Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Patrón de higo estrangulador
Intención
El patrón de higos estranguladores ayuda a migrar una aplicación monolítica a una arquitectura de microservicios de forma gradual, con un menor riesgo de transformación y una menor disrupción empresarial.
Motivación
Las aplicaciones monolíticas se desarrollan para proporcionar la mayor parte de sus funciones en un único proceso o contenedor. El código está estrechamente acoplado. Como resultado, los cambios en las aplicaciones requieren volver a realizar pruebas exhaustivas para evitar problemas de regresión. Los cambios no se pueden probar de forma aislada, lo que afecta a la duración del ciclo. A medida que la aplicación se enriquece con más funciones, la alta complejidad puede implicar más tiempo dedicado al mantenimiento, un aumento del tiempo de comercialización y, en consecuencia, una ralentización de la innovación de los productos.
Cuando la aplicación aumenta de tamaño, aumenta la carga cognitiva del equipo y puede provocar que los límites de propiedad del equipo no estén claros. No es posible escalar las funciones individuales en función de la carga; es necesario escalar toda la aplicación para soportar los picos de carga. A medida que los sistemas envejecen, la tecnología puede quedar obsoleta, lo que aumenta los costos de soporte. Las aplicaciones antiguas y monolíticas siguen las mejores prácticas que estaban disponibles en el momento del desarrollo y no se diseñaron para distribuirse.
Cuando una aplicación monolítica se migra a una arquitectura de microservicios, se puede dividir en componentes más pequeños. Estos componentes se pueden escalar de forma independiente, se pueden lanzar de forma independiente y pueden ser propiedad de equipos individuales. Esto se traduce en una mayor velocidad de cambio, ya que los cambios están localizados y se pueden probar y publicar rápidamente. Los cambios tienen un alcance de impacto menor porque los componentes están acoplados de forma flexible y se pueden implementar de forma individual.
Sustituir completamente un monolito por una aplicación de microservicios mediante la reescritura o la refactorización del código es una tarea enorme y un gran riesgo. Una migración a gran escala, en la que el monolito se migra en una sola operación, supone un riesgo de transformación y una disrupción empresarial. Mientras se refactoriza la aplicación, es extremadamente difícil o incluso imposible añadir nuevas funciones.
Una forma de resolver este problema es utilizar el patrón de higos estranguladores, que fue introducido por Martin Fowler. Este patrón implica pasar a los microservicios mediante la extracción gradual de funciones y la creación de una nueva aplicación en torno al sistema existente. Las funciones del monolito se sustituyen gradualmente por microservicios, y los usuarios de las aplicaciones pueden utilizar las funciones recién migradas de forma progresiva. Cuando todas las funciones se trasladen al nuevo sistema, la aplicación monolítica se podrá retirar de forma segura.
Aplicabilidad
Usa el patrón de higos estranguladores cuando:
-
Desea migrar su aplicación monolítica gradualmente a una arquitectura de microservicios.
-
Un enfoque de migración radical es riesgoso debido al tamaño y la complejidad del monolito.
-
La empresa quiere añadir nuevas funciones y no puede esperar a que se complete la transformación.
-
Los usuarios finales deben verse mínimamente afectados durante la transformación.
Problemas y consideraciones
-
Acceso a la base de código: para implementar el patrón de higos estranguladores, debe tener acceso a la base de código de la aplicación monolítica. A medida que se vayan migrando las funciones del monolito, tendrá que realizar pequeños cambios en el código e implementar una capa anticorrupción dentro del monolito para enrutar las llamadas a nuevos microservicios. No puede interceptar llamadas sin acceso a la base de código. El acceso a la base de código también es fundamental para redirigir las solicitudes entrantes; es posible que sea necesario refactorizar el código para que la capa proxy pueda interceptar las llamadas de las funciones migradas y enrutarlas a microservicios.
-
Dominio poco claro: la descomposición prematura de los sistemas puede resultar costosa, especialmente cuando el dominio no está claro y es posible definir mal los límites de los servicios. El diseño basado en dominios (DDD) es un mecanismo para entender el dominio, y la tormenta de eventos es una técnica para determinar los límites del dominio.
-
Identificación de microservicios: puede utilizar el DDD como una herramienta clave para identificar los microservicios. Para identificar los microservicios, busque las divisiones naturales entre las clases de servicios. Muchos servicios tendrán su propio objeto de acceso a los datos y se desacoplarán fácilmente. Los servicios que tienen una lógica empresarial relacionada y clases que no tienen dependencias o que tienen pocas dependencias son buenos candidatos para convertirse en microservicios. Puede refactorizar el código antes de descomponer el monolito para evitar un acoplamiento estrecho. También debes tener en cuenta los requisitos de conformidad, el ritmo de publicación, la ubicación geográfica de los equipos, las necesidades de ampliación, las necesidades tecnológicas basadas en casos de uso y la carga cognitiva de los equipos.
-
Capa anticorrupción: durante el proceso de migración, cuando las funciones del monolito tengan que llamar microservicios a las que se migraron, se debe implementar una capa anticorrupción (ACL) que dirija cada llamada al microservicio correspondiente. Con el fin de desvincular las llamadas existentes en el monolito y evitar que se produzcan cambios en ellas, la ACL funciona como un adaptador o una fachada que convierte las llamadas en una interfaz más nueva. Esto se analiza en detalle en la sección de implementación del patrón de ACL, que aparece anteriormente en esta guía.
-
Fallo en la capa proxy: durante la migración, una capa proxy intercepta las solicitudes que van a la aplicación monolítica y las dirige al sistema antiguo o al nuevo sistema. Sin embargo, esta capa proxy puede convertirse en un único punto de fallo o en un obstáculo en el rendimiento.
-
Complejidad de la aplicación: los monolitos de gran tamaño son los que más se benefician del diseño de higos estranguladores. En el caso de aplicaciones pequeñas, en las que la complejidad de una refactorización completa es baja, podría resultar más eficiente reescribir la aplicación en una arquitectura de microservicios en lugar de migrarla.
-
Interacciones de servicios: los microservicios se pueden comunicar de forma sincrónica o asíncrona. Cuando se requiera una comunicación sincrónica, considere si los tiempos de espera pueden provocar el consumo de conexiones o del grupo de subprocesos y provocar problemas de rendimiento de las aplicaciones. En esos casos, utilice el patrón de disyuntores para devolver el fallo inmediato en el caso de operaciones que puedan fallar durante períodos prolongados. La comunicación asíncrona se puede lograr mediante el uso de eventos y colas de mensajes.
-
Agregación de datos: en una arquitectura de microservicios, los datos se distribuyen en las bases de datos. Cuando sea necesaria la agregación de datos, se puede utilizar AWS AppSync
en la interfaz o el patrón de segregación de responsabilidades por consultas de comandos (CQRS) en el backend. -
Coherencia de los datos: los microservicios son propietarios de su almacén de datos y la aplicación monolítica también puede utilizar estos datos. Para permitir el uso compartido, puede sincronizar el almacén de datos de los nuevos microservicios con la base de datos de la aplicación monolítica mediante una cola y un agente. Sin embargo, esto puede provocar redundancia de datos y, finalmente, coherencia entre dos almacenes de datos, por lo que le recomendamos que lo trate como una solución táctica hasta que pueda establecer una solución a largo plazo, como un lago de datos.
Implementación
Siguiendo la pauta de la figura estranguladora, sustituyes una funcionalidad específica por un nuevo servicio o aplicación, componente por componente. Una capa proxy intercepta las solicitudes que van a la aplicación monolítica y las dirige al sistema antiguo o al nuevo sistema. Como la capa proxy dirige a los usuarios a la aplicación correcta, puede añadir funciones al nuevo sistema y, al mismo tiempo, garantizar que el monolito siga funcionando. Con el tiempo, el nuevo sistema sustituirá todas las funciones del sistema anterior y podrá retirarlo del servicio.
Arquitectura de alto nivel
En el siguiente diagrama, una aplicación monolítica tiene tres servicios: servicio de usuario, servicio de carrito y servicio de cuentas. El servicio de carrito depende del servicio de usuario y la aplicación utiliza una base de datos relacional monolítica.
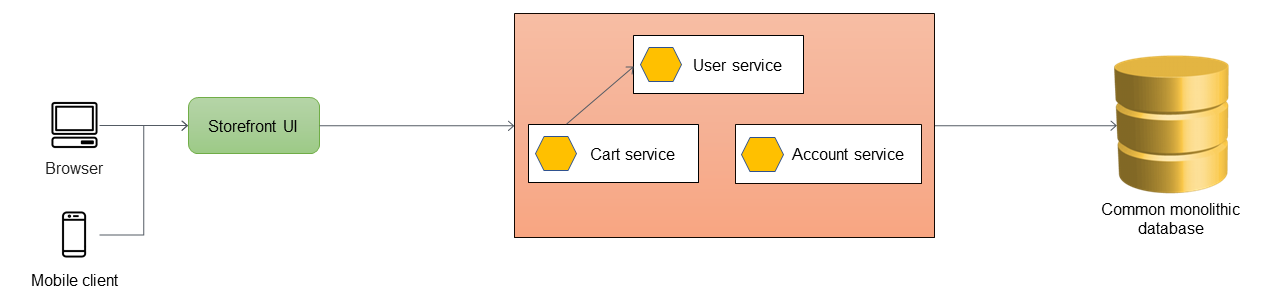
El primer paso es añadir una capa proxy entre la interfaz de usuario de la tienda y la aplicación monolítica. Al principio, el proxy enruta todo el tráfico a la aplicación monolítica.
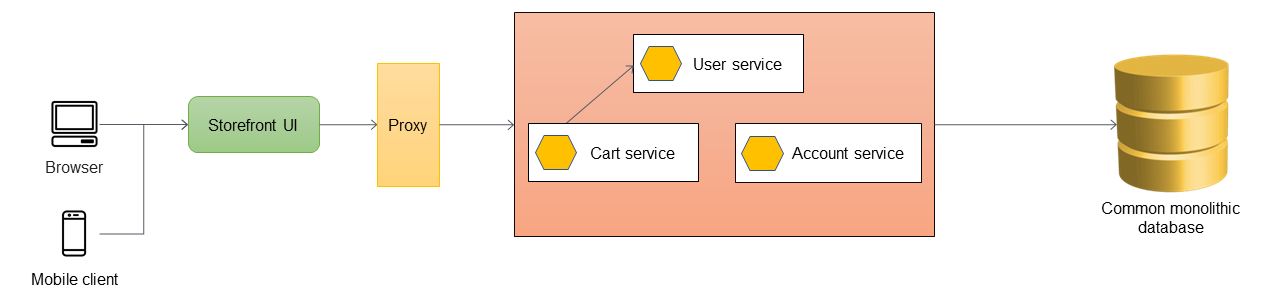
Cuando desee añadir nuevas funciones a su aplicación, debe implementarlas como nuevos microservicios en lugar de añadir funciones al monolito existente. Sin embargo, sigue corrigiendo errores en el monolito para garantizar la estabilidad de la aplicación. En el siguiente diagrama, la capa proxy enruta las llamadas al monolito o al nuevo microservicio en función de la URL de la API.
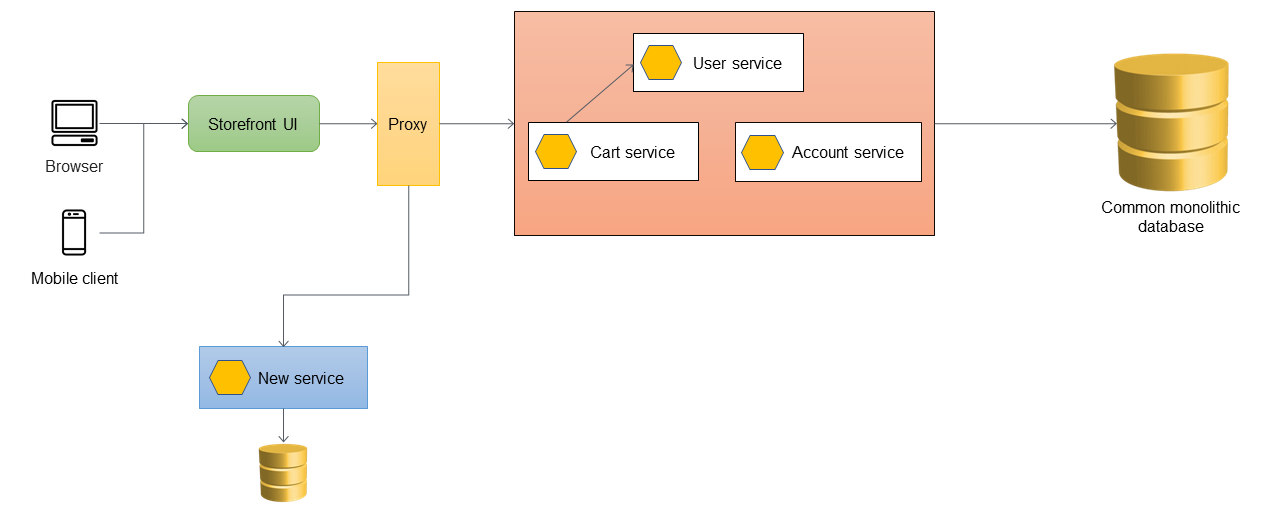
Añadir una capa anticorrupción
En la siguiente arquitectura, el servicio de usuario se ha migrado a un microservicio. El servicio de carrito llama al servicio de usuario, pero la implementación ya no está disponible en el monolito. Además, es posible que la interfaz del servicio recién migrado no coincida con la interfaz anterior de la aplicación monolítica. Para abordar estos cambios, debe implementar una ACL. Durante el proceso de migración, cuando las funciones del monolito necesitan llamar microservicios a las funciones que se migraron, la ACL convierte las llamadas a la nueva interfaz y las enruta al microservicio correspondiente.
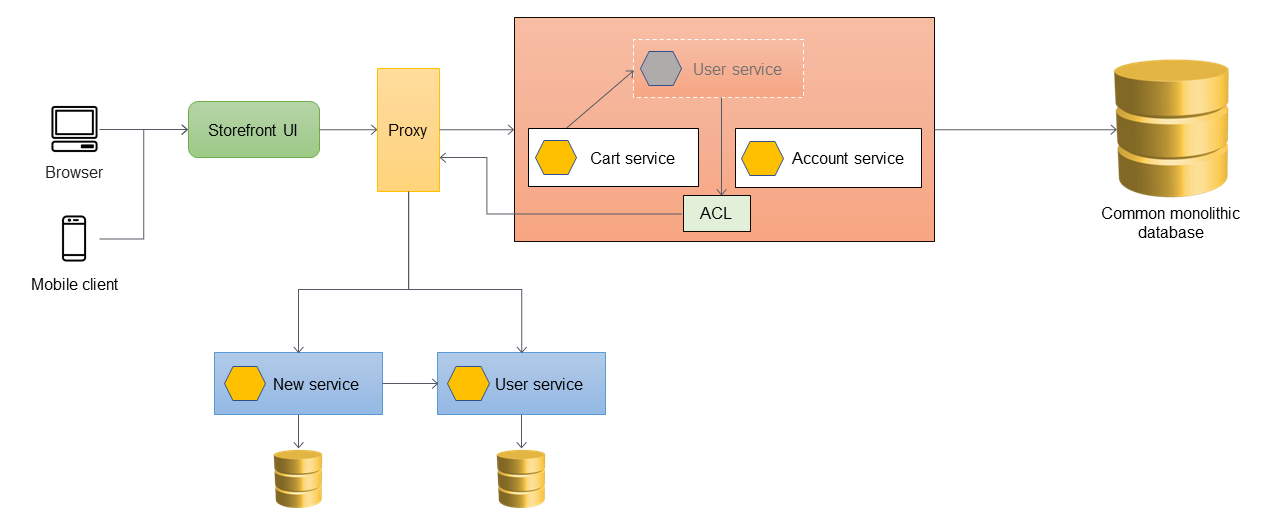
Puede implementar la ACL dentro de la aplicación monolítica como una clase específica del servicio que se migró; por ejemplo, UserServiceFacade oUserServiceAdapter. La ACL debe retirarse una vez que todos los servicios dependientes se hayan migrado a la arquitectura de microservicios.
Cuando se utiliza la ACL, el servicio de carrito sigue llamando al servicio de usuario dentro del monolito y el servicio de usuario redirige la llamada al microservicio a través de la ACL. El servicio de carritos debería seguir llamando al servicio de usuario sin tener conocimiento de la migración del microservicio. Este acoplamiento flexible es necesario para reducir la regresión y la disrupción empresarial.
Gestión de la sincronización de datos
Como práctica recomendada, el microservicio debe ser propietario de sus datos. El servicio de usuario almacena sus datos en su propio almacén de datos. Es posible que necesite sincronizar los datos con la base de datos monolítica para gestionar dependencias, como la elaboración de informes, y para dar soporte a las aplicaciones posteriores que aún no están preparadas para acceder directamente a los microservicios. Es posible que la aplicación monolítica también requiera los datos para otras funciones y componentes que aún no se hayan migrado a microservicios. Por lo tanto, es necesaria la sincronización de datos entre el nuevo microservicio y el monolito. Para sincronizar los datos, puede introducir un agente de sincronización entre el microservicio del usuario y la base de datos monolítica, como se muestra en el siguiente diagrama. El microservicio de usuario envía un evento a la cola cada vez que se actualiza su base de datos. El agente de sincronización escucha la cola y actualiza continuamente la base de datos monolítica. En última instancia, los datos de la base de datos monolítica son coherentes con los datos que se están sincronizando.
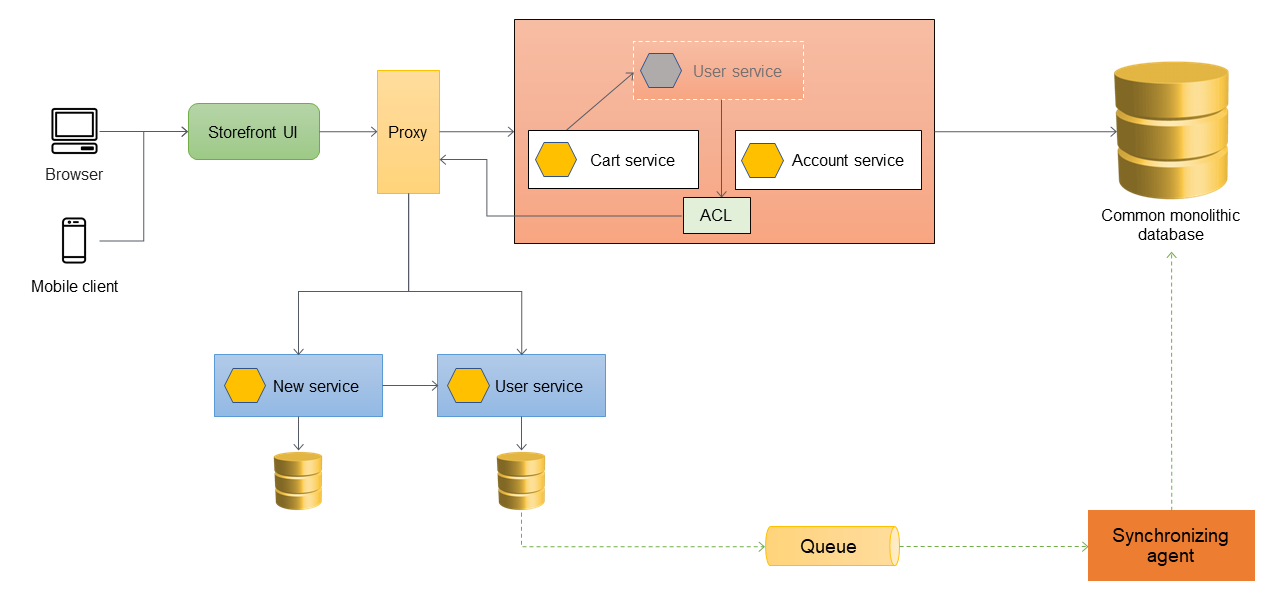
Migración de servicios adicionales
Cuando el servicio de carritos se migra fuera de la aplicación monolítica, su código se revisa para llamar directamente al nuevo servicio, de modo que la ACL ya no enrute esas llamadas. En el siguiente diagrama se ilustra esta arquitectura.
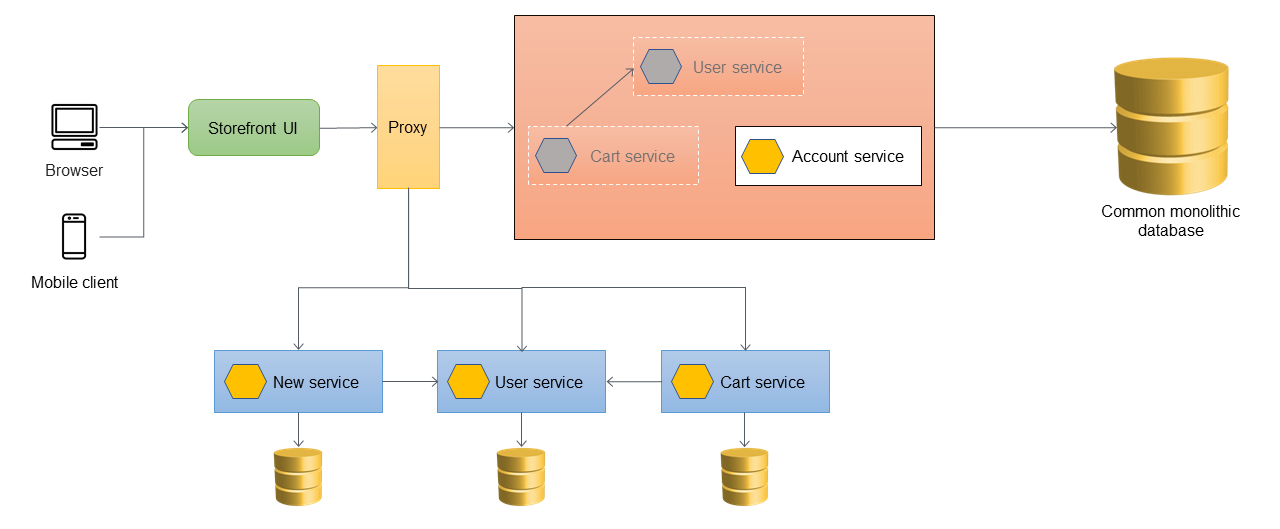
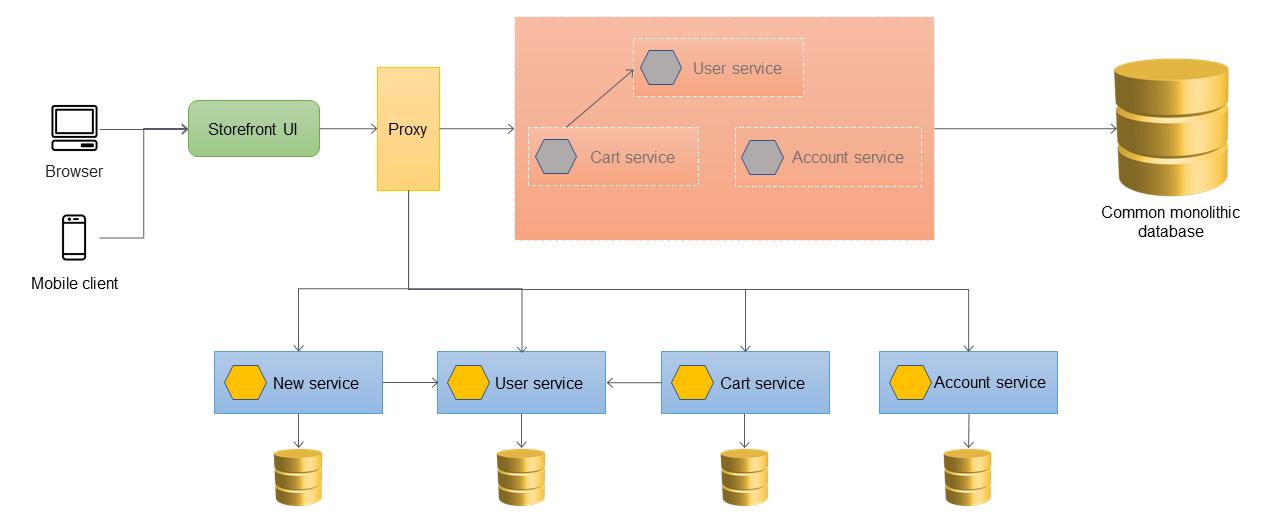
El siguiente diagrama muestra el estado final de estrangulamiento, en el que todos los servicios se han migrado fuera del monolito y solo queda el esqueleto del monolito. Los datos históricos se pueden migrar a almacenes de datos propiedad de servicios individuales. La ACL se puede quitar y el monolito está listo para ser desmantelado en esta etapa.
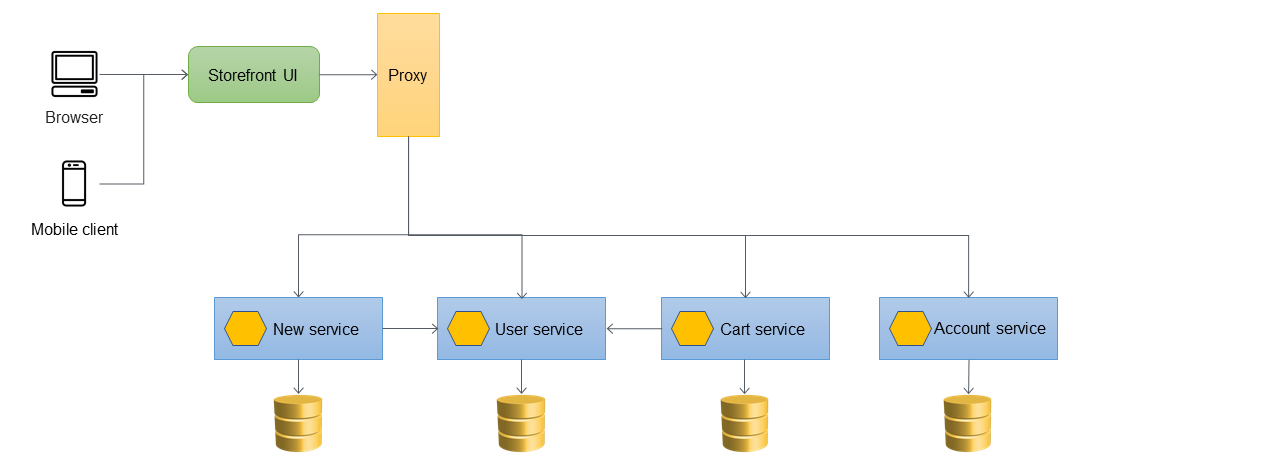
El siguiente diagrama muestra la arquitectura final tras el desmantelamiento de la aplicación monolítica. Puede alojar los microservicios individuales a través de una URL basada en recursos (por ejemplohttp://www.storefront.com/user) o a través de su propio dominio (por ejemplohttp://user.storefront.com), en función de los requisitos de la aplicación. Para obtener más información sobre los principales métodos para exponer el protocolo HTTP APIs a los consumidores principales mediante el uso de nombres de host y rutas, consulta la sección sobre patrones de enrutamiento de las API.
Implementación mediante los servicios de AWS
Uso de API Gateway como proxy de la aplicación
El siguiente diagrama muestra el estado inicial de la aplicación monolítica. Supongamos que se migró mediante una lift-and-shift estrategia, AWS por lo que se ejecuta en una instancia de Amazon Elastic Compute Cloud (Amazon EC2)
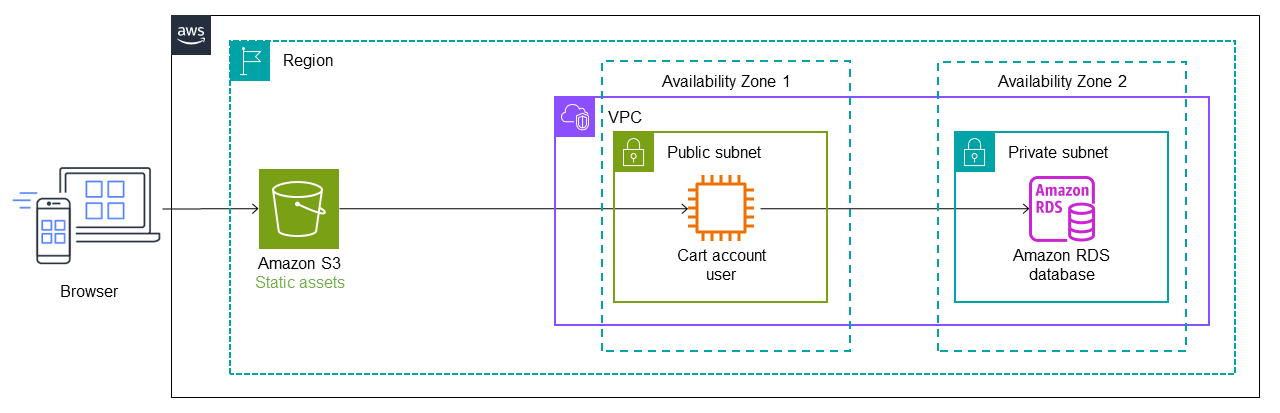
En la siguiente arquitectura, AWS Migration Hub Refactor Spacesimplementa Amazon API Gateway
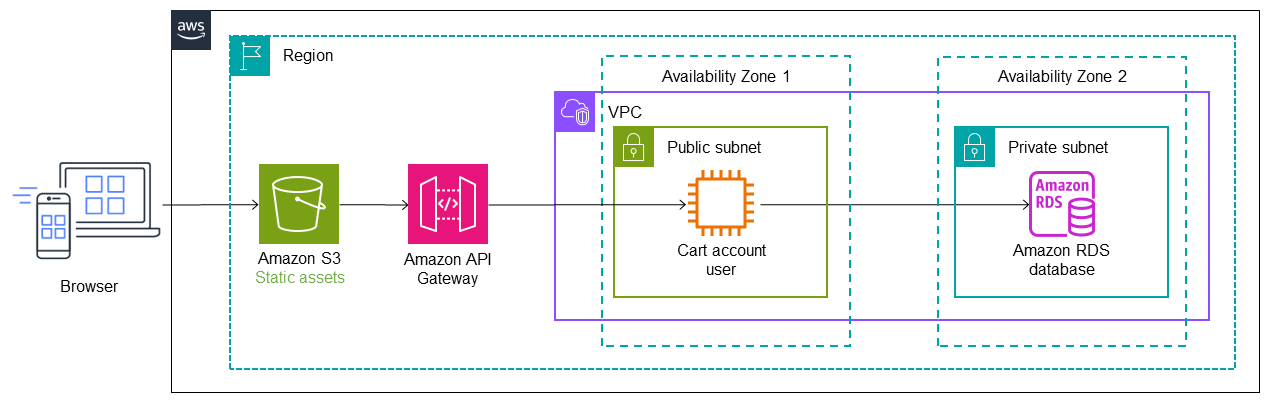
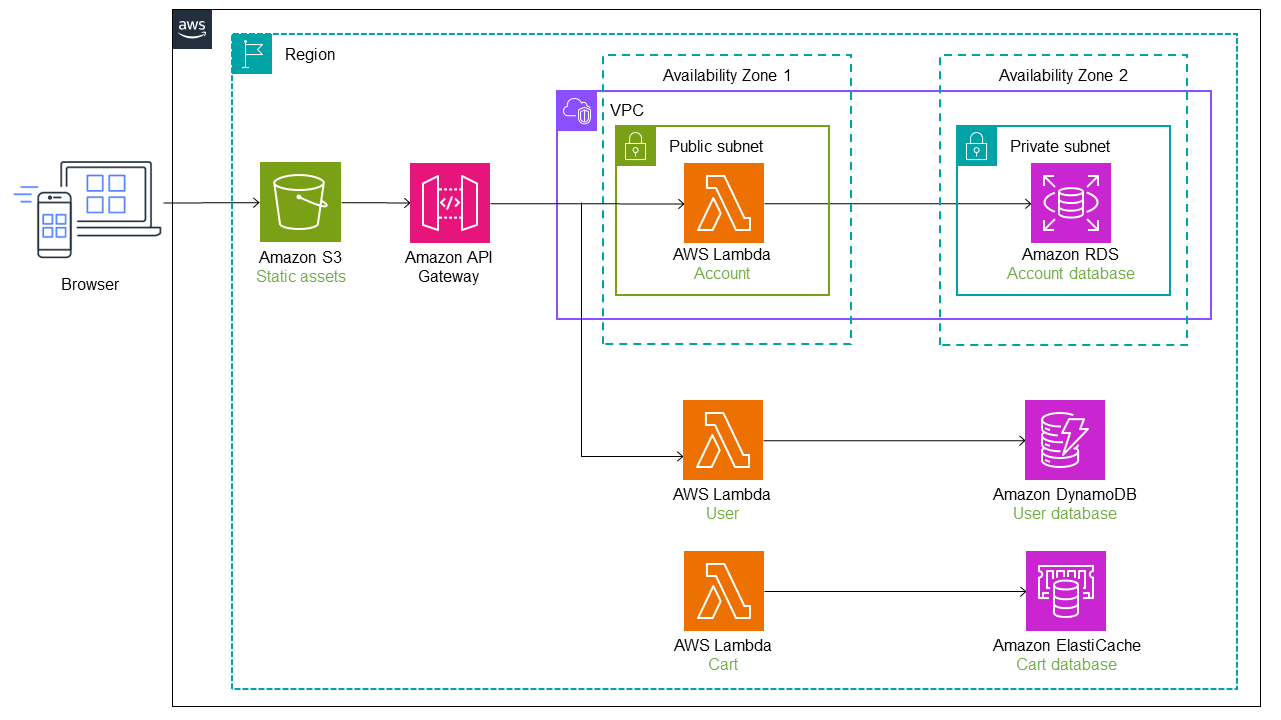
El servicio de usuario se migra a una función Lambda y una base de datos de Amazon DynamoDB
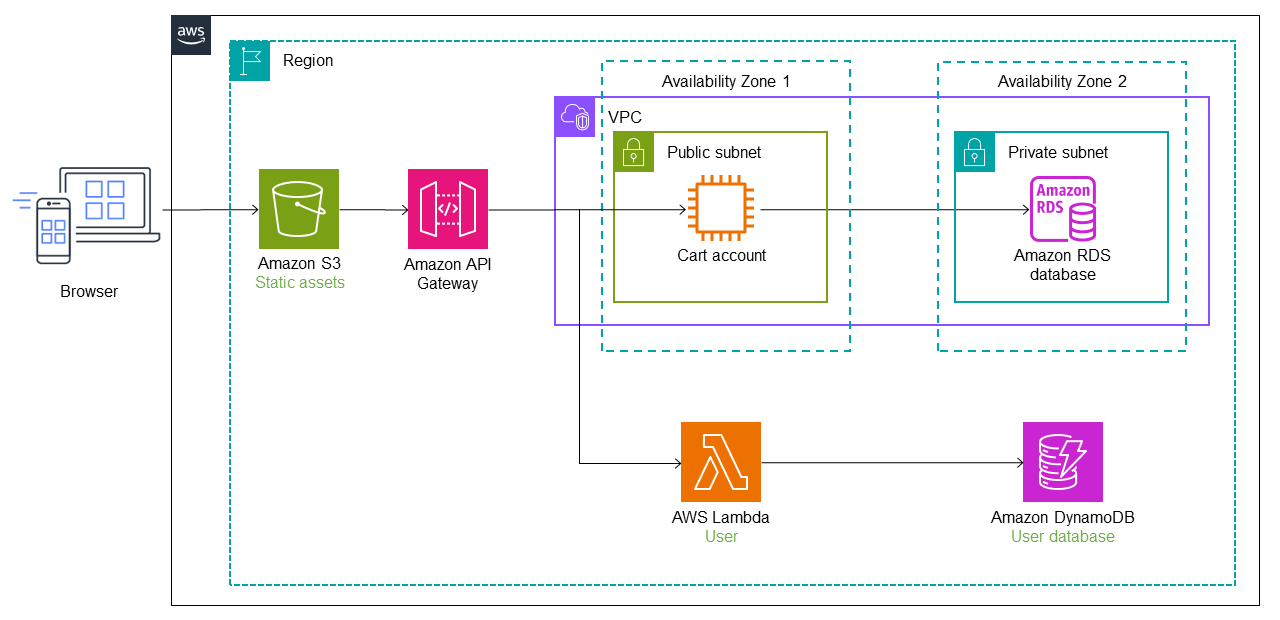
En el siguiente diagrama, el servicio de carrito también se migró del monolito a una función Lambda. Se añaden una ruta y un punto final de servicio adicionales a Refactorizar Spaces, y el tráfico pasa automáticamente a la función Cart Lambda. Amazon administra el almacén de datos de la función Lambda. ElastiCache
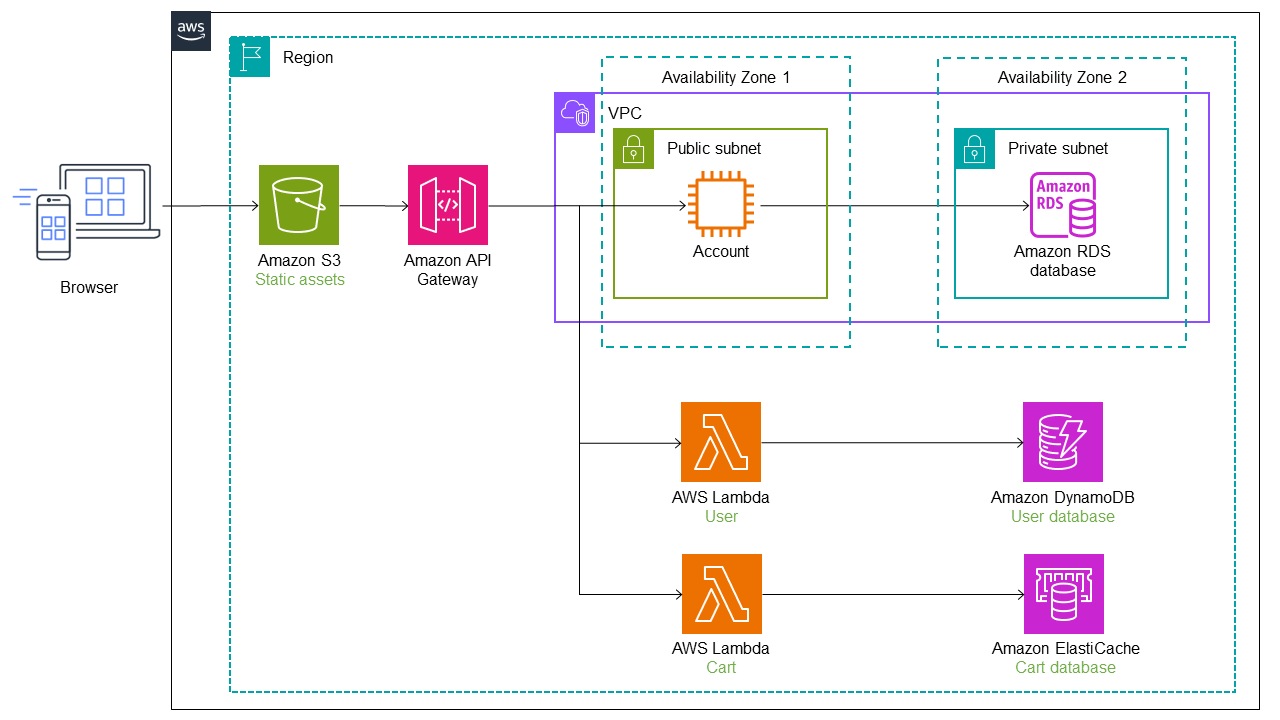
En el siguiente diagrama, el último servicio (cuenta) se migra del monolito a una función Lambda. Sigue utilizando la base de datos original de Amazon RDS. La nueva arquitectura ahora tiene tres microservicios con bases de datos independientes. Cada servicio usa un tipo de base de datos diferente. Este concepto de utilizar bases de datos diseñadas específicamente para satisfacer las necesidades específicas de los microservicios se denomina persistencia políglota. Las funciones Lambda también se pueden implementar en diferentes lenguajes de programación, según lo determine el caso de uso. Durante la refactorización, Refactor Spaces automatiza la transición y el enrutamiento del tráfico a Lambda. Esto les ahorra a sus desarrolladores el tiempo necesario para diseñar, implementar y configurar la infraestructura de enrutamiento.
Uso de varias cuentas
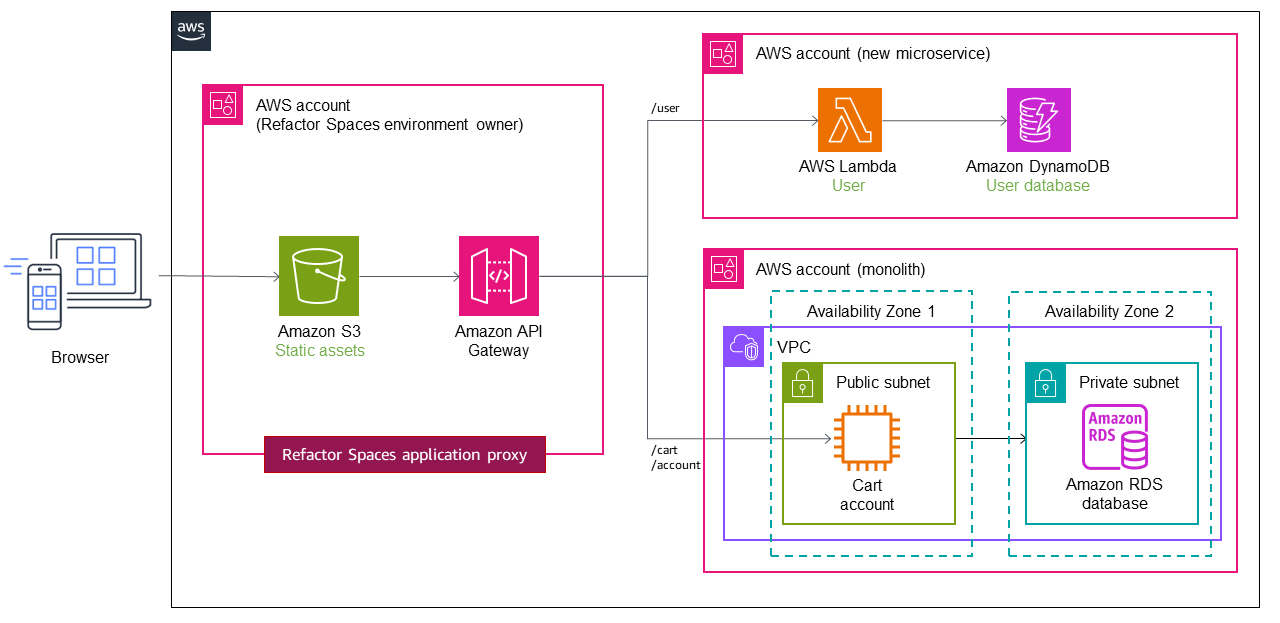
En la implementación anterior, utilizamos una única VPC con una subred privada y una pública para la aplicación monolítica, e implementamos los microservicios dentro de la misma Cuenta de AWS por motivos de simplicidad. Sin embargo, esto rara vez ocurre en situaciones reales, en las que los microservicios se suelen implementar de forma múltiple para lograr una implementación independiente. Cuentas de AWS En una estructura de cuentas múltiples, es necesario configurar el tráfico de enrutamiento desde el monolito a los nuevos servicios en cuentas diferentes.
Refactor Spaces le ayuda a crear y configurar la AWS infraestructura para enrutar las llamadas de la API fuera de la aplicación monolítica. Refactor Spaces organiza políticas de API Gateway
Supongamos que los servicios de usuario y carrito se implementan en dos cuentas diferentes, como se muestra en el siguiente diagrama. Cuando usa Refactor Spaces, solo necesita configurar el punto final del servicio y la ruta. Refactor Spaces automatiza la integración entre API Gateway y Lambda y la creación de políticas de recursos de Lambda, para que pueda centrarse en refactorizar los servicios de forma segura a partir del monolito.
Para ver un tutorial en vídeo sobre el uso de Refactorice Spaces, consulte Refactorizar aplicaciones
Taller
Referencias de blogs
Contenido relacionado
