Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Tutorial: Introducción a Amazon EMR
Revise un flujo de trabajo para configurar rápidamente un clúster de Amazon EMR y ejecutar una aplicación de Spark.
Configuración del clúster de Amazon EMR
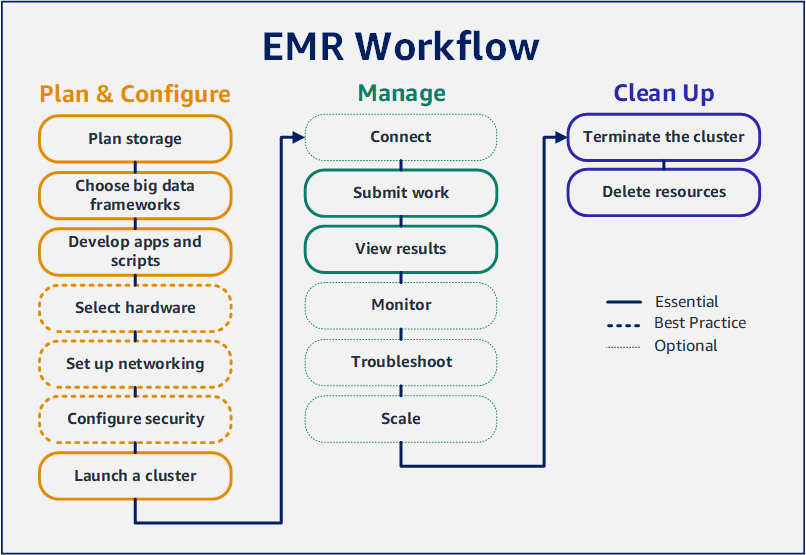
Amazon EMR, puede configurar un clúster para procesar y analizar datos con marcos de macrodatos en solo unos minutos. En este tutorial, se muestra cómo lanzar un clúster de muestra con Spark y cómo ejecutar un PySpark script sencillo almacenado en un bucket de Amazon S3. Cubre tareas esenciales de Amazon EMR en tres categorías principales de flujo de trabajo: planificación y configuración, administración y limpieza.
Encontrará enlaces a temas más detallados a medida que avance en el tutorial e ideas para pasos adicionales en la sección Pasos a seguir a continuación. Si tiene alguna pregunta o no sabe cómo continuar, contacte con el equipo de Amazon EMR en nuestro foro de discusión
Requisitos previos
-
Antes de lanzar un clúster de Amazon EMR, asegúrese de completar las tareas en Antes de configurar Amazon EMR.
Costo
-
El clúster de ejemplo que cree se ejecuta en un entorno real. El clúster genera unos gastos mínimos. Para evitar cargos adicionales, asegúrese de completar las tareas de limpieza del último paso de este tutorial. Los cargos se acumulan en virtud la tarifa por segundo según los precios de Amazon EMR. Los cargos también varían según la región. Para obtener más información, consulte Precios de Amazon EMR
. -
Es posible que se acumulen cargos mínimos por los archivos pequeños que almacene en Amazon S3. Es posible que no se apliquen algunos o todos los cargos de Amazon S3 si se encuentra dentro de los límites de uso de la capa AWS gratuita. Para obtener más información, consulte Precios de Amazon S3
y Nivel gratuito de AWS .
Paso 1: Configurar recursos de datos y lanzar un clúster de Amazon EMR
Prepare el almacenamiento para Amazon EMR
Cuando utiliza Amazon EMR, puede elegir entre una variedad de sistemas de archivos para almacenar los datos de entrada, los datos de salida y los archivos de registro. En este tutorial, utilizará EMRFS para almacenar datos en un bucket de S3. EMRFS es una implementación del sistema de archivos de Hadoop que le permite leer y escribir archivos normales en Amazon S3. Para obtener más información, consulte Trabajo con almacenamiento y sistemas de archivos con Amazon EMR.
Para crear un bucket para este tutorial, consulte Crear un bucket de S3 en la Guía del usuario de la consola de Amazon Simple Storage Service. Cree el bucket en la misma AWS región en la que planea lanzar su clúster de Amazon EMR. Por ejemplo, Oeste de EE. UU. (Oregón) us-west-2.
Los buckets y las carpetas que utilice con Amazon EMR tienen las siguientes limitaciones:
-
Los nombres pueden contener letras minúsculas, números, puntos (.) y guiones (-).
-
Los nombres no pueden terminar en números.
-
El nombre de un bucket debe ser único en todas las cuentas de AWS .
-
La carpeta de salida debe estar vacía.
Preparar una aplicación con datos de entrada para Amazon EMR
La forma más común de preparar una aplicación para Amazon EMR consiste en cargar la aplicación y sus datos de entrada en Amazon S3. A continuación, cuando envíe el trabajo a su clúster, especifique las ubicaciones de Amazon S3 para el script y los datos.
En este paso, debe cargar un PySpark script de muestra en su bucket de Amazon S3. Le proporcionamos un PySpark script para que lo utilice. El script procesa los datos de inspección del establecimiento de alimentos y devuelve un archivo de resultados en su bucket de S3. En el archivo de resultados se enumeran los diez establecimientos con más infracciones de tipo “rojo”.
También debe cargar datos de entrada de muestra en Amazon S3 para que el PySpark script los procese. Los datos de entrada son una versión modificada de los resultados de las inspecciones del Departamento de Salud en el condado de King (Washington) entre 2006 y 2020. Para obtener más información, consulte Datos abiertos del condado de King: datos de inspección de establecimientos alimentarios
name,inspection_result,inspection_closed_business,violation_type,violation_points 100 LB CLAM,Unsatisfactory,FALSE,BLUE,5 100 PERCENT NUTRICION,Unsatisfactory,FALSE,BLUE,5 7-ELEVEN #2361-39423A,Complete,FALSE,,0
Para preparar el PySpark script de ejemplo para EMR
-
Copie el siguiente código de muestra en un nuevo archivo en el editor que prefiera.
import argparse from pyspark.sql import SparkSession def calculate_red_violations(data_source, output_uri): """ Processes sample food establishment inspection data and queries the data to find the top 10 establishments with the most Red violations from 2006 to 2020. :param data_source: The URI of your food establishment data CSV, such as 's3://amzn-s3-demo-bucket/food-establishment-data.csv'. :param output_uri: The URI where output is written, such as 's3://amzn-s3-demo-bucket/restaurant_violation_results'. """ with SparkSession.builder.appName("Calculate Red Health Violations").getOrCreate() as spark: # Load the restaurant violation CSV data if data_source is not None: restaurants_df = spark.read.option("header", "true").csv(data_source) # Create an in-memory DataFrame to query restaurants_df.createOrReplaceTempView("restaurant_violations") # Create a DataFrame of the top 10 restaurants with the most Red violations top_red_violation_restaurants = spark.sql("""SELECT name, count(*) AS total_red_violations FROM restaurant_violations WHERE violation_type = 'RED' GROUP BY name ORDER BY total_red_violations DESC LIMIT 10""") # Write the results to the specified output URI top_red_violation_restaurants.write.option("header", "true").mode("overwrite").csv(output_uri) if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument( '--data_source', help="The URI for you CSV restaurant data, like an S3 bucket location.") parser.add_argument( '--output_uri', help="The URI where output is saved, like an S3 bucket location.") args = parser.parse_args() calculate_red_violations(args.data_source, args.output_uri) -
Guarde el archivo como
health_violations.py. -
Suba
health_violations.pya Amazon S3 en el bucket que creó para este tutorial. Para obtener instrucciones, consulte Cargar un objeto en un bucket en la Guía de introducción a Amazon Simple Storage Service.
Para preparar los datos de entrada de muestra para EMR
-
Descargue el archivo zip, food_establishment_data.zip.
-
Descomprima y guarde
food_establishment_data.zipcomofood_establishment_data.csven su máquina. -
Suba el archivo CSV en el bucket de S3 que creó para este tutorial. Para obtener instrucciones, consulte Cargar un objeto en un bucket en la Guía de introducción a Amazon Simple Storage Service.
Para obtener más información sobre cómo configurar los datos para EMR, consulte Preparación de los datos de entrada para su procesamiento con Amazon EMR.
Lanzar un clúster de Amazon EMR
Tras preparar la ubicación de almacenamiento y la aplicación, puede lanzar un clúster de muestra de Amazon EMR. En este paso, lanza un clúster de Apache Spark con la versión de Amazon EMR más reciente.
Paso 2: Enviar el trabajo a su clúster de Amazon EMR
Envío de trabajos y visualización de resultados
Después de lanzar un clúster, puede enviar el trabajo al clúster en ejecución para procesar y analizar los datos. El trabajo se envía a un clúster de Amazon EMR como un paso. Un paso es una unidad de trabajo compuesta por una o más acciones. Por ejemplo, puede enviar un paso para calcular valores o para transferir y procesar datos. Puede enviar pasos cuando al crear un clúster o bien a un clúster en ejecución. En este tutorial, envía health_violations.py como un paso a su clúster en ejecución. Para obtener más información sobre los pasos, consulte Envío del trabajo a un clúster de Amazon EMR.
Para obtener más información sobre el ciclo de vida del paso, consulte Ejecución de pasos para procesar datos.
Ver los resultados
Cuando un paso se ejecute correctamente, podrá ver los resultados de salida en la carpeta de salida de Amazon S3.
Para ver los resultados de health_violations.py
Abra la consola de Amazon S3 en https://console.aws.amazon.com/s3/
. -
Elija el nombre del bucket y, a continuación, la carpeta de salida que especificó al enviar el paso. Por ejemplo,
amzn-s3-demo-buckety luegomyOutputFolder. -
Compruebe que los siguientes elementos aparecen en la carpeta de salida:
-
Un objeto de tamaño pequeño llamado
_SUCCESS. -
Un archivo CSV que comienza con el prefijo
part-que contiene los resultados.
-
-
Elija el objeto con los resultados y, a continuación, seleccione Descargar para guardar los resultados en el sistema de archivos local.
-
Abra los resultados con el editor que prefiera. En el archivo de salida, se muestra una lista de los diez establecimientos de alimentación con más infracciones rojas. En el archivo de salida, también se muestra el número total de infracciones rojas de cada establecimiento.
A continuación se muestra un resultado de
health_violations.py.name, total_red_violations SUBWAY, 322 T-MOBILE PARK, 315 WHOLE FOODS MARKET, 299 PCC COMMUNITY MARKETS, 251 TACO TIME, 240 MCDONALD'S, 177 THAI GINGER, 153 SAFEWAY INC #1508, 143 TAQUERIA EL RINCONSITO, 134 HIMITSU TERIYAKI, 128
Para obtener más información sobre el resultado del clúster de Amazon EMR, consulte Cómo configurar una ubicación para la salida del clúster de Amazon EMR.
Cuando utiliza Amazon EMR, es posible que desee conectarse a un clúster en ejecución para leer los archivos de registro, depurar el clúster o utilizar herramientas de la CLI, como el intérprete de comandos de Spark. Amazon EMR le permite conectarse a un clúster mediante el protocolo Secure Shell (SSH). En esta sección, se explica cómo configurar SSH, conectarse al clúster y ver los archivos de registro de Spark. Para obtener más información acerca de la conexión al clúster, consulte Autenticación en nodos de clúster de Amazon EMR.
Autorizar las conexiones de SSH a su clúster
Antes de conectarse al clúster, debe modificar sus grupos de seguridad para autorizar las conexiones SSH entrantes. Los grupos EC2 de seguridad de Amazon actúan como firewalls virtuales para controlar el tráfico entrante y saliente del clúster. Cuando creó el clúster para este tutorial, Amazon EMR creó los siguientes grupos de seguridad en su nombre:
- ElasticMapReduce-maestro
-
El grupo de seguridad administrado por Amazon EMR, asociado al nodo principal. En un clúster de Amazon EMR, el nodo principal es una EC2 instancia de Amazon que administra el clúster.
- ElasticMapReduce-esclavo
-
El grupo de seguridad, asociado a los nodos secundarios y de tareas.
Conéctese a su clúster mediante el AWS CLI
Independientemente del sistema operativo, puede crear una conexión SSH a su clúster mediante la AWS CLI.
Para conectarse a su clúster y ver los archivos de registro mediante el AWS CLI
-
Use el comando siguiente para abrir una conexión SSH a su clúster.
<mykeypair.key>Sustitúyalo por la ruta completa y el nombre de archivo del archivo de key pair. Por ejemplo,C:\Users\<username>\.ssh\mykeypair.pem.aws emr ssh --cluster-id<j-2AL4XXXXXX5T9>--key-pair-file<~/mykeypair.key> -
Navegue hasta
/mnt/var/log/sparkpara acceder a los registros de Spark en el nodo maestro del clúster. A continuación, consulte los archivos de esa ubicación. Para obtener una lista de los archivos de registro adicionales del nodo maestro, consulte Ver archivos de registro en el nodo principal.cd /mnt/var/log/spark ls
Amazon EMR on también EC2 es un tipo de procesamiento compatible con Amazon SageMaker AI Unified Studio. Consulte Administración de Amazon EMR EC2 para saber cómo usar y administrar EMR en los EC2 recursos de Unified Studio. Amazon SageMaker AI
Paso 3: eliminar los recursos de Amazon EMR
Terminar su clúster
Ahora que ha enviado el trabajo a su clúster y ha visto los resultados de su PySpark solicitud, puede cancelar el clúster. Al terminar un clúster, se detienen todos los cargos de Amazon EMR y las instancias de Amazon asociados al clúster. EC2
Al terminar un clúster, Amazon EMR conserva los metadatos del clúster durante dos meses sin costo alguno. Los metadatos archivados le ayudan a clonar el clúster para un nuevo trabajo o a revisitar la configuración del clúster como referencia. Los metadatos no incluyen los datos que el clúster escribe en S3 ni los datos almacenados en el HDFS del clúster.
nota
La consola de Amazon EMR no le permite eliminar un clúster de la vista de lista una vez terminado el clúster. Un clúster terminado desaparece de la consola cuando Amazon EMR borra sus metadatos.
Eliminar recursos de S3
Para evitar cargos adicionales, debe eliminar el bucket de Amazon S3. Al eliminar el bucket, se eliminan todos los recursos de Amazon S3 de este tutorial. El bucket debe contener:
-
El PySpark guion
-
El conjunto de datos de entrada
-
La carpeta de resultados de salida
-
La carpeta de archivos de registro
Puede que tenga que tomar medidas adicionales para eliminar los archivos almacenados si guardó el PySpark script o el resultado en una ubicación diferente.
nota
Debe terminar el clúster antes de eliminar el bucket. De lo contrario, es posible que no se le permita vaciar el bucket.
Para ello, siga las instrucciones de Eliminar un bucket de S3 en la Guía del usuario de Amazon Simple Storage Service.
Pasos a seguir a continuación
Ya ha lanzado su primer clúster de Amazon EMR de principio a fin. También ha completado tareas esenciales de EMR, como preparar y enviar aplicaciones de macrodatos, ver los resultados y terminar un clúster.
Utilice los siguientes temas para obtener más información sobre cómo personalizar el flujo de trabajo de Amazon EMR.
Explorar las aplicaciones de macrodatos para Amazon EMR
Descubra y compare las aplicaciones de macrodatos que puede instalar en un clúster en la Guía de publicación de Amazon EMR. La guía de versiones detalla cada versión de EMR e incluye consejos para usar marcos como Spark y Hadoop en Amazon EMR.
Planificar el hardware, las redes y la seguridad de los clústeres
En este tutorial, creó un clúster de EMR sencillo sin configurar las opciones avanzadas. Las opciones avanzadas le permiten especificar los tipos de EC2 instancias de Amazon, las redes de clústeres y la seguridad de los clústeres. Para obtener más información sobre la planificación y el lanzamiento de un clúster que cumpla sus requisitos, consulte Planificación, configuración y lanzamiento de clústeres de Amazon EMR y Seguridad en Amazon EMR.
Administrar clústeres
Profundice en el trabajo con clústeres en ejecución en Administración de clústeres de Amazon EMR. Para administrar un clúster, puede conectarse al clúster, depurar los pasos y hacer un seguimiento de las actividades y el estado del clúster. También puede ajustar los recursos del clúster en respuesta a las demandas de carga de trabajo con el escalado administrado por EMR.
Utilizar una interfaz diferente
Además de la consola Amazon EMR, puede gestionar Amazon EMR mediante la API del AWS Command Line Interface servicio web o una de las muchas compatibles. AWS SDKs Para obtener más información, consulte Interfaces de administración.
También puede interactuar con las aplicaciones instaladas en los clústeres de Amazon EMR de muchas maneras. Algunas aplicaciones, como Apache Hadoop, publican interfaces web que puede consultar. Para obtener más información, consulte Ver las interfaces web alojadas en clústeres de Amazon EMR.
Consultar el blog técnico de EMR
Para ver ejemplos de tutoriales y un análisis técnico detallado sobre las nuevas características de Amazon EMR, consulte el blog de macrodatos de AWS
