instance and use HPC Connector to run workflows entirely on AWS. HPC Connector uses customer-defined cluster configurations for creating clusters in the cloud that you can use for running jobs.

You can use HPC Connector flexibly as your needs change over time. For example, you can use it to experiment with running select workloads on AWS or to manage most or all of your workloads on AWS. You can use HPC Connector to manage your HPC workloads from both your on-premises and AWS environments in a centralized fashion. For example, you might be migrating your workloads to AWS and need to manage and maintain both environments for some time. Or, you want to burst some workloads to the cloud when on-premises resources are insufficient to meet your requirements. Having access to elastic AWS resources can help to increase the productivity of your researchers. Moreover, you can use HPC Connector to get started managing hybrid on-premises and AWS environments in an more centralized manner.
How HPC Connector works
HPC Connector works by using AWS ParallelCluster. AWS ParallelCluster is an open-source cluster management tool on AWS that you can use to deploy and manage HPC clusters on AWS. It uses a simple text file to model and provision all the resources needed for your HPC applications in an automated and secure manner. With AWS ParallelCluster, the resources needed for your applications are dynamically scaled in an automated and secure manner. After a burst of jobs is completed, AWS ParallelCluster terminates the instances it created. This leaves only the head node and the minimum capacity defined active and ready to scale up new compute nodes when required.
When submitting a job to a remote cluster hosted on AWS , HPC Connector relies on AWS Systems Manager Session Manager for the job submission process, and uses
Amazon S3
-
Creates an Amazon S3 folder for transferring data from the user’s local spooler.
-
Generates a dynamic policy to restrict Amazon S3 access to the newly created Amazon S3 folder.
-
Creates a new set of temporary credentials that use the generated policy.
-
Launches a script for transferring the data that's in the local spooler to S3 using such credentials.
-
Runs a remote script on the head node of the remote cluster that uses AWS SSM, which performs the following actions.
-
Retrieves the data from the S3 folder using a set of temporary credentials (using the same mechanism described above). The data is then copied to the destination folder.
-
Changes the files and folder permissions to give ownership of the files to the remote user.
-
Submits the job as a remote user from within the destination folder, with the proper environment variables and launching the job script associated to the EnginFrame service.
-
HPC Connector run requirements
For HPC Connector to work properly, you must have an AWS account and create and configure the following items.
-
An Amazon S3 bucket that's used by HPC Connector for transferring the data from the spooler local to the node running the EnginFrame server to the remote clusters on AWS, or the other way around. HPC Connector doesn't support Using Amazon S3 bucket keys.
-
An IAM role for accessing the Amazon S3 bucket. This role is used by HPC Connector for transferring the data back and forth the remote destination.
-
An IAM role for managing AWS ParallelCluster in your account. This role is used by HPC Connector for creating, starting, and stopping clusters.
-
An IAM role for running jobs remotely using AWS SSM. This role is used for launching job scripts remotely on the clusters.
-
For EnginFrame on-premises, an IAM user for allowing HPC Connector to assume the required roles when managing clusters or launching remote jobs.
Cluster users
When launching a cluster from within HPC Connector, administrators must specify how to map users within the cluster with respect to the user launching the job. HPC Connector supports the following two different mechanisms for this.
-
Single user mode – In this mode, any user connected to the EnginFrame portal and with access to the cluster submits jobs to the cluster as a single predefined cluster user. This mode requires administrators to specify the user name to use when creating the cluster (for example, ec2-user or ubuntu).
-
Multi-user 1:1 mode – In this mode, any user connected to the EnginFrame portal and with access to the cluster submits jobs to the cluster as a remote cluster user with the same name.
HPC Connector does not provision or manage users on the cluster. This means that you're required to have such users already present in the cluster before submitting any job. Additionally, you might also need a mechanism to keep users in sync with your on-premises environment. HPC Connector maps the on-premises and remote users with the chosen logic. However, if the chosen user isn't available in the remote cluster, your job submissions will fail.
When requested to launch a job remotely, HPC Connector launches the job using AWS SSM. HPC Connector assumes the role of a remote user on the cluster depending on the mode. This is either the user specified when the cluster is created for single user mode or a user with the same name as the one logged in to the EnginFrame portal for multi-user mode.
