Uso de la transición o la conmutación por error en la base de datos global de Amazon Aurora
La característica de base de datos global de Aurora proporciona más protección de continuidad empresarial y recuperación ante desastres (BCDR) que la alta disponibilidad estándar proporcionada por un clúster de bases de datos de Aurora en una sola Región de AWS. Al utilizar una base de datos global de Aurora, puede planificar y recuperarse más rápido de desastres regionales o interrupciones totales del nivel de servicio inusuales y no previstos.
Puede consultar las siguientes directrices y procedimientos para planificar, probar e implementar su estrategia de BCDR mediante la característica de base de datos global de Aurora.
Temas
Planificación de la continuidad empresarial y la recuperación ante desastres
Ejecución de transiciones para bases de datos globales de Amazon Aurora
Recuperación de una base de datos global Amazon Aurora de una interrupción no planificada
Administración de RPO para bases de datos globales basadas en Aurora PostgreSQL–
Resiliencia entre regiones para clústeres secundarios de una base de datos global
Planificación de la continuidad empresarial y la recuperación ante desastres
Para planificar su estrategia de continuidad empresarial y recuperación ante desastres, resulta útil comprender la siguiente terminología del sector y su relación con las características de la base de datos global de Aurora.
La recuperación de desastres suele obedecer a los dos objetivos empresariales siguientes:
-
Objetivo de tiempo de recuperación (RTO): el tiempo que tarda un sistema en volver a un estado operativo después de un desastre o interrupción del servicio. En otras palabras, el RTO mide el tiempo de inactividad. Para la base de datos global de Aurora, el RTO puede ser del orden de minutos.
-
Objetivo de punto de recuperación (RPO): la cantidad de datos que se pueden perder (medidos en el tiempo) después de un desastre o interrupción del servicio. Esta pérdida de datos suele deberse a un retraso en la replicación asíncrona. Para una base de datos global de Aurora, el RPO se mide normalmente en segundos. Con una base de datos global basada en Aurora PostgreSQL–, puede utilizar el parámetro
rds.global_db_rpopara establecer y realizar un seguimiento del límite superior de RPO, pero hacerlo podría afectar al procesamiento de transacciones en el nodo escritor del clúster principal. Para obtener más información, consulte Administración de RPO para bases de datos globales basadas en Aurora PostgreSQL–.
Realizar una transición o una conmutación por error con la base de datos global de Aurora implica promocionar un clúster de base de datos secundario al clúster de base de datos principal. El término “interrupción regional” se utiliza a menudo para describir una variedad de situaciones de error. El peor de los casos podría ser una interrupción generalizada provocada por un evento catastrófico que afecte a cientos de kilómetros cuadrados. Sin embargo, la mayoría de las interrupciones están mucho más localizadas y afectan solo a un pequeño subconjunto de los servicios en la nube o los sistemas de los clientes. Tenga en cuenta el alcance total de la interrupción para asegurarse de que la conmutación por error entre regiones sea la solución apropiada y elegir el método de conmutación por error adecuado para la situación. La decisión de utilizar el enfoque de transición o conmutación por error depende de la situación de interrupción concreta:
-
Conmutación por error: utilice este enfoque para recuperarse de una interrupción imprevista. Con este enfoque, realiza una conmutación por error entre regiones a uno de los clústeres de bases de datos secundario de su base de datos global de Aurora. El RPO de este enfoque suele ser un valor distinto de cero medido en segundos. La cantidad de pérdida de datos depende del retraso en la replicación de la base de datos global Aurora en las Regiones de AWS en el momento del error. Para obtener más información, consulte Recuperación de una base de datos global Amazon Aurora de una interrupción no planificada.
-
Transición: esta operación se denominaba anteriormente “conmutación por error planificada administrada”. Utilice este enfoque para situaciones controladas, como el mantenimiento operativo y otros procedimientos operativos planificados en los que todos los clústeres de Aurora y otros servicios con los que interactúan se encuentren en buen estado. Dado que esta característica sincroniza los clústeres secundarios de base de datos con el principal antes de realizar cualquier otro cambio, el RPO es 0 (sin pérdida de datos). Para obtener más información, consulte Ejecución de transiciones para bases de datos globales de Amazon Aurora.
nota
Antes de realizar una transición o conmutación por error en un clúster de base de datos de Aurora secundario sin periféricos, debe agregarle una instancia de base de datos. Para obtener más información acerca de los clústeres de base de datos sin pantalla, consulte Creación de un clúster de base de datos de Aurora sin pantalla en una región secundaria.
Ejecución de transiciones para bases de datos globales de Amazon Aurora
nota
Antes, las transiciones se denominaban conmutaciones por error planificadas administradas.
Al utilizar las transiciones, puede cambiar la región del clúster principal de forma rutinaria. Este enfoque está destinado a situaciones controladas, como el mantenimiento operativo y otros procedimientos operativos planificados.
Existen tres casos de uso frecuentes en los que se utilizan las transiciones.
-
Para los requisitos de “rotación regional” impuestos a sectores específicos. Por ejemplo, es posible que los reglamentos de los servicios financieros exijan que los sistemas de nivel 0 se cambien a una región diferente durante varios meses para garantizar que los procedimientos de recuperación de desastres se ensayen con cierta asiduidad.
-
Para aplicaciones multirregionales del tipo “seguir el sol”. Por ejemplo, es posible que una empresa desee ofrecer escrituras con menor latencia en diferentes regiones en función del horario laboral en distintas zonas horarias.
-
Como método sin pérdida de datos para conmutar por recuperación a la región principal original tras una conmutación por error.
nota
Las transiciones están diseñadas para usarse en una base de datos global de Aurora en la que todos los clústeres de Aurora y otros servicios con los que interactúan se encuentran en buen estado. Para la recuperación de una interrupción no programada, siga el procedimiento correspondiente en Recuperación de una base de datos global Amazon Aurora de una interrupción no planificada.
Solo puede realizar transiciones entre regiones en la base de datos global de Aurora si los clústeres de base de datos principal y secundario tienen las mismas versiones principal, secundaria y de nivel de parche del motor. Según el motor y las versiones del motor, es posible que los niveles de parche deban ser idénticos o diferentes. Para obtener una lista de los motores y las versiones de motores que permiten estas operaciones entre clústeres principales y secundarios con diferentes niveles de parches, consulte Compatibilidad de los niveles de parche para la transición o conmutación por error administrada entre regiones. Antes de iniciar la transición, compruebe las versiones del motor de su clúster global para asegurarse de que admiten la transición entre regiones administrada y actualícelas, si es necesario.
Durante una transición, Aurora convierte el clúster de la región secundaria elegida en el clúster principal. El mecanismo de transición mantiene la topología de replicación existente de la base de datos global: sigue teniendo el mismo número de clústeres de Aurora en las mismas regiones. Antes de que Aurora inicie el proceso de transición, espera a que los clústeres de la región secundaria de destino estén completamente sincronizados con el clúster de la región principal. El clúster de base de datos en la región principal se convierte en solo de lectura. El clúster secundario elegido promociona uno de sus nodos de solo de lectura al estado de escritor completo, lo que permite que el clúster secundario asuma el rol de clúster principal. Dado que el clúster secundario de destino se sincronizó con el principal al principio del proceso, el nuevo principal continúa las operaciones para la base de datos global de Aurora sin perder ningún dato. La base de datos no estará disponible durante un breve periodo, mientras los clústeres principales y secundarios seleccionados asumen nuevas funciones.
nota
Para administrar las ranuras de replicación para Aurora PostgreSQL después de realizar una transición, consulte Administración de ranuras lógicas para Aurora PostgreSQL .
Para optimizar la disponibilidad de las aplicaciones, se recomienda hacer lo siguiente antes de utilizar esta característica:
-
Realice esta operación durante los horarios menos concurridos o en otro momento cuando las escrituras en el clúster de base de datos principal sean mínimas.
-
Compruebe los tiempos de retraso para todos los clústeres secundarios de base de datos Aurora de la base de datos global de Aurora. Para todas las bases de datos globales basadas en Aurora PostgreSQL y para las bases de datos globales basadas en Aurora MySQL a partir de las versiones de motor 3.04.0 y posteriores, o 2.12.0 y posteriores, utilice Amazon CloudWatch para ver la métrica
AuroraGlobalDBRPOLagde todos los clústeres de bases de datos secundarios. Para ver las versiones secundarias anteriores de las bases de datos globales basadas en Aurora MySQL, consulte, en cambio, la métricaAuroraGlobalDBReplicationLag. Estas métricas muestran el retraso (en milisegundos) de la replicación a un clúster secundario con respecto al clúster principal de base de datos. Este valor es directamente proporcional al tiempo que tarda Aurora en completar la transición. Por lo tanto, cuanto mayor sea el valor de retraso, más tiempo llevará la transición. Cuando examine estas métricas, hágalo desde el clúster principal actual.Para obtener más información acerca de las métricas de CloudWatch para Aurora, consulte Métricas de nivel de clúster para Amazon Aurora.
-
El clúster de base de datos secundario que se promociona durante una transición puede tener ajustes de configuración diferentes a los del clúster de base de datos principal anterior. Se recomienda mantener la coherencia entre los siguientes tipos de ajustes de configuración en todos los clústeres de los clústeres de la base de datos global de Aurora. Esto ayuda a minimizar los problemas de rendimiento, incompatibilidades de carga de trabajo y otros comportamientos anómalos después de una transición.
-
Configure un grupo de parámetros de clúster de base de datos de Aurora para el nuevo clúster principal, si es necesario: cuando se promociona un clúster secundario de base de datos para que asuma el rol principal, el grupo de parámetros del secundario se puede configurar de manera diferente que el del principal. Si es así, modifique el grupo de parámetros del clúster secundario de base de datos promocionado para que se ajuste a la configuración del clúster principal. Para saber cómo hacerlo, consulte Modificación de parámetros para una base de datos Aurora global.
-
Configurar herramientas y opciones de monitoreo, como Amazon CloudWatch Events y alarmas – Configurar el clúster de base de datos promocionado con la misma capacidad de registro, alarmas, etc. según sea necesario para la base de datos global. Al igual que con los grupos de parámetros, la configuración de estas características no se hereda del clúster principal durante el proceso de transición. Algunas métricas de CloudWatch, como el retraso de la replicación, solo están disponibles para las regiones secundarias. Por lo tanto, una transición cambia la forma de ver esas métricas y configurar las alarmas en ellas, y podría requerir cambios en los paneles predefinidos. Para obtener más información acerca de los clústeres de base de datos de Aurora y la supervisión, consulte Supervisión de métricas de Amazon Aurora con Amazon CloudWatch.
-
Configurar integraciones con otros servicios de AWS: si la base de datos global de Aurora se integra con servicios de AWS, como AWS Secrets Manager, AWS Identity and Access Management, Amazon S3 y AWS Lambda, asegúrese de configurar sus integraciones con estos servicios según sea necesario. Para obtener más información sobre la integración de bases de datos globales de Aurora con IAM, Amazon S3 y Lambda, consulte Uso de las bases de datos globales de Amazon Aurora con otros servicios de AWS. Para obtener más información sobre Secrets Manager, consulte Cómo automatizar la replicación de secretos en AWS Secrets Manager entre Regiones de AWS
.
-
Si utiliza el punto de conexión del escritor de la base de datos global de Aurora, no es necesario cambiar la configuración de conexión en su aplicación. Compruebe que los cambios de DNS se hayan propagado y que pueda conectarse y realizar operaciones de escritura en el nuevo clúster principal. A continuación, podrá reanudar el funcionamiento completo de la aplicación.
Suponga que las conexiones de su aplicación utilizan el punto de conexión del clúster principal anterior, en lugar del punto de conexión del escritor global. En ese caso, asegúrese de cambiar la configuración de conexión de la aplicación para utilizar el punto de conexión del clúster del nuevo clúster principal. Si aceptó los nombres proporcionados al crear la base de datos global de Aurora, puede cambiar el punto de enlace quitando -ro de la cadena del punto de enlace del clúster promocionado en la aplicación. Por ejemplo, el punto de enlace del clúster secundario my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com se convierte en my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com cuando ese clúster se promueve a principal.
Si utiliza RDS Poxy, asegúrese de redirigir las operaciones de escritura de la aplicación al punto de conexión de lectura o escritura correspondiente del proxy asociado al nuevo clúster principal. Este punto de conexión proxy puede ser el punto de conexión predeterminado o un punto de conexión de lectura o escritura personalizado. Para obtener más información, consulte Cómo funcionan los puntos de conexión de RDS Proxy con las bases de datos globales.
Puede realizar una transición de la base de datos global de Aurora mediante la AWS Management Console, la AWS CLI o la API de RDS.
Para realizar la transición en la base de datos global de Aurora
Inicie sesión en la AWS Management Console y abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. -
Elija Bases de datos y busque la base de datos global de Aurora que tiene intención de someter al proceso de transición.
-
Elija Transición o conmutación por error de base de datos global en el menú Acciones.
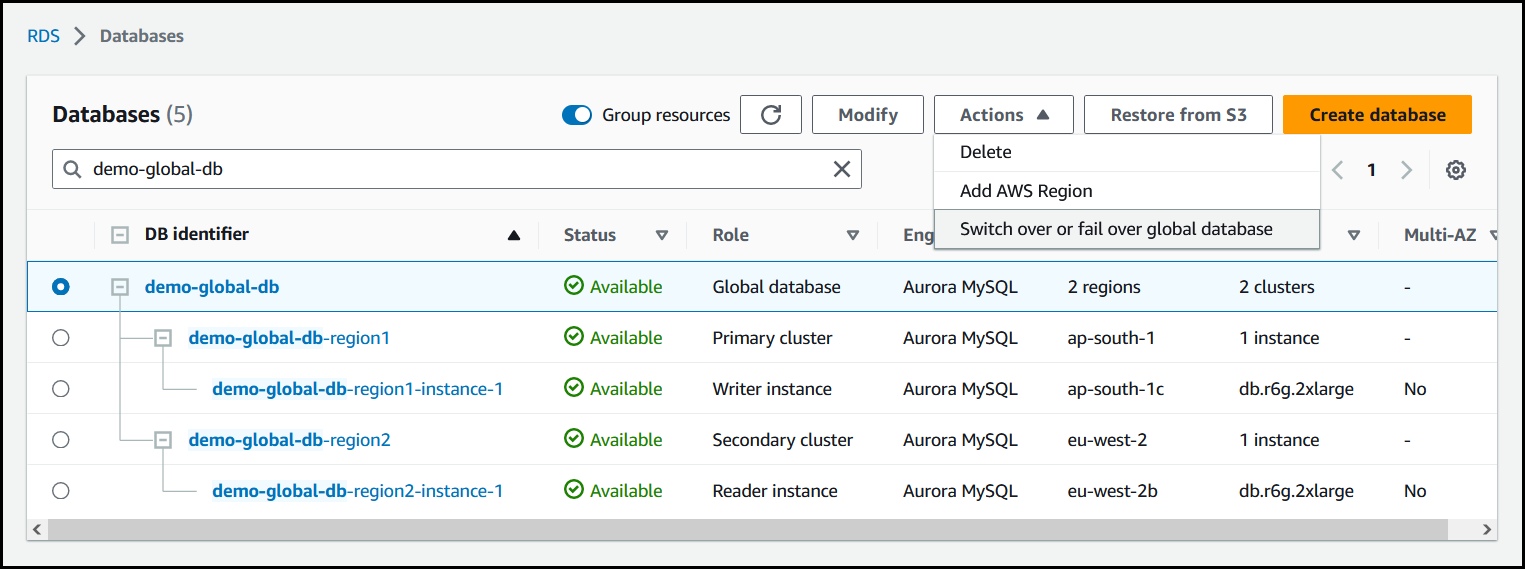
-
Elija Transición.
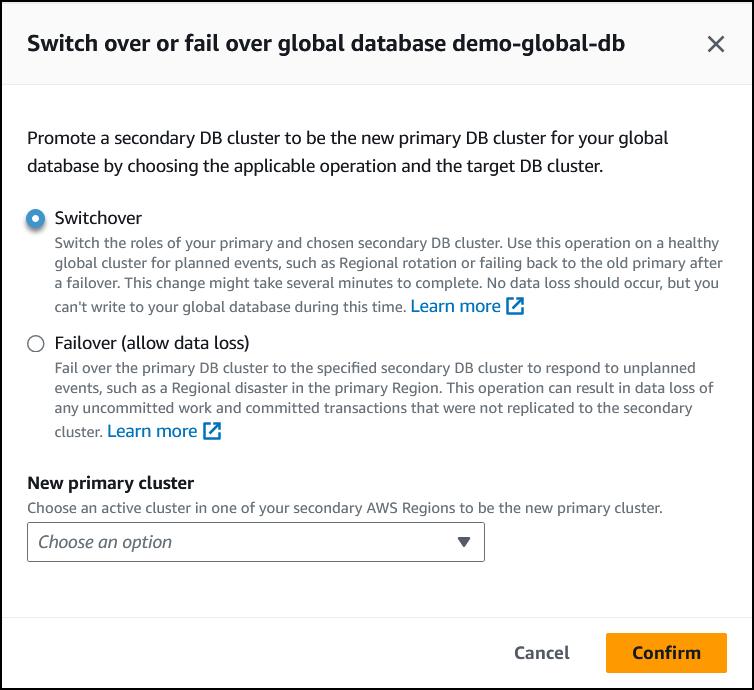
-
Para Nuevo clúster principal, elija un clúster activo en una de sus Regiones de AWS secundarias para que sea el nuevo clúster principal.
-
Elija Confirmar.
Cuando finalice la transición, podrá ver los clústeres de base de datos de Aurora y su estado actual en la lista Bases de datos, como se muestra en la siguiente imagen.
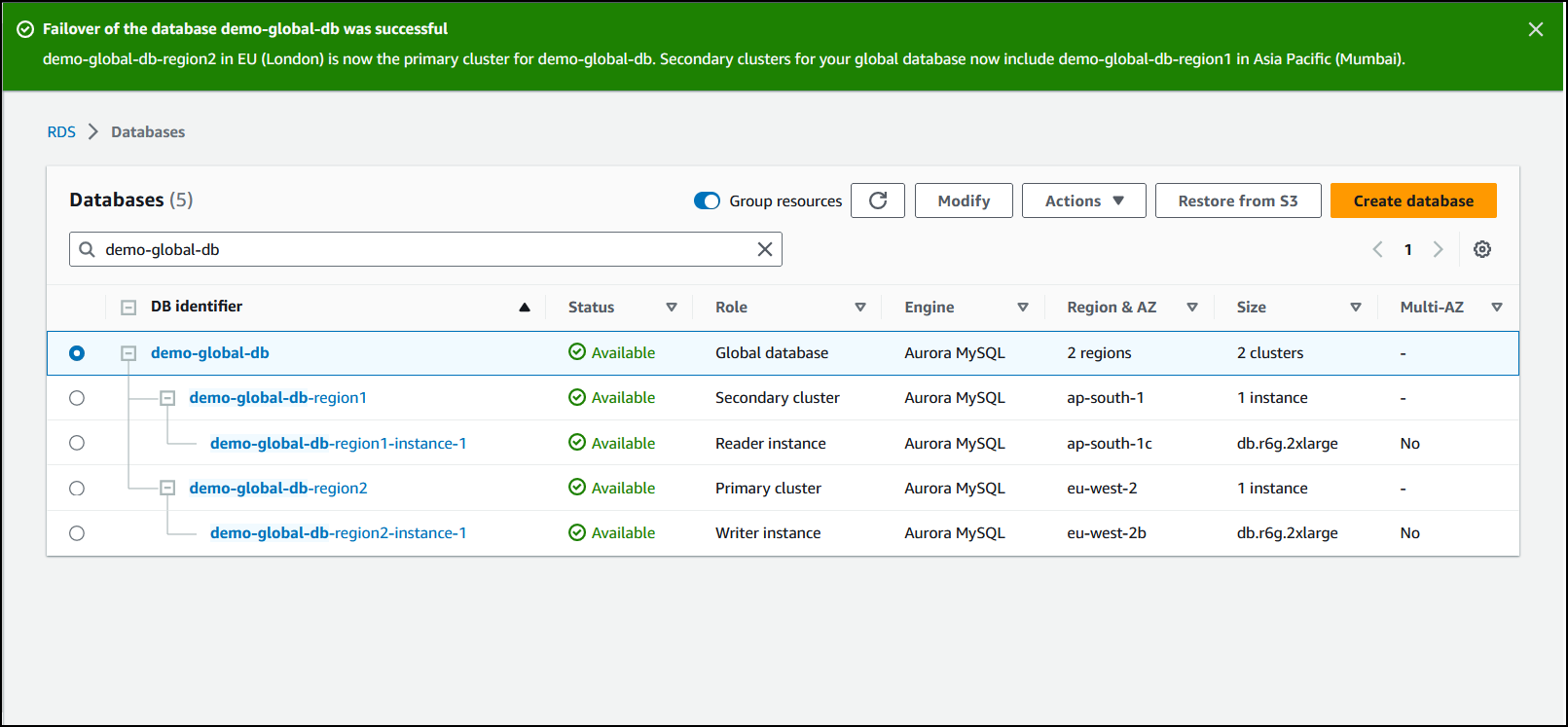
Para realizar la transición en una base de datos global de Aurora
Utilice el comando de la CLI switchover-global-cluster para realizar una transición en la base de datos global de Aurora. Con el comando, pase valores para los siguientes parámetros.
-
--region: especifique la Región de AWS donde se ejecuta el clúster de base de datos principal de la base de datos global de Aurora. -
--global-cluster-identifier– Especifique el nombre de la base de datos global de Aurora. -
--target-db-cluster-identifier– Especifique el nombre de recurso de Amazon (ARN) del clúster de base de datos de Auroraque desea promover para que sea el principal de la base de datos global de Aurora.
Para Linux, macOS o Unix:
aws rds --regionregion_of_primary\ switchover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote
Para Windows:
aws rds --regionregion_of_primary^ switchover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote
Para realizar una transición de la base de datos global de Aurora, ejecute la operación de la API SwitchoverGlobalCluster.
Recuperación de una base de datos global Amazon Aurora de una interrupción no planificada
En raras ocasiones, su base de datos global de Aurora puede experimentar una interrupción inesperada en su Región de AWS principal. Si esto sucede, el clúster principal de base de datos de Aurora y su nodo de escritor no estarán disponibles, y cesará la replicación entre el clúster principal y el secundario. Para minimizar el tiempo de inactividad (RTO) y la pérdida de datos (RPO), puede trabajar rápidamente para realizar una conmutación por error entre regiones.
La base de datos global de Aurora tiene dos métodos de conmutación por error que puede usar en una situación de recuperación ante desastres:
-
Conmutación por error administrada: este método se recomienda para la recuperación de desastres. Si utiliza este método, Aurora vuelve a añadir automáticamente la antigua región principal a la base de datos global como región secundaria cuando vuelve a estar disponible. De este modo, se mantiene la topología original del clúster global. Para obtener información sobre cómo utilizar este método, consulte Ejecución de la conmutación por error administrada para bases de datos globales de Aurora.
-
Conmutación por error manual: este método alternativo se puede utilizar cuando la conmutación por error administrada no es una opción, por ejemplo, cuando las regiones principal y secundaria utilizan versiones de motor incompatibles. Para obtener información sobre cómo utilizar este método, consulte Ejecución de la conmutación por error manual para bases de datos globales de Aurora.
importante
Ambos métodos de conmutación por error pueden provocar la pérdida de datos de transacciones de escritura que no se replicaron en el secundario elegido antes de que se produjera el evento de conmutación por error. Sin embargo, el proceso de recuperación que promueve una instancia de base de datos del clúster de base de datos secundario elegido a instancia de base de datos principal de escritor garantiza que los datos estén en un estado coherente desde el punto de vista de las transacciones. Las conmutaciones por error también son susceptibles de provocar problemas de cerebro dividido.
Ejecución de la conmutación por error administrada para bases de datos globales de Aurora
Este enfoque tiene por objeto garantizar la continuidad empresarial en caso de que se produzca un verdadero desastre regional o una interrupción total del nivel de servicio.
Durante una conmutación por error administrada, el clúster secundario de la región secundaria elegida se convierte en el nuevo clúster principal. El clúster secundario elegido promueve uno de sus nodos de solo de lectura al estado de escritor completo. Este paso permite que el clúster asuma el rol de clúster principal. La base de datos no estará disponible durante un breve periodo, mientras el clúster asume su nuevo rol. Tan pronto como la región principal antigua esté en buen estado y vuelva a estar disponible, Aurora la volverá a agregar automáticamente al clúster global como región secundaria. De este modo, se mantiene la topología de replicación existente de la base de datos global de Aurora.
nota
Para administrar las ranuras de replicación para Aurora PostgreSQL después de realizar una conmutación por error, consulte Administración de ranuras lógicas para Aurora PostgreSQL .
nota
Solo puede realizar conmutaciones por error administradas entre regiones en la base de datos global de Aurora si los clústeres de base de datos principal y secundario tienen las mismas versiones principal, secundaria y de nivel de parche del motor. Según el motor y las versiones del motor, es posible que los niveles de parche deban ser idénticos o diferentes. Para obtener una lista de los motores y las versiones de motores que permiten estas operaciones entre clústeres principales y secundarios con diferentes niveles de parches, consulte Compatibilidad de los niveles de parche para la transición o conmutación por error administrada entre regiones. Antes de iniciar la conmutación por error, compruebe las versiones del motor de su clúster global para asegurarse de que admiten la transición entre regiones administrada y actualícelas, si es necesario. Si las versiones del motor requieren niveles de parches idénticos, pero ejecutan niveles de parche distintos, puede realizar la conmutación por error manualmente por medio de los pasos que se indican en Ejecución de la conmutación por error manual para bases de datos globales de Aurora.
La conmutación por error administrada no espera a que los datos se sincronicen entre la región secundaria elegida y la región principal actual. Como la base de datos global de Aurora replica los datos de forma asíncrona, es posible que no todas las transacciones se repliquen en la región AWS secundaria elegida antes de que se promocione para aceptar todas las capacidades de lectura/escritura.
Para garantizar que los datos estén en un estado uniforme, Aurora crea un nuevo volumen de almacenamiento para la antigua región principal una vez que se recupera. Antes de crear el nuevo volumen de almacenamiento en la región AWS, Aurora intenta tomar una instantánea del volumen de almacenamiento anterior en el punto en que se produjo el error. De esta forma, puede restaurar la instantánea y recuperar cualquiera de los datos que se hayan perdido de esta. Si esta operación se realiza correctamente, Aurora coloca la instantánea con el nombre rds:unplanned-global-failover- en la sección de instantáneas de la AWS Management Console. También puede usar el comando name-of-old-primary-DB-cluster-timestampdescribe-db-cluster-snapshots de la AWS CLI o la operación de la API DescribeDBClusterSnapshots para ver los detalles de la instantánea.
Al iniciar una conmutación por error administrada, Aurora también intenta detener el tráfico de escritura a través de la capa de almacenamiento de Aurora, de alta disponibilidad. A este mecanismo lo denominamos “delimitación de escritura”. Si el proceso se realiza correctamente, Aurora emite un evento de RDS que le notifica que las escrituras se han detenido. En el improbable caso de que se produzcan varios fallos en las zonas de disponibilidad en una región, es posible que el proceso de escritura no se lleve a cabo a tiempo. En ese caso, Aurora emite un evento de RDS que le informa de que se ha agotado el tiempo de espera del proceso para detener las escrituras. Si se puede acceder al clúster principal anterior en la red, Aurora registra estos eventos allí. De lo contrario, Aurora registra los eventos en el nuevo clúster principal. Para obtener más información acerca de estos eventos, consulte Eventos de clúster de bases de datos. Dado que limitar la escritura es el mejor intento, es posible que las escrituras se acepten momentáneamente en la antigua región principal, lo que provocaría problemas de cerebro dividido.
Le recomendamos que realice las siguientes tareas antes de realizar una conmutación por error con la base de datos global de Aurora. Si lo hace, se minimiza la posibilidad de que se produzcan problemas de cerebro dividido o de que se recuperen datos no replicados de la instantánea del clúster principal anterior.
-
Para evitar que se envíen escrituras al clúster principal de la base de datos global de Aurora, desconecte las aplicaciones.
-
Asegúrese de que todas las aplicaciones que se conecten al clúster de base de datos principal utilicen el punto de conexión del escritor global. Este punto de conexión tiene un valor que permanece igual incluso cuando una nueva región se convierte en el clúster principal debido a una transición o una conmutación por error. Aurora implementa medidas de seguridad adicionales para minimizar la posibilidad de pérdida de datos en las operaciones de escritura enviadas a través del punto de conexión global. Para obtener más información acerca de los puntos de conexión del escritor global, consulte Conexión a la base de datos global de Amazon Aurora.
-
Si utiliza el punto de conexión del escritor global y sus capas de aplicaciones o redes almacenan en caché los valores de DNS, reduzca el tiempo de vida (TTL) de la memoria caché de DNS a un valor bajo, por ejemplo, 5 segundos. De esta forma, la aplicación registra rápidamente los cambios de DNS en el punto de conexión del escritor global. Aunque Aurora intenta bloquear las escrituras en la antigua región principal, no se garantiza que la acción tenga éxito. Al reducir la duración de la memoria caché del DNS, se reduce aún más la probabilidad de que se produzcan problemas de cerebro dividido. Como alternativa, puede comprobar el evento de RDS que le informa cuando Aurora observe los cambios de DNS en el punto de conexión del escritor global. De esta forma, puede validar que su aplicación también registró el cambio de DNS antes de reiniciar el tráfico de escritura de la aplicación.
-
Compruebe los tiempos de retraso para todos los clústeres secundarios de base de datos de Aurora de la base de datos global de Aurora. La elección de la región secundaria con el menor retraso de replicación puede minimizar la pérdida de datos con respecto a la región principal que actualmente presenta errores.
Para todas las versiones de bases de datos globales basadas en Aurora PostgreSQL y para las bases de datos globales basadas en Aurora MySQL a partir de las versiones de motor 3.04.0 y posteriores, o 2.12.0 y posteriores, utilice Amazon CloudWatch para ver la métrica
AuroraGlobalDBRPOLagde todos los clústeres de base de datos secundarios. Para ver las versiones secundarias anteriores de las bases de datos globales basadas en Aurora MySQL, consulte, en cambio, la métricaAuroraGlobalDBReplicationLag. Estas métricas muestran el retraso (en milisegundos) de la replicación a un clúster secundario con respecto al clúster principal de base de datos.Para obtener más información acerca de las métricas de CloudWatch para Aurora, consulte Métricas de nivel de clúster para Amazon Aurora.
Durante una conmutación por error administrada, el clúster secundario de base de datos elegido se promueve a su nuevo rol de clúster principal. Sin embargo, no hereda las diversas opciones de configuración del clúster principal de base de datos. Una falta de coincidencia en la configuración puede provocar problemas de rendimiento, incompatibilidades de carga de trabajo y otros comportamientos anómalos. Para evitar estos problemas, recomendamos que se resuelvan las diferencias entre los clústeres de bases de datos globales de Aurora para lo siguiente:
-
Configure grupo de parámetros de clúster de base de datos de Aurora para el nuevo clúster principal, si es necesario: puede configurar los grupos de parámetros de clúster de base de datos de Aurora de forma independiente para cada clúster de Aurora de la base de datos global de Aurora. Por lo tanto, cuando se promueve un clúster secundario de base de datos para que asuma el rol principal, su grupo de parámetros puede configurarse de manera diferente que para el principal. Si es así, modifique el grupo de parámetros del clúster secundario de base de datos promocionado para que se ajuste a la configuración del clúster principal. Para saber cómo hacerlo, consulte Modificación de parámetros para una base de datos Aurora global.
-
Configurar herramientas y opciones de monitoreo, como Amazon CloudWatch Events y alarmas – Configurar el clúster de base de datos promocionado con la misma capacidad de registro, alarmas, etc. según sea necesario para la base de datos global. Al igual que con los grupos de parámetros, la configuración de estas características no se hereda del clúster principal durante el proceso de conmutación por error. Algunas métricas de CloudWatch, como el retraso de la replicación, solo están disponibles para las regiones secundarias. Por lo tanto, una conmutación por error cambia la forma de ver esas métricas y configurar las alarmas en ellas, y podría requerir cambios en los paneles predefinidos. Para obtener más información acerca de la supervisión de clústeres de base de datos de Aurora, consulte Supervisión de métricas de Amazon Aurora con Amazon CloudWatch.
-
Configure integraciones con otros servicios de AWS: si la base de datos global de Aurora se integra con otros servicios de AWS, como AWS Secrets Manager, AWS Identity and Access Management, Amazon S3 y AWS Lambda, debe asegurarse de que están configurados según sea necesario para que se pueda acceder desde cualquier región secundaria. Para obtener más información sobre la integración de bases de datos globales de Aurora con IAM, Amazon S3 y Lambda, consulte Uso de las bases de datos globales de Amazon Aurora con otros servicios de AWS. Para obtener más información sobre Secrets Manager, consulte Cómo automatizar la replicación de secretos en AWS Secrets Manager entre Regiones de AWS
.
Por lo general, el clúster secundario elegido asume el rol principal en cuestión de minutos. En cuanto la instancia de base de datos del escritor de la nueva región principal esté disponible, podrá conectar sus aplicaciones a ella y reanudar sus cargas de trabajo. Una vez que Aurora promueve el nuevo clúster principal, reconstruye automáticamente todos los clústeres regionales secundarios adicionales.
Como las bases de datos globales de Aurora utilizan la replicación asíncrona, el retraso de la replicación en cada región secundaria puede variar. Aurora reconstruye estas regiones secundarias para que tengan exactamente los mismos datos de un momento dado que el nuevo clúster de región principal. La duración de la tarea de reconstrucción completa puede tardar entre unos minutos y varias horas, según el tamaño del volumen de almacenamiento y la distancia entre las regiones. Cuando los clústeres de la región secundaria terminen de reconstruirse a partir de la nueva región principal, estarán disponibles para el acceso de lectura.
Tan pronto como se promocione y esté disponible el nuevo escritor principal, el clúster de la nueva región principal podrá gestionar las operaciones de lectura y escritura de la base de datos global de Aurora.
Si utiliza el punto de conexión global, no es necesario cambiar la configuración de conexión en su aplicación. Compruebe que los cambios de DNS se hayan propagado y que pueda conectarse y realizar operaciones de escritura en el nuevo clúster principal. A continuación, podrá reanudar el funcionamiento completo de la aplicación.
Si no utiliza el punto de conexión global, asegúrese de cambiar el punto de conexión de la aplicación para que utilice el punto de conexión del clúster para el clúster de base de datos principal recién promocionado. Si aceptó los nombres proporcionados al crear la base de datos global de Aurora, puede cambiar el punto de enlace quitando -ro de la cadena del punto de enlace del clúster promocionado en la aplicación.
Por ejemplo, el punto de enlace del clúster secundario my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.com se convierte en my-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.com cuando ese clúster se promueve a principal.
Si utiliza RDS Poxy, asegúrese de redirigir las operaciones de escritura de la aplicación al punto de conexión de lectura o escritura correspondiente del proxy asociado al nuevo clúster principal. Este punto de conexión proxy puede ser el punto de conexión predeterminado o un punto de conexión de lectura o escritura personalizado. Para obtener más información, consulte Cómo funcionan los puntos de conexión de RDS Proxy con las bases de datos globales.
Para restaurar la topología original del clúster de base de datos global, Aurora monitoriza la disponibilidad de la antigua región principal. Tan pronto como la región esté en buen estado y vuelva a estar disponible, Aurora la volverá a agregarla automáticamente al clúster global como región secundaria. Antes de crear el nuevo volumen de almacenamiento en la antigua región principal, Aurora intenta tomar una instantánea del volumen de almacenamiento anterior en el punto en que se produjo el error. Lo hace para que pueda usarla para recuperar cualquiera de los datos perdidos. Si esta operación se realiza correctamente, Aurora crea una instantánea con el nombre rds:unplanned-global-failover-. Puede encontrar esta instantánea en la sección Instantáneas de la AWS Management Console. También puede ver esta instantánea en la información devuelta por la operación de la API DescribeDBClusterSnapshots. name-of-old-primary-DB-cluster-timestamp
nota
La instantánea del volumen de almacenamiento anterior es una instantánea del sistema que está sujeta al período de retención de la copia de seguridad configurado en el clúster principal anterior. Para conservar esta instantánea más allá del período de retención, puede copiarla para guardarla como una instantánea manual. Para obtener más información sobre la copia de instantáneas, incluido el precio, consulte Copia de una instantánea de clúster de base de datos.
Una vez restaurada la topología original, puede conmutar por recuperación la base de datos global a la región principal original realizando una operación de transición cuando sea más conveniente para su empresa y su carga de trabajo. Para ello, siga los pasos que se indican en Ejecución de transiciones para bases de datos globales de Amazon Aurora.
Puede realizar una conmutación por error con la base de datos global de Aurora mediante la AWS Management Console, la AWS CLI o la API de RDS.
Para realizar la conmutación por error administrada en la base de datos global de Aurora
Inicie sesión en la AWS Management Console y abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. -
Seleccione Bases de datos y busque la base de datos global de Aurora en la que desea llevar a cabo la conmutación por error.
-
Elija Transición o conmutación por error de base de datos global en el menú Acciones.
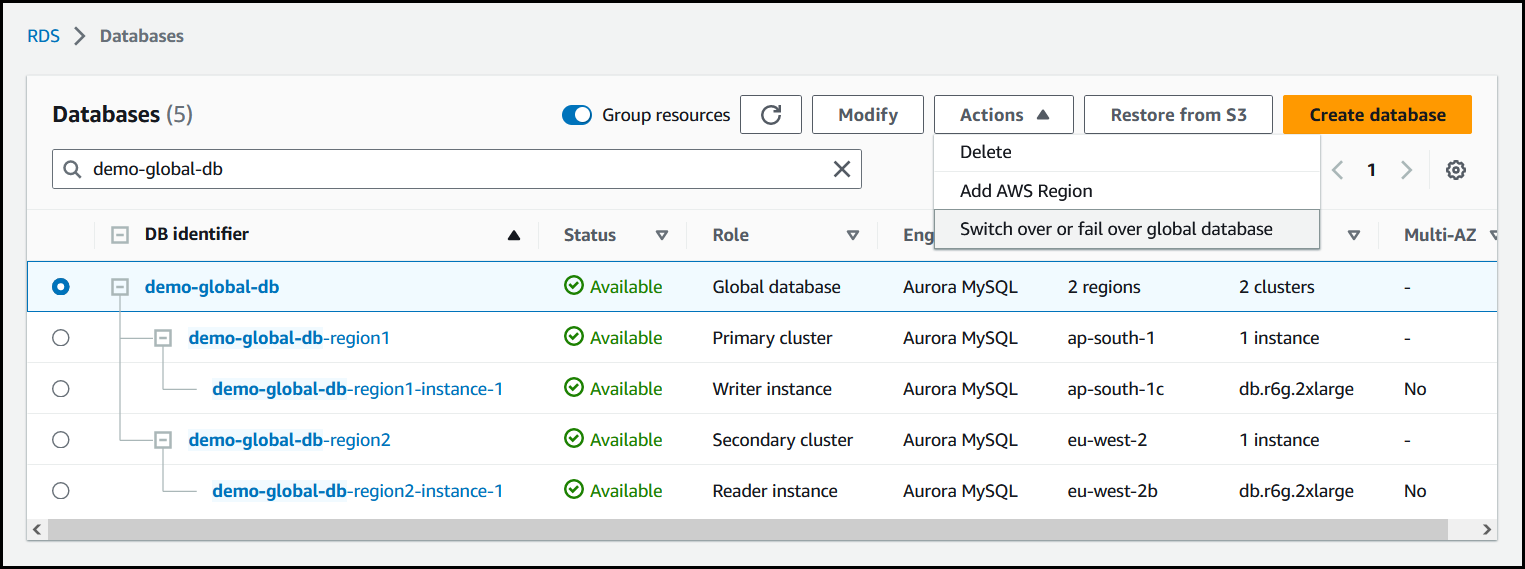
-
Elija Conmutación por error (permitir la pérdida de datos).
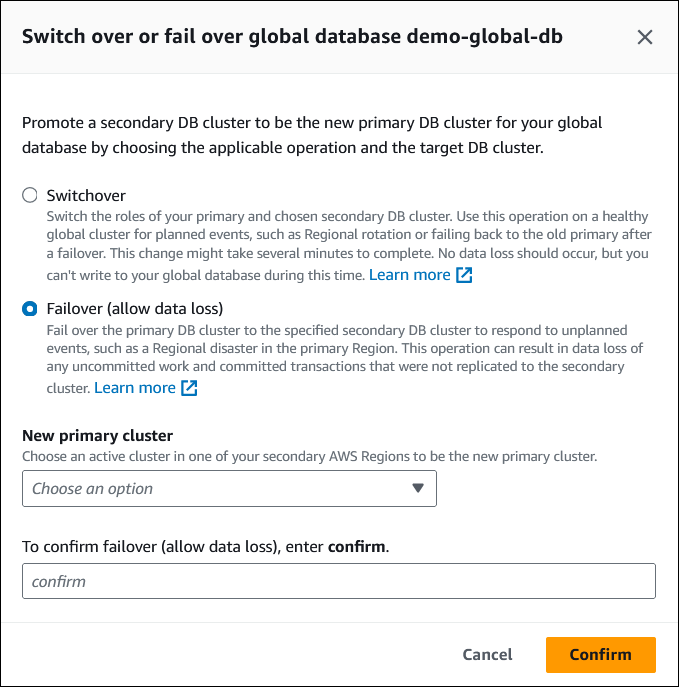
-
Para Nuevo clúster principal, elija un clúster activo en una de sus Regiones de AWS secundarias para que sea el nuevo clúster principal.
-
Introduzca
confirmy, a continuación, elija Confirmar.
Cuando finalice la conmutación por error, podrá ver los clústeres de base de datos de Aurora y su estado actual en la lista Bases de datos, como se muestra en la siguiente imagen.
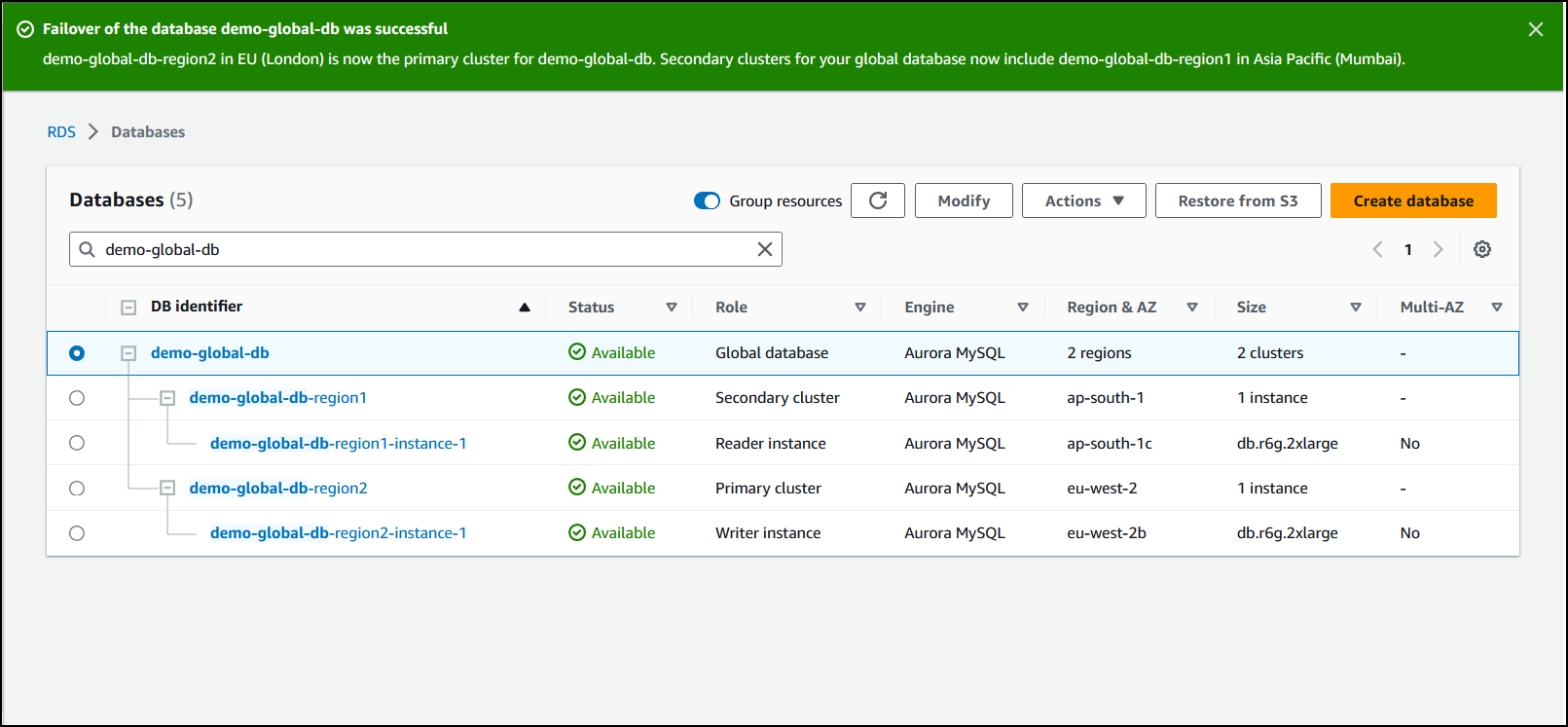
Para realizar la conmutación por error administrada en una base de datos global de Aurora
Utilice el comando de la CLI failover-global-cluster para realizar una conmutación por error con la base de datos global de Aurora. Con el comando, pase valores para los siguientes parámetros.
-
--region: especifique la Región de AWS donde se ejecuta el clúster secundario de la base de datos que desea que sea el nuevo clúster principal de la base de datos global de Aurora. -
--global-cluster-identifier– Especifique el nombre de la base de datos global de Aurora. -
--target-db-cluster-identifier: especifique el nombre de recurso de Amazon (ARN) del clúster de la base de datos de Aurora que desea promover para que sea el clúster principal de la base de datos global de Aurora. -
--allow-data-loss: indique explícitamente que es una operación de conmutación por error en lugar de una operación de transición. Una operación de conmutación por error puede tener como resultado la pérdida de algunos datos si los componentes de replicación asincrónica no han completado el envío de todos los datos replicados a la región secundaria.
Para Linux, macOS o Unix:
aws rds --regionregion_of_selected_secondary\ failover-global-cluster --global-cluster-identifierglobal_database_id\ --target-db-cluster-identifierarn_of_secondary_to_promote\ --allow-data-loss
Para Windows:
aws rds --regionregion_of_selected_secondary^ failover-global-cluster --global-cluster-identifierglobal_database_id^ --target-db-cluster-identifierarn_of_secondary_to_promote^ --allow-data-loss
Para realizar una conmutación por error con la base de datos global de Aurora, ejecute la operación de API FailoverGlobalCluster.
Ejecución de la conmutación por error manual para bases de datos globales de Aurora
En algunos casos, es posible que no pueda utilizar el proceso de conmutación por error administrada. Un ejemplo es si los clústeres de bases de datos principal y secundario no ejecutan versiones de motor compatibles. En este caso, puede seguir este proceso manual para realizar una conmutación por error en la región secundaria de destino.
sugerencia
Recomendamos que comprenda este proceso antes de usarlo. Tenga un plan listo para continuar rápidamente a la primera señal de un problema en toda la región. Puede utilizar Amazon CloudWatch periódicamente para realizar el seguimiento de los tiempos de retraso de los clústeres secundarios y estar preparado para identificar la región secundaria con el menor retraso de replicación. Asegúrese de probar su plan para verificar que sus procedimientos sean completos y precisos, y que el personal esté formado para realizar una conmutación por error de recuperación de desastres antes de que realmente suceda.
Para realizar una conmutación por error manual en un clúster secundario después de una interrupción no planificada en la región principal
-
Deje de emitir instrucciones DML y otras operaciones de escritura en el clúster de base de datos de Aurora principal en la Región de AWS con la interrupción.
-
Identifique un clúster de base de datos de Aurora de una Región de AWS secundaria para usarlo como un nuevo clúster de base de datos principal. Si tiene dos (o más) Regiones de AWS secundarias en la base de datos global de Aurora, elija el clúster secundario que tenga el menor retraso de replicación.
-
Desconecte el clúster secundario de la base de datos global de Aurora elegido.
La eliminación de un clúster de base de datos secundario de una base de datos global de Aurora detiene inmediatamente la replicación de la principal a esta secundaria y la promueve a un clúster de base de datos de Aurora aprovisionado e independiente con capacidades completas de lectura y escritura. Todavía está disponible cualquier otro clúster secundario de base de datos de Aurora asociado con el clúster principal de la región con la interrupción y puede aceptar llamadas desde la aplicación. También consumen recursos. Debido a que está recreando la base de datos global de Aurora, elimine los otros clústeres de base de datos secundarios antes de crear la nueva base de datos global de Aurora en los siguientes pasos. De este modo, se evitan incoherencias con respecto a los datos entre los clústeres de la base de datos global de Aurora (problemas del tipo cerebro dividido).
Para obtener más información sobre los pasos para desasociar clústeres, consulte Eliminación de un clúster de una base de datos global de Amazon Aurora.
-
Vuelva a configurar la aplicación para enviar todas las operaciones de escritura a este clúster de base de datos de Aurora ahora independiente con su nuevo punto de enlace. Si aceptó los nombres proporcionados al crear la base de datos global de Aurora, puede cambiar el punto de enlace quitando
-rode la cadena del punto de enlace del clúster en la aplicación.Por ejemplo, el punto de enlace del clúster secundario
my-global.cluster-ro-aaaaaabbbbbb.us-west-1.rds.amazonaws.comse convierte enmy-global.cluster-aaaaaabbbbbb.us-west-1.rds.amazonaws.comcuando ese clúster se desasocia de las bases de datos globales de Aurora.Este clúster de base de datos de Aurora se convierte en el clúster principal de una nueva base de datos global de Aurora cuando comienza a agregarle regiones en el siguiente paso.
Si utiliza RDS Poxy, asegúrese de redirigir las operaciones de escritura de la aplicación al punto de conexión de lectura o escritura correspondiente del proxy asociado al nuevo clúster principal. Este punto de conexión proxy puede ser el punto de conexión predeterminado o un punto de conexión de lectura o escritura personalizado. Para obtener más información, consulte Cómo funcionan los puntos de conexión de RDS Proxy con las bases de datos globales.
-
Agregue una Región de AWS al clúster de base de datos. Al hacerlo, comienza el proceso de reproducción de clúster principal a secundario. Para obtener más información sobre los pasos para agregar una región, consulte Incorporación de una Región de AWS a una base de datos global de Amazon Aurora.
-
Agregue más Regiones de AWS según sea necesario para recrear la topología necesaria para admitir su aplicación.
Asegúrese de que las escrituras de la aplicación se envíen al clúster de base de datos de Aurora correcto antes, durante y después de realizar estos cambios. De este modo, se evitan incoherencias con respecto a los datos entre los clústeres de la base de datos global de Aurora (problemas del tipo cerebro dividido).
Si realizó una reconfiguración en respuesta a una interrupción en una Región de AWS, puede volver a hacer que la Región de AWS sea de nuevo la región principal después de que se resuelva la interrupción. Para ello, añada la antigua Región de AWS a la nueva base de datos global y, a continuación, utilice el proceso de transición para cambiar su rol. La base de datos global de Aurora debe utilizar una versión de Aurora PostgreSQL o Aurora MySQL que admita la transiciones. Para obtener más información, consulte Ejecución de transiciones para bases de datos globales de Amazon Aurora.
Administración de RPO para bases de datos globales basadas en Aurora PostgreSQL–
Con una base de datos global basada en Aurora PostgreSQL, puede administrar el objetivo de punto de recuperación (RPO) de la base de datos global de Aurora mediante el parámetro rds.global_db_rpo. El RPO representa la cantidad máxima de datos que se pueden perder en caso de interrupción.
Cuando establece un RPO para la base de datos global basada en Aurora PostgreSQL–, Aurora monitorea el tiempo de retraso de RPO de todos los clústeres secundarios para asegurarse de que al menos un clúster secundario permanezca dentro de la ventana de RPO de destino. El tiempo de retraso de RPO es otra métrica basada en tiempo.
El objetivo de punto de recuperación (RPO) se utiliza cuando la base de datos reanuda las operaciones en una nueva Región de AWS después de una conmutación por error. Aurora evalúa los tiempos de retraso de RPO y RPO para confirmar (o bloquear) transacciones en el clúster principal de la siguiente manera:
-
Confirma la transacción si al menos un clúster secundario de base de datos tiene un tiempo de retraso de RPO menor que el RPO.
-
Bloquea la transacción si todos los clústeres secundarios de base de datos tienen tiempos de retraso de RPO mayores que el RPO. También registra el evento en el archivo de registro de PostgreSQL y emite eventos de “espera” que muestran las sesiones bloqueadas.
En otras palabras, si todos los clústeres secundarios están detrás del RPO fijado, Aurora detiene las transacciones en el clúster principal hasta que al menos uno de los clústeres secundarios se recupere. Las transacciones en pausa se reanudan y confirman tan pronto como el tiempo de retraso de al menos un clúster secundario de base de datos sea menor que el RPO. El resultado es que ninguna transacción se puede confirmar hasta que se cumpla el RPO.
El parámetro rds.global_db_rpo es dinámico. Si decide que no quiere que todas las transacciones de escritura se detengan hasta que el retraso disminuya lo suficiente, puede restablecerlo rápidamente. En este caso, Aurora reconoce e implementa el cambio tras un breve retraso.
importante
En una base de datos global con solo dos regiones de AWS, recomendamos mantener el valor predeterminado del parámetro rds.global_db_rpo en el grupo de parámetros de la región secundaria. De lo contrario, si se realiza una conmutación por error en debido a una pérdida de la región de AWS principal, Aurora podría pausar las transacciones. En su lugar, espere a que Aurora vuelva a crear el clúster en la región de AWS antigua que ha fallado antes de cambiar este parámetro para aplicar un RPO máximo.
Si establece este parámetro como se describe a continuación, también puede supervisar las métricas que genera. Puede hacerlo mediante psql u otra herramienta para consultar el clúster principal de la base de datos global de Aurora y obtener información detallada sobre las operaciones de la base de datos global basada en Aurora PostgreSQL–. Para saber cómo hacerlo, consulte Supervisión de bases de datos globales basadas en Aurora PostgreSQL.
Temas
Establecimiento del objetivo de punto de recuperación
El parámetro de rds.global_db_rpo controla la configuración de RPO para una base de datos PostgreSQL. Este parámetro es compatible con Aurora PostgreSQL. Valores válidos para el rango de rds.global_db_rpo de 20 segundos a 2 147 483 647 segundos (68 años). Elija un valor realista para satisfacer las necesidades de su negocio y su caso de uso. Por ejemplo, es posible que desee permitir hasta 10 minutos para su RPO, en cuyo caso establece el valor en 600.
Puede establecer este valor para la base de datos global basada en Aurora PostgreSQL–mediante la AWS Management Console, la AWS CLI o la API de RDS.
Para establecer el RPO
Inicie sesión en la AWS Management Console y abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. -
Elija el clúster principal de la base de datos global de Aurora y abra la pestaña Configuration (Configuración) para buscar su grupo de parámetros de clúster de base de datos. Por ejemplo, el grupo de parámetros predeterminado para un clúster principal de base de datos que ejecuta Aurora PostgreSQL 11.7 es
default.aurora-postgresql11.Los grupos de parámetros no se pueden editar directamente. En su lugar, puede hacer lo siguiente:
-
Cree un grupo de parámetros de clúster de base de datos personalizado con el grupo de parámetros predeterminado apropiado como punto de partida. Por ejemplo, cree un grupo de parámetros de clúster de base de datos personalizado basado en el
default.aurora-postgresql11. -
En su grupo de parámetros de base de datos personalizado, establezca el valor del parámetro rds.global_db_rpo para satisfacer su caso de uso. Los valores válidos van desde 20 segundos hasta el valor entero máximo de 2 147 483 647 (68 años).
-
Aplique el grupo de parámetros de clúster de base de datos modificado a su clúster de base de datos de Aurora
-
Para obtener más información, consulte Modificación de los parámetros en un grupo de parámetros de clúster de base de datos en Amazon Aurora.
Para establecer el parámetro rds.global_db_rpo, utilice el comando de CLI modify-db-cluster-parameter-group. En el comando, especifique el nombre del grupo de parámetros del clúster principal y los valores para el parámetro RPO.
En el ejemplo siguiente se establece el RPO en 600 segundos (10 minutos) para el grupo de parámetros de clúster principal de base de datos denominado my_custom_global_parameter_group.
Para Linux, macOS o Unix:
aws rds modify-db-cluster-parameter-group \ --db-cluster-parameter-group-namemy_custom_global_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
Para Windows:
aws rds modify-db-cluster-parameter-group ^ --db-cluster-parameter-group-namemy_custom_global_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ParameterValue=600,ApplyMethod=immediate"
Para modificar el parámetro rds.global_db_rpo, utilice la operación ModifyDBClusterParameterGroup de la API de Amazon RDS.
Visualización del objetivo de punto de recuperación
El objetivo de punto de recuperación (RPO) de una base de datos global se almacena en el parámetro rds.global_db_rpo para cada clúster de base de datos. Puede conectarse al punto de enlace del clúster secundario que desea ver y utilizar psql para consultar la instancia de este valor.
show rds.global_db_rpo;db-name=>
Si no se establece este parámetro, la consulta devuelve lo siguiente:
rds.global_db_rpo
-------------------
-1
(1 row)La siguiente respuesta es de un clúster secundario de base de datos que tiene una configuración de RPO de 1 minuto.
rds.global_db_rpo
-------------------
60
(1 row) También puede utilizar la CLI para obtener valores para averiguar si rds.global_db_rpo está activo en cualquiera de los clústeres de base de datos de Aurora mediante el uso de la CLI para obtener los valores de todos los parámetros user del clúster.
Para Linux, macOS o Unix:
aws rds describe-db-cluster-parameters \ --db-cluster-parameter-group-namelab-test-apg-global\ --source user
Para Windows:
aws rds describe-db-cluster-parameters ^ --db-cluster-parameter-group-namelab-test-apg-global* --source user
El comando devuelve un resultado similar al siguiente para todos los parámetros user que no son default-engine o parámetros de clúster de base de datos de system.
{
"Parameters": [
{
"ParameterName": "rds.global_db_rpo",
"ParameterValue": "60",
"Description": "(s) Recovery point objective threshold, in seconds, that blocks user commits when it is violated.",
"Source": "user",
"ApplyType": "dynamic",
"DataType": "integer",
"AllowedValues": "20-2147483647",
"IsModifiable": true,
"ApplyMethod": "immediate",
"SupportedEngineModes": [
"provisioned"
]
}
]
}
Para obtener más información sobre la visualización de parámetros del grupo de parámetros de clúster, consulte Visualización de los valores de parámetros de un grupo de parámetros de clúster de base de datos en Amazon Aurora.
Desactivación del objetivo de punto de recuperación
Para desactivar el RPO, restablezca el parámetro rds.global_db_rpo. Puede restablecer los parámetros mediante la AWS Management Console, la AWS CLI o la API RDS.
Para deshabilitar el RPO
Inicie sesión en la AWS Management Console y abra la consola de Amazon RDS en https://console.aws.amazon.com/rds/
. -
En el panel de navegación, seleccione Parameter groups (Grupos de parámetros).
-
En la lista, elija el grupo de parámetros de clúster de base de datos principal.
-
Elija Edit parameters (Editar parámetros).
-
Elija la casilla situada junto al parámetro rds.global_db_rpo.
-
Elija Restablecer.
-
Cuando la pantalla muestre Restablecer parámetros en el grupo de parámetros de base de datos, elija Restablecer parámetros.
Para obtener más información sobre cómo restablecer un parámetro con la consola, consulte Modificación de los parámetros en un grupo de parámetros de clúster de base de datos en Amazon Aurora.
Para restablecer el parámetro rds.global_db_rpo, utilice el comando reset-db-cluster-parameter-group.
Para Linux, macOS o Unix:
aws rds reset-db-cluster-parameter-group \ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group\ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
Para Windows:
aws rds reset-db-cluster-parameter-group ^ --db-cluster-parameter-group-nameglobal_db_cluster_parameter_group^ --parameters "ParameterName=rds.global_db_rpo,ApplyMethod=immediate"
Para restablecer el parámetro rds.global_db_rpo, utilice la operación ResetDBClusterParameterGroup de la API de Amazon RDS.
