Uso de una base de datos global de Amazon Aurora
Con la característica de base de datos global de Amazon Aurora, puede configurar varios clústeres de bases de datos Aurora que abarquen varias Regiones de AWS. Aurora sincroniza automáticamente todos los cambios realizados en el clúster de base de datos principal con uno o más clústeres secundarios. Una base de datos global de Aurora tiene un clúster de base de datos principal en una región y hasta 10 clústeres de base de datos secundarios en diferentes regiones. Esta configuración multirregional proporciona una recuperación rápida de cualquier interrupción que pueda afectar a toda una Región de AWS. Tener una copia completa de todos los datos en varias ubicaciones geográficas también permite operaciones de lectura de baja latencia para las aplicaciones que se conectan desde ubicaciones muy distantes de todo el mundo.
Temas
Información general sobre la base de datos global de Amazon Aurora
Uso del reenvío de escritura en una base de datos Amazon Aurora global
Uso de la transición o la conmutación por error en la base de datos global de Amazon Aurora
Uso de las bases de datos globales de Amazon Aurora con otros servicios de AWS
Información general sobre la base de datos global de Amazon Aurora
Por medio de la característica de base de datos global de Amazon Aurora, puede ejecutar sus aplicaciones distribuidas globalmente a través de una única base de datos de Aurora que abarca múltiples Regiones de AWS.
Una base de datos global de Aurora consta de una Región de AWS principal donde se escriben los datos, y hasta 10 Regiones de AWS secundarias de solo lectura. Emita operaciones de escritura en el clúster de base de datos principal en la Región de AWS principal. La forma más cómoda de hacerlo es conectarse al punto de conexión del escritor de la base de datos global Aurora, que siempre apunta al clúster de base de datos principal, incluso después de una transición o una conmutación por error a otra Región de AWS. Después de cualquier operación de escritura, Aurora replica los datos en las Regiones de AWS secundarias mediante una infraestructura dedicada, con una latencia normalmente inferior a un segundo.
En el siguiente diagrama, puede encontrar un ejemplo de base de datos global de Aurora que abarca dos Regiones de AWS.
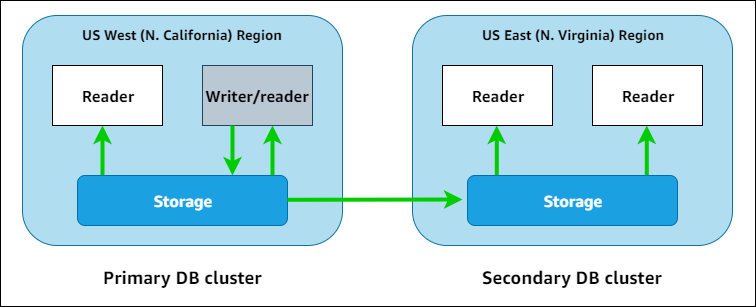
Puede escalar verticalmente el clúster secundario independientemente agregando una o varias Aurora instancias del lector de Aurora para servir a cargas de trabajo de solo lectura. Puede utilizar Aurora Serverless v2 para las instancias del lector para lograr un escalado aún más granular y flexible.
Solo el clúster primario realiza operaciones de escritura. Los clientes que realizan operaciones de escritura se conectan al punto de conexión del escritor de la base de datos global de Aurora, que siempre apunta a la instancia de base de datos del clúster primario. Como se muestra en el diagrama, Aurora utiliza el volumen de almacenamiento de clúster y no el motor de base de datos para una replicación rápida y de baja sobrecarga. Para obtener más información, consulte Información general del almacenamiento de Amazon Aurora.
La base de datos global de Aurora está diseñada para aplicaciones con una huella mundial. Los clústeres de base de datos secundarios de solo lectura en varias Regiones de AWS ayudan a optimizar las operaciones de lectura más cercanas a los usuarios de la aplicación. Con la característica del reenvío de escritura, también puede configurar su base de datos global para que los clústeres secundarios envíen solicitudes de escritura al principal. Para obtener más información, consulte Uso del reenvío de escritura en una base de datos Amazon Aurora global.
La base de datos global de Aurora admite dos operaciones diferentes para cambiar la región del clúster de base de datos principal, según el caso: transición de base de datos global de Aurora y conmutación por error de base de datos global.
-
En el caso de procedimientos operativos planificados, como la rotación regional, utilice el mecanismo de transición (antes denominad “conmutación por error planificada administrada”). Con esta característica, puede reubicar el clúster principal de una base de datos global de Aurora en buen estado a una de sus regiones secundarias sin necesidad de perder datos. Para obtener más información, consulte Ejecución de transiciones para bases de datos globales de Amazon Aurora.
-
Para recuperar la base de datos global de Aurora después de una interrupción en la región principal, utilice el mecanismo de conmutación por error. Con esta característica, realiza una conmutación por error del clúster de base de datos principal a otra región (conmutación por error entre regiones). Para obtener más información, consulte Ejecución de la conmutación por error administrada para bases de datos globales de Aurora.
Ventajas de la base de datos global de Amazon Aurora
Mediante el uso de la base de datos global de Aurora, puede obtener las siguientes ventajas:
Lecturas globales con latencia local: si tiene oficinas en todo el mundo, puede utilizar la base de datos global de Aurora para mantener actualizadas sus principales orígenes de información en la Región de AWS principal. Las oficinas en sus otras regiones pueden acceder a la información en su propia región, con latencia local.
Clústeres de base de datos de Aurora secundarios y escalables: puede escalar los clústeres secundarios; para ello, agregue más instancias de solo lectura a una Región de AWS secundaria. El clúster secundario es de solo lectura, por lo que puede admitir hasta 16 instancias de base de datos de Aurora de solo lectura en lugar del límite habitual de 15 para un solo clúster de Aurora.
Replicación rápida de clústeres de base de datos de Aurora primarios a secundarios: la replicación realizada por una base de datos global de Aurora tiene poco impacto en el rendimiento del clúster de base de datos principal. Los recursos de las instancias de bases de datos están totalmente dedicados a servir a las cargas de trabajo de lectura y escritura de la aplicación.
Recuperación de interrupciones en toda la región: los clústeres secundarios le permiten hacer que una base de datos global de Aurora esté disponible en una Región de AWS principal nueva más rápido (RTO más bajo) y con menos pérdida de datos (RPO más bajo) que las soluciones de replicación tradicionales.
Disponibilidad en regiones y versiones
La disponibilidad y el soporte de la característica varía según las versiones específicas de cada motor de base de datos de Aurora y entre Regiones de AWS. Para obtener más información acerca de la versión y la disponibilidad de las regiones con la base de datos global de Aurora, consulte Regiones y motores de base de datos admitidos para bases de datos globales Aurora.
Limitaciones de la base de datos global de Amazon Aurora
Las limitaciones siguientes se aplican actualmente a la base de datos global de Aurora:
La base de datos global de Aurora está disponibles en ciertas Regiones de AWS y para versiones específicas de Aurora MySQL y Aurora PostgreSQL. Para obtener más información, consulte Regiones y motores de base de datos admitidos para bases de datos globales Aurora.
La base de datos global de Aurora tienen requisitos de configuración concretos para las clases de instancias de base de datos compatibles de Aurora, la cantidad máxima de Regiones de AWS, etc. Para obtener más información, consulte Requisitos de configuración de una base de datos Amazon Aurora global.
Para la compatibilidad de Aurora MySQL con MySQL 5.7, las transiciones de base de datos global de Aurora requieren la versión 2.09.1 o una superior.
-
Solo puede realizar transiciones o conmutaciones por error administradas entre regiones en la base de datos global de Aurora si los clústeres de base de datos principal y secundario tienen las mismas versiones principal, secundaria y de nivel de parche del motor. Según el motor y las versiones del motor, es posible que los niveles de parche deban ser idénticos o diferentes. Para obtener una lista de los motores y las versiones de motores que permiten estas operaciones entre clústeres principales y secundarios con diferentes niveles de parches, consulte Compatibilidad de los niveles de parche para la transición o conmutación por error administrada entre regiones. Si las versiones del motor requieren niveles de parches idénticos, puede realizar la conmutación por error manualmente por medio de los pasos que se indican en Ejecución de la conmutación por error manual para bases de datos globales de Aurora.
La base de datos global de Aurora actualmente no admite las siguientes características de Aurora:
-
Aurora Serverless v1
-
Búsqueda de datos anteriores en Aurora.
-
Para conocer las limitaciones del uso de la característica RDS Proxy con la base de datos global, consulte Limitaciones de RDS Proxy con bases de datos globales.
La actualización automática de versiones secundarias no se aplica a clústeres de Aurora MySQL y Aurora PostgreSQL que formen parte de una base de datos global. Tenga en cuenta que puede especificar esta configuración para una instancia de base de datos que forme parte de un clúster de base de datos global, pero la configuración no tendrá ningún efecto.
La base de datos global de Aurora actualmente no admite Aurora Auto Scaling para clústeres de bases de datos secundarios.
Para utilizar las secuencias de actividades de base de datos (DAS) en la base de datos global de Aurora que ejecuta Aurora MySQL 5.7, la versión del motor debe ser la 2.08 o superior. Para obtener más información sobre DAS, consulte Supervisión de Amazon Aurora con flujos de actividad de la base de datos.
-
Las limitaciones siguientes se aplican actualmente a la actualización de la base de datos global de Aurora:
No puede aplicar un grupo de parámetros personalizado al clúster de base de datos global mientras realiza una actualización importante de la versión de esa base de datos global de Aurora. Se crean grupos de parámetros personalizados en cada región del clúster global y se aplican manualmente a los clústeres regionales después de la actualización.
-
Con una base de datos global de Aurora basada en Aurora MySQL, no se puede realizar una actualización local desde la versión 2 a la versión 3 de Aurora MySQL si el parámetro
lower_case_table_namesestá activado. Para obtener más información sobre los métodos que puede utilizar, consulte Actualizaciones de la versión principal. Con la base de datos global de Aurora, no se puede realizar una actualización de versión importante del motor de base de datos de Aurora PostgreSQL si la característica Objetivo de punto de recuperación (RPO) está habilitada. Para obtener información sobre la característica RPO, consulte Administración de RPO para bases de datos globales basadas en Aurora PostgreSQL–.
Con una base de datos global de Aurora, no se puede realizar una actualización de versión secundaria de la versión de Aurora MySQL 3.01 o 3.02 a la versión 3.03 o una posterior mediante el proceso estándar. Para obtener más información sobre el proceso que se debe usar, consulte Actualización de Aurora MySQL mediante la modificación de la versión del motor.
Para obtener información sobre cómo actualizar la base de datos global de Aurora, consulte Actualización de una base de datos global de Amazon Aurora.
No puede detener ni iniciar por separado los clústeres de base de datos de Aurora en su base de datos global. Para obtener más información, consulte Detención e inicio de un clúster de bases de datos de Amazon Aurora.
Las instancias de base de datos del lector de Aurora conectadas al clúster de base de datos de Aurora secundario pueden reiniciarse en determinadas circunstancias. Si la instancia de base de datos del escritor de la Región de AWS principal se reinicia o se conmuta por error, las instancias de base de datos del lector también se reinician en las regiones secundarias. El clúster secundario no estará disponible hasta que todas las instancias de base de datos del lector vuelvan a estar sincronizadas con la instancia del escritor del clúster de base de datos principal. El comportamiento del clúster principal cuando se reinicia o se produce una conmutación por error es el mismo que en un clúster de base de datos único y no global. Para obtener más información, consulte Replicación con Amazon Aurora.
Asegúrese de comprender los impactos en la base de datos global de antes de realizar cambios en el clúster de base de datos principal. Para obtener más información, consulte Recuperación de una base de datos global Amazon Aurora de una interrupción no planificada.
Actualmente, la base de datos global de Aurora no admite el estado
inaccessible-encryption-credentials-recoverableen el que Amazon Aurora pierde el acceso a la clave AWS KMS del clúster de base de datos. En estos casos, el clúster de base de datos cifrado entra en el estadoinaccessible-encryption-credentialsde terminal. Para obtener más información sobre estos estados, consulte Ver el estado del clúster de base de datos.-
Secrets Manager no admite Aurora Global Database. Al agregar una región a una base de datos global, primero debe desactivar la integración de Secrets Manager para la instancia de base de datos.
-
Los clústeres de base de datos basados en Aurora PostgreSQL que se ejecutan en la base de datos global de Aurora tienen las siguientes limitaciones:
La administración de caché de clúster no es compatible con los clústeres de base de datos secundarios de Aurora PostgreSQL que forman parte de bases de datos globales de Aurora.
-
Si el clúster de base de datos principal de la base de datos global se basa en una réplica de una instancia de Amazon RDS PostgreSQL, no puede crear un clúster secundario. No intente crear un secundario a partir de ese clúster mediante AWS Management Console, la AWS CLI, o la operación
CreateDBClusterAPI. Los intentos para hacerlo se agotan y no se crea el clúster secundario.
Se recomienda crear clústeres de base de datos secundarios para las bases de datos globales utilizando la misma versión del motor de base de datos de Aurora que el primario. Para obtener más información, consulte Creación de una base de datos global de Amazon Aurora.
