Las traducciones son generadas a través de traducción automática. En caso de conflicto entre la traducción y la version original de inglés, prevalecerá la version en inglés.
Consumidores de datos
Los consumidores de datos consumen los datos del productor de datos después de que el catálogo centralizado los comparte utilizando AWS Lake Formation. El siguiente diagrama muestra dos consumidores de datos en el lago de datos.
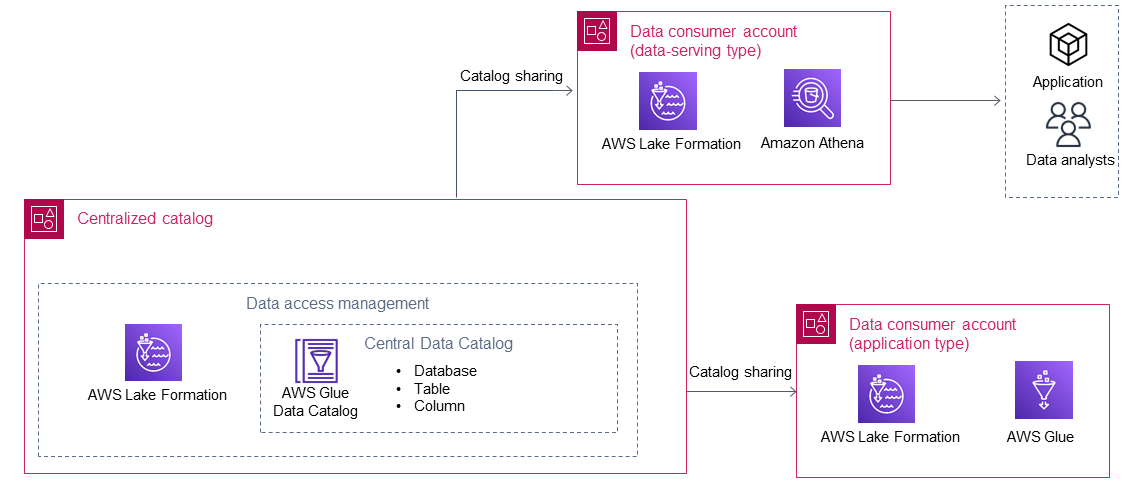
Hay dos tipos de consumidores de datos: aplicaciones y servidores de datos. En la siguiente tabla se describen estos dos tipos.
| Tipo de aplicación |
Los consumidores de datos de aplicaciones ejecutan las aplicaciones por su cuenta Cuentas de AWS. Las aplicaciones utilizan las funciones AWS Identity and Access Management (de IAM) para acceder a los datos compartidos de un productor de datos y, a continuación, los procesan según su lógica. Por lo general, este tipo de consumidor de datos tiene requisitos de datos prescriptivos para satisfacer las necesidades de una aplicación. |
| Tipo de servidor de datos |
Los consumidores de datos que sirven datos suelen estar pensados para personas (por ejemplo, analistas de datos o científicos de datos) y aplicaciones (por ejemplo, una aplicación de inteligencia empresarial) que no tienen la suya propia. Cuentas de AWS En el lago de datos de una organización pueden existir varios consumidores de datos que sirven datos. Por ejemplo, diferentes líneas de negocio pueden optar por configurar sus propios consumidores de datos que sirvan datos para ayudar a los usuarios a consumir los datos del lago de datos. Estos consumidores de datos tienen sus propias funciones principales de IAM configuradas en las suyas Cuenta de AWS (por ejemplo, las funciones de IAM asociadas a ellas AWS IAM Identity Center) que utilizan los usuarios finales de la cuenta del consumidor de datos para acceder a los datos compartidos a través de los AWS servicios (por ejemplo, Amazon Athena). Por lo general, este tipo de consumidor de datos tiene requisitos de datos amplios y en continuo aumento. |
AWS Lake Formation es el AWS servicio más importante que utiliza un consumidor de datos para compartir datos entre cuentas y acceder al catálogo centralizado. Una vez que el catálogo centralizado comparte las bases de datos, los recursos compartidos están disponibles en Lake Formation, en la cuenta del consumidor de datos. Luego, se puede conceder el acceso a los datos a los directores de IAM locales en la cuenta del consumidor de datos, con el permiso del productor de los datos, si es necesario. Luego, los datos compartidos pueden ser utilizados por AWS servicios integrados con Lake Formation (por ejemplo, Amazon Athena y AWS Glue). Puede utilizar los siguientes AWS servicios para acceder a los datos compartidos en la cuenta del consumidor de datos:
-
Amazon Athena es un servicio de consultas interactivo que ayuda a analizar directamente los datos en Amazon Simple Storage Service (Amazon S3) mediante SQL estándar. Para obtener más información sobre Athena y Lake Formation, consulte Cómo accede Athena a los datos registrados en Lake Formation en la documentación de Amazon Athena.
-
Amazon Redshift Spectrum le ayuda a consultar y recuperar datos estructurados y semiestructurados de archivos de Amazon S3 de manera eficiente sin tener que cargar los datos en tablas de Amazon Redshift. Para obtener más información sobre Redshift Spectrum y Lake Formation, consulte Uso de Redshift Spectrum con Lake Formation en la documentación de Amazon Redshift.
-
AWS Gluees un servicio de extracción, transformación y carga (ETL) totalmente gestionado que permite clasificar los datos, limpiarlos, enriquecerlos y moverlos de forma fiable entre distintos almacenes y flujos de datos de forma sencilla y rentable. La función de IAM asociada a un trabajo de AWS Glue ETL puede acceder a los datos del lago de datos gestionados por Lake Formation si cuenta con los permisos de acceso necesarios.
-
Amazon EMR ayuda a ejecutar marcos de big data (por ejemplo, Apache Hadoop
y Apache Spark ) para procesar y analizar grandes cantidades de datos. Para obtener más información sobre Amazon EMR y Lake Formation, consulte Integrar Amazon EMR con Lake Formation en la documentación de Amazon EMR. -
Amazon QuickSight es un servicio de inteligencia empresarial escalable, sin servidor, integrable y basado en el aprendizaje automático (ML) que puede utilizar para analizar y visualizar los datos de su lago de datos. Para obtener más información sobre QuickSight Lake Formation, consulte Autorizar conexiones a través de Lake Formation en la QuickSight documentación.
-
Amazon SageMaker AI Data Wrangler (Data Wrangler) reduce el tiempo necesario para agregar y preparar los datos para el aprendizaje automático. Para obtener más información sobre Data Wrangler y Lake Formation, consulte Prepare ML Data Wrangler con Amazon SageMaker AI Data Wrangler en la documentación de Amazon AI. SageMaker
