Diseño del esquema del sistema de administración de reclamaciones en DynamoDB
Caso de uso empresarial del sistema de administración de reclamaciones
DynamoDB es una base de datos muy adecuada para el caso de uso de un sistema de administración de reclamaciones (o un centro de contacto), ya que la mayoría de los patrones de acceso asociados a ellos serían búsquedas transaccionales basadas en clave-valor. Los patrones de acceso típicos en este escenario serían:
-
Crear y actualizar reclamaciones
-
Escalar una reclamación
-
Crear y leer comentarios sobre una reclamación
-
Obtener todas las reclamaciones de un cliente
-
Obtener todos los comentarios de un agente y obtener todos los escalados
Algunos comentarios pueden llevar asociada una descripción de la reclamación o de la solución. Aunque todos estos son patrones de acceso de clave-valor, puede haber requisitos adicionales como el envío de notificaciones cuando se agrega un nuevo comentario a una reclamación o la ejecución de consultas analíticas para hallar la distribución de reclamaciones por gravedad (o el rendimiento de los agentes) por semana. Un requisito adicional relacionado con la administración del ciclo de vida o el cumplimiento de la normativa sería archivar los datos de la reclamación transcurridos tres años desde su registro.
Diagrama de arquitectura del sistema de administración de reclamaciones
A continuación, se muestra el diagrama de arquitectura del sistema de administración de reclamaciones. Este diagrama muestra las diferentes integraciones de Servicio de AWS que utiliza el sistema de administración de reclamaciones.
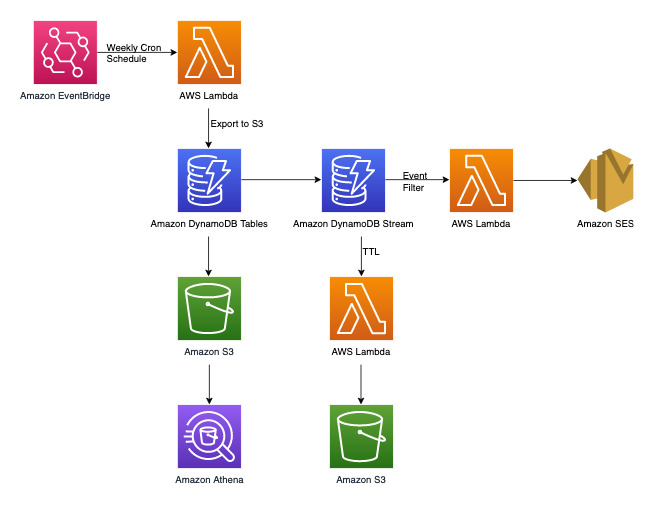
Aparte de los patrones de acceso transaccional de clave-valor que trataremos más adelante en la sección de modelado de datos de DynamoDB, tenemos tres requisitos no transaccionales. El diagrama de arquitectura anterior puede desglosarse en los tres flujos de trabajo siguientes:
-
Enviar una notificación cuando se agregue un nuevo comentario a una reclamación
-
Ejecutar consultas analíticas sobre los datos semanales
-
Archivar datos de más de tres años
Echemos un vistazo más a fondo a cada una de ellas.
Enviar una notificación cuando se agregue un nuevo comentario a una reclamación
Podemos utilizar el siguiente flujo de trabajo para cumplir este requisito:

DynamoDB Streams es un mecanismo de captura de datos de cambios para registrar toda la actividad de escritura en sus tablas de DynamoDB. Puede configurar funciones de Lambda para desencadenar algunos o todos estos cambios. Se puede configurar un filtro de eventos en los desencadenadores de Lambda para filtrar los eventos que no sean pertinentes para el caso de uso. En este caso, podemos utilizar un filtro para desencadenar Lambda solo cuando se agregue un nuevo comentario y enviar una notificación a los ID de correo electrónico pertinentes, que pueden obtenerse de AWS Secrets Manager o de cualquier otro almacén de credenciales.
Ejecutar consultas analíticas sobre los datos semanales
DynamoDB es adecuado para cargas de trabajo centradas principalmente en el procesamiento transaccional en línea (OLTP). Para el otro 10 % a 20 % de patrones de acceso con requisitos analíticos, los datos pueden exportarse a S3 con la característica administrada Exportar a Amazon S3 sin impacto en el tráfico en directo de la tabla de DynamoDB. Examinemos este flujo de trabajo:
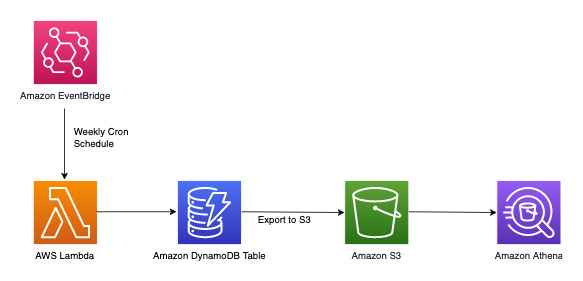
Amazon EventBridge puede utilizarse para desencadenar AWS Lambda de forma programada: permite configurar una expresión cron para que la invocación de Lambda tenga lugar periódicamente. Lambda puede invocar la llamada a la API ExportToS3 y almacenar los datos de DynamoDB en S3. A continuación, un motor SQL como Amazon Athena puede acceder a estos datos de S3 para ejecutar consultas analíticas en los datos de DynamoDB sin que se vea afectada la carga de trabajo transaccional en directo de la tabla. Un ejemplo de consulta de Athena para hallar el número de reclamaciones por nivel de gravedad tendría el siguiente aspecto:
SELECT Item.severity.S as "Severity", COUNT(Item) as "Count" FROM "complaint_management"."data" WHERE NOT Item.severity.S = '' GROUP BY Item.severity.S ;
Esto da como resultado la siguiente consulta de Athena:

Archivar datos de más de tres años
Puede aprovechar la característica Tiempo de vida (TTL) de DynamoDB para eliminar datos obsoletos de su tabla de DynamoDB sin costo adicional (excepto en el caso de las réplicas de tablas globales para la versión 2019.11.21 (actual), donde las eliminaciones TTL replicadas a otras regiones consumen capacidad de escritura). Estos datos aparecen y se pueden consumir desde DynamoDB Streams para archivarse en Amazon S3. El flujo de trabajo para este requisito es el siguiente:

Diagrama de relaciones entre entidades del sistema de administración de reclamaciones
Este es el diagrama de relaciones entre entidades (ERD) que utilizaremos para el diseño del esquema del sistema de administración de reclamaciones.

Patrones de acceso al sistema de administración de reclamaciones
Estos son los patrones de acceso que tendremos en cuenta para el diseño del esquema de administración de reclamaciones.
-
createComplaint
-
updateComplaint
-
updateSeveritybyComplaintID
-
getComplaintByComplaintID
-
addCommentByComplaintID
-
getAllCommentsByComplaintID
-
getLatestCommentByComplaintID
-
getAComplaintbyCustomerIDAndComplaintID
-
getAllComplaintsByCustomerID
-
escalateComplaintByComplaintID
-
getAllEscalatedComplaints
-
getEscalatedComplaintsByAgentID (orden de más reciente a más antiguo)
-
getCommentsByAgentID (entre dos fechas)
Evolución del diseño del esquema del sistema de administración de reclamaciones
Al tratarse de un sistema de administración de reclamaciones, la mayoría de los patrones de acceso giran en torno a la reclamación como entidad principal. El valor de ComplaintID, al ser altamente cardinal, garantizará una distribución uniforme de los datos en las particiones subyacentes y es también el criterio de búsqueda más común para nuestros patrones de acceso identificados. Por lo tanto, ComplaintID es una buena candidata a clave de partición en este conjunto de datos.
Paso 1: Abordar los patrones de acceso 1 (createComplaint), 2 (updateComplaint), 3 (updateSeveritybyComplaintID) y 4 (getComplaintByComplaintID)
Podemos utilizar una clave de clasificación genérica valorada como “metadatos” (o “AA”) para almacenar información específica de la reclamación como CustomerID, State, Severity y CreationDate. Utilizamos operaciones singleton con PK=ComplaintID y SK=“metadata” para hacer lo siguiente:
-
PutItempara crear una nueva reclamación -
UpdateItempara actualizar la gravedad u otros campos de los metadatos de la reclamación -
GetItempara obtener los metadatos de la reclamación

Paso 2: Abordar el patrón de acceso 5 (addCommentByComplaintID)
Este patrón de acceso requiere un modelo de relación de uno a varios entre una reclamación y los comentarios sobre ella. Aquí utilizaremos la técnica de partición vertical para utilizar una clave de clasificación y crear una colección de elementos con distintos tipos de datos. Si observamos los patrones de acceso 6 (getAllCommentsByComplaintID) y 7 (getLatestCommentByComplaintID), sabremos que los comentarios deberán ordenarse por tiempo. También podemos tener varios comentarios que lleguen al mismo tiempo, por lo que podemos utilizar la técnica de clave de clasificación compuesta para agregar la hora y CommentID en el atributo de clave de clasificación.
Otras opciones para tratar estas posibles colisiones de comentarios serían aumentar la granularidad para la marca de tiempo o agregar un número incremental como sufijo en lugar de utilizar Comment_ID. En este caso, antepondremos el prefijo “comm#” al valor de la clave de clasificación de los elementos correspondientes a comentarios para permitir operaciones basadas en intervalos.
También tenemos que asegurarnos de que currentState en los metadatos de la reclamación refleja el estado cuando se agrega un nuevo comentario. Agregar un comentario puede indicar que la reclamación se ha asignado a un agente o que se ha resuelto, etc. Para agrupar la adición de comentarios y la actualización del estado actual en los metadatos de la reclamación, de forma que todo sea posible, utilizaremos la API TransactWriteItems. El estado de la tabla resultante tiene ahora este aspecto:

Vamos a agregar algunos datos más en la tabla y también agregar ComplaintID como un campo separado de nuestro PK para preparar el modelo para el futuro en caso de que necesitemos índices adicionales en ComplaintID. Tenga en cuenta también que algunos comentarios pueden tener archivos adjuntos que almacenaremos en Amazon Simple Storage Service y solo mantendremos sus referencias o URL en DynamoDB. Se recomienda mantener la base de datos transaccional lo más reducida posible para optimizar los costos y el rendimiento. Los datos ahora tienen este aspecto:
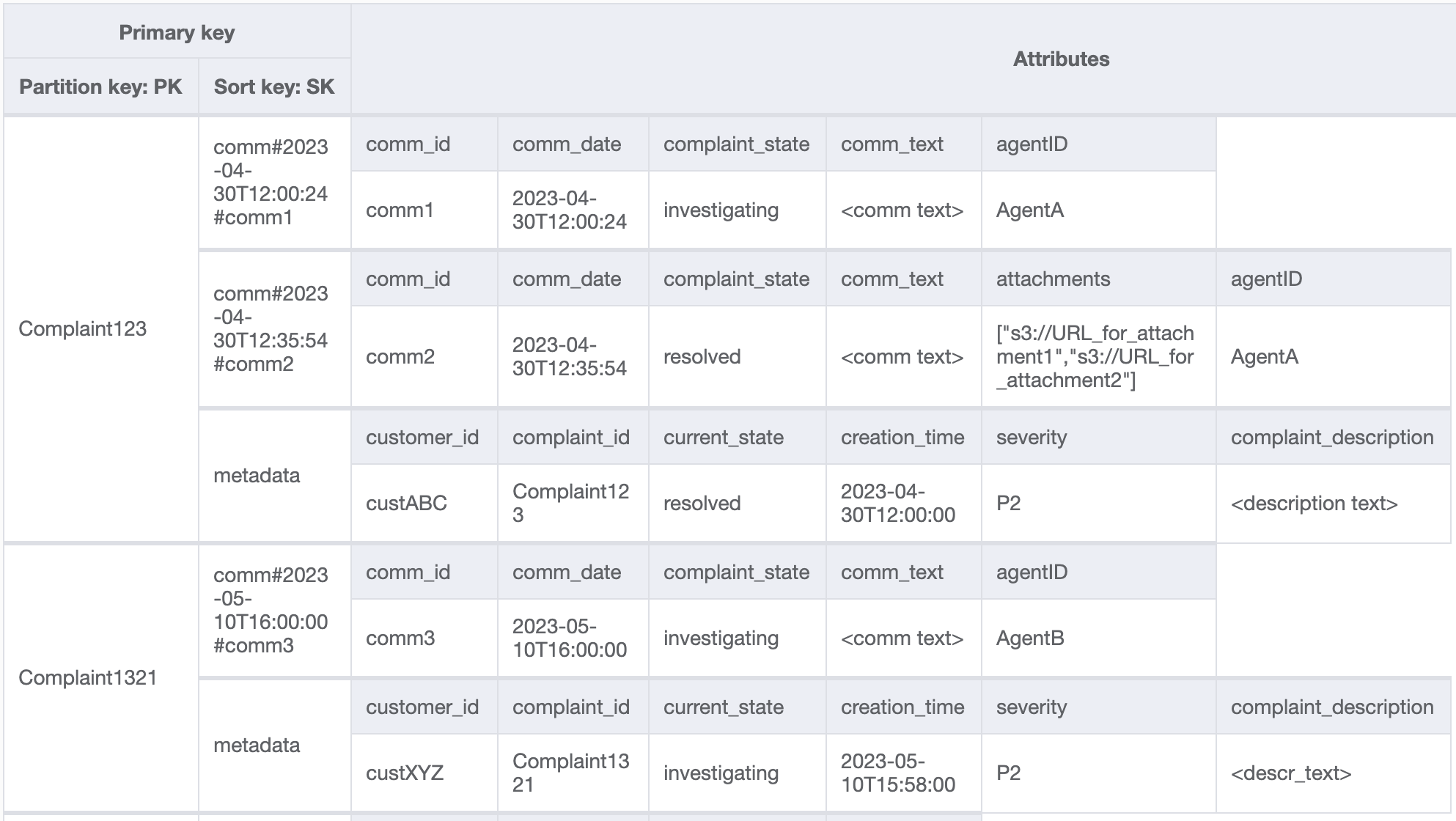
Paso 3: Abordar patrones de acceso 6 (getAllCommentsByComplaintID) y 7 (getLatestCommentByComplaintID)
Para obtener todos los comentarios de una reclamación, podemos utilizar la operación query con la condición begins_with en la clave de clasificación. En lugar de consumir capacidad de lectura adicional para leer la entrada de metadatos y, a continuación, tener la sobrecarga de filtrar los resultados relevantes, tener una condición de clave de clasificación como esta nos ayuda a leer solo lo que necesitamos. Por ejemplo, una operación de consulta con PK=Complaint123 y SK begins_with comm# devolvería lo siguiente al mismo tiempo que omitiría la entrada de metadatos:

Puesto que necesitamos el último comentario de una reclamación en el patrón 7 (getLatestCommentByComplaintID), vamos a utilizar dos parámetros de consulta adicionales:
-
ScanIndexForwarddebe configurarse en False para que los resultados se ordenen en orden descendente -
Limitdebe configurarse en 1 para obtener el último comentario (solo uno)
De forma similar al patrón de acceso 6 (getAllCommentsByComplaintID), omitimos la entrada de metadatos mediante begins_with comm# como la condición de clave de clasificación. Ahora, puede realizar el patrón de acceso 7 en este diseño mediante la operación de consulta con PK=Complaint123 y SK=begins_with comm#, ScanIndexForward=False y Limit 1. Como resultado se devolverá el siguiente elemento objetivo:

Agreguemos más datos ficticios a la tabla.
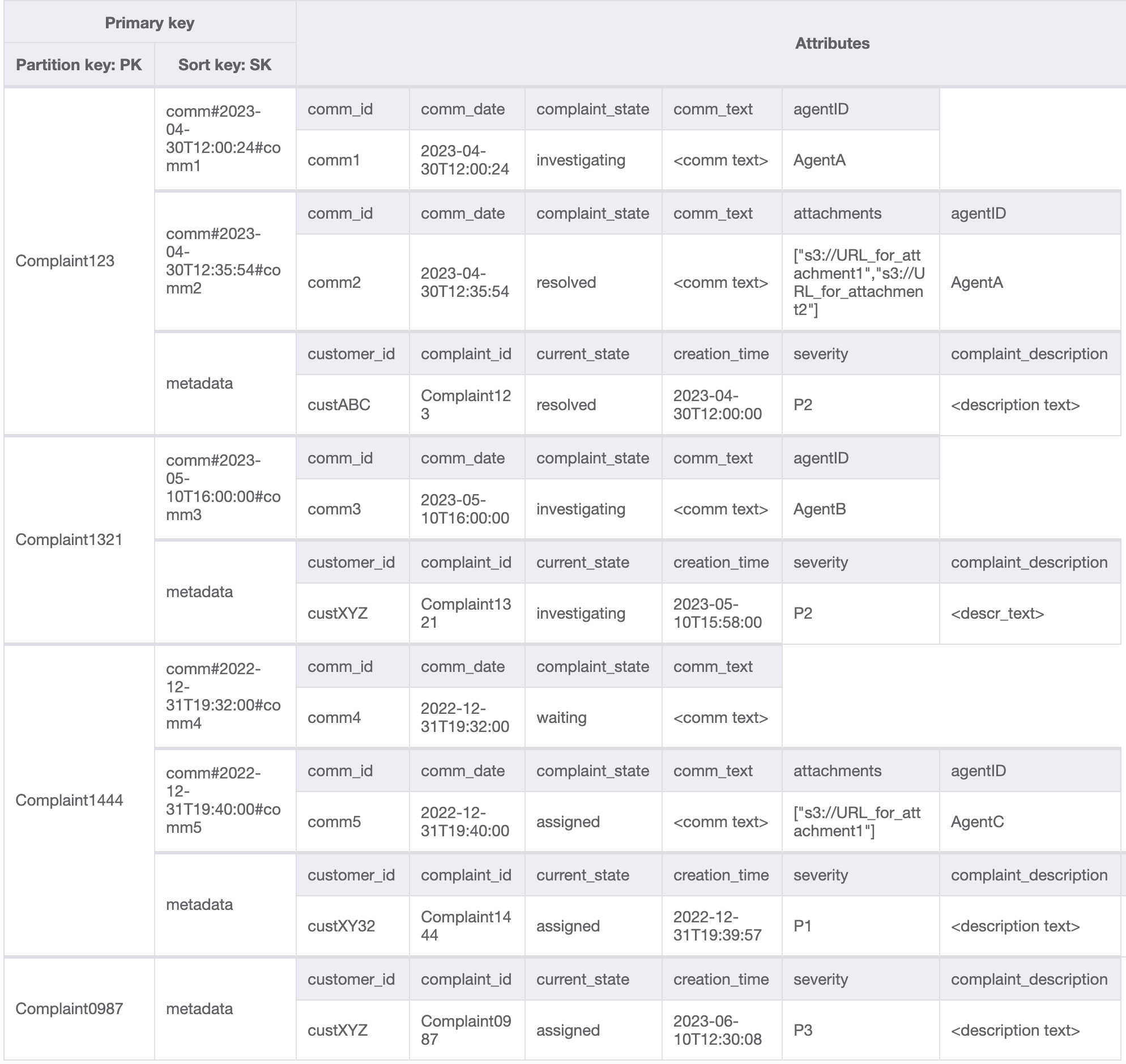
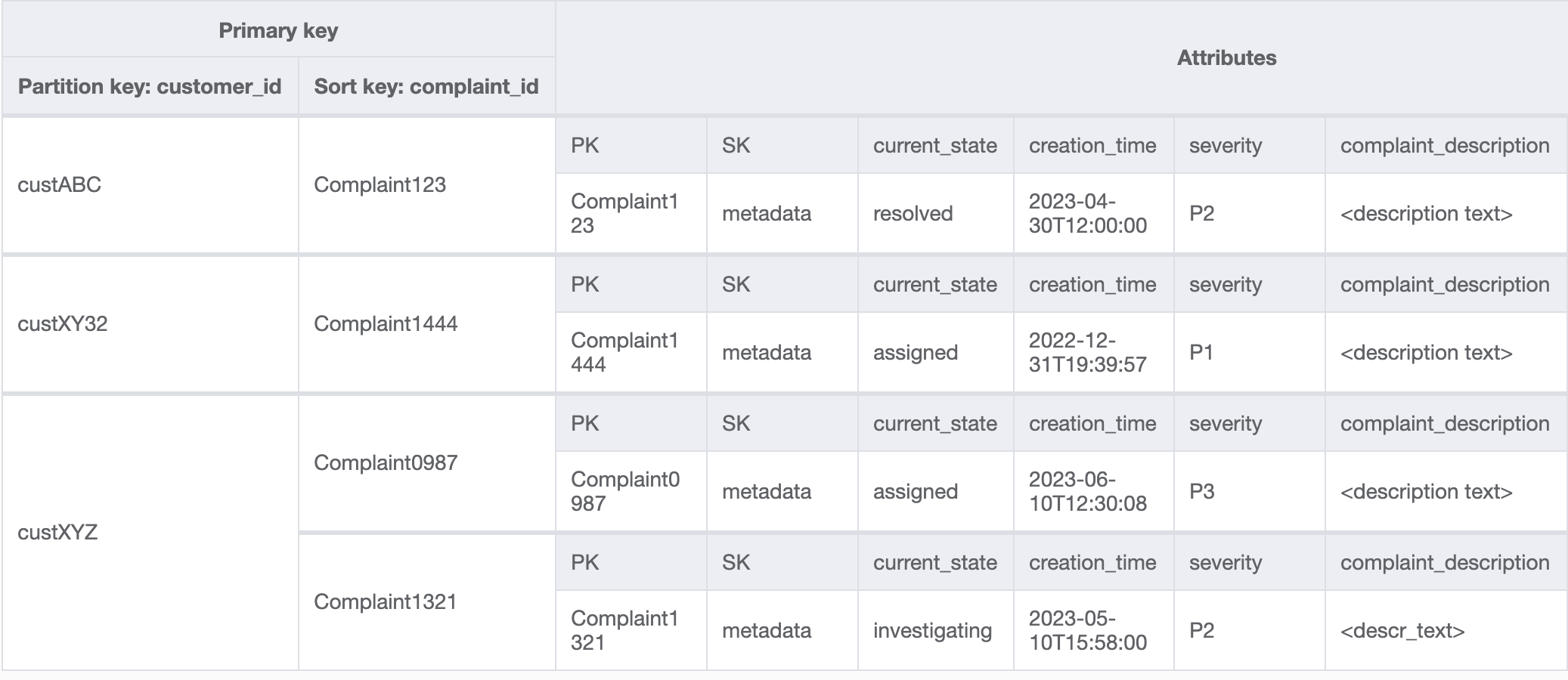
Paso 4: Abordar patrones de acceso 8 (getAComplaintbyCustomerIDAndComplaintID) y 9 (getAllComplaintsByCustomerID)
El acceso a los patrones 8 (getAComplaintbyCustomerIDAndComplaintID) y 9 (getAllComplaintsByCustomerID) presenta un nuevo criterio de búsqueda: CustomerID. Recuperarlo de la tabla existente requiere un proceso Scan costoso de lectura de todos los datos y, a continuación, filtrar los elementos relevantes para CustomerID en cuestión. Podemos hacer que esta búsqueda sea más eficaz mediante la creación de un índice secundario global (GSI) con CustomerID como clave de partición. Teniendo en cuenta la relación de uno a varios entre cliente y reclamaciones, así como el patrón de acceso 9 (getAllComplaintsByCustomerID), ComplaintID sería el candidato adecuado para la clave de clasificación.
Los datos del GSI tendrían este aspecto:
Un ejemplo de consulta en este GSI para el patrón de acceso 8 (getAComplaintbyCustomerIDAndComplaintID) sería: customer_id=custXYZ, sort key=Complaint1321. El resultado sería:

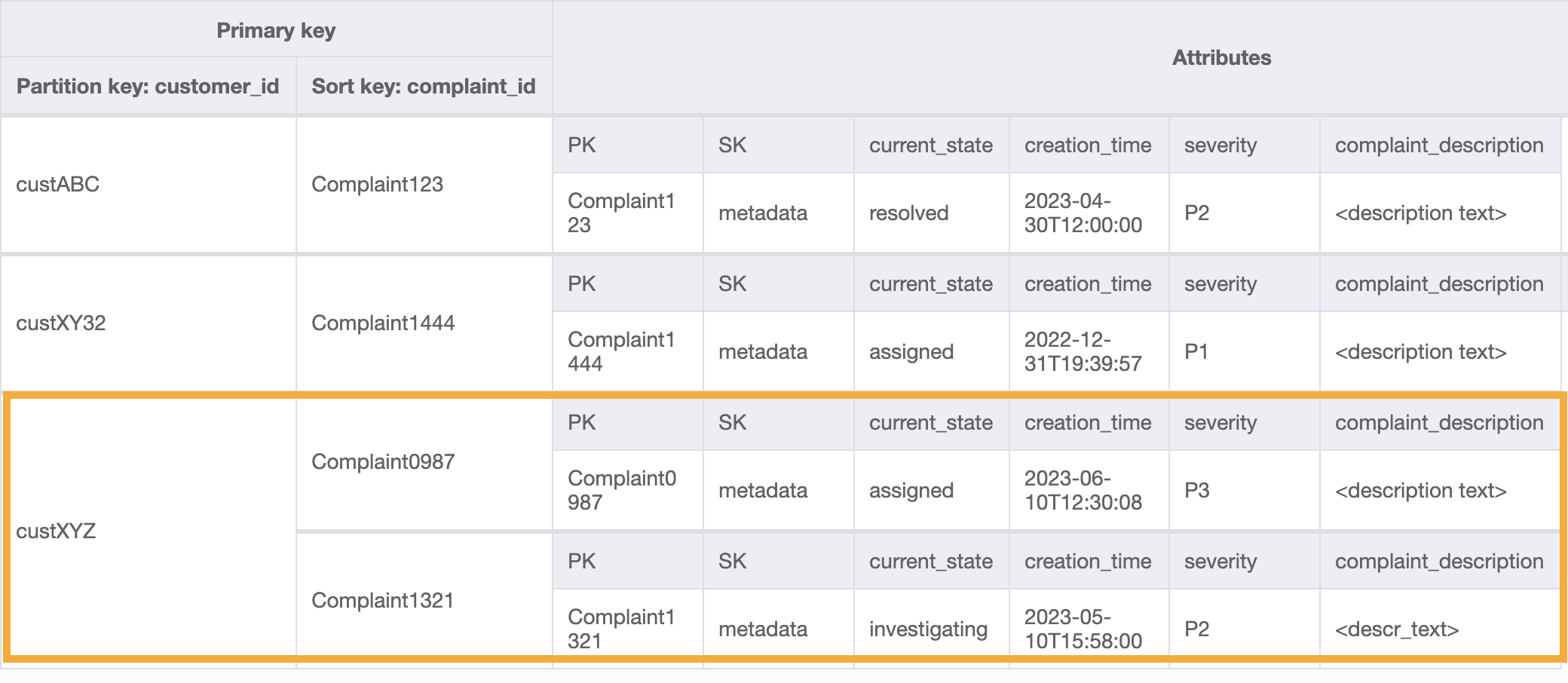
Para obtener todas las reclamaciones de un cliente para el patrón de acceso 9 (getAllComplaintsByCustomerID), la consulta del GSI sería: customer_id=custXYZ como condición de clave de partición. El resultado sería:
Paso 5: Abordar el patrón de acceso 10 (escalateComplaintByComplaintID)
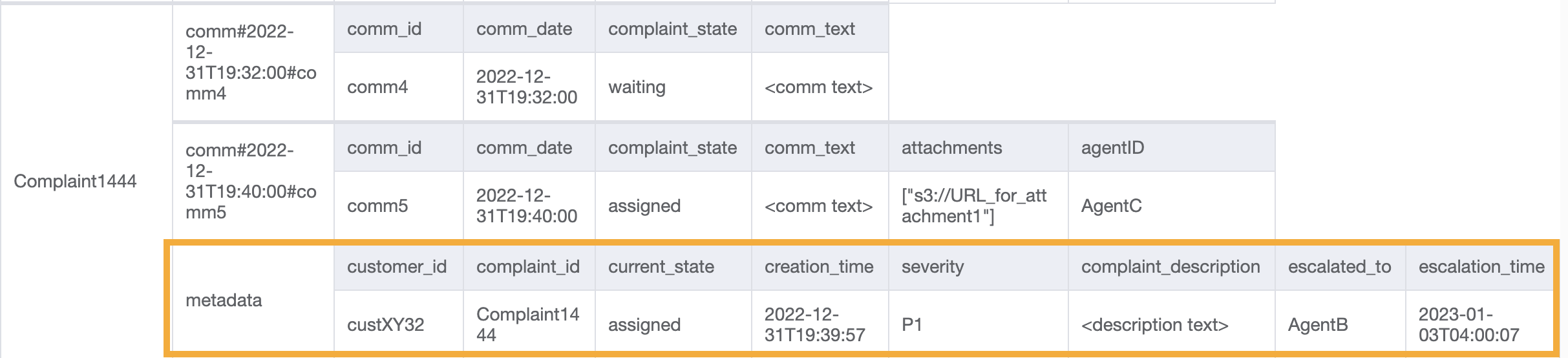
Este acceso introduce el aspecto de escalado. Para escalar una reclamación, podemos utilizar UpdateItem para agregar atributos como escalated_to y escalation_time al elemento de metadatos de reclamación existente. DynamoDB proporciona un diseño de esquema flexible, lo que significa que un conjunto de atributos no clave puede ser uniforme o discreto en diferentes elementos. Consulte a continuación un ejemplo:
UpdateItem with PK=Complaint1444, SK=metadata
Paso 6: Abordar patrones de acceso 11 (getAllEscalatedComplaints) y 12 (getEscalatedComplaintsByAgentID)
De todo el conjunto de datos, solo se espera que se escalen unas pocas reclamaciones. Por lo tanto, la creación de un índice sobre los atributos relacionados con el escalado conduciría a búsquedas eficientes, así como a un almacenamiento de GSI rentable. Podemos hacerlo aprovechando la técnica del índice disperso. El GSI con clave de partición como escalated_to y clave de clasificación como escalation_time tendría el siguiente aspecto:

Para obtener todas las reclamaciones escaladas para el patrón de acceso 11 (getAllEscalatedComplaints), simplemente escaneamos este GSI. Tenga en cuenta que esta escaneo será eficaz y rentable debido al tamaño del GSI. Para obtener reclamaciones escaladas para un agente específico (patrón de acceso 12 [getEscalatedComplaintsByAgentID]), la clave de partición sería escalated_to=agentID y establecemos ScanIndexForward aFalse para ordenar de más reciente a más antiguo.
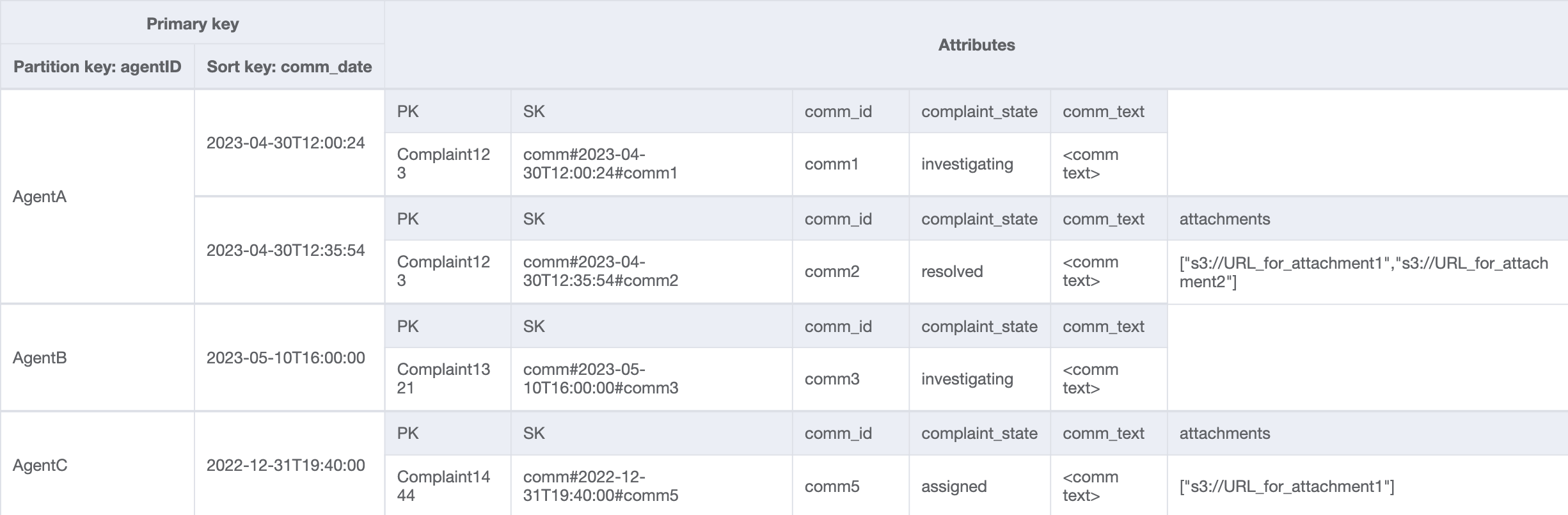
Paso 7: Abordar el patrón de acceso 13 (getCommentsByAgentID)
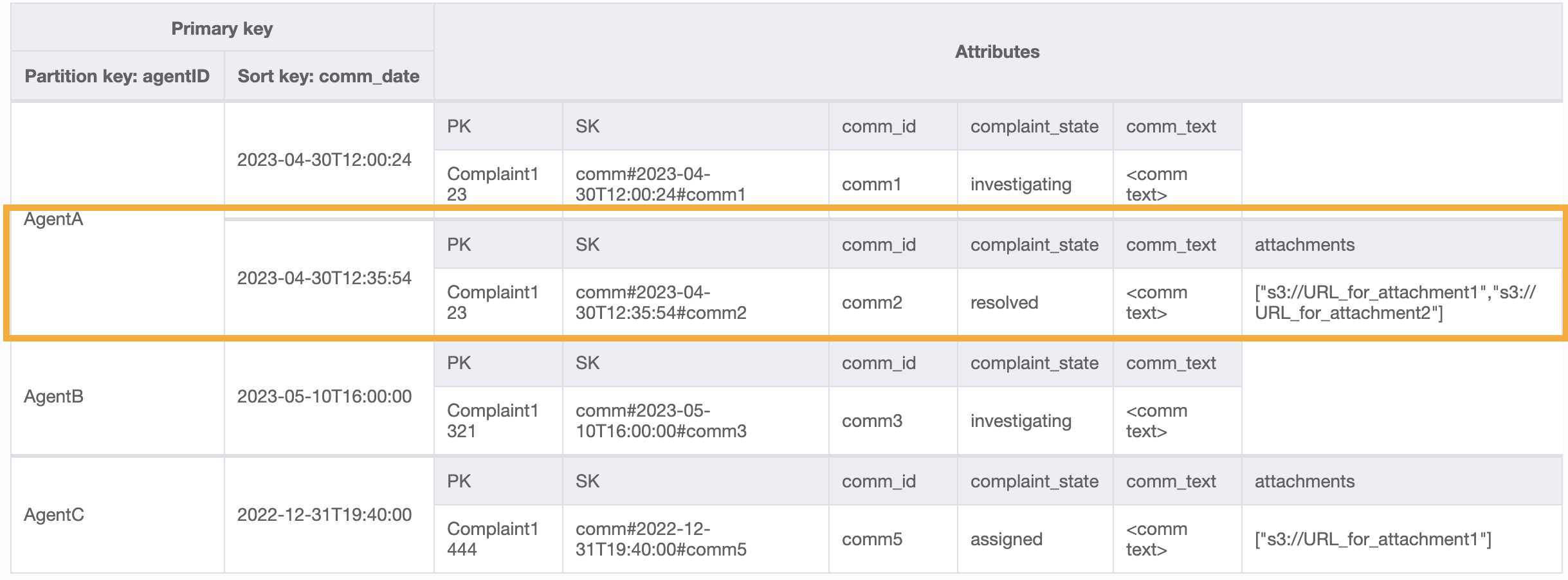
Para el último patrón de acceso, necesitamos realizar una búsqueda por una nueva dimensión: AgentID. También necesitamos una ordenación basada en el tiempo para leer los comentarios entre dos fechas, así que creamos un GSI con agent_id como la clave de partición y comm_date como la clave de clasificación. Los datos de este GSI tendrán el siguiente aspecto:

Un ejemplo de consulta en este GSI sería partition key agentID=AgentA y sort key=comm_date between (2023-04-30T12:30:00, 2023-05-01T09:00:00), cuyo resultado es:
En la tabla siguiente se resumen todos los patrones de acceso y cómo los aborda el diseño del esquema:
| Patrón de acceso | Tabla base/GSI/LSI | Operación | Valor de clave de partición | Valor de la clave de clasificación | Otras condiciones/filtros |
|---|---|---|---|---|---|
| createComplaint | Tabla base | PutItem | PK=complaint_id | SK=metadata | |
| updateComplaint | Tabla base | UpdateItem | PK=complaint_id | SK=metadata | |
| updateSeveritybyComplaintID | Tabla base | UpdateItem | PK=complaint_id | SK=metadata | |
| getComplaintByComplaintID | Tabla de base | GetItem | PK=complaint_id | SK=metadata | |
| addCommentByComplaintID | Tabla base | TransactWriteItems | PK=complaint_id | SK=metadata, SK=comm#comm_date#comm_id | |
| getAllCommentsByComplaintID | Tabla base | Consultar | PK=complaint_id | SK begins_with “comm#” | |
| getLatestCommentByComplaintID | Tabla base | Consultar | PK=complaint_id | SK begins_with “comm#” | scan_index_forward=False, Limit 1 |
| getAComplaintbyCustomerIDAndComplaintID | Customer_complaint_GSI | Consultar | customer_id=customer_id | complaint_id = complaint_id | |
| getAllComplaintsByCustomerID | Customer_complaint_GSI | Consultar | customer_id=customer_id | N/A | |
| escalateComplaintByComplaintID | Tabla base | UpdateItem | PK=complaint_id | SK=metadata | |
| getAllEscalatedComplaints | Escalations_GSI | Examen | N/A | N/A | |
| getEscalatedComplaintsByAgentID (orden de más reciente a más antiguo) | Escalations_GSI | Consultar | escalated_to=agent_id | N/A | scan_index_forward=False |
| getCommentsByAgentID (entre dos fechas) | Agents_Comments_GSI | Consultar | agent_id=agent_id | SK entre (fecha1, fecha2) |
Esquema final del sistema de administración de reclamaciones
Estos son los diseños finales del esquema. Para descargar este diseño de esquema como un archivo JSON, consulte los ejemplos de DynamoDB
Tabla base

Customer_Complaint_GSI

Escalations_GSI

Agents_Comments_GSI
Uso de NoSQL Workbench con este diseño de esquema
Puede importar este esquema final en NoSQL Workbench, una herramienta visual que proporciona características de modelado de datos, visualización de datos y desarrollo de consultas para DynamoDB, a fin de explorar y editar más a fondo el nuevo proyecto. Para comenzar, siga estos pasos:
-
Descargue NoSQL Workbench. Para obtener más información, consulte Descargar NoSQL Workbench para DynamoDB.
-
Descargue el archivo de esquema JSON que se muestra anteriormente, que ya está en el formato de modelo NoSQL Workbench.
-
Importe el archivo de esquema JSON en NoSQL Workbench. Para obtener más información, consulte Importación de un modelo de datos existente.
-
Una vez que haya importado en NOSQL Workbench, podrá editar el modelo de datos. Para obtener más información, consulte Edición de un modelo de datos existente.
-
Para visualizar el modelo de datos, agregar datos de ejemplo o importar datos de ejemplo de un archivo CSV, utilice la característica Visualizador de datos de NoSQL Workbench.
