Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Optimizar el almacenamiento
Al actualizar o eliminar los datos de una tabla Iceberg, se aumenta el número de copias de los datos, como se muestra en el siguiente diagrama. Lo mismo ocurre con la compactación en ejecución: aumenta el número de copias de datos en Amazon S3. Esto se debe a que Iceberg trata los archivos subyacentes a todas las tablas como inmutables.
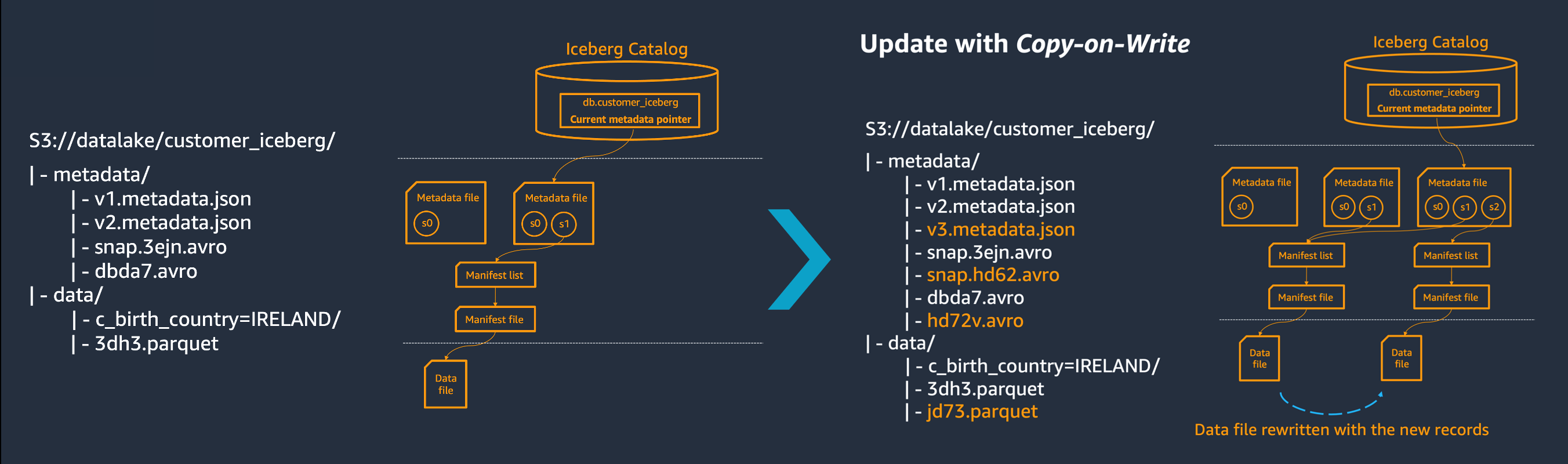
Siga las prácticas recomendadas de esta sección para gestionar los costes de almacenamiento.
Habilite S3 Intelligent-Tiering
Utilice la clase de almacenamiento Amazon S3 Intelligent-Tiering para mover automáticamente los datos al nivel de acceso más rentable cuando cambien los patrones de acceso. Esta opción no supone una sobrecarga operativa ni afecta al rendimiento.
Nota: No utilice los niveles opcionales (como Archive Access y Deep Archive Access) de S3 Intelligent-Tiering with Iceberg tables. Para archivar datos, consulte las directrices de la siguiente sección.
También puede usar las reglas del ciclo de vida de Amazon S3 para establecer sus propias reglas para mover objetos a otra clase de almacenamiento de Amazon S3, como S3 Standard-IA o S3 One Zone-IA (consulte Transiciones compatibles y restricciones relacionadas en la documentación de Amazon S3).
Archive o elimine las instantáneas históricas
Por cada transacción confirmada (inserción, actualización, combinación, compactación) en una tabla de Iceberg, se crea una nueva versión o instantánea de la tabla. Con el tiempo, el número de versiones y el número de archivos de metadatos de Amazon S3 se acumulan.
Es necesario conservar las instantáneas de una tabla para funciones como el aislamiento de las instantáneas, la reversión de tablas y las consultas sobre viajes en el tiempo. Sin embargo, los costes de almacenamiento aumentan con la cantidad de versiones que se conservan.
En la siguiente tabla se describen los patrones de diseño que puede implementar para administrar los costos en función de sus requisitos de retención de datos.
Patrón de diseño |
Solución |
Casos de uso |
|---|---|---|
Eliminar instantáneas antiguas |
|
Este enfoque elimina las instantáneas que ya no se necesitan para reducir los costos de almacenamiento. Puede configurar cuántas instantáneas deben conservarse o durante cuánto tiempo, en función de sus requisitos de retención de datos. Esta opción realiza una eliminación definitiva de las instantáneas. No puede revertir ni viajar en el tiempo a instantáneas caducadas. |
Establezca políticas de retención para instantáneas específicas |
|
Este patrón es útil para cumplir con los requisitos empresariales o legales que requieren que muestres el estado de una tabla en un momento dado del pasado. Al colocar políticas de retención en instantáneas etiquetadas específicas, puede eliminar otras instantáneas (sin etiquetar) que se hayan creado. De esta forma, puede cumplir con los requisitos de retención de datos sin conservar todas las instantáneas creadas. |
Archive las instantáneas antiguas |
Para obtener instrucciones detalladas, consulte la entrada del AWS blog Mejore la eficiencia operativa de las tablas Apache Iceberg basadas en los lagos de datos de Amazon S3
|
Este patrón le permite conservar todas las versiones e instantáneas de las tablas a un costo menor. No puede viajar en el tiempo ni volver a las instantáneas archivadas sin restaurar primero esas versiones como tablas nuevas. Esto suele ser aceptable para fines de auditoría. Puede combinar este enfoque con el patrón de diseño anterior y establecer políticas de retención para instantáneas específicas. |
Elimine los archivos huérfanos
En determinadas situaciones, las aplicaciones de Iceberg pueden fallar antes de que usted confirme sus transacciones. Esto deja los archivos de datos en Amazon S3. Como no se ha realizado ninguna confirmación, estos archivos no se asociarán a ninguna tabla, por lo que puede que tenga que limpiarlos de forma asíncrona.
Para gestionar estas eliminaciones, puede utilizar la declaración VACUUM en Amazon Athena. Esta declaración elimina las instantáneas y también elimina los archivos huérfanos. Esto resulta muy rentable, ya que Athena no cobra por el coste informático de esta operación. Además, no es necesario programar ninguna operación adicional al utilizar el VACUUM estado de cuenta.
Como alternativa, puedes usar Spark en Amazon EMR o AWS Glue para ejecutar el remove_orphan_files procedimiento. Esta operación tiene un coste informático y debe programarse de forma independiente. Para obtener más información, consulte la documentación de Iceberg
