Ejecución de una prueba de concepto de Amazon Aurora
A continuación, encontrará una explicación de cómo configurar una prueba de concepto de Aurora. Una prueba de concepto es una investigación que se realiza para ver si Aurora se adapta bien a su aplicación. La prueba de concepto le ayuda a comprender las características de Aurora en el contexto de sus propias aplicaciones de base de datos y cuál es el rendimiento de Aurora en comparación con el de su entorno de base de datos actual. También es útil para ver cuánto trabajo tendrá que dedicar a trasladar datos, migrar código SQL, ajustar el rendimiento y adaptar los procedimientos de administración actuales.
En este tema, se proporciona información e instrucciones generales para los procedimientos y decisiones de tipo general que deben adoptarse al ejecutar una prueba de concepto. Si desea consultar instrucciones detalladas, haga clic en los enlaces siguientes para llegar a la documentación de temas específicos.
Información general de una prueba de concepto de Aurora
Con una prueba de concepto de Amazon Aurora aprenderá cuánto le costará migrar los datos y las aplicaciones SQL existentes a Aurora. En dicha prueba, se aplican a escala aspectos importantes de Aurora, con un volumen de datos y una actividad representativos de su entorno de producción. El objetivo es asegurarse y confiar en que los puntos fuertes de Aurora estarán a la altura de los retos que le impulsan a ampliar su infraestructura de base de datos anterior. Cuando acabe la prueba de concepto, tendrá un plan sólido para realizar una comparación a mayor escala del rendimiento y la prueba de aplicación. En este punto, ya comprenderá cuáles son los principales elementos que tiene que desarrollar para llegar a una implementación de producción.
El siguiente consejo sobre prácticas recomendadas puede serle útil para evitar errores que se producen con frecuencia y que pueden provocar problemas durante la comparación. Sin embargo, en este tema no se cubre el proceso detallado paso a paso de realización de una comparación y un ajuste del rendimiento. Este procedimiento varía en función de la carga de trabajo y de las características de Aurora que use. Para obtener información detallada, consulte la documentación relacionada con el rendimiento, como Administración del rendimiento y el escalado para clústeres de base de datos Aurora, Mejoras del rendimiento de Amazon Aurora MySQL, Rendimiento y escalado para Amazon Aurora PostgreSQL y Monitoreo de la carga de base de datos con Performance Insights en Amazon Aurora.
La información que se proporciona en este tema se aplica principalmente a aplicaciones en las que la organización escribe el código y diseña el esquema, y que son compatibles con los motores de base de datos de código abierto MySQL y PostgreSQL. Si va a probar una aplicación comercial o un código generado por un marco de aplicaciones, puede que no tenga suficiente flexibilidad para aplicar todas las directrices. En dicho caso, contáctese con el representante de AWS para saber si existen prácticas recomendadas o casos prácticos de Aurora para su tipo de aplicación.
1. Identifique sus objetivos
Al evaluar Aurora como parte de una prueba de concepto, usted elige las medidas que van a realizarse y cómo determinar si un ejercicio se ha realizado correctamente.
Tiene que asegurarse de que la funcionalidad completa de la aplicación sea compatible con Aurora. Como las versiones principales de Aurora son compatibles por conexión con las versiones principales correspondientes de MySQL y PostgreSQL, la mayoría de las aplicaciones desarrolladas para estos motores también son compatibles con Aurora. Sin embargo, debe validar la compatibilidad aplicación por aplicación.
Por ejemplo, algunas de las opciones de configuración de un clúster de Aurora influyen en si se puede o se deben usar características determinadas de la base de datos. Puede comenzar, por ejemplo, por un clúster de Aurora de ámbito más general, conocido como clúster aprovisionado. Después, puede que le interese decidir si una configuración especializada como una consulta paralela o sin servidor le sería útil a su carga de trabajo.
Formúlese las siguientes preguntas para establecer y cuantificar sus objetivos:
-
¿Es compatible Aurora con todos los casos de uso funcionales de su carga de trabajo?
-
¿Qué volumen de conjunto de datos o nivel de carga quiere? ¿Puede escalar a dicho nivel?
-
¿Cuáles son sus requisitos específicos de latencia o desempeño de consultas? ¿Puede conseguirlos?
-
¿Cuál es el tiempo mínimo de inactividad planificada o sin planificar aceptable para su carga de trabajo? ¿Puede conseguirlo?
-
¿Cuáles son las métricas necesarias para un funcionamiento eficiente? ¿Puede monitorizarlas con precisión?
-
¿Es compatible Aurora con sus objetivos empresariales concretos como, por ejemplo, una reducción de costos, el aumento de la implementación o la velocidad de aprovisionamiento? ¿Tiene alguna forma de cuantificar dichos objetivos?
-
¿Puede cumplir todos los requisitos de seguridad y conformidad de su carga de trabajo?
Reserve tiempo para mejorar sus conocimientos sobre los motores de base de datos y las capacidades de plataforma de Aurora, y revise la documentación del servicio. Tome nota de todas las características que le pueden ser útiles para obtener los resultados deseados. Por ejemplo, puede interesarle la característica de consolidación de cargas de trabajo que se describe en la publicación del blog de bases de datos de AWS que trata de cómo planificar y optimizar Amazon Aurora con compatibilidad de MySQL para cargas de trabajo consolidadas
2. Conozca las características de su carga de trabajo
Evalúe Aurora en el contexto del caso de uso para el que está destinado. Aurora es una buen opción para las cargas de trabajo de procesamiento de transacciones en línea (OLTP). También puede ejecutar informes en el clúster que contiene los datos OLTP en tiempo real sin aprovisionar un clúster de almacén de datos independiente. Para saber si su caso de uso entra dentro de estas categorías, averigüe si tiene las siguientes características:
-
Un alto grado de simultaneidad, con decenas, centenas o miles de clientes a la vez.
-
Un alto volumen de consultas con baja latencia (de milisegundos a segundos).
-
Transacciones breves en tiempo real.
-
Patrones de consulta altamente selectivos, con búsquedas basadas en índices.
-
En el caso de HTAP, consultas analíticas que pueden aprovechar la característica de consultas paralelas de Aurora.
Cuando se elige una base de datos, uno de los factores clave es la velocidad de los datos. Si la velocidad es elevada, los datos se insertan y se actualizan con mucha frecuencia. En un sistema de este tipo, puede haber miles de conexiones y centenares de miles de consultas simultáneas que leen una base de datos y escriben en ella. Por lo general, las consultas que se realizan en sistemas de alta velocidad afectan a un número relativamente pequeño de filas y suelen obtener acceso a varias columnas de la misma fila.
Aurora está diseñado para trabajar con datos de alta velocidad. En función de la carga de trabajo, un clúster de Aurora con una única instancia de base de datos r4.16xlarge puede procesar más de 600 000 instrucciones SELECT por segundo. De nuevo, según la carga de trabajo, un clúster de este tipo puede procesar 200 000 sentencias INSERT, UPDATE y DELETE por segundo. Aurora es una base de datos de almacenamiento de filas ideal para las cargas de trabajo OLTP de alto volumen, alto rendimiento y alto paralelismo.
Aurora también puede ejecutar consultas en el mismo clúster que gestiona la carga de trabajo OLTP. Aurora soporta hasta 15 réplicas, cada una de las cuales está, en promedio, a 10 o 20 milisegundos de la instancia principal. Los analistas pueden consultar los datos OLTP en tiempo real sin copiar los datos en un clúster de almacenes de datos independiente. Dado que los clústeres de Aurora pueden usar la característica de consulta en paralelo, puede descargar un gran volumen de trabajo de procesamiento, filtrado y agregación en el subsistema de almacenamiento de Aurora de distribución masiva.
Aproveche esta fase de planificación para familiarizarse con las capacidades de Aurora, otros servicios de AWS, la AWS Management Console y AWS CLI. Además, compruebe cómo funcionan con otras herramientas que tiene previsto utilizar en la prueba de concepto.
3. Practique con la AWS Management Console o con la AWS CLI
En el siguiente paso, tendrá que practicar con la AWS Management Console o con AWS CLI para familiarizarse con estas herramientas y Aurora.
Practique con la AWS Management Console
Las siguientes actividades iniciales que se realizan con clústeres de la base de datos de Aurora tienen como objetivo principal familiarizarlo con el entorno de la AWS Management Console y hacerle practicar la configuración y la modificación de clústeres de Aurora. Si usa motores de base de datos compatibles con MySQL y PostgreSQL junto con Amazon RDS, puede aprovechar sus conocimientos cuando utilice Aurora.
Aproveche el modelo de almacenamiento compartido y las características de Aurora como la replicación y las instantáneas; puede tratar clústeres completos de bases de datos como si fueran otro tipo de objeto que puede manipular a su voluntad. Puede configurar, eliminar y cambiar con frecuencia la capacidad de los clústeres de Aurora durante la prueba de concepto. Las elecciones de capacidad, configuración de base de datos y disposición física de los datos que realice al principio no lo limitan.
Para comenzar, configure un clúster de Aurora vacío. Elija el tipo de capacidad provisioned (aprovisionado) y la ubicación regional para sus experimentos iniciales.
Establezca conexión con el clúster mediante un programa cliente como una aplicación de línea de comandos de SQL. Al principio establezca conexión utilizando el punto de enlace del clúster. Conéctese al punto de enlace para realizar cualquier operación de escritura, como instrucciones de lenguaje de definición de datos (DDL) y procesos de extracción, transformación y carga (ETL). Más adelante, en la prueba de concepto, conectará sesiones de uso intensivo de consultas usando el punto de enlace del lector, que se encargará de distribuir la carga de trabajo de las consultas entre numerosas instancias de base de datos del clúster.
Escale el clúster añadiendo más réplicas de Aurora. Para informarse sobre estos procedimientos, consulte Replicación con Amazon Aurora. Aumente o reduzca el escalado de las instancias de base de datos cambiando la clase de instancia de AWS. Comprenda cómo Aurora simplifica estos tipos de operaciones, ya que si más adelante sus estimaciones iniciales de la capacidad del sistema demuestran ser poco precisas, pueda modificarlas sin tener que volver a comenzar.
Cree una instantánea y restáurela en otro clúster.
Examine las métricas del clúster para ver la actividad en el tiempo y cómo las métricas se aplican a las instancias de base de datos del clúster.
Al principio puede serle útil familiarizarse con el uso de la AWS Management Console para realizar estas tareas. Cuando comprenda qué puede hacer con Aurora, podrá automatizar dichas operaciones con AWS CLI. En las secciones siguientes encontrará información detallada acerca de los procedimientos y las prácticas recomendadas de estas actividades durante el período de prueba de concepto.
Practique con la AWS CLI
Recomendamos que automatice los procedimientos de implementación y administración, incluso en un entorno de prueba de concepto. Para ello, familiarícese con la AWS CLI si todavía no está familiarizado. Si usa motores de base de datos compatibles con MySQL y PostgreSQL junto con Amazon RDS, puede aprovechar sus conocimientos cuando utilice Aurora.
Normalmente, Aurora trabaja con grupos de instancias de bases de datos ordenadas en clústeres. Esto hace que en muchas operaciones se tenga que determinar qué instancias de base de datos están asociadas a un clúster y luego se realicen operaciones administrativas en bucle en todas las instancias.
Por ejemplo, puede automatizar pasos como la creación de clústeres de Aurora y luego escalarlos mediante ampliación con clases de instancias más grandes o ampliarlos con instancias de bases de datos adicionales. Esta característica es útil si desea repetir cualquier etapa de su prueba de concepto y explorar escenarios condicionales con diferentes tipos de configuraciones de clústeres de Aurora.
Aprenda cuáles son las capacidades y limitaciones de las herramientas de implementación de infraestructura como AWS CloudFormation. Puede darse el caso de que actividades que realiza en un contexto de prueba de concepto no sean adecuadas en un entorno de producción. Por ejemplo, el comportamiento de AWS CloudFormation en una modificación consiste en crear una instancia nueva y eliminar la actual, incluidos sus datos. Para obtener más detalles acerca de este comportamiento, consulte Comportamientos de actualización de los recursos de la pila en la guía del usuario de AWS CloudFormation.
4. Cree su clúster de Aurora
Con Aurora, puede explorar escenarios condicionales añadiendo instancias de base de datos al clúster y escalando mediante ampliación las instancias de base de datos a clases de instancias más potentes. También puede crear clústeres con distintos ajustes de configuración para que ejecuten la misma carga de trabajo uno al lado de otro. Aurora aporta una gran flexibilidad que le permite configurar, eliminar y volver a configurar clústeres de bases de datos. Teniendo en cuenta estas técnicas, le será útil practicarlas en las etapas iniciales del proceso de prueba de concepto. Para informarse de los procedimientos generales para crear clústeres de Aurora, consulte Creación de un clúster de base de datos de Amazon Aurora.
Para practicar, comience con un clúster que tenga la configuración que indicamos más abajo. Omita este paso solo si tiene en mente algunos casos de uso específicos. Por ejemplo, puede que le interese omitir este paso si su caso de uso necesita un tipo especializado de clúster de Aurora, O bien, puede que le interese omitirlo si necesita una combinación específica de motor de base de datos y versión.
-
Desactivación de Easy create (Creación sencilla). Para la prueba de concepto, le recomendamos que preste mucha atención a todos los ajustes que elija a fin de que pueda crear clústeres idénticos o muy parecidos más adelante.
-
Use una versión del motor de base de datos reciente. Estas combinaciones de motor de base de datos y versión tienen una compatibilidad de amplio espectro con otras características de Aurora y un uso de clientes sustancial para aplicaciones de producción.
-
Aurora MySQL versión 3.x (compatibilidad con MySQL 8.0)
-
Aurora PostgreSQL versión 15.x o 16.x
-
-
Elija la plantilla Dev/Test (Desarrollo/Prueba). Esta opción no es significativa para sus actividades de prueba de concepto.
-
Para DB instance class (Clase de instancia de base de datos), elija Memory Optimized classes (Clases optimizadas para memoria) y una de las clases de instancias xlarge. Más adelante, podrá subir o bajar el nivel de la clase de instancia.
-
En Multi-AZ Deployment (Implementación Multi-AZ), elija Create an Aurora Replica or Reader node in different AZ (Crear una Réplica de Aurora o un nodo de lector en una AZ diferente). En muchos de los aspectos más útiles de Aurora se usan clústeres compuestos por numerosas instancias de base de datos. En todos los clústeres nuevos es normal comenzar siempre por dos instancias de base de datos como mínimo. Si se usa una zona de disponibilidad diferente para la otra instancia de base de datos, será más fácil probar diferentes escenarios de alta disponibilidad.
-
Cuando elija un nombre para una instancia de base de datos, utilice una convención de nomenclatura genérica. Nunca se refiera a una instancia de base de datos del clúster como la instancia “escritora”, ya que, según las necesidades, esto rol lo asumirán instancias de base de datos diferentes. Le recomendamos que use algo parecido a
clustername-az-serialnumber; por ejemplomyprodappdb-a-01. De esta manera, puede identificar de forma exclusiva la instancia de base de datos y su ubicación. -
Configure la retención de la copia de seguridad en un valor elevado para el clúster de Aurora. Si el período de retención es largo, puede realizar una recuperación a un momento dado (PITR) para un período de 35 días como máximo. Podrá restablecer la base de datos en un estado conocido después de haber ejecutado las pruebas con instrucciones DDL y de lenguaje de manipulación de datos (DML). También puede hacer una recuperación si por error borra o cambia datos.
-
Habilite las características adicionales de recuperación, registro y monitorización al crear el clúster. Active todas las opciones disponibles bajo Backtrack, Información sobre rendimiento, Supervisión y Exportaciones de registro. Con estas opciones habilitadas, puede probar la idoneidad de características como el backtracking, la monitorización mejorada o la información sobre rendimiento en su carga de trabajo. También puede estudiar fácilmente el rendimiento y la resolución de problemas durante la prueba de concepto.
5. Configure el esquema
En el clúster de Aurora, configure las bases de datos, tablas, índices, claves externas y otros objetos del esquema para su aplicación. Si se está trasladando desde un sistema de base de datos compatible con MySQL o PostgreSQL, esta etapa será probablemente sencilla y fácil. Tendrá que usar la misma línea de comandos y sintaxis de SQL u otras aplicaciones cliente con las que ya está familiarizado con su motor de base de datos.
Para generar instrucciones SQL en el clúster, busque el punto de enlace de clúster y suministre el valor como parámetro de conexión a su aplicación cliente. Encontrará el punto de enlace del clúster en la pestaña Connectivity (Conectividad) de la página de detalles del clúster. El punto de enlace del clúster es el que está etiquetado como Writer (Escritor). El otro punto de enlace, etiquetado como Reader (Lector), representa una conexión de solo lectura que se puede proporcionar a usuarios finales que ejecuten informes u otras consultas de solo lectura. Para obtener ayuda con problemas relativos a la conexión del clúster, consulte Conexión a un clúster de base de datos Amazon Aurora.
Si migra el esquema y los datos desde otro sistema de base de datos, en este punto probablemente tendrá que introducir algún cambio. Los cambios de esquema se efectúan para que coincida con la sintaxis de SQL y las capacidades disponibles en Aurora. En este punto puede excluir algunas columnas, restricciones, desencadenantes u otros objetos del esquema. Esta operación es útil, sobre todo si los objetos requieren un trabajo adicional para que sean compatibles con Aurora y no son especialmente importantes para sus objetivos en la prueba de concepto.
Si realiza la migración desde un sistema de base de datos cuyo motor subyacente no sea el mismo que el de Aurora, considere usar AWS Schema Conversion Tool (AWS SCT) para simplificar el proceso. Para obtener más detalles, consulte la guía del usuario de AWS Schema Conversion Tool. Para obtener detalles generales sobre las actividades de migración y portabilidad, consulte el documento técnico AWS Migrating Your Databases to Amazon Aurora
Durante esta etapa, puede detectar si la configuración del esquema es poco eficiente en algunos aspectos como, por ejemplo, en la estrategia de indexación u otras estructuras de tabla como tablas con particiones. Esta baja eficiencia puede incrementarse si implementa la aplicación en un clúster que tenga numerosas instancias de base de datos y una carga de trabajo elevada. Decida si debe ajustar ahora estos aspectos del rendimiento o bien si esperará a actividades posteriores, como la prueba de referencia completa.
6. Importe los datos
Durante la prueba de concepto, tiene que importar los datos, o una muestra representativa de ellos, desde su antiguo sistema de base de datos. Si es práctico, configure como mínimo algunos datos en cada una de las tablas. Esto es útil para probar la compatibilidad de todos los tipos de datos y las características del esquema. Cuando haya probado las características básicas de Aurora, aumente la cantidad de datos. Cuando termine la prueba de concepto, deberá poder probar sus herramientas de ETL, consultas y carga de trabajo en general con un conjunto de datos que sea lo suficientemente grande como para obtener conclusiones precisas.
Para importar los datos de la copia de seguridad lógica o física a Aurora, puede usar varias técnicas. Para obtener información detallada, consulte Migración de datos a un clúster de base de datos de Amazon Aurora MySQL o Migración de datos a Amazon Aurora con compatibilidad con PostgreSQL, según el motor de base de datos que use en la prueba de concepto.
Experimente con las tecnologías y las herramientas ETL que esté pensando utilizar. Vea cuáles son las que mejor se adaptan a sus necesidades. Tenga en cuenta tanto el desempeño como la flexibilidad. Por ejemplo, algunas herramientas ETL realizan una transferencia única, mientras que otras utilizan una replicación en curso desde el sistema antiguo hasta Aurora.
Si realiza la migración desde un sistema compatible con MySQL hasta Aurora MySQL, puede usar las herramientas de transferencia de datos nativas. Es el mismo caso que si migra desde un sistema compatible con PostgreSQL hasta Aurora PostgreSQL. Si migra desde un sistema de base de datos que usa un motor subyacente que no es el mismo que el de Aurora, puede experimentar con AWS Database Migration Service (AWS DMS). Para obtener más detalles sobre AWS DMS, consulte la guía del usuario de AWS Database Migration Service.
Para obtener más detalles sobre las actividades de migración y transferencia, consulte el documento técnico de AWS del manual de migración de Aurora
7. Transfiera su código SQL
La prueba de SQL y las aplicaciones asociadas es más o menos laboriosa, en función de los diferentes casos. El nivel de trabajo depende, en concreto, de si la migración se efectúa desde un sistema compatible con MySQL o PostgreSQL, o desde otro tipo de sistema.
-
Si la migración se efectúa desde RDS for MySQL o RDS for PostgreSQL, los cambios que SQL necesita son tan pequeños que puede probar el código SQL original con Aurora e incorporar manualmente los cambios necesarios.
-
Igualmente, si efectúa la migración desde una base de datos local compatible con MySQL o PostgreSQL, puede probar el código SQL original e incorporar manualmente los cambios.
-
Si realiza la migración desde otra base de datos comercial, los cambios que debe efectuar en SQL son más extensos. En dicho caso, piense en utilizar AWS SCT.
Durante esta etapa, puede detectar si la configuración del esquema es poco eficiente en algunos aspectos como, por ejemplo, en la estrategia de indexación u otras estructuras de tabla como tablas con particiones. Decida si debe ajustar ahora estos aspectos del rendimiento o bien si esperará a actividades posteriores, como la prueba de referencia completa.
Puede verificar la lógica de conexión de la base de datos en su aplicación. Para aprovechar el procesamiento distribuido de Aurora, es posible que deba usar conexiones diferentes para las operaciones de lectura y escritura, así como tener sesiones relativamente cortas para las operaciones de consulta. Para obtener más información acerca de las conexiones, consulte 9. Conéctese a Aurora.
Tenga en cuenta si ha tenido que transigir o hacer concesiones para solucionar problemas en la base de datos de producción. Integre tiempo en el programa de realización de la prueba de concepto para introducir mejoras en las consultas y el diseño de esquema. Para evaluar si puede obtener fácilmente beneficios en el rendimiento, los costos operativos y la escalabilidad, pruebe las aplicaciones original y modificada, una al lado de la otra, en clústeres de Aurora diferentes.
Para obtener más detalles sobre las actividades de migración y transferencia, consulte el documento técnico de AWS del manual de migración de Aurora
8. Especifique las opciones de configuración
Al efectuar la prueba de concepto de Aurora, tiene la posibilidad también de revisar los parámetros de configuración de la base de datos. Probablemente la configuración de MySQL o PostgreSQL ya esté ajustada para el rendimiento y la escalabilidad de su entorno actual. El subsistema de almacenamiento de Aurora está adaptado y ajustado a un entorno basado en la nube distribuido con un subsistema de almacenamiento de alta velocidad. En consecuencia, muchas configuraciones de motor de base de datos antiguas no se pueden aplicar. Le recomendamos que realice los experimentos iniciales con los ajustes de configuración de Aurora predeterminados. Vuelva a aplicar la configuración de su entorno actual solo si se producen atascos de rendimiento o de escalabilidad. Si está interesado en este tema, puede profundizar consultando la Introducción del motor de almacenamiento Aurora
Aurora facilita la reutilización de los ajustes de configuración óptimos para una aplicación o un caso de uso determinado. En vez de editar un archivo de configuración independiente por cada instancia de base de datos, administre conjuntos de parámetros que después asignará a clústeres enteros o a instancias de bases de datos específicas. Por ejemplo, la configuración de la zona horaria se aplica a todas las instancias de base de datos del clúster, y puede ajustar el valor del tamaño de la memoria caché de la página para cada instancia de base de datos.
Comience con uno de los conjuntos de parámetros predeterminados y aplique cambios solo a aquellos parámetros que tenga que ajustar. Para obtener información detallada acerca de cómo trabajar con grupos de parámetros, consulte Parámetros del clúster de base de datos de Amazon Aurora y de instancia de base de datos. Para informarse de los ajustes de configuración que se pueden o no se pueden aplicar a clústeres de Aurora, consulte Parámetros de configuración de Aurora MySQL o Parámetros de Amazon Aurora PostgreSQL. según el motor de base de datos.
9. Conéctese a Aurora
Cuando realice la configuración inicial del esquema y los datos, y ejecute las consultas de ejemplo, verá que puede conectarse a diferentes puntos de enlace de un clúster de Aurora. El punto de enlace que use dependerá de si la operación es de lectura, como una instrucción SELECT, o de escritura, como una instrucción CREATE o INSERT. A medida que aumente la carga de trabajo en un clúster de Aurora y experimente con características de Aurora, es importante que la aplicación asigne cada operación al punto de enlace adecuado.
Si usa el punto de enlace del clúster destinado a operaciones de escritura, se conectará siempre a una instancia de base de datos del clúster que tenga capacidad de lectura-escritura. De forma predeterminada, solo una instancia de base de datos de un clúster de Aurora tiene capacidad de lectura-escritura. Esta instancia de la base de datos se conoce como la instancia principal. Si la instancia principal original deja de esta disponible, Aurora activa un mecanismo de conmutación por error y otra instancia de base de datos pasa a ocupar el lugar de la principal.
Igualmente, si dirige instrucciones SELECT al punto de enlace del lector, extiende el trabajo de procesamiento de consultas a las instancias de base de datos del clúster. Cada conexión del lector se asigna a una instancia de base de datos diferente mediante una resolución DNS de turno rotativo. Si efectúa la mayor parte del trabajo de consulta en las réplicas de Aurora de base de datos de solo lectura, reducirá la carga de la instancia principal y la liberará para que pueda gestionar las instrucciones DDL y DML.
Al utilizar estos puntos de enlace, reducirá la dependencia de los nombres de host no modificables y, al mismo tiempo, ayudará a la aplicación a recuperarse más rápidamente de los errores de las instancias de base de datos.
nota
Aurora también tiene puntos de enlace personalizados que usted crea. Normalmente, estos puntos de enlace no se necesitan durante una prueba de concepto.
Las réplicas de Aurora están sujetas a un retraso de réplica, aunque por lo general dicho retraso sea de 10 a 20 milisegundos. Puede monitorizar el retraso de replicación y decidir si entra dentro del rango de requisitos de coherencia de sus datos. A veces, las consultas de lectura pueden necesitar que la coherencia de lectura sea sólida (coherencia de lectura después de escritura). En dichos casos, puede seguir utilizando para ellas el punto de enlace del clúster y no el punto de enlace del lector.
Para aprovechar plenamente las capacidades de Aurora para la ejecución en paralelo distribuida, puede que tenga que cambiar la lógica de conexión. El objetivo es evitar enviar todas las solicitudes de lectura a la instancia principal. Las réplicas de Aurora de solo lectura están a la espera, listas para hacerse cargo de las instrucciones SELECT. Codifique la lógica de aplicación para que use el punto de enlace adecuado para cada tipo de operación. Siga estas instrucciones generales:
-
Evite utilizar una única cadena de conexión no modificable para todas las sesiones de base de datos.
-
Si es práctico, escriba operaciones como instrucciones DDL o DML en las funciones, en el código de aplicación cliente. De esta forma, puede hacer que diferentes tipos de operaciones usen conexiones específicas.
-
Realice funciones separadas para las operaciones de consulta. Aurora asigna cada nueva conexión que se realice al punto de enlace del lector a una réplica de Aurora diferente a fin de equilibrar la carga de las aplicaciones con un uso elevado de la lectura.
-
En el caso de las operaciones que usan conjuntos de consultas, cierre y vuelva a abrir la conexión al punto de enlace del lector cuando acabe cada conjunto de consultas relacionadas. Agrupe las conexiones si esta característica está disponible en su pila de software. Dirigir las consultas a diferentes conexiones ayuda a Aurora a distribuir la carga de trabajo de lectura entre las instancias de bases de datos del clúster.
Para obtener información general acerca de la administración de conexiones y los puntos de enlace de Aurora, consulte Conexión a un clúster de base de datos Amazon Aurora. Para profundizar en el tema, consulte Manual de administrador de bases de datos MySQL de Aurora: administración de conexiones
10. Ejecute la carga de trabajo
Una vez que haya establecido los valores de esquema, datos y configuración, puede empezar a practicar con el clúster ejecutando la carga de trabajo. La carga de trabajo que use en la prueba de concepto debe reflejar los principales aspectos de su carga de trabajo de producción. Le recomendamos que las decisiones que tome sobre el rendimiento se basen siempre en pruebas y cargas de trabajo reales, y no en referencias sintéticas como sysbench o TPC-C. Cuando sea práctico, recopile medidas que se basen en su esquema, sus patrones de consulta y su volumen de uso.
Además de tener en cuenta el aspecto práctico, replique las condiciones reales en las que se ejecutará la aplicación. Por ejemplo, normalmente se ejecuta el código de aplicación en instancias Amazon EC2, en la misma región de AWS y en la misma Virtual Private Cloud (VPC) que el clúster de Aurora. Si la aplicación de producción se ejecuta en varias instancias EC2 que se extienden por varias zonas de disponibilidad, configure el entorno de la prueba de concepto de la misma manera. Para obtener más información sobre las regiones de AWS, consulte Regiones y zonas de disponibilidad en la guía del usuario de Amazon RDS. Para obtener más información acerca del servicio Amazon VPC, consulte ¿Qué es Amazon VPC? en la Guía del usuario de Amazon VPC.
Una vez que haya comprobado que las características básicas de su aplicación funcionan y que puede obtener acceso a los datos a través de Aurora, puede practicar aspectos del clúster de Aurora. Puede que le interese practicar características como conexiones simultáneas con equilibrio de carga, transacciones simultáneas y replicaciones automáticas.
Cuando llegue a este punto, debería estar ya familiarizado con los mecanismos de transferencia de datos y, por lo tanto, poder ejecutar pruebas con una proporción más grande de datos de muestra.
En esta etapa puede estudiar cómo repercuten los cambios en los ajustes de configuración como, por ejemplo, los límites de memoria o los de conexión. Repase los procedimientos que ha explorado en 8. Especifique las opciones de configuración.
También puede experimentar con mecanismos como la creación y restauración de instantáneas. Por ejemplo, puede crear clústeres con clases de instancias de AWS diferentes, números de réplicas de AWS diferentes, etc. Luego, en cada clúster, puede restaurar la misma instantánea que contiene su esquema y todos los datos. Para obtener información detallada sobre este ciclo, consulte Creación de una instantánea de clúster de base de datos y Restauración de una instantánea de clúster de base de datos.
11. Mida el rendimiento
Las prácticas recomendadas de esta área están diseñadas para garantizar que se configuren las herramientas y los procesos adecuados para aislar rápidamente los comportamientos anormales durante las operaciones de carga de trabajo. También se configuran para que pueda identificar de forma fiable todas las causes aplicables.
Siempre puede ver el estado actual de su clúster o examinar las tendencias a lo largo del tiempo, consultando la pestaña Monitoring (Monitorización). Esta pestaña está disponible en la página de detalles de la consola de cada clúster o de la instancia de base de datos de Aurora. En ella se muestran las métricas del servicio de monitorización de Amazon CloudWatch en forma de gráficos. Puede filtrar las métricas por nombre, por instancia de base de datos y por período de tiempo.
Para tener a su disposición más opciones en la pestaña Monitoring (Monitorización), habilite Enhanced Monitoring (Monitorización mejorada) y Performance Insights (Información sobre rendimiento) en la configuración del clúster. También puede habilitar más adelante estas opciones si no las ha seleccionado al configurar el clúster.
El rendimiento se mide principalmente basándose en los gráficos que muestran la actividad de todo el clúster de Aurora. Puede verificar si las réplicas de Aurora tienen tiempos de carga y respuesta similares. También puede ver cómo se divide el trabajo entre la instancia principal de lectura-escritura y las réplicas de Aurora de solo lectura. Si detecta un desequilibrio en las instancias de base de datos o un problema que afecta a una sola instancia de base de datos, consulte la pestaña Monitoring (Monitorización) de la instancia afectada.
Cuando haya configurado el entorno y la carga de trabajo real para que emulen su aplicación de producción, podrá evaluar el rendimiento de Aurora. A continuación le indicamos las preguntas más importantes que tiene que plantearse:
-
¿Cuántas consultas por segundo procesa Aurora? Para saber la respuesta, consulte las métricas de Throughput (Desempeño) para ver las cifras de diversos tipos de operaciones.
-
¿Cuánto tiempo tarda, en promedio, Aurora en procesar una consulta determinada? Para saber la respuesta, consulte las métricas de Latency (Latencia) para ver las cifras de diversos tipos de operaciones.
Para ver las métricas de rendimiento y latencia, consulte la pestaña Monitorización de un clúster de Aurora en la consola de Amazon RDS
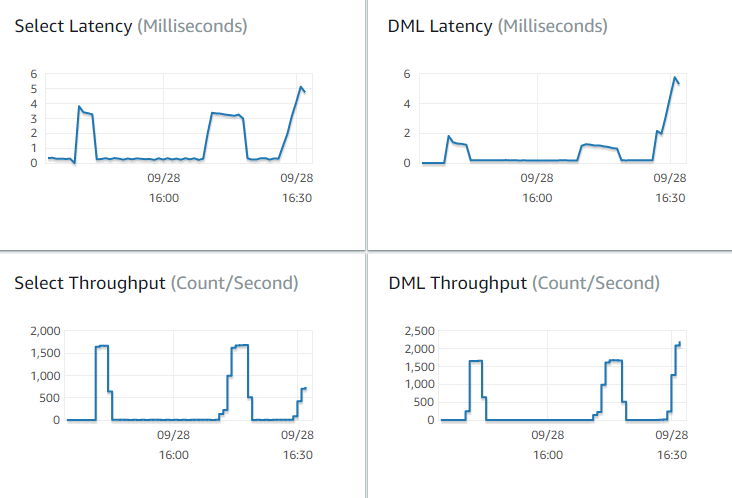
Si puede hacerlo, establezca valores de referencia para estas métricas en su entorno actual. Si esta operación no es práctica, cree una base de referencia en el clúster de Aurora ejecutando una carga de trabajo que sea equivalente a su aplicación de producción. Por ejemplo, ejecute su carga de trabajo de Aurora con un número similar de usuarios y consultas simultáneos. Luego observe cómo cambian los valores a medida que va experimentando con diferentes clases de instancias, tamaños de clúster, ajustes de configuración, etc.
Si los resultados del desempeño no están a la altura de lo que esperaba, profundice en la investigación de los factores que repercuten en el rendimiento de la base de datos para su carga de trabajo. Igualmente, si las cifras de la latencia son superiores a lo que esperaba, profundice en las causas. Para ello, monitorice las métricas secundarias del servidor de base de datos (CPU, memoria, etc.). De esta forma podrá ver si las instancias de base de datos están próximas a sus límites. También podrá saber cuánta capacidad adicional les queda a las instancias de bases de datos para gestionar más consultas simultáneas, consultas para tablas más grandes, etc.
sugerencia
Para detectar valores de métricas que se salen de los rangos previstos, configure alarmas de CloudWatch.
Cuando evalúe la capacidad y el tamaño de clúster ideales de Aurora, puede encontrar la configuración que obtiene el rendimiento máximo de la aplicación sin aprovisionar recursos en exceso. En este sentido, un factor importante es encontrar el tamaño adecuado de las instancias de base de datos de clúster de Aurora. Comience seleccionando un tamaño de instancia cuya capacidad de memoria y CPU sea similar a la de su entorno de producción actual. Recopile las cifras de desempeño y latencia de la carga de trabajo con ese tamaño de instancia. Luego, escale el tamaño al siguiente tamaño más grande. Compruebe si los resultados del desempeño y la latencia mejoran. Reduzca también el tamaño de la instancia para ver si los resultados de la latencia y el desempeño siguen siendo los mismos. Su objetivo es obtener el máximo desempeño, con el nivel de latencia más bajo, en la instancia más pequeña posible.
sugerencia
Dé a los clústeres de Aurora y a las instancias de base de datos la capacidad suficiente como para poder gestionar los picos de tráfico repentinos e impredecibles. Para las bases de datos críticas para el trabajo, deje como mínimo un 20 % de espacio de CPU y de capacidad de memoria libre.
Ejecute pruebas de rendimiento el tiempo suficiente como para medir el rendimiento de la base de datos en un estado constante y flexible. Puede que tenga que ejecutar la carga de trabajo durante varios minutos o incluso unas cuantas horas para llegar a este estado constante. Es normal que, al principio de una ejecución, haya algunas variaciones. Estas variaciones se deben a que cada réplica de Aurora activa sus cachés en función de las consultas SELECT que gestiona.
El mejor rendimiento de Aurora se obtiene con cargas de trabajo transaccionales en las que hay numerosos usuarios y consultas simultáneos. Para asegurarse de que la carga sea suficiente para un rendimiento óptimo, ejecute referencias con multiprocesos, o bien ejecute varias instancias de las pruebas de rendimiento a la vez. Mida el rendimiento con centenares o incluso miles de subprocesos cliente a la vez. Simule el número de subprocesos simultáneos que prevé tener en su entorno de producción. También puede ejecutar pruebas de estrés adicionales con más subprocesos para medir la escalabilidad de Aurora.
12. Pruebe la alta disponibilidad de Aurora
Muchas de las principales características de Aurora tienen una alta disponibilidad. Se trata de las características de replicación automática, conmutación por error automática, copia de seguridad automática con restauración a un momento dado y capacidad para añadir instancias de base de datos al clúster. La seguridad y la fiabilidad de dichas características es importante para las aplicaciones críticas.
La evaluación de estas características requiere adoptar una visión específica. En las actividades anteriores, como la medición del rendimiento, se observaba el rendimiento del sistema cuando todo funcionaba correctamente. Sin embargo, para probar la alta disponibilidad, es preciso enfocar la observación desde el estudio de las peores situaciones que puedan producirse. Ha de tener en cuenta distintos tipos de errores, incluso si tales casos son excepcionales. Por ejemplo, puede introducir problemas a propósito para asegurarse de que el sistema se recupere deprisa y correctamente.
sugerencia
Para una prueba de concepto, configure todas las instancias de base de datos de un clúster de Aurora con la misma clase de instancia de AWS. Con ello, será posible probar las características de disponibilidad de Aurora sin grandes cambios en el rendimiento ni la escalabilidad, ya que saca fuera de línea las instancias de base de datos para simular los errores.
Le recomendamos que use como mínimo dos instancias en cada clúster de Aurora. Las instancias de base de datos de un clúster de Aurora pueden extenderse hasta un máximo de tres zonas de disponibilidad (AZ). Ubique las dos o tres primeras instancias de base de datos de cada AZ diferente. Cuando comience a utilizar clústeres más grandes, extienda sus instancias de base de datos a todas las zonas de disponibilidad de la región de AWS. Al hacerlo aumentará su capacidad de tolerancia a errores. Aunque un problema afecte a una AZ entera, Aurora puede realizar una conmutación por error a una instancia de base de datos de otra AZ. Si tiene un clúster con más de tres instancias, distribuya las instancias de base de datos de la forma más homogénea posible entre las tres AZ.
sugerencia
El almacenamiento de un clúster de Aurora no depende de las instancias de base de datos. El almacenamiento de cada clúster de Aurora se extiende siempre a tres AZ.
Cuando pruebe las características de alta disponibilidad, use siempre instancias de base de datos con capacidad idéntica en el clúster de prueba. Con esto evitará cambios imprevistos en el rendimiento, la latencia, etc. siempre que una instancia de base de datos sustituya a otra.
Para aprender a simular condiciones de error para probar las características de alta disponibilidad, consulte Pruebas de Amazon Aurora MySQL por medio de consultas de inserción de errores.
En la ejecución de la prueba de concepto, uno de los objetivos es encontrar el número ideal de instancias de bases de datos y la clase de instancia óptima para dichas instancias de base de datos. Para ello, tiene que equilibrar los requisitos de alta disponibilidad y rendimiento.
En Aurora, cuantas más instancias de bases de datos tenga en un clúster, más beneficiada saldrá la alta disponibilidad. Si tiene más instancias de base de datos, mejorará también la escalabilidad de las aplicaciones que realicen una lectura intensiva. Aurora puede distribuir múltiples conexiones para consultas SELECT entre las réplicas de Aurora de solo lectura.
Por otra parte, si limita el número de instancias de base de datos reducirá el tráfico de replicación desde el nodo principal. El tráfico de replicación consume ancho de banda de red, que es otro aspecto del rendimiento y la escalabilidad generales. Por lo tanto, para las aplicaciones OLTP de uso intensivo de escritura, es mejor que se incline por un número más pequeño de instancias de base de datos grandes que por muchas instancias de base de datos pequeñas.
En un clúster de Aurora típico, una instancia de base de datos (la instancia principal) gestiona todas las instrucciones DDL y DML. Las demás instancias de base de datos (las réplicas de Aurora) solo se encargan de las instrucciones SELECT. Aunque las instancias de base de datos no realizan exactamente la misma cantidad de trabajo, recomendamos que use la misma clase de instancia para todas las instancias de base de datos del clúster. Así, si se produce un error y Aurora promociona una instancia de base de datos de solo lectura como la nueva instancia principal, dicha instancia principal tendrá la misma capacidad que antes.
Si tiene que utilizar instancias de base de datos con capacidades diferentes en el mismo clúster, configure niveles de conmutación por error para las instancias de base de datos. Estos niveles determinarán el orden de promoción de las réplicas de Aurora mediante el mecanismo de conmutación por error. Ponga las instancias de base de datos que sean mucho más grandes o pequeñas que las demás en un nivel de conmutación por error más bajo. Así se asegurará de que se sean las últimas en ser elegidas para una promoción.
Practique las características de recuperación de datos de Aurora, como la restauración automática a un momento dado, las instantáneas manuales y su restauración, y el backtracking de clústeres. Si es pertinente, copie instantáneas en otras regiones de AWS y restáurelas en otras regiones de AWS para imitar escenarios de recuperación de desastres (DR).
Investigue los requisitos de su organización para los objetivos de tiempo de recuperación (RTO), los objetivos de punto de recuperación (RPO) y la redundancia geográfica. La mayoría de las organizaciones agrupan estos elementos en la categoría más general de recuperación de desastres. Evalúe las características de alta disponibilidad de Aurora descritas en esta sección en el contexto de su proceso de recuperación de desastres, a fin de asegurarse de que los requisitos de RTO y RPO se cumplan.
13. Qué hacer a continuación
Al finalizar un proceso de prueba de concepto realizado correctamente, confirmará que Aurora es una solución adecuada para usted basándose en la carga de trabajo prevista. A lo largo del proceso anterior, ha comprobado cómo funciona Aurora en un entorno operativo realista y ha medido su funcionamiento de acuerdo con sus criterios de éxito.
Después de configurar su entorno de base de datos y ejecutarlo con Aurora, puede pasar a los pasos de evaluación más detallados que lo conducirán a la migración e implementación de producción finales. Según cuál sea su situación, dichos pasos adicionales se incluirán o no en el proceso de prueba de concepto. Para obtener más detalles sobre las actividades de migración y transferencia, consulte el documento técnico de AWS del manual de migración de Aurora
En otro paso adicional, estudie las configuraciones de seguridad adecuadas para su carga de trabajo y diseñadas para cumplir los requisitos de seguridad de un entorno de producción. Planifique los controles que deben implantarse para proteger el acceso a las credenciales de usuario maestro del clúster de Aurora. Defina los roles y las responsabilidades de los usuarios de la base de datos para controlar el acceso a los datos almacenados en el clúster de Aurora. Tenga en cuenta los requisitos de acceso a la base de datos de las aplicaciones, scripts y herramientas o servicios de terceros. Explore servicios y características de AWS como AWS Secrets Manager y autenticación de IAM de AWS Identity and Access Management.
Cuando llegue a este punto, debería conocer los procedimientos y las prácticas recomendadas para ejecutar pruebas de referencia con Aurora. Puede darse el caso de que necesite realizar un ajuste adicional del rendimiento. Para obtener información detallada, consulteAdministración del rendimiento y el escalado para clústeres de base de datos Aurora, Mejoras del rendimiento de Amazon Aurora MySQL, Rendimiento y escalado para Amazon Aurora PostgreSQL y Monitoreo de la carga de base de datos con Performance Insights en Amazon Aurora. Si realiza un ajuste adicional, tiene que estar familiarizado con las métricas que ha recopilado durante la prueba de concepto. En un paso siguiente, podría tener que crear clústeres nuevos con opciones diferentes para los ajustes de configuración, el motor de base de datos y la versión de la base de datos. O bien, podría tener que crear tipos especializados de clústeres de Aurora para adaptarse a las necesidades de casos de uso específicos.
Por ejemplo, puede explorar clústeres de consulta en paralelo de Aurora para aplicaciones de procesamiento de transacciones híbridas o procesamiento analítico (HTAP). Si una distribución geográfica extensa es fundamental para la recuperación de desastres o para minimizar la latencia, puede explorar bases de datos globales de Aurora. Si su carga de trabajo es intermitente o utiliza Aurora en un escenario de desarrollo y prueba, puede explorar clústeres de Aurora Serverless.
Sus clústeres de producción también podrán necesitar grandes volúmenes de conexiones de entrada. Para aprender dichas técnicas, consulte el documento técnico de AWS del manual de administrador de base de datos de Aurora MySQL: administración de conexiones
Si, después de la prueba de concepto, decide que su caso de uso no es adecuado para Aurora, considere los siguientes servicios de:AWS
-
Para casos de uso puramente analíticos, las cargas de trabajo se benefician de un formato de almacenamiento en columna y otras características más adecuadas para las cargas de trabajo OLAP. Los servicios de AWS que abordan tales casos de uso incluyen los siguientes:
-
Muchas cargas de trabajo disponen de una combinación de Aurora con uno o varios de estos servicios. Puede mover datos entre estos servicios con los siguientes productos:
-
Importación desde Amazon S3, tal y como se describe en la Guía del usuario de Amazon Aurora .
-
Exportación a Amazon S3, tal y como se describe en la Guía del usuario de Amazon Aurora.
-
Numerosas herramientas ETL conocidas más.
