Migración física de MySQL con Percona XtraBackup y Amazon S3
Puede copiar los archivos de copia de seguridad completos e incrementales de la base de datos MySQL 5.7 o 8.0 de origen a un bucket de Amazon S3. A continuación, puede realizar la restauración a un clúster de base de datos de Amazon Aurora MySQL con la misma versión principal del motor de base de datos de esos archivos.
Esta opción puede ser bastante más rápida que migrar datos mediante mysqldump, ya que mysqldump repite todos los comandos para volver a crear el esquema y los datos a partir de la base de datos origen en el nuevo clúster de base de datos de Aurora MySQL. Al copiar los archivos de datos de MySQL de origen, Aurora MySQL puede utilizar inmediatamente esos archivos como datos para el clúster de base de datos de Aurora MySQL.
También puede reducir el tiempo de inactividad mediante el uso de la replicación de registros binarios durante el proceso de migración. Si usa la replicación de logs binarios, la base de datos MySQL externa permanece abierta a las transacciones mientras se migran los datos al clúster de base de datos de Aurora MySQL. Una vez creado el clúster de base de datos de Aurora MySQL, se usa la replicación de registros binarios para sincronizar el clúster de base de datos de Aurora MySQL con las transacciones que han tenido lugar después de la copia de seguridad. Cuando el clúster de base de datos de Aurora MySQL DB esté sincronizado con la base de datos MySQL, se termina la migración y se produce el cambio al clúster de base de datos de Aurora MySQL para las nuevas transacciones. Para obtener más información, consulte Sincronización del clúster de base de datos de Amazon Aurora MySQL con la base de datos MySQL mediante replicación.
Contenido
Limitaciones y consideraciones
Las siguientes limitaciones y consideraciones se aplican a la restauración a un clúster de base de datos de Amazon Aurora MySQL a partir de un bucket de Amazon S3:
-
Solo puede migrar los datos a un nuevo clúster de base de datos, no a un clúster de base de datos existente.
-
Debe utilizar Percona XtraBackup para realizar copias de seguridad de sus datos en S3. Para obtener más información, consulte Instalación de Percona XtraBackup.
-
El bucket de Amazon S3 y el clúster de base de datos de Aurora MySQL deben estar en la misma región de AWS.
-
No puede restaurar desde lo siguiente:
-
Una exportación de instantáneas del clúster de base de datos a Amazon S3. Tampoco puede migrar datos desde una exportación de instantáneas del clúster de base de datos a su bucket de S3.
-
Una base de datos de origen cifrada, pero puede cifrar los datos que se están migrando. También puede dejar los datos sin cifrar durante el proceso de migración.
-
Una base de datos MySQL 5.5 o 5.6.
-
-
Percona Server for MySQL no se admite como base de datos de origen, ya que puede contener tablas
compression_dictionary*en el esquemamysql. -
No puede llevar a cabo la restauración en un clúster de base de datos de Aurora Serverless.
-
No se admite la migración a versiones anteriores ni en las versiones principales ni en las secundarias. Por ejemplo, no puede migrar de la versión 8.0 de MySQL a la versión 2 de Aurora MySQL (compatible con MySQL 5.7) y no puede migrar de la versión 8.0.32 de MySQL a la versión 3.03 de Aurora MySQL, que es compatible con la versión de la comunidad 8.0.26 de MySQL.
-
No se puede migrar a la versión 3.05 o posteriores de Aurora MySQL desde algunas versiones anteriores de MySQL 8.0, como 8.0.11, 8.0.13 y 8.0.15. Le recomendamos que actualice a la versión 8.0.28 de MySQL antes de realizar la migración.
-
La importación de Amazon S3 no es compatible en la clase de instancia de base de datos db.t2.micro. Sin embargo, puede restaurar en otra clase de instancia de base de datos y, a continuación, cambiar la clase de instancia de base de datos posteriormente. Para obtener más información sobre las clases de instancias de bases de datos, consulte Clases de instancia de base de datos de Amazon Aurora.
-
Amazon S3 limita el tamaño de un archivo cargado en un bucket de S3 a 5 TB. Si un archivo de copia de seguridad supera los 5 TB, debe dividir el archivo de copia de seguridad en archivos más pequeños.
-
Amazon RDS limita el número de archivos cargados en un bucket de S3 a 1 millón. Si los datos de copia de seguridad de su base de datos, con todas las copias de seguridad completas e incrementales, superan 1 millón de archivos, use un archivo Gzip (.gz), tar (.tar.gz) o Percona xbstream (.xbstream) para almacenar archivos de copia de seguridad completas e incrementales en el bucket de S3. Percona XtraBackUp 8.0 solo admite Percona xbstream para la compresión.
-
Para proporcionar servicios de administración para cada clúster de base de datos, se crea el usuario
rdsadmincuando se crea el clúster de base de datos. Como se trata de un usuario reservado en RDS, se aplican las siguientes limitaciones:-
Las funciones, procedimientos, vistas, eventos y activadores con el definidor
'rdsadmin'@'localhost'no se importan. Para obtener más información, consulte Objetos almacenados con 'rdsadmin'@'localhost' como definidor y Privilegios de la cuenta de usuario maestro con Amazon Aurora MySQL.. -
Cuando se crea el clúster de base de datos de Aurora MySQL, se crea un usuario maestro con los privilegios máximos admitidos. Al restaurar desde una copia de seguridad, los privilegios no admitidos asignados a los usuarios que se importan se eliminan automáticamente durante la importación.
Para identificar a los usuarios que podrían verse afectados por esto, consulte Cuentas de usuario con privilegios no admitidos. Para obtener más información sobre los privilegios admitidos en Aurora MySQL, consulte Modelo de privilegios basado en roles.
-
-
En el caso de la versión 3 de Aurora MySQL, no se importan los privilegios dinámicos. Los privilegios dinámicos compatibles con Aurora se pueden importar después de la migración. Para obtener más información, consulte Privilegios dinámicos de la versión 3 de Aurora MySQL.
-
Las tablas creadas por el usuario en el esquema de
mysqlno se migran. -
El parámetro
innodb_data_file_pathdebe configurarse con un solo archivo de datos que utilice el nombre de archivo de datos predeterminadoibdata1:12M:autoextend. Las bases de datos con dos archivos de datos, o con un archivo de datos con un nombre diferente, no se pueden migrar con este método.A continuación se muestran ejemplos de nombres de archivo no permitidos:
innodb_data_file_path=ibdata1:50M,ibdata2:50M:autoextendyinnodb_data_file_path=ibdata01:50M:autoextend. -
No puede migrar de una base de datos de origen que tenga tablas definidas fuera del directorio de datos de MySQL predeterminado.
-
Actualmente, el tamaño máximo admitido para las copias de seguridad sin comprimir que utilizan este método está limitado a 64 TiB. En el caso de las copias de seguridad comprimidas, este límite se reduce para ajustarse a los requisitos de espacio de descompresión. En esos casos, el tamaño máximo admitido de la copia de seguridad sería (
64 TiB – compressed backup size). -
Aurora MySQL no admite la importación de MySQL ni de otros componentes y complementos externos.
-
Aurora MySQL no restaura todo lo que contiene la base de datos. Se recomienda guardar el esquema y los valores de la base de datos correspondientes para los siguientes elementos de la base de datos MySQL de origen y añadirlos al clúster de base de datos de Aurora MySQL restaurado una vez creado:
-
Cuentas de usuario
-
Funciones
-
Procedimientos almacenados
-
Información de zona horaria. Esta información se carga desde el sistema operativo local del clúster de base de datos de Aurora MySQL. Para obtener más información, consulte Zona horaria local para los clústeres de base de datos de Amazon Aurora.
-
Antes de empezar
Antes de copiar los datos en un bucket de Amazon S3 y restaurar a un clúster de base de datos a partir de esos archivos, debe hacer lo siguiente:
-
Instale Percona XtraBackup en su servidor local.
-
Permita que Aurora MySQL obtenga acceso a su bucket de Amazon S3 en su nombre.
Instalación de Percona XtraBackup
Amazon Aurora puede restaurar un clúster de base de datos a partir de archivos creados con Percona XtraBackup. Puede instalar Percona XtraBackup desde las descargas de software: Percona
Para la migración de MySQL 5.7, utilice Percona XtraBackup 2.4.
Para la migración de MySQL 8.0, utilice Percona XtraBackup 8.0. Asegúrese de que la versión de Percona XtraBackup sea compatible con la versión del motor de su base de datos de origen.
Permisos necesarios
Para migrar los datos de MySQL a un clúster de base de datos de Amazon Aurora MySQL, se requieren varios permisos:
-
El usuario que solicita que Aurora cree un nuevo clúster a partir de un bucket de Amazon S3 debe tener permiso para mostrar los buckets de su cuenta de AWS. Puede conceder este permiso al usuario mediante una política de AWS Identity and Access Management (IAM).
-
Aurora requiere permiso para realizar acciones en su nombre y acceder al bucket de Amazon S3 en el que se almacenan los archivos utilizados para crear el clúster de base de datos de Amazon Aurora MySQL. Puede conceder los permisos necesarios a Aurora mediante un rol de servicio de IAM.
-
El usuario que realiza la solicitud también debe tener permiso para enumerar los roles de IAM para la cuenta de AWS.
-
Si el usuario que ha realizado la solicitud va a crear la función del servicio de IAM o va a solicitar que Aurora cree la función del servicio de IAM (mediante la consola), el usuario debe tener permiso para crear un rol de IAM para la cuenta de AWS.
-
Si tiene previsto cifrar los datos durante el proceso de migración, actualice la política de IAM del usuario que va a realizar la migración para conceder a RDS acceso a las AWS KMS keys para cifrar los backups. Para obtener instrucciones, consulte Creación de una política de IAM para acceder a los recursos de AWS KMS.
Por ejemplo, la siguiente política de IAM concede a un usuario los permisos mínimos necesarios para que pueda utilizar la consola para mostrar los roles de IAM, crear un rol de IAM, mostrar los buckets de Amazon S3 de la cuenta y mostrar las claves de KMS.
Además, para que un usuario pueda asociar un rol de IAM a un bucket de Amazon S3, el usuario de IAM debe disponer del permiso iam:PassRole para ese rol de IAM. Este permiso hace que un administrador pueda restringir los roles de IAM que un usuario puede asociar a buckets de Amazon S3.
Por ejemplo, la siguiente política de IAM permite a un usuario asociar el rol denominado S3Access a un bucket de Amazon S3.
Para obtener más información sobre los permisos de usuario de IAM, consulte Administración de acceso mediante políticas.
Creación del rol de servicio de IAM
Puede hacer que la Consola de administración de AWS cree un rol para usted eligiendo la opción Create a New Role (Crear una función) (se explica más adelante en este tema). Si selecciona esta opción y especifica un nombre para el nuevo rol, Aurora crea el rol de servicio de IAM necesario para que Aurora acceda al bucket de Amazon S3 con el nombre que usted indique.
Como alternativa, puede crear el rol manualmente completando el siguiente procedimiento.
Para crear un rol de IAM para que Aurora pueda acceder a Amazon S3
-
Realice los pasos que se indican en Creación de una política de IAM para acceder a los recursos de Amazon S3.
-
Realice los pasos que se indican en Creación de un rol de IAM que permita a Amazon Aurora acceder a los servicios de AWS.
-
Realice los pasos que se indican en Asociación de un rol de IAM con un clúster de base de datos Amazon Aurora MySQL.
Copia de seguridad de archivos para restaurarlos como un clúster de base de datos de Amazon Aurora MySQL
Puede crear un backup completo de los archivos de la base de datos MySQL usando Percona XtraBackup y cargar los archivos de backup en un bucket de Amazon S3. Como alternativa, si ya usa Percona XtraBackup para realizar los backups de los archivos de la base de datos MySQL, puede cargar los archivos y los directorios de backup completos e incrementales en un bucket de Amazon S3.
Temas
Creación de una copia de seguridad completa con Percona XtraBackup
Para crear una copia de seguridad completa de los archivos de la base de datos MySQL que se puedan restaurar desde Amazon S3 para crear un clúster de base de datos de Aurora MySQL, use la utilidad Percona XtraBackup (xtrabackup) para realizar una copia de seguridad de la base de datos.
Por ejemplo, el siguiente comando crea un backup de una base de datos MySQL y almacena los archivos en la carpeta /on-premises/s3-restore/backup.
xtrabackup --backup --user=<myuser>--password=<password>--target-dir=</on-premises/s3-restore/backup>
Si desea comprimir su backup en un solo archivo (que se puede dividir si es necesario), puede utilizar la opción --stream para guardar el backup en uno de los siguientes formatos:
-
Gzip (.gz)
-
tar (.tar)
-
Percona xbstream (.xbstream)
El siguiente comando crea una copia de seguridad de la base de datos MySQL dividido en varios archivos Gzip.
xtrabackup --backup --user=<myuser>--password=<password>--stream=tar \ --target-dir=</on-premises/s3-restore/backup>| gzip - | split -d --bytes=500MB \ -</on-premises/s3-restore/backup/backup>.tar.gz
El siguiente comando crea una copia de seguridad de la base de datos MySQL dividido en varios archivos tar.
xtrabackup --backup --user=<myuser>--password=<password>--stream=tar \ --target-dir=</on-premises/s3-restore/backup>| split -d --bytes=500MB \ -</on-premises/s3-restore/backup/backup>.tar
El siguiente comando crea una copia de seguridad de la base de datos MySQL dividido en varios archivos xbstream.
xtrabackup --backup --user=<myuser>--password=<password>--stream=xbstream \ --target-dir=</on-premises/s3-restore/backup>| split -d --bytes=500MB \ -</on-premises/s3-restore/backup/backup>.xbstream
nota
Si aparece el siguiente error, puede deberse a que se han mezclado formatos de archivo en el comando:
ERROR:/bin/tar: This does not look like a tar archive
Una vez realizado el backup de la base de datos MySQL con la utilidad Percona XtraBackup, ya podrá copiar los directorios y los archivos del backup en un bucket de Amazon S3.
Para obtener más información acerca de cómo crear y cargar un archivo en un bucket de Amazon S3, consulte Introducción a Amazon Simple Storage Service en la Guía de introducción a Amazon S3.
Uso de copias de seguridad incrementales con Percona XtraBackup
Amazon Aurora MySQL admite backups completos e incrementales creados con Percona XtraBackup. Si ya usa Percona XtraBackup para realizar copias de seguridad completas e incrementales de sus archivos de base de datos MySQL, no tiene que crear una copia de seguridad completa y cargar los archivos del backup en Amazon S3. En lugar de eso, puede ahorrar una cantidad considerable de tiempo copiando los directorios y archivos de backup de sus backups completos e incrementales en un bucket de Amazon S3. Para obtener más información, consulte el artículo sobre creación de una copia de seguridad incremental
Cuando copie los archivos de backup completos o incrementales en un bucket de Amazon S3, debe copiar repetidamente el contenido del directorio base. Esos contenidos incluyen el backup completo y también todos los directorios y archivos del backup incremental. Esta copia debe mantener la estructura de directorios en el bucket de Amazon S3. Aurora realiza iteraciones por todos los archivos y directorios. Aurora utiliza el archivo xtrabackup-checkpoints incluido con cada copia de seguridad progresiva para identificar el directorio base y ordenar las copias de seguridad progresivas por rango del número de secuencia del registro (LSN).
Para obtener más información acerca de cómo crear y cargar un archivo en un bucket de Amazon S3, consulte Introducción a Amazon Simple Storage Service en la Guía de introducción a Amazon S3.
Consideraciones sobre copias de seguridad
Aurora no admite copias de seguridad parciales creados con Percona XtraBackup. No puede utilizar las siguientes opciones para crear una copia de seguridad parcial al realizar copias de seguridad de los archivos de origen de su base de datos: --tables, --tables-exclude, --tables-file, --databases, --databases-exclude o --databases-file.
Para obtener más información acerca de cómo realizar una copia de seguridad de su base de datos con Percona XtraBackup, consulte la documentación de Percona XtraBackup
Aurora admite copias de seguridad incrementales creadas con Percona XtraBackup. Para obtener más información, consulte el artículo sobre creación de una copia de seguridad incremental
Aurora consume sus archivos de copia de seguridad en función del nombre de archivo. Asegúrese de asignar la extensión de archivo adecuada a los archivos de copia de seguridad según el formato de archivo: por ejemplo, .xbstream para archivos almacenados con el formato xbstream de Percona.
Aurora consume sus archivos de backup en orden alfabético, así como según la numeración natural. Utilice siempre la opción split al ejecutar el comando xtrabackup para asegurarse de que la escritura y la asignación de nombre de sus archivos de backup se realice en el orden correcto.
Amazon S3 limita el tamaño de un archivo cargado en un bucket de Amazon S3 a 5 TB. Si los datos del backup de su base de datos superan los 5 TB, use el comando split para dividir los archivos de backup en varios archivos que ocupen menos de 5 TB.
Aurora limita el número de archivos de origen cargados en un bucket de Amazon S3 a 1 millón de archivos. En algunos casos, los datos de backup de su base de datos con todos los backups completos e incrementales incluyen un número elevado de archivos. En estos casos, usa un archivo tarball (.tar.gz) para almacenar los archivos de backups completos e incrementales en el bucket de Amazon S3.
Cuando carga un archivo en un bucket de Amazon S3, puede usar el cifrado del lado del servidor para cifrar los datos. Luego, puede restaurar un clúster de base de datos de Amazon Aurora MySQL a partir de estos archivos cifrados. Amazon Aurora MySQL puede restaurar un clúster de base de datos con archivos cifrados mediante los siguientes tipos de cifrado del lado del servidor:
-
Cifrado en el servidor con claves de cifrado administradas por Amazon S3 (SSE-S3): cada objeto está cifrado con una clave exclusiva que utiliza un cifrado multifactor seguro.
-
Cifrado en el servidor con claves administradas por AWS KMS (SSE-KMS): similar a SSE-S3, pero tiene la opción de crear y administrar usted mismo las claves de cifrado, así como otras diferencias.
Para obtener información sobre cómo usar el cifrado en el servidor al cargar archivos en un bucket de Amazon S3, consulte Protección de datos con el cifrado del lado del servidor en la Guía para desarrolladores de Amazon S3.
Restauración de un clúster de base de datos de Amazon Aurora MySQL desde un bucket de Amazon S3
Puede restaurar los archivos de copia de seguridad desde el bucket de Amazon S3 para crear un nuevo clúster de base de datos de Amazon Aurora MySQL mediante la consola de Amazon RDS.
Para restaurar un clúster de base de datos de Amazon Aurora MySQL a partir de los archivos de un bucket de Amazon S3
Inicie sesión en la Consola de administración de AWS y abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. -
En la esquina superior derecha de la consola de Amazon RDS, elija la región de AWS en la que se va a crear su clúster de base de datos. Elija la misma región de AWS que el bucket de Amazon S3 que contiene su copia de seguridad de base de datos.
-
En el panel de navegación, elija Databases (Bases de datos) y después Restore from S3 (Restaurar desde S3).
-
Elija Restore from S3 (Restaurar de S3).
Aparecerá la página Create database by restoring from S3 (Crear base de datos restaurando desde S3).
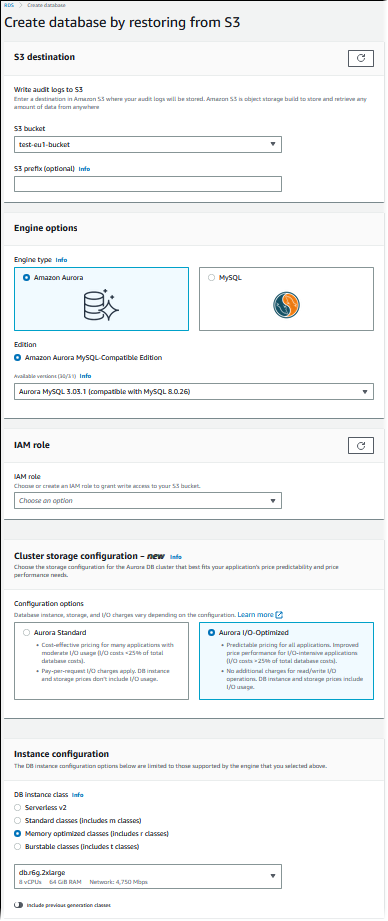
-
En S3 destination (destino de S3):
-
Elija el bucket de S3 que contiene sus archivos de copia de seguridad.
-
(Opcional) En S3 folder path prefix (Prefijo de ruta de carpeta de S3), escriba un prefijo de ruta de archivo para los archivos almacenados en el bucket de Amazon S3.
Si no especifica un prefijo, RDS creará su instancia de base de datos con todos los archivos y carpetas de la carpeta raíz del bucket de S3. Si especifica un prefijo, RDS creará su instancia de base de datos con los archivos y carpetas del bucket de S3 cuya ruta completa del archivo empieza con el prefijo especificado.
Por ejemplo, suponga que almacena los archivos de backup en S3 en una subcarpeta denominada copias de seguridad y que tiene varios conjuntos de archivos de backup, cada uno en su propio directorio (gzip_backup1, gzip_backup2, etc.). En este caso, debe especificar un prefijo de backups/gzip_backup1 para restaurar a partir de los archivos de la carpeta gzip_backup1.
-
-
En Engine options (Opciones del motor):
-
Para Engine type (Tipo de motor), elija Amazon Aurora.
-
En Version (Versión), elija la versión del motor Aurora MySQL para la instancia de base de datos restaurada.
-
-
En IAM Role (Rol de IAM), puede elegir un rol de IAM existente.
-
(Opcional) También puede hacer que se cree un nuevo rol de IAM eligiendo Create a new role (Crear un nuevo rol). Si es así:
-
Introduzca elIAM role name (Nombre de rol de IAM).
-
Elija si desea Allow access to KMS key (Permitir el acceso a la clave KMS):
-
Si no ha cifrado los archivos de copia de seguridad, elija No.
-
Si ha cifrado los archivos de copia de seguridad con AES-256 (SSE-S3) al cargarlos en Amazon S3, elija No. En este caso, los datos se encriptan de manera automática.
-
Si ha cifrado los archivos de copia de seguridad con cifrado en el servidor de AWS KMS (SSE-KMS) al cargarlos en Amazon S3, elija Yes (Sí). A continuación, elija la clave de KMS correcta para AWS KMS key.
La Consola de administración de AWS crea una política de IAM que permite a Aurora descifrar los datos.
Para obtener más información, consulte Protección de datos con el cifrado del lado del servidor en la Guía para desarrolladores de Amazon S3.
-
-
-
Elija la configuración del clúster de base de datos, como la configuración de almacenamiento del clúster de base de datos, la clase de instancia de base de datos, el identificador de clúster de base de datos y las credenciales de inicio de sesión. Para obtener más información acerca de cada ajuste, consulte Configuración de clústeres de bases de datos de Aurora.
-
Personalice la configuración adicional del clúster de base de datos Aurora MySQL según sea necesario.
-
Elija Create database (Crear base de datos) para iniciar la instancia de base de datos Aurora.
En la consola de Amazon RDS, la nueva instancia de base de datos aparece en la lista de instancias de base de datos. La instancia de la base de datos tendrá el estado creating hasta que se cree la instancia y esté lista para el uso. Cuando el estado cambie a available, podrá conectarse a la instancia principal de su clúster de base de datos. Dependiendo de la clase de instancia de base de datos y del almacenamiento asignado, es posible que la nueva instancia tarde varios minutos en estar disponible.
Para ver el clúster que acaba de crear, elija la vista Databases (Bases de datos) en la consola de Amazon RDS y elija el clúster de base de datos. Para obtener más información, consulte Visualización de un clúster de base de datos de Amazon Aurora.
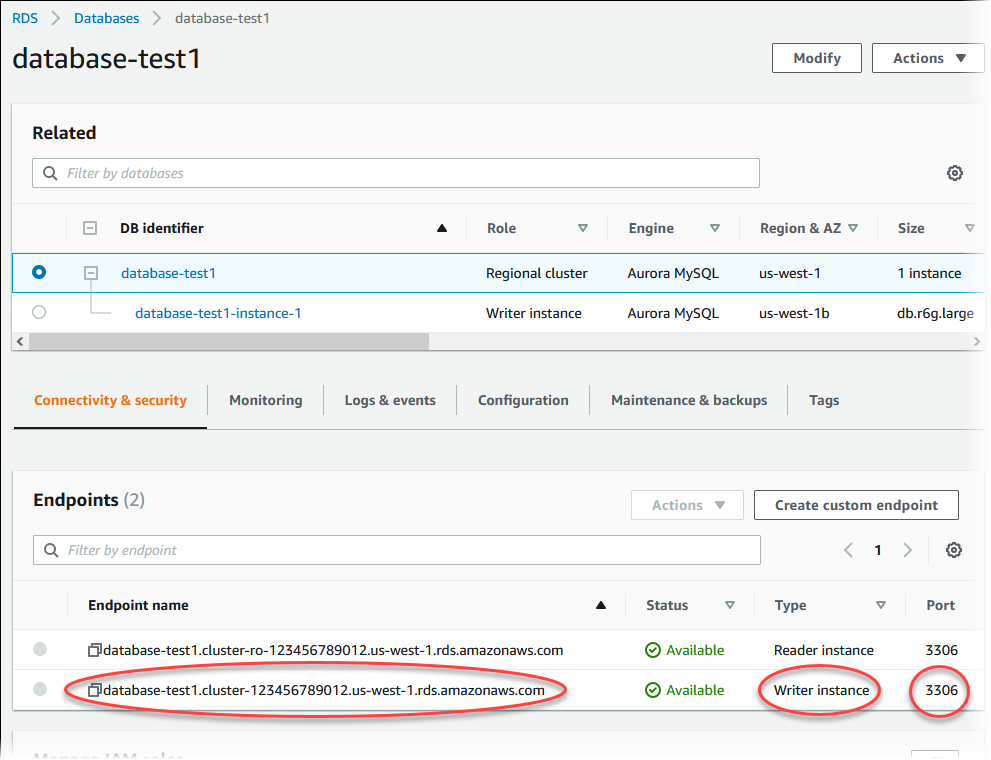
Anote el puerto y el punto de enlace del escritor del clúster de base de datos. Utilice el punto de enlace del escritor y el puerto del clúster de base de datos en sus cadenas de conexión JDBC y ODBC para cualquier aplicación que realice operaciones de lectura o escritura.
Sincronización del clúster de base de datos de Amazon Aurora MySQL con la base de datos MySQL mediante replicación
Para que no se produzcan interrupciones durante la migración, puede replicar las transacciones que se confirmaron en su base de datos MySQL en el clúster de base de datos de Aurora MySQL. La replicación permite al clúster de base de datos ponerse al día con las transacciones de la base de datos MySQL que se produjeron durante la migración. Cuando el clúster de base de datos esté totalmente sincronizado, puede detener la replicación y terminar la migración a Aurora MySQL.
Temas
Configuración de la base de datos MySQL externa y el clúster de base de datos de Aurora MySQL para la replicación cifrada
Para replicar los datos de forma segura, puede usar la replicación cifrada.
nota
Si no necesita usar la replicación cifrada, puede omitir estos pasos y pasar a las instrucciones de Sincronización del clúster de base de datos de Amazon Aurora MySQL con la base de datos MySQL externa.
A continuación, se indican los requisitos previos para utilizar la replicación cifrada:
-
La capa de conexión segura (SSL) debe estar habilitada en la base de datos principal de MySQL externa.
-
Debe disponerse de una clave cliente y un certificado cliente para el clúster de base de datos de Aurora MySQL.
Durante la replicación cifrada, el clúster de base de datos Aurora MySQL actúa como un cliente en el servidor de base de datos MySQL. Los certificados y las claves del cliente de Aurora MySQL son archivos con formato .pem.
Para configurar su base de datos MySQL externa y su clúster de base de datos de Aurora MySQL para la replicación cifrada
-
Compruebe que esté preparado para la replicación cifrada:
-
Si no tiene SSL habilitado en la base de datos principal de MySQL externa y no dispone de una clave cliente ni de un certificado cliente, habilite SSL en el servidor de base de datos de MySQL y genere la clave cliente y el certificado cliente necesarios.
-
Si SSL está habilitado en el primario externo, proporcione una clave cliente y un certificado cliente para el clúster de base de datos de Aurora MySQL. Si no los tiene, genere una nueva clave y certificado para el clúster de base de datos Aurora MySQL. Para firmar el certificado cliente, debe tener la clave de la entidad de certificación que usó para configurar SSL en la base de datos primaria de MySQL externa.
Para obtener más información, consulte Creating SSL Certificates and Keys Using openssl
en la documentación de MySQL. Necesita un certificado de la entidad de certificación, la clave cliente y el certificado cliente.
-
-
Conéctese al clúster de base de datos Aurora MySQL como usuario principal mediante SSL.
Para obtener información acerca de la conexión a un clúster de base de datos Aurora MySQL con SSL, consulte Conexiones TLS a clústeres de base de datos de Aurora MySQL.
-
Ejecute el procedimiento almacenado mysql.rds_import_binlog_ssl_material para importar la información de SSL en el clúster de base de datos Aurora MySQL.
Para el parámetro
ssl_material_value, inserte la información de los archivos con formato .pem para el clúster de base de datos Aurora MySQL en la carga JSON correcta.En el siguiente ejemplo se importa la información de SSL en un clúster de base de datos Aurora MySQL. En los archivos con formato .pem, el código del cuerpo suele ser más grande que el que se muestra en el ejemplo.
call mysql.rds_import_binlog_ssl_material( '{"ssl_ca":"-----BEGIN CERTIFICATE----- AAAAB3NzaC1yc2EAAAADAQABAAABAQClKsfkNkuSevGj3eYhCe53pcjqP3maAhDFcvBS7O6V hz2ItxCih+PnDSUaw+WNQn/mZphTk/a/gU8jEzoOWbkM4yxyb/wB96xbiFveSFJuOp/d6RJhJOI0iBXr lsLnBItntckiJ7FbtxJMXLvvwJryDUilBMTjYtwB+QhYXUMOzce5Pjz5/i8SeJtjnV3iAoG/cQk+0FzZ qaeJAAHco+CY/5WrUBkrHmFJr6HcXkvJdWPkYQS3xqC0+FmUZofz221CBt5IMucxXPkX4rWi+z7wB3Rb BQoQzd8v7yeb7OzlPnWOyN0qFU0XA246RA8QFYiCNYwI3f05p6KLxEXAMPLE -----END CERTIFICATE-----\n","ssl_cert":"-----BEGIN CERTIFICATE----- AAAAB3NzaC1yc2EAAAADAQABAAABAQClKsfkNkuSevGj3eYhCe53pcjqP3maAhDFcvBS7O6V hz2ItxCih+PnDSUaw+WNQn/mZphTk/a/gU8jEzoOWbkM4yxyb/wB96xbiFveSFJuOp/d6RJhJOI0iBXr lsLnBItntckiJ7FbtxJMXLvvwJryDUilBMTjYtwB+QhYXUMOzce5Pjz5/i8SeJtjnV3iAoG/cQk+0FzZ qaeJAAHco+CY/5WrUBkrHmFJr6HcXkvJdWPkYQS3xqC0+FmUZofz221CBt5IMucxXPkX4rWi+z7wB3Rb BQoQzd8v7yeb7OzlPnWOyN0qFU0XA246RA8QFYiCNYwI3f05p6KLxEXAMPLE -----END CERTIFICATE-----\n","ssl_key":"-----BEGIN RSA PRIVATE KEY----- AAAAB3NzaC1yc2EAAAADAQABAAABAQClKsfkNkuSevGj3eYhCe53pcjqP3maAhDFcvBS7O6V hz2ItxCih+PnDSUaw+WNQn/mZphTk/a/gU8jEzoOWbkM4yxyb/wB96xbiFveSFJuOp/d6RJhJOI0iBXr lsLnBItntckiJ7FbtxJMXLvvwJryDUilBMTjYtwB+QhYXUMOzce5Pjz5/i8SeJtjnV3iAoG/cQk+0FzZ qaeJAAHco+CY/5WrUBkrHmFJr6HcXkvJdWPkYQS3xqC0+FmUZofz221CBt5IMucxXPkX4rWi+z7wB3Rb BQoQzd8v7yeb7OzlPnWOyN0qFU0XA246RA8QFYiCNYwI3f05p6KLxEXAMPLE -----END RSA PRIVATE KEY-----\n"}');Para obtener más información, consulte mysql.rds_import_binlog_ssl_material y Conexiones TLS a clústeres de base de datos de Aurora MySQL.
nota
Después de ejecutar el procedimiento, los secretos se almacenan en archivos. Para borrar los archivos más tarde, puede ejecutar el procedimiento almacenado mysql.rds_remove_binlog_ssl_material.
Sincronización del clúster de base de datos de Amazon Aurora MySQL con la base de datos MySQL externa
Puede sincronizar su clúster de base de datos de Amazon Aurora MySQL con la base de datos MySQL mediante replicación.
Para sincronizar su clúster de base de datos de Aurora MySQL con la base de datos MySQL mediante replicación
-
Asegúrese de que el archivo /etc/my.cnf de la base de datos MySQL externa tenga las entradas pertinentes.
Si no se requiere la replicación cifrada, asegúrese de que la base de datos MySQL externa se inicia con los logs binarios (binlogs) habilitados y SSL deshabilitado. A continuación se indican las entradas pertinentes en el archivo /etc/my.cnf para los datos sin cifrar.
log-bin=mysql-bin server-id=2133421 innodb_flush_log_at_trx_commit=1 sync_binlog=1Si se requiere la replicación cifrada, asegúrese de que la base de datos MySQL externa se inicia con SSL y los binlogs habilitados. Las entradas del archivo /etc/my.cnf incluyen las ubicaciones del archivo .pem para el servidor de base de datos MySQL.
log-bin=mysql-bin server-id=2133421 innodb_flush_log_at_trx_commit=1 sync_binlog=1 # Setup SSL. ssl-ca=/home/sslcerts/ca.pem ssl-cert=/home/sslcerts/server-cert.pem ssl-key=/home/sslcerts/server-key.pemPuede confirmar que SSL está habilitado con el siguiente comando.
mysql>show variables like 'have_ssl';El resultado debería ser similar al siguiente.
+~-~-~-~-~-~-~-~-~-~-~-~-~-~--+~-~-~-~-~-~--+ | Variable_name | Value | +~-~-~-~-~-~-~-~-~-~-~-~-~-~--+~-~-~-~-~-~--+ | have_ssl | YES | +~-~-~-~-~-~-~-~-~-~-~-~-~-~--+~-~-~-~-~-~--+ 1 row in set (0.00 sec) -
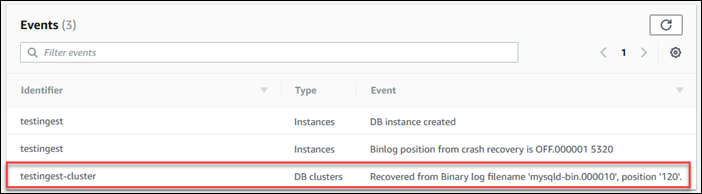
Determine la posición del registro binario inicial para la replicación: Especificará la posición para iniciar la replicación en un paso posterior.
Uso de Consola de administración de AWS
Inicie sesión en la Consola de administración de AWS y abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. -
En el panel de navegación, seleccione Events.
-
En la lista Events (Eventos), anote la posición del evento Recovered from Binary log filename (Recuperado del nombre de archivo de log binario).
Uso de AWS CLI
También puede obtener el nombre y la posición del archivo binlog utilizando el comando describe-events desde la AWS CLI. El siguiente es un ejemplo del comando
describe-events.PROMPT> aws rds describe-eventsEn la salida, identifique el evento que muestra la posición de binlog.
-
Mientras está conectado a la base de datos MySQL externa, cree el usuario que se va a usar para la replicación. Esta cuenta se usa únicamente para la replicación y debe estar limitada a su dominio para mejorar la seguridad. A continuación se muestra un ejemplo.
mysql>CREATE USER '<user_name>'@'<domain_name>' IDENTIFIED BY '<password>';El usuario requiere los privilegios
REPLICATION CLIENTyREPLICATION SLAVE. Conceda estos privilegios al usuario.GRANT REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO '<user_name>'@'<domain_name>';Si necesita usar la replicación cifrada, exija conexiones SSL al usuario de la replicación. Por ejemplo, puede utilizar la siguiente declaración para exigir el uso de conexiones SSL en la cuenta de usuario
<user_name>GRANT USAGE ON *.* TO '<user_name>'@'<domain_name>' REQUIRE SSL;nota
Si
REQUIRE SSLno se incluye, la conexión de replicación podría cambiarse inadvertidamente por una conexión sin cifrar. -
En la consola de Amazon RDS, agregue la dirección IP del servidor que aloja la base de datos MySQL externa al grupo de seguridad de la VPC para el clúster de base de datos de Aurora MySQL. Para obtener más información acerca de la modificación de un grupo de seguridad de VPC, consulte Grupos de seguridad de su VPC en la Guía del usuario de Amazon Virtual Private Cloud.
Es posible que también necesite configurar su red local para permitir las conexiones desde la dirección IP de su clúster de base de datos de Aurora MySQL con el fin de que se pueda comunicar con la base de datos MySQL externa. Para encontrar la dirección IP del clúster de base de datos de Aurora MySQL, use el comando
host.host<db_cluster_endpoint>El nombre de host es el nombre DNS del punto de enlace del clúster de base de datos de Aurora MySQL.
-
Habilite la replicación de registros binarios ejecutando el procedimiento almacenado mysql.rds_reset_external_master (Aurora MySQL versión 2) o mysql.rds_reset_external_source (Aurora MySQL versión 3). Este procedimiento almacenado tiene la siguiente sintaxis.
CALL mysql.rds_set_external_master ( host_name , host_port , replication_user_name , replication_user_password , mysql_binary_log_file_name , mysql_binary_log_file_location , ssl_encryption ); CALL mysql.rds_set_external_source ( host_name , host_port , replication_user_name , replication_user_password , mysql_binary_log_file_name , mysql_binary_log_file_location , ssl_encryption );Para obtener más información acerca de los parámetros, consulte mysql.rds_reset_external_master (Aurora MySQL versión 2) y mysql.rds_reset_external_source (Aurora MySQL versión 3).
Para
mysql_binary_log_file_nameymysql_binary_log_file_location, use la posición del evento Recovered from Binary log filename (Recuperado del nombre de archivo de log binario) que anotó antes.Si los datos del clúster de base de datos de Aurora MySQL no están cifrados, el parámetro
ssl_encryptiondebe establecerse en0. Si los datos están cifrados, el parámetrossl_encryptiondebe establecerse en1.El siguiente ejemplo ejecuta el procedimiento para un clúster de base de datos de Aurora MySQL que tiene datos cifrados.
CALL mysql.rds_set_external_master( 'Externaldb.some.com', 3306, 'repl_user'@'mydomain.com', 'password', 'mysql-bin.000010', 120, 1); CALL mysql.rds_set_external_source( 'Externaldb.some.com', 3306, 'repl_user'@'mydomain.com', 'password', 'mysql-bin.000010', 120, 1);Este procedimiento almacenado establece los parámetros que el clúster de base de datos de Aurora MySQL usa para conectarse a una base de datos MySQL externa y leer su log binario. Si los datos están cifrados, también descarga el certificado de la entidad de certificación de SSL, el certificado cliente y la clave cliente en el disco local.
-
Inicie la replicación de logs binarios ejecutando el procedimiento almacenado mysql.rds_start_replication.
CALL mysql.rds_start_replication; -
Monitorice qué retardo tiene el clúster de base de datos de Aurora MySQL con respecto a la base de datos principal de replicación de MySQL. Para ello, conéctese al clúster de base de datos de Aurora MySQL y ejecute el siguiente comando.
Aurora MySQL version 2: SHOW SLAVE STATUS; Aurora MySQL version 3: SHOW REPLICA STATUS;En la salida del comando, el campo
Seconds Behind Mastermuestra cuánto retardo tiene el clúster de base de datos de Aurora MySQL con respecto al MySQL principal. Cuando este valor es0(cero), el clúster de base de datos de Aurora MySQL se ha sincronizado con el principal y puede continuar con el siguiente paso para detener la replicación. -
Conéctese a la base de datos principal de replicación MySQL y detenga la replicación. Para ello, ejecute el procedimiento almacenado mysql.rds_stop_replication.
CALL mysql.rds_stop_replication;
